基于朴素贝叶斯分类的强化学习及在游戏中的应用
【摘要】 随着互联网的告诉发展,手机电脑上也出现了各种各样的游戏,丰富人们的日常生活水平。游戏往往会出现决策问题,如何做出一个正确的决策是我们玩游戏的关键。对于简单的小游戏,Random算法和Sarsa算法都能轻松的解决,并且这些算法在游戏中达到的成绩远超人类玩家在游戏中达到的成绩。伴随着机器学习的不断进步与创新,强化学习能应用于各式各样的游戏中,并出现了各种算法来解决游戏图像和游戏策略的问题。强化学习是指智能体通过模仿人类的学习方法来适应环境,这种方法能使计算机主动学习规则,通过不断的尝试获取数据,优化累积奖励信息,根据奖励做出不同的动作来逐渐优化决策。
本文运用强化学习中的Q-learning算法,但是该算法在改变初始信息时,所有的Q值都将改变,以至于从不同的起点开始游戏都需要重新运用Q-learning算法计算Q表。为了改善算法的效率并降低Q-learning算法的过高估计问题,本文在Q-learning算法中加入朴素贝叶斯分类,根据样本的经验,探索不同的路径,逐渐完善Q表,并对于Q表进行分类,根据分类的方案,选取每个状态下得优良动作,最后让所有位置状态都能通过最短路径完成游戏 。
【关键词】 强化学习 ,朴素贝叶斯分类,Q-learning算法
Reinforcement Learning based on Naive Bayes Classification and Its Application in Games
【Abstract】 With the development of Internet, there are many kinds of games on mobile computers, which enrich people's daily life. Games often have decision-making problems. How to make a correct decision is the key to play games. For simple games, random algorithm and sarsa algorithm can be easily solved, and the performance of these algorithms in the game is far higher than that of human players in the game. With the continuous progress and innovation of machine learning, reinforcement learning can be applied to various games, and there are algorithms to solve the problem of game image and game strategy. Reinforcement learning means that the agent adapts to the environment by imitating the human learning method, which enables the computer to learn the rules actively, obtain data through continuous attempts, optimize and accumulate reward information, and make different actions according to the reward to gradually optimize the decision-making.
This paper uses the Q-learning algorithm in reinforcement learning, but when the algorithm changes the initial information, all the Q values will change, so that the game from different starting points needs to re use the Q-learning algorithm to calculate the Q table. For improving the efficiency of the algorithm and cutting down the over estimation of the Q-learning algorithm, this paper adds naive Bayes classification to the Q-learning algorithm, explores different paths according to the sample experience, gradually improves the Q table, classifies the Q table, selects excellent actions in each state according to the classification scheme, and finally makes all the position states complete through the shortest path game.
【Key Words】 Reinforcement Learning,Q-learning,Naive Bayesian algorithm
目 录
1 绪 论
1.1 选题背景和研究意义
1.2 国内外研究现状
1.2.1 国内研究现状
1.2.2 国外研究现状
1.3 研究的基本内容
2 基础理论介绍
2.1 朴素贝叶斯分类
2.1.1 贝叶斯定理
2.1.2 朴素贝叶斯定理
2.2 强化学习
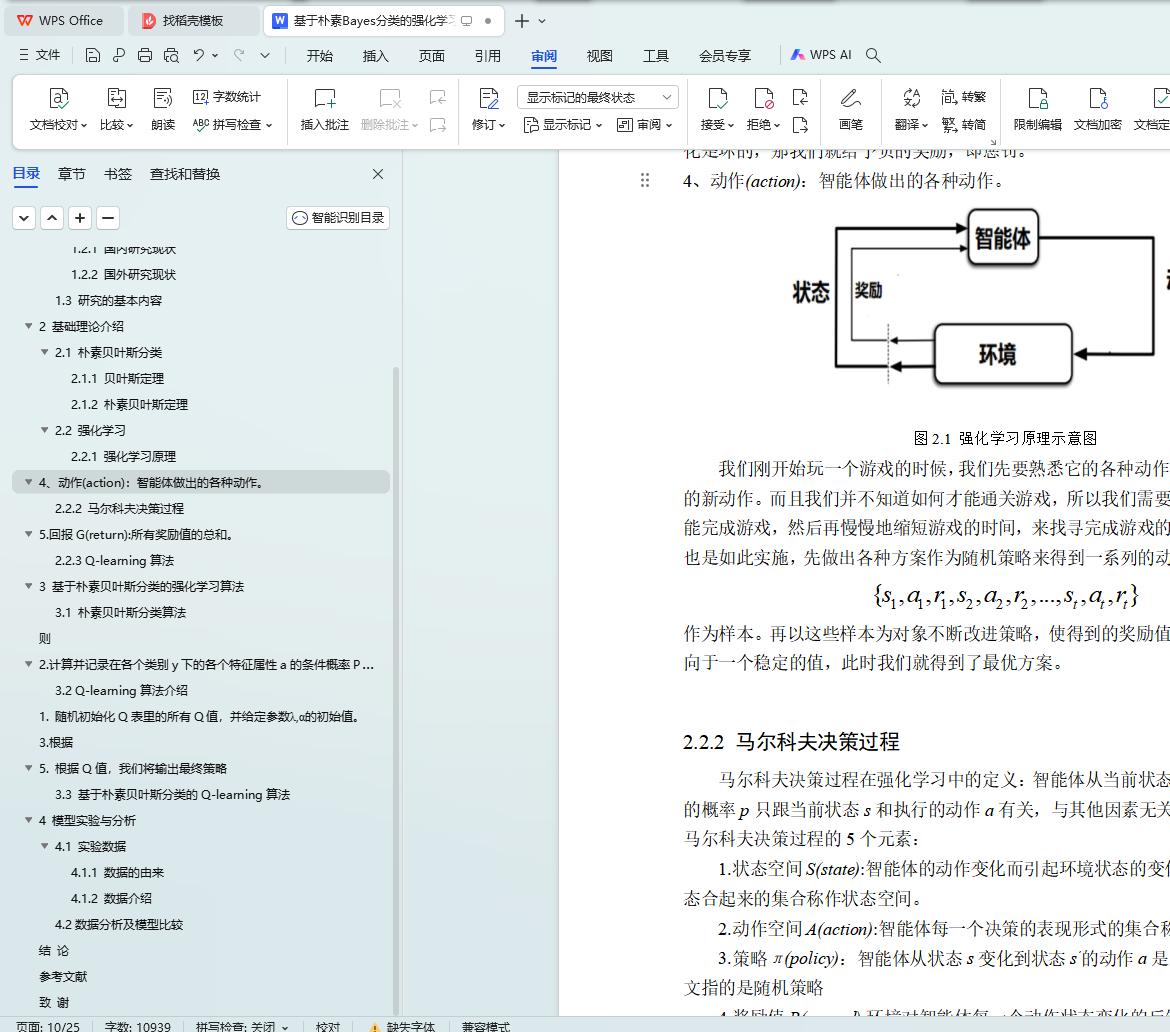
2.2.1 强化学习原理
2.2.2 马尔科夫决策过程
2.2.3 Q-learning算法
3 基于朴素贝叶斯分类的强化学习算法
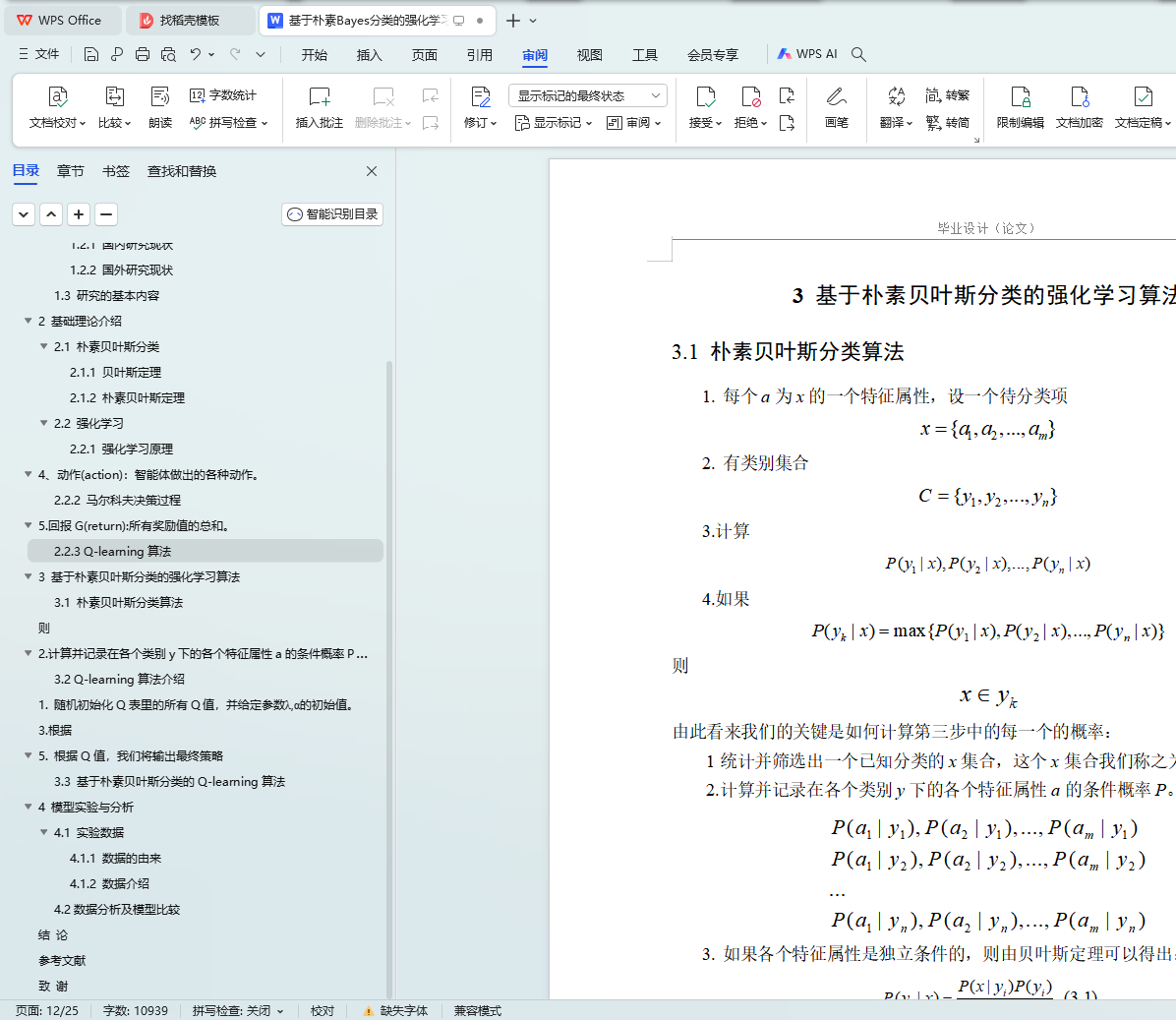
3.1 朴素贝叶斯分类算法
3.2 Q-learning算法介绍
3.3 基于朴素贝叶斯分类的Q-learning算法
4 模型实验与分析
4.1 实验数据
4.1.1 数据的由来
4.1.2 数据介绍
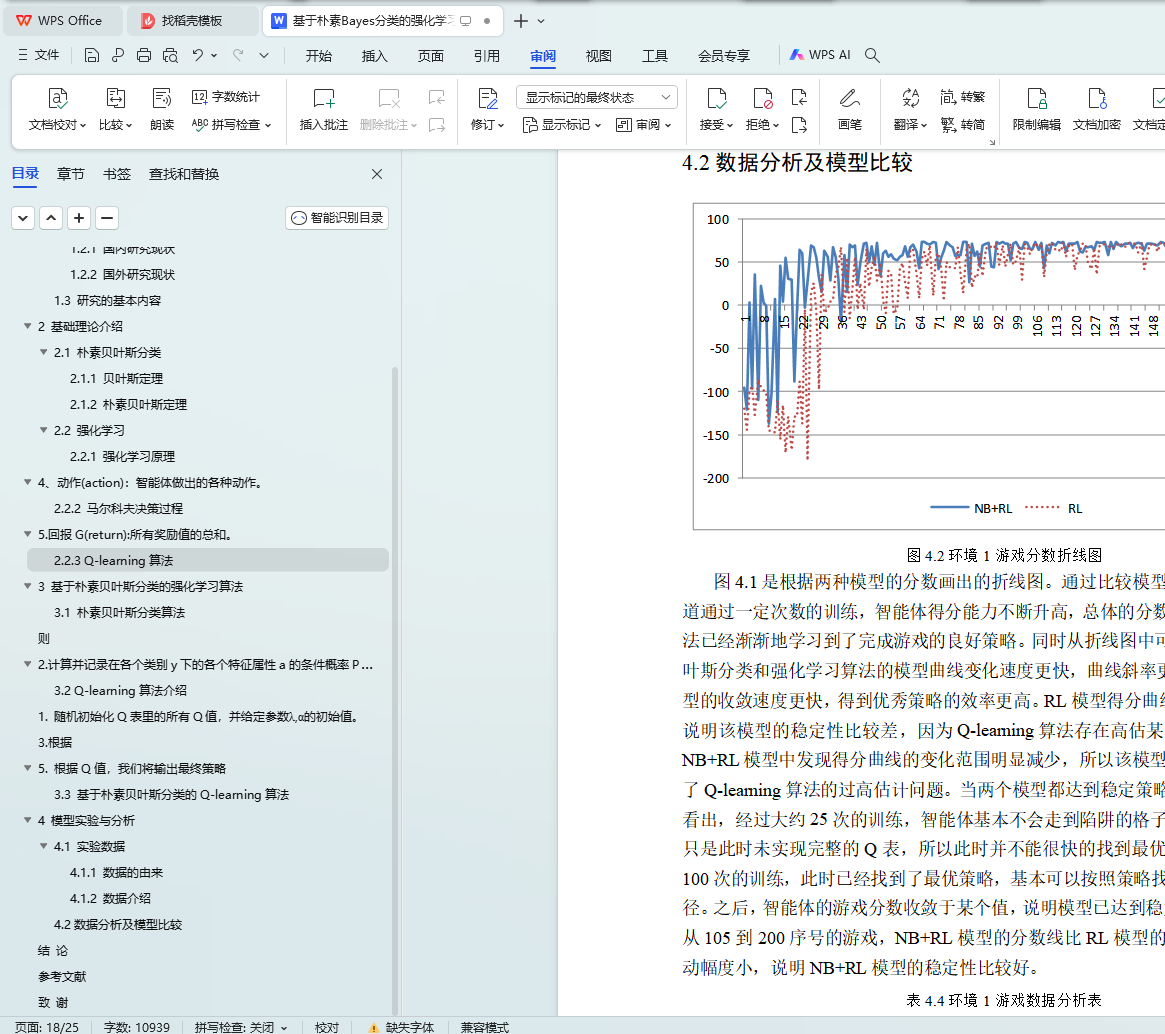
4.2数据分析及模型比较
结 论
参考文献
附 录(必要时)
致 谢