6.3 图划分和通信
采用不同的图划分算法,分区之间和分区内顶点之间的通信开销也会各有差异。例如Pregel采取hash方式进行图划分可以很好的保持计算节点间负载均衡,但在迭代处理过程中面临高额的跨计算 节点通信,并且不适合幂律图的划分。然而基于GAS模型的PowerGraph采用顶点划分的方式,并且根据顶点的分布状况去分配对应的边,以减小跨节点的通信量,能实现对幂律图的有效处理。
本小节首先对现有图划分策略进行介绍,然后从消息交换模式和消息发送时序控制两个方面总结了消息通信方面的核心技术。
6.3.1 图划分策略
图划分质量对负载均衡、计算节点通信、存储和计算效率等都有极大影响。目前主要的图划分原则是:保证负载均衡和减少边跨越划分块的次数。图分割的难点在于真实世界的图一般符合幂律分布,这使得图难于均匀分割,导致负载倾斜和数据局部性差。此外,过于复杂的图分割带来的计算开销也是必须要考虑的一个重要因素。
图划分是图计算的前提。由于图计算通常按照拓扑结构访问数据,所以每次迭代处理均会引入巨大的通信开销,成为制约图计算性能的关键因素。因此,一个良好的图划分算法应保证划分后的子图在负载均衡的前提下,减少子图之间的交互边(切分边)规模,从而减少网络通信。在图计算中有两种主要的划分方法,如图 6-3-1所示:(1)基于边的划分,在GraphLab、LFGraph和最初版本的Pregel等系统中使用了该方法;(2)基于顶点的划分,在PowerGraph、GraphX等系统中使用了该方法。此外,PowerLyra也提出了一种由前二者引申出的点边混合划分方法,如图 6-3-1所示。基于边的划分和基于顶点的划分适合不同的场景。

图 6-3-1 基于边和基于顶点划分算法的对比
一、以顶点为中心的划分
如图 6-3-2,这种图划分方式的基本调整单位为图顶点及其对应的邻接边。对于基于顶点的划分的系统,边被分到了不同划分块中,而顶点可以跨越多个划分块。与仅能跨越两个划分块的边不同,一个顶点可以同时存在于多个划分块之中,因为这个顶点的边可以被分配给多个划分块。该划分方式把图数据的顶点作为处理对象,利用图的边传递信息,通过顶点与邻接边之间的边通信,进而在邻接点之间传递计算和状态信息。顶点为中心实际上是把顶点作为独立的计算代理顶点,计算代理顶点相互独立地执行计算和通信任务。
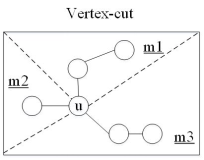
图 6-3-2 基于顶点划分算法
二、以边为中心的划分
如图 6-3-3所示,基于边的切割时沿着图的边划分,把顶点均匀地分布到每个计算节点最小化边在计算节点的跨越,该方法要求每一个割边需要多个计算节点上保留复制和通信以保持图之间的结构依赖关系。以边为中心划分的系统,顶点被分配到不同划分块中,边可以跨越多个划分块。在具有很多低度顶点的图中,顶点的所有相邻边被分配给同一个机器,所以基于边的划分更适合这种场景。然而,对于幂律图,基于顶点的划分允许通过在多个机器上分配这些节点的负载来实现更好的负载均衡。
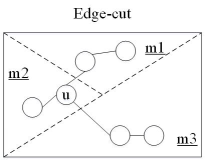
图 6-3-3 基于边的划分算法
三、顶点和边混合划分方式
PowerLyra提出了一种混合图分割方法Hybrid-Cut,即出入度高的顶点采用切点法,反之,出入度低的顶点采用切边法。性能提高了至少1.24倍。如图 6-3-4所示,Hybrid-Cut图划分算法根据顶点度数的不同选取差异化的处理策略,对于度数较低的顶点,如节点2,3,4,5,6,为了保证局部性,算法会将其集中放置在一起,而对于度数较高的顶点,如1,为了充分利用图计算框架并行计算的能力,算法会将其对应的边摊放到各个机器上。通过按顶点度数对顶点进行差异化的处理,Hybrid-Cut算法在局部性和算法并行性上达到了较好的均衡。
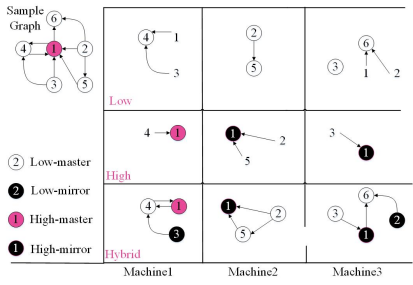
图 6-3-4 点边混合划分算法
6.3.2 消息推送机制
在图处理应用中,每个图顶点都需要向邻居顶点发送消息或从邻居顶点接收消息,其中图的边可以看作消息收发的通道。当图顶点的数据规模达到百亿级别时,边的数据规模会十分庞大,而单节点图计算受硬件资源限制,在处理更大规模数据时面临硬件可扩展方面的问题,因此,现有图处理系统通过统一的资源调度, 使待处理数据存储于分布式内存中, 实现大规模数据的快速访问和处理。图划分是分布式计算的前提,划分后的各个子图之间采用何种消息推送模式,是制约图处理系统性能的关键因素。
一、消息交换模式
图处理过程中消息交换模式可分为Push和Pull两种,如图 6-3-5所示。
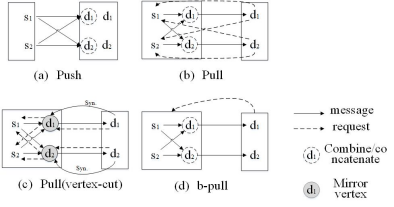
图 6-3-5 Pull和Push消息交换模式
1. Push模式
Push模式是一种以源顶点为中心的处理模式,即图处理系统遍历源顶点,完成顶点的更新计算,然后按照出边广播消息给目的顶点。这种方式处理机制简单,且在内存资源充足的情况下,由于各个任务可以分别处理源顶点,因此具有较好的并发性。另一方面,考虑到出边中的目的顶点的分布具有较差的局部性从目的顶点的角度分析,其收到的消息在时间和空间方面均具有较差的局部性。而作为同步处理系统烦的内在约束,在第k次迭代,一个顶点只收到了所有来自k-1步的消息之后,才可以启动本地计算更新顶点的值。Push模式下较差的时空局部性,使得图处理系统必须存储所有已收到的消息,知道所有源顶点完成消息推送,这显然增大了接收端的消息存储规模。尤其是在内存资源有限的环境下,大量消息的磁盘存取会导致昂贵的I/O开销。目前,Pregel、GPS和Giraph等系统均采用Push的方式实现消息交换。其中,Giraph系统同时支持内存版本和磁盘版本的图处理应用。
2. Pull模式
Pull模式是以目的定点为中心的一种消息推送机制,即各任务遍历目的顶点,根据入边相对应源顶点请求消息数据。显然,当一个目的顶点收到所有请求消息后,即可立即执行更新计算,避免存储大量的消息数据。Chronos、Seraph等系统均支持Pull方式的消息推送机制。然而,Pull方式下,在请求消息数据时,需要传送对应的源顶点ID,在分布式环境下引入额外的通信开销,尤其对于单源最短路径计算等问题,在迭代的收敛阶段大部分目的顶点可能已经达到稳定状态,Pull会引入额外的请求开销。
二、消息发送的时序控制
由于图结构依赖性导致其计算往往需要多次迭代,复杂性的结构使得达到稳定点计算步骤不同,需要在计算步之间进行控制。根据消息发送的时序控制,可以将现有的图处理消息交换模式分为同步和异步通信。前者,图计算顶点的计算处理和消息通信串行进行,在计算完毕周,统一发送消息,控制和实现的方式简单但是容易造成瞬间的网络通信阻塞,增大了发送端的消息存储开销。后者图顶点的计算和处理与消息通信并发执行,在计算过程中就可以发送消息,将大规模消息的发送分散在不同的时间段,充分利用空闲的网络资源,避免瞬间的网络通信堵塞。同步异步消息推送机制的比较见图 6-3-6。

图 6-3-6 同步异步消息推送机制的比较
1. 同步模式
同步模式即相邻两步迭代之间存在同步控制,所有任务均完成该步的工作之后,才可以启动下一次迭代计算,发往第k次迭代的消息仅在第k次迭代时对顶点可见。同步模式的控制机制简单,便于用户理解,且表达力强,易于程序调试,因此被Pregel、Giraph等系统广泛采用。但是该模式也有自身局限:
(1)水桶效应:在同步模式中,由于任务处理速度不一致,当各任务负责处理的数据规模或数据内部的复杂程度不同时,会导致任务处理速度相差很大,因此造成了水桶效应。频繁的同步操作使得处理效率最慢的任务严重影响整体性能,尤其是对于出度分布具有幂律偏斜特点的真实图。而图算法的高频迭代性更加剧了水桶效应的影响。
(2)收敛速度慢:在同步模式下,两次迭代计算之间,消息仅能在顶点的直接邻居之间传播。低效的消息传播方式,使得迭代的收敛速度缓慢。例如,对于单源最短路径的计算,其迭代计算步数等于图的直径,在路网等直径较大且出边分布比较稀疏的图数据,缓慢的收敛速度成为影响系统性能的关键因素之一。
2. 异步模式
异步模式即相邻两步迭代之间不存在同步控制,各任务独立进行迭代计算,不存在相互等待。在迭代过程中,当消息到达接收方后,目的顶点可以立即启动计算处理,并广播新的计算结果,而不必同步等待所有顶点均收到所有消息数据。
异步处理机制缓解了水桶效应的影响,可以加快消息的传播速度,加速收敛,减少同步开销。此外,由于消息接收后可以立即参与计算,减少了消息数据的存储开销。然而,与基于BSP的同步计算模型相比,异步计算增大了编程和调试的难度。此外,一步计算结果具有不确定性,如果程序设计不合理,可能导致迭代计算无法收敛。最后,由于顶点接收到部分消息后即启动更新计算,可能导致大量冗余消息的传播。
3. 混合模式
深入分析上述同步和异步模式的特性可知,实际计算性能会受到实际图应用算法、图划分方法、迭代的执行速度、输入图的特征和分布式集群的规模等诸多因素的影响,两种方式各有利弊。因此PowerSwitch利用在线采样与离线分析技术和一组启发算法,动态预测两种模型的计算性能,建立代价收益模型,实现迭代过程中同步和异步计算的自动切换。如图 6-3-7所示。
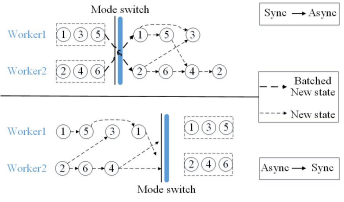
图 6-3- 7 同步异步切换
