���ڻ���ѧϰ�Ļ���ʶ��APP�����ʵ��
һ�� ��Ŀ��Դ
��Դ������/���ʵ�ʡ�
���� �о���Ŀ�ĺ�����
һ���棬��ͳ�Ļ���ʶ��ͨ�������˹�������ȡ�ͻ���ѧϰģ�ͣ����ڽ϶�����ԣ���������Զ��������ӱ����Ļ���ͼ��ʱ��Ч���ϲ���ѧϰ���ر��Ǿ��������磨CNN�����ܹ��Զ�ѧϰͼ���е���������������Ҫ�˹���Ԥ�����ܹ��ڴ��ģ���ݼ��ϱ��ֳ���Խ�����ܡ��������ѧϰ������ʶ���ȷ�Ժ�Ч�ʵõ�����������ϵͳ�ܹ��ڸ��ֻ����£��粻ͬ�Ĺ��ա�����������Ƕȵȣ�ȷʶ��Ʒ�֡���Կ��С������Լ���ҵӦ�ã��������գ���������Ҫ���塣��һ���棬����ȫ��ֲ������Ժ���̬���������������أ�ֲ��ʶ��ϵͳ�ܹ��ṩ��Ч�ĸ������ߣ������о���Ա���õط����ͼ��ֲ����Ⱥ�ķֲ��ͱ仯�����ѧϰģ���ܹ�ͨ��ʶ�ܵ����ࡢ����״���ȣ�Ϊֲ��ѧ����̬ѧ�����������������ṩ�ɿ�������֧�֡�
���� �Ķ�����Ҫ�ο�������������
[1] ����. �������ѧϰ������ϡ���ʾ������ʶ��[D].����ϵͳѧ��,2016.DOI��
10.11992/tis.2016030
[2] ������. �������ѧϰ������ʶ�����о�[D].����ʦ����ѧ,2015.
[3] ������.�������ѧϰ������ʶ���о�[D].����������ѧ,2013.DOI:CDMD:2.1013.198327.
[4] ��֣ƽ.�������ѧϰ����������㷨�о�[J].�����Ӧ��������,2018.DOI��10.3969/j.issn.1000-386x.2018.01.035
[5] ������.�������ѧϰ�����ּ��[J].������ͨ��ѧ,2015.
[6] �ŭU. �������ѧϰ��ͼ���������ϵͳ[D].���Ӽ���Ӧ��,2019.DOI:CNKI:SUN:DZJY.0.2019-12-016.
[7] �ź�. �������ѧϰ�ĵ�Ŀ��ȹ����о�[D].�Ϸʹ�ҵ��ѧ,2022.
[8] ��쿳�. �������ѧϰ��ͼ�����[D].�����ʵ��ѧ,2017.DOI:CNKI:CDMD:1.1017.289472.
[9] ����.�������ѧϰ��������Ϊʶ���㷨����[J].�Զ���ѧ��,2016,DOI��10.16383/j.aas.2016.c150710
[10] ������. �������ѧϰ����Ƶ�쳣����о�����[D].ģʽʶ�����˹�����,2024.DOI:10.16451/j.cnki.issn1003-6059.202402003.
[11] ������.�������ѧϰ��ţ�����ʯ���Ƶȼ��ֻ�����ϵͳ[J].ũҵ����ѧ��,2020.DOI��10.11975/j.issn.1002-6819.2020.13.029.
[12] ������.�������ѧϰ�����ಡ���羵ͼ���Զ�ʶ��[J].�л�ʵ����ٴ�����ѧ��־,2021.DOI��10.3760/cma.j.cn112866-20200406-00108.
[13] ����.�������ѧϰ�ı���ȱ�ݼ�ⷽ������[J].�Զ���ѧ��,2021.DOI��10.16383/j.aas.c190811.
�ġ� ��������״�ͷ�չ�������о�����������
��ͳ�Ļ���ʶ��ϵͳ��Ҫ�����ڻ��ڹ�����㷨��dz�����ѧϰ�������������������ȡ���㷨�ʹ�ͳ�ķ��������Щϵͳ��Ȼ��һЩ��������Ч��������Ը��ӵĻ���ʶ������ʱ�������������ԵIJ���֮������������ص㣬����������ѧϰ���һ������ʶ��ϵͳ.���ѧϰ�������Ǿ��������磨CNN�����ܹ��Զ��Ӵ�����ͼ��������ѧϰ��Ч���������������˹���ơ����ѧϰģ���ܹ���ѵ������������Ӧ��ѧϰ�������е���Ҫ���������и�ǿ�ķ����������ݴ��ԡ�ʹ��������ǿ����������ת����ת���ü����ı����ȺͶԱȶȵȣ��������ģ�ͶԲ�ͬ���ݱ仯����Ӧ������������ǿϵͳ�ڸ��ӻ����µ�ʶ�����ܡ��������ѧϰ�����IJ��Ϸ�չ���о������ڲ��ϳ��Ը�������ӵľ��������磨CNN���ܹ�����DenseNet��EfficientNet�ȣ��������ʶ�Ⱥ�ģ��³���ԡ�
�塢 �о����ݡ����ص��о��Ĺؼ����⼰���˼·
1.ϵͳ�����������
ϵͳ����Ӧ��������
ǰ������
��1���û���ҳ���
��2������ʶ����
��3��ͼƬ�ϴ�����
��4��ʶ����չʾ
�������
��1�����ݼ��ռ���Ԥ��������
��2��������ȡ
��3��ģ�ʹ���Ż�
��4��ģ�͵�ѵ��
��5��ģ�͵IJ���
Ϊʵ�����Ϲ��ܣ�ϵͳӦ���еĹ���ģ����ͼ1��ʾ��
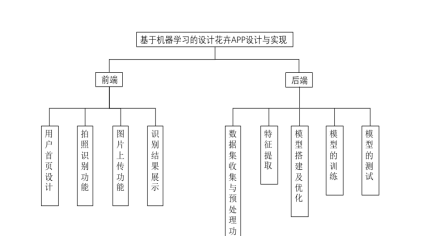
ͼ1 ϵͳ����ģ��ͼ
2. ���ݵ��������
�����һ���������ѧϰ�Ļ���ʶ��ϵͳʱ�����ݿ�������������Ҫ�ġ����ݿ���Ҫ�ܹ��洢��������ͼ�����ݡ���ǩ��Ϣ��ͼ��������ѵ�������е��м����ݵȡ������Ƕ����ݿ������������ϸ��Ϣ������
(1)ͼ�����ݱ����洢����ͼ��Ļ�����Ϣ��
����ͼ���Ψһ��ʶ������ʽ���ֱ��ʣ��ļ���С���ϴ�ʱ��ȡ�
(2)����Ʒ����Ϣ�����洢���ܵķ�����Ϣ��
���ܵ�Ψһ��ʶ�������ܵ�ѧ�������ܵ���ɫ�����ܵĻ��ͣ����ܵ���ɫ�������������Ŀƣ����ܵ�ϡ�жȵȡ�
(3) �������ݼ�
��Ҫ�㹻������������ٰ���5000��ͼƬ������ȷ����ȷ��ʶ����ֻ��ܵ���Ϣ��
(4)ͼ���뻨��Ʒ�ֹ��������洢ͼ���뻨��Ʒ�ּ�Ĺ�����Ϣ��
������Ψһ��ʶ����ͼ�������������ܱ����������ǩ��ȷ�Եȡ�
(5)�û���Ϣ�����洢�û���Ϣ��
�û�ID�����䣬ע��ʱ��ȡ�
3. ϵͳ����ԭ��
�������ѧϰ�Ļ���ʶ��ϵͳ���þ��������磨CNN���Ի���ͼ����з��ࡢʶ���������ȡ����ϵͳ����ԭ�����Է�Ϊ������Ҫ�Σ������ռ�������Ԥ������ģ��ѵ�������Ժͷ������ڹ�������ʶ��ϵͳʱ��������Ҫ�ռ������Ļ���ͼ�������ֶ����Զ���ע��ȷ��ÿ��ͼ������ȷ�����Ӧ�Ļ���������й�����ͼ������ͨ����Ҫ����һϵ��Ԥ�������裬�Ա������뵽���ѧϰģ���н���ѵ������������ѵ���Σ�ʹ�þ��������磨CNN�������ѧϰģ�ͽ��л���ͼ���������ȡ����ࡣ��ģ��ѵ����ɺ���ʹ�ø�ģ�Ͷ��µ�ͼ�����������������ʶ��
4. �ؼ������ͽ��˼·
��1�����ݲɼ���������ǿ
����ͼ������ݼ����ܰ�������������ֲ�����ͼ������������Ƕȡ����������Ⱦ��нϴ�ı仯����Щ������ܵ���ģ�͵ķ������������ʶ�ȵ͡��ɼ������ı�עͼ���Dz�ͬ�Ļ���Ʒ�֡���ͬ������Ƕȡ������ͱ������������ù������ݼ���Oxford Flowers 102�Ȳ���ͼ����ǿ����������ת����ת�����š��ü�����ɫ�任�ȣ�����չѵ�����ݼ�������ģ�͵�³���ԣ���ֹ����ϡ�
��2�����������磨CNN����������ȡ��ģ�����
��Ƶĺ��ľ��Ǿ������������ƣ�������õľ����������������������㣬�����ػ��㣬����ȫ���Ӳ���ɡ� ����������ṹ������ͼ��ͼ2��ʾ��
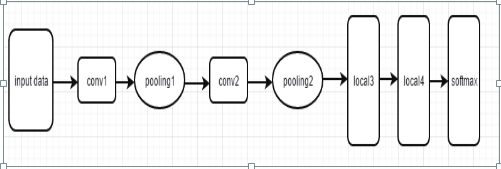
ͼ1 ����������ṹ
��������CNN�ĺ��ģ�������ȡ�ֲ���������ͨ��������������������������ͼ��Ļ����������㣩����������ͼ��feature map����������ͨ����һ��С���˲���������ͼ���ϻ���������ֲ�����ļ�Ȩ�͡��ػ�����ŵ���ǿ��Էdz���Ч����С����ijߴ磬���ҿ��Ա��������Ҫ��������������һ�� Ҫ�����IJ������;�������Щ���ƣ��ػ������ǰ����Ҳ��ͨ��һ�������ھ����������Ĺ������Ľṹ��ɵġ�ȫ���Ӳ�ͨ��λ������ĺ�ˣ����ڽ���ȡ��������ӳ�䵽Ŀ������ع�����������㼶���������ÿ���ڵ㶼��ǰһ������нڵ������ӣ����ڷ�����������վ��ߡ�
��3���Ż�������
ϵͳʹ���ݶ��½��㷨���Ż����磬������Ҫ�ȶ��������Ż��㷨����������������ı���㷨���ڶ�����һ����Ҫ�ĺ������Կ�ʼѵ��������ģ���ˣ��ȶ���ѵ������ͼƬ�����ļ��кͱ�����������ļ��У�ͨ��֮ǰ������ļ����������ͻ�ȡ���κ�������ȡѵ��ʱ��ͼƬ���κͱ�ǩ���Ρ�ÿѵ��100���������ǰ��ѵ����ʧ��ʶ��ȷ�ʣ�ÿ��2000������һ������ģ�͡�tensorflow�����ַ�ʽ��ʵ�ֶ�ѵ������������ģ�͵ı��棬��һ�ַ�ʽ�����ɼ����ļ������ļ�����չ��ͨ��Ϊ.ckpt��ͨ����tf.train.Saver������ֱ����Saver.saver()���ɣ����ַ���������������һЩȨֵ��Ҳ���������ඨ��ı������ڶ��ַ�ʽ��������ͼЭ���ļ�(graph proto file)�������ļ���չ��һ��Ϊ.pb�������ַ�ʽ���ɵ��ļ���ͼЭ���ļ���Ҳ����ֻ����ͼ�νṹ������Ȩ�أ��÷���tf.train.write_graph()�����档
5. ����ܹ�
�ڻ������ѧϰ�Ļ���ʶ��ϵͳ�У�ϵͳͨ���漰�������Դ�ʹ���ģ�顣���ȣ�ϵͳ��������Բ�ͬ�ɼ�Դ�����ݣ���Щ���ݿ��ܰ�������ͼ��ɼ��豸��������ͷ���ֻ�����ͷ�ȣ���ʵʱͼ�����ݣ�Ҳ���ܰ���������ͼ�����ݿ�����ȡ����ʷͼ�����ݡ�����ͼ�����Ԥ������ͨ�������������д�����������Ȼ����ԭʼ������ ���������ݼ��е��������������� TensorFlow��Keras �����ѧϰ��ܹ������������磨CNN�������û������ݼ�����ģ��ѵ������֤��
���� ��ɱ�ҵ������߱��Ĺ��ߺ������Լ����;��
6.1ʵ���豸��ʵ�黷��
��1��Ӳ����һ̨�ĵ��ԣ�һ̨�ķ�������
��2������ϵͳ������windows 11��
��3��������TensorFlow C API��ONNX Runtime��OpenCV��libcsv��Pycharm��
�ߡ� ��������Ҫ�Ρ�������ʱ�䰲��
��һ�Σ�ѧϰ���������ѧϰ������ϣ��˽��й����ѧϰ����չ���ƣ�ȷ��ϵͳ���������������ĵ��飬ͨ���������о�ȷ����һ�ε�ʵʩ����Ϥ�������ߡ���ɿ��ⱨ�棬רҵ�����룬��װ����Ϥ��������(��1-2��)��
�ڶ��Σ���Ҫ�����Ƕ���֯�ṹ�빦�ܽ��з���������ϵͳԭ�������ݿ�Ĵ�����ͨ���Թ������ݵķ��������ϵͳ����Ʒ�������3-5��)��
�����Σ���Ҫ������ȷ��ϵͳ��������Ʒ������滮��ϵͳ���ܣ�ȷ���������ݵ���֯��Ȼ�������ϸ��ƣ�����־�ļ��ռ����û���Ϊ�����Ϳ��ӻ�������ƣ���6-11��)��
���ĽΣ����ƽ�����ƣ���������ϵͳ�ļ��ɣ������ĺ͵������ﵽԤ����Ҫ���Ŀ�꣬��ϵͳģ����е��ԣ�����ϵͳ�����������ݵ�����������ı�ҵ����(��12-16��)��
