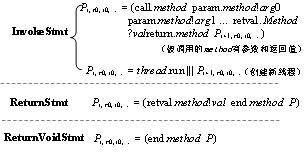| 设计 任务书 文档 开题 答辩 说明书 格式 模板 外文 翻译 范文 资料 作品 文献 课程 实习 指导 调研 下载 网络教育 计算机 网站 网页 小程序 商城 购物 订餐 电影 安卓 Android Html Html5 SSM SSH Python 爬虫 大数据 管理系统 图书 校园网 考试 选题 网络安全 推荐系统 机械 模具 夹具 自动化 数控 车床 汽车 故障 诊断 电机 建模 机械手 去壳机 千斤顶 变速器 减速器 图纸 电气 变电站 电子 Stm32 单片机 物联网 监控 密码锁 Plc 组态 控制 智能 Matlab 土木 建筑 结构 框架 教学楼 住宅楼 造价 施工 办公楼 给水 排水 桥梁 刚构桥 水利 重力坝 水库 采矿 环境 化工 固废 工厂 视觉传达 室内设计 产品设计 电子商务 物流 盈利 案例 分析 评估 报告 营销 报销 会计 |
|
|
|
| 首 页 | 机械毕业设计 | 电子电气毕业设计 | 计算机毕业设计 | 土木工程毕业设计 | 视觉传达毕业设计 | 理工论文 | 文科论文 | 毕设资料 | 帮助中心 | 设计流程 |
您现在所在的位置:首页 >>毕设资料 >> 文章内容 |
HashMappolicy中出现的类是从实际的类文件中逐项加载的。然后,逐个解析类文件中的方法。对于每种方法,从哈希表中提取对应的路径标识和路径段,节点处理有三种情况: 1)如果它与源类型匹配,则会找到相应的状态变量,并在其前面插入控制代码,这样可以在运行时激活对指定路径的监视。 2)如果与分支类型匹配,则找到当前位置的下一个分支。对于不同的后续路径,根据第III-D节中的表I,在后续目标路径的第一个语句之前插入相应控制代码。如果节点不是第一个重复节点(sn’=-1),则表示该节点已被处理,可以忽略。 3)如果它与释放点类型匹配,则会找到相应的语句,并在该语句之前插入控制代码,从而可以执行信息流控制和审核。 在路径中,一个方法可以调用多次。newinvoke类型用于将当前插桩位置更新到方法的开始。为了节省空间,省略了算法1和2中关于newinvoke节点的细节描述。 通过遍历HashMappolicy完成相关类文件的代码插装后,可以获得一组新的类文件。然后,将所有新类文件重新打包到.dex文件中,以替换原始APK文件中的.dex文件。使用压缩包,可以生成新的APK文件。 图1.5显示了InsecureBankv2的代码插桩示例。此图中仅保留插桩节点前后的语句,并省略部分分支节点的插桩。可以发现,插入的代码实际上是函数调用代码。考虑到项目的层次结构和接口,将实际操作所需的函数封装到单独的类中。在实际运行过程中调用这些函数,就可以实现相关的功能。
图1.5 代码插桩 1.5 运行监控 通过代码插桩,可以在应用程序正常运行时实现信息流控制。本节介绍了具体的控制原理。虽然在循环结构中重用和重新计算敏感信息并不常见,但为了保证FSAFlow的鲁棒性,我们考虑了敏感信息在循环或嵌套循环中的传播。以图1.6所示的代码片段作为示例来说明运行时控制机制。 如果使用IFDS算法分析该示例,则在其从s2到s5三次遍历循环体后,将找到程序N*中的节点<s3,td>, <s3,in>, <s3,a>, < s3,b>, <s3,c>。当IFDS第四次尝试遍历s3时,它将发现没有可用于路径扩展的新节点。然后,IFDS停止遍历循环体并继续遍历s6。最后,它将输出路径s0-s1-s21-s31-s41-s51-s22-s32-s42-s52-s23-s33-s43-s53-s6(sin表示sin的第n次执行),而实际执行路径是s0-s1-s21-s31-s41-s51-s22-s32-s42-s52-s23-s33-s43-s53-s24-s34-s44-s54-s6,这将导致信息泄漏并导致IFDS中的信息漏报。事实上,所有静态信息流分析技术都可能面临这个问题。
图1.6 循环结构中敏感信息传播代码片段 为了更好地处理这个问题,污染传播过程沿着路径分为三个阶段:1)前向传播阶段(N):执行的语句在循环之外,对应于s1和s6的执行阶段。2) 循环传播阶段(P):执行语句在循环体中。根据IFDS,在当前循环中仍然存在与“s21-s31-s41-s51-s22-s32-s42-s52-s23-s33-s43-s53”的执行阶段相对应的新节点扩展。3) 循环稳定阶段(S):执行语句位于循环体结构中。根据IFDS,当前循环中没有新的节点扩展。IFDS不再跟踪该时段的执行,其对应于" s24-s34-s44-s54"的执行阶段。 虽然IFDS没有分析S阶段以避免路径长度爆炸的问题,但它仍然达到了良好的精度。然而,对S阶段的进一步监测是有益的。如果存在包含S阶段的泄漏路径,则会导致IFDS中出现信息漏报。因为STA很难确定S阶段中实际执行的循环次数,所以对S阶段使用过精确的STA算法很容易导致过多的开销。因此,需要一种更有效、更合理的方法来解决这一问题。在执行进入循环的S阶段之前,它已经经历了P阶段,并通过污染累积达到了最大污染状态。因此,在S阶段内循环的同一代码段的重复执行往往趋于稳定,以保持循环的最大污染状态。实际上,循环中的代码可能是重复的逻辑行为,如科学计算、文件读取和写入等。路径的执行通常不会改变P阶段的最终传播状态。因此,这些路径仍然有效,但它们在传播中是不起作用的。FSAFlow继续监控稳定期以确保安全第一,在大多数情况下,它仍然只监控关键分支节点,以确保性能和正确性,如表IV所示。在少数情况下,S阶段可能出现误判。此时,对该路径的监控策略进行修改,不再监控其稳定期以减少误判。
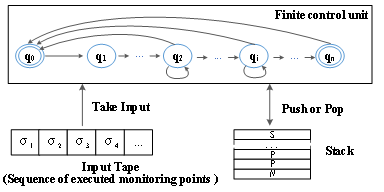
图1.7 路径控制自动机模型 FSAFlow实现了基于下推自动机的路径控制,下推自动机是有限状态自动机的扩展,由状态控制器、输入和堆栈组成。如图1.7所示,在形式上,给定静态分析输出的路径path,并假设其长度为N,则运行时对应的自动机表示为M= 1)Q是一组有限的状态。path上的每个节点i对应于状态qi(i>0)。q0对应于路径的非活动状态;q1对应于源点,qn对应于释放点。 2) 3) 4) 5) 6)F:{q0, qn} 表1列出了M的转换函数。M从状态q0和空堆栈开始。执行源语句后,它达到q1状态并进入N阶段。在N阶段,当遇到诸如If/Switch之类的分支跳转时,如果跳转目标指向路径中的下一个节点,则状态将向前更新一步;当遇到While/For循环时,M将进入P阶段,如果跳跃目标和目标路径点都需要进入循环体,则状态向前更新一步。在P阶段内,当遇到分支跳转时,如果跳转目标指向path中的下一个节点,则状态将向前更新一步;否则,当路径中的下一个节点指向循环出口分支时,如果分支跳转再次进入循环体,M阶段将进入S阶段。在这种情况下,在执行达到关于路径的污染传播的最大值后继续执行循环体。在S阶段内,不会跳出循环体的分支将被连续监视,并且路径状态保持不变。当遇到跳出循环体的分支时,M将弹出堆栈,并将堆栈指示的最后一个阶段恢复为当前阶段。然后,根据不同的阶段要求继续跟踪和监控。在P或S阶段,如果M通过区分循环ID确定进入不同的循环,则将发生循环嵌套。在这种情况下,新阶段信息将被推送到堆栈中,并且新阶段的分配与当前阶段的分配相同。如果遇到其他情况,M将返回到q0状态并清除堆栈。 表1 M的转换函数
a. FSAFlow利用全局变量记录所有受监督路径的执行状态和堆栈。如图1.6所示,本节示例有四个监控点。这些监测点的主要控制代码如图1.8所示。
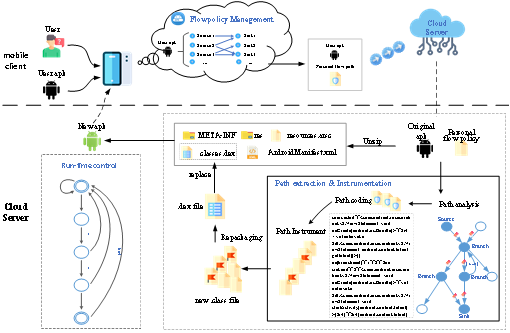
图1.8 代码插桩 如果执行到达相应源点的监视点,FSAFlow将检查执行是否与所需状态匹配。如果是这样,FSAFlow将限制源点的执行。如果拦截的敏感数据是数字,则该数据被分配为0。如果拦截的敏感数据是字符数据,则首先将字符替换为0的ASCII码。为了防止利用敏感数据的长度进行隐蔽通信,进一步调用随机数生成API来随机确定清除字符数据的长度。最后,为了不影响程序的正常功能,将净化后的数据传递到源点执行。此外,将向用户提示拦截的信息,如图1.9所示。当然,存在各种隐蔽通道,例如使用泄漏频率进行通信。在未来的工作中,FSAFlow被认为与隐藏信道带宽限制和阻塞机制相结合,以实现更安全的拦截。
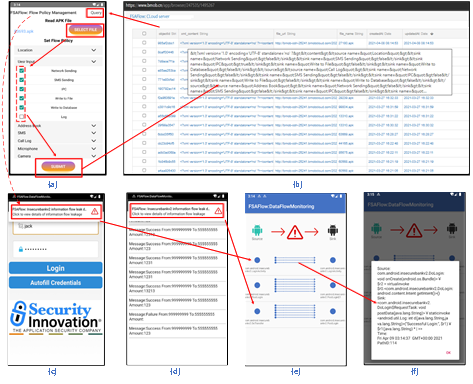
图1.9 FSAFlow组件实现 1.6 系统实现 图9显示了FSAFlow系统每个组件的完成情况。客户端和服务器之间的交互采用WebSocket协议和全双工模式,提高了系统的稳定性和可用性。 云服务器采用Java开发,JDK版本为1.8。静态路径分析模块是通过修改FlowDroid开发的,总共修改了2000多行代码。FSAFlow的路径监控插桩框架是在soot平台上开发的,其中Jimple提供的3地址代码的中间表示和精确调用图分析框架为FSAFlow系统奠定了重要的基础。同时还使用了Dexpler插件和Heros框架。客户端应用程序可以在最新版本的Android上运行。 图9(a)显示了FSAFlow的用户定义信息流路径管理界面。实现了选择目标APK文件、选择信息流源点和释放点的功能。如图9(b)所示,提交到云服务器进行处理后,可以通过query功能下载新的APK文件。以InsecureBankv2为例,处理后的APK文件的运行如图9(c)-(f)所示。在敏感信息被信息流泄露之前,它将受到限制,并在成功拦截后向用户发送通知,如图9(c)-(d)所示。用户可以单击通知以查看泄漏路径的详细信息,如图9(e)-(f)所示。 2. 基于分布式策略的组件级信息流细粒度控制技术 信息流跟踪技术能否应用于用户隐私保护的关键在于能否在跟踪技术的基础上实现信息流控制。在本文提出的基于有限自动机的轻量级信息流路径跟踪优化技术的基础上,已经具备了在路径的释放点处的初步信息流控制实现条件。移动应用程序中往往集成了大量的第三方组件,其内部信息流十分复杂,可能包含各种未知的隐式信息流,给信息流控制带来了巨大的挑战。对于应用程序内集成的不同第三方组件,往往其安全需求也不相同。本章提出了一种基于细粒度跟踪优化的不可信组件分布式信息流控制技术,借助细粒度的静态信息流分析和插桩技术,在动态运行时实时调整安全标记,实现了对Android应用程序敏感信息流的实时控制。 2.1 模型设计框架 以保护用户隐私为出发点,本章提出的信息流控制系统框架如图2.1所示。
图2.1 信息流控制系统框架图 首先对某个待处理的应用程序,利用经典的静态信息流分析工具flowdroid,对其进行全面的分析处理,找出所有的敏感信息源和敏感信息泄露点,以及在敏感源与泄漏点之间的敏感信息泄露路径。 在利用flowdroid进行信息流泄露路径扫描时,通过对扫描过程和扫描细节的控制,不但得到了程序变量级的信息流传播路径,还得到了组件级的信息流传播情况。程序变量级的信息流传播路径,一部分处于某些组件内,一部分不属于某个具体的组件。这种对信息流变量间细粒度传输情况的挖掘,为下一步通过插桩实现信息流控制奠定了基础。涉及到敏感性信息的信息流路径,无论是否属于某个组件,同样都能够得到控制。 组件间通信的方式主要有startActivity,getIntent,Call和Reflection等。对于可信的组件,采用细粒度的信息流跟踪控制。对于不可信的第三方组件,此时将会被单独筛选出来,便于后续的插桩处理。在flowdroid得到的信息流中筛选出与不可信第三方组件相关的信息流路径,并结合扫描到的组件接口,得到需要进行控制的精确位置。 在组件接口处插入的控制代码实现了分布式信息流控制模型的安全标签建立,标签调整,策略判断即信息流拦截等功能,是处理过的应用程序能够在运行时实现分布式信息流控制功能。 2.2 信息流控制模型提出 2.2.1 分布式信息流控制策略 定义标记、标签、source、sink按照现有关于信息流控制模型相关研究的形式,本文所提出的信息流控制模型由标记(tags)和标签(lables)组成。应用程序中的数据所有者组件被称为data owner(O)。数据所有者能够以安全标签d的形式为其敏感数据定义一个安全类别,这样的一组标签d就构成了一个安全标记S。按照信息流控制模型的安全性要求,具体来说,假定应用程序中的两个组件P和Q的安全标记分别为SP和SQ,当且仅当SP⊆SQ时,信息流才能够从P流向Q。本文提出的信息流控制方法严格执行这种DIFC规则。 每个安全标签d都具有被命名为d+和d-的相关功能,用于升密和降密。数据拥有者组件可以将调整安全标记的功能授权给其他组件(即委托能力集CP)或者全部其它组件(即全局能力集G)。在任何时候,组件P都有一个有效的能力集,由CP和G中的能力组成。P可以通过添加标签d将其安全标记SP更改为SP+,当且仅当d+∈CP∪G。类似地,P可以通过减去标签d将SP更改为SP―,当且仅当d―∈CP∪G。 如果某个网络接口组件N是不可信的,它将具有一个空的安全标记,即SN={}。此时,组件P必须具有一个空标记SP={}或具有将自己的标记改为SP={}的能力,才能够建立网络连接,即∀d∈SP,d―∈CP∪G。 集合 对于主体 主体能力取自产生该主体的可执行客体属性,由授权管理员设置和管理,在主体创建时由系统读取和载入。我们用 2.2.2 控制策略标签调整 信息在组件间流动时需要遵守安全信息流动条件。我们给出信息安全流动的定义: 定义1规则:从组件实体
在消息流动后,
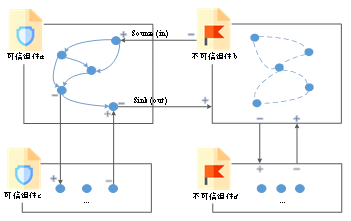
安全的信息流动需要同时考虑信息流出方的发送能力和信息流入方的接受能力,如定义1所示,低保密级的信息向高保密级流动并实施污点传播。从便于实际应用考虑,这里规定信息流出方 考虑如图2.2所示简易的组件间信息流模型,主要分为可信组件间的信息流传播,可信组件与不可信组件之间的信息流传播以及不可信组件之间的信息流传播。针对每个组件,定义了source和sink,分别表示组件信息的流入(in)和流出(out)。
图2.2 组件间信息流传播 假定可信组件之间的信息流动可以不受限制,不可信组件之间的信息流传播,无论是接收还是发送都需要进行控制,而可信组件可以接收不可信组件传出的信息流,不可信组件接收可信组件传出的信息流时需要受到控制。则不同类型组件之间的信息流传播情况可表示为以下几种形式: 1)可信组件a与可信组件c互相之间可以进行读写等操作而不受严格的控制,其安全标记不发生变化。(属于变量级控制 未设置标记) 2)当不可信组件b发送信息给a时,当且仅当 3)可信组件a与不可信组件b之间需要满足a可读或可动态加载b,但是a不可对b进行写操作。此时a与b的安全标记需要满足 4)不可信组件b与不可信组件d之间的信息流传播,当且仅当 根据安全需求,假设组件a中某处出现不允许发送给不可信第三方的高保密等级敏感信息,则此时在系统中为组件a创建安全标签 2.3 信息流控制系统实现 本章提出的分布式信息流控制技术依靠flowdroid工具的静态分析技术和soot工具的插桩技术实现。首先利用flowdroid对目标应用程序进行分析,扫描得出所有常规和可信组件的信息流传播路径以及不可信组件的入口点和出口点,再调用soot框架将控制代码插入应用程序内相应位置,形成新的apk文件,此时新生成的应用程序能够在运行时实现分布式信息流控制。 2.3.1 静态分析 本文第三章中提出的FSAFLOW对flowdroid进行了优化,本章同样利用这一优化方法对目标应用程序进行静态分析。本章提出的分布式信息流控制方法需要对可信组件和常规信息流进行细粒度的跟踪分析,而对于不可信的第三方组件,只需要扫描出该组件的入口点和出口点信息。 关于静态分析算法已在第三章进行了详细描述,本章不再赘述。根据静态分析的约束条件,需要对静态分析部分进行预定义,通过指定不可信组件的类名或方法名,使静态分析对不可信组件不再进行细粒度的跟踪分析,只记录该第三方组件的入口点和出口点,剥离出第三方组件。在报告信息流路径时,将入口点和出口点分别作为该第三方组件的source点和sink点,只有按照常规的信息流路径格式完成报告。一般来说,应用程序内集成的第三方组件往往数量较少,不会对静态分析的预定义造成较大难度。 静态分析过程完成后,输出带有source、branch和sink标记的路径信息以及函数调用返回信息和以第三方组件的入口点和出口点为source和sink点的信息流路径信息,并将所有信息写入路径文件。本文提出的信息流分析方法是建立在Jimple中间语句上的,因此此处的输出路径也由Jimple代码语句进行表示。此外,根据类、方法和路径标识,通过多级哈希表对所有路径进行分层统一管理,保证每个参与的类和方法只遍历一次。后续的代码插桩工作在此基础上进行。 2.3.2 控制代码插桩与控制 本章的控制代码插桩方法扩展了soot框架,能够遍历所有方法体的语句,并在指定位置插入监控代码。算法2-1详细描述了代码插桩的过程。首先,将逐项读取哈希表HashMappolicy中出现的类名,以查找与之匹配的类文件。然后逐个解析类文件中的方法。对于每种方法,从哈希表中提取相应的路径标识和路径段。路径段上的节点处理有以下几种情况: 1)如果节点与source类型匹配,则定位相应的语句并在其后面插入控制代码,这样可以在程序运行时激活对指定路径的监视。 2)如果节点与branch类型匹配,则定位当前位置的下一个分支语句,然后在该语句之前插入控制代码,以便在程序运行时更新路径的监视状态。 3)如果节点与不可信第三方组件入口点或出口点类型匹配,则定位当前语句并在该语句前插入控制策略标签调整代码,从而实现对第三方组件的分布式控制。 4)如果节点与sink类型匹配,则定位相应的语句并在该语句之前插入控制代码,从而可以执行信息流路径的验证审计。
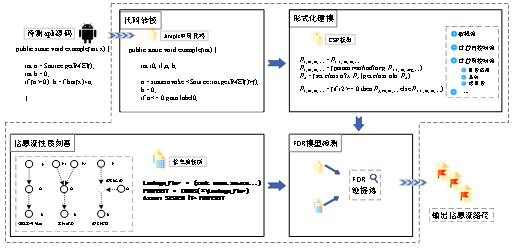
通过遍历HashMappolicy完成相关类文件的代码插装后,可以获得一组新的类文件。将所有新生成的类文件重新打包到.dex文件中,以替换原始APK文件中的.dex文件,即可生成新的经过安全增强,能够进行运行监控的APK文件。 静态插桩阶段插入的代码实际上是函数调用代码。考虑到项目的层次化和接口化,实现信息流分布式控制功能的相关代码都被封装到单独的类中,在实际运行过程中调用这些函数即可实现相关运行监控功能。控制代码封装类的参数包括安全标签中的安全标记S和能力C等,其基本格式为DIFC_control_logic(pathID, S1, S2, C),其中S1和S2分别表示形如{ 3. 基于通信顺序进程的Android程序复杂信息流分析技术 信息流分析技术中采用的污点跟踪方法,分别从静态、动态或动态与静态混合的方向入手,将信息流分析问题抽象为可达性问题,最终获得可达性信息流路径结果。这种只对信息流处理可达性问题的分析方式具有一定的局限性,无法处理复杂信息流。例如,在针对多污点源的信息流分析,以及存在反射的信息流分析问题时,这一类信息流分析方法往往很难给出复杂的信息流分析结果。为了弥补传统信息流分析方法和现有形式化分析方法在复杂信息流分析方面存在的不足,本文提出了一种基于通信顺序进程CSP的Android程序复杂信息流分析方法,其核心思想是利用CSP对信息流传播过程进行建模,利用形式化的方法,更加详细地刻画出复杂信息流的传播过程,全面捕捉信息流行为,完成复杂情况下的信息流分析。 3.1 系统设计 本文提出的基于通信顺序进程的Android程序复杂信息流分析方法,是基于将应用程序的信息流传播过程用CSP模型进行建模而完成的,在此基础上,再进行信息流行为提取,判断是否存在敏感信息泄露,最后报告敏感信息流路径。整体工作流程和系统框架如图3.1所示。
图3.1 系统框架 首先对目标APK文件进行分析和代码转换,将APK文件转换为中间表示形式再建立CSP模型。接下来需要建立CSP模型,刻画典型信息流性质。最后将目标应用程序的CSP模型和典型信息流CSP模型同时输入FDR(Failures Divergence Re-finement)检测器进行检测,获得信息流路径的进程报告。 由于Java源代码和Java字节码中的语句类型非常复杂,因此快速有效地提取代码中的信息非常重要。基于以上考虑,APK文件首先进行反编译,然后调用Soot转换成Jimple中间语言。Jimple具有语句类型少、类型清晰、三种地址形式等优点,有利于后续的形式化建模。 将Jimple语句转化为对应的CSP进程,即可完成对Android应用程序的正式建模。由于Jimple中只有15条语句,而且三个地址形式使语义非常清晰,因此将Jimple表示为CSP进程会更容易。每一个语句的过程范式都是建立在其特征的基础上的,是对代码行为的准确抽象表达。在此基础上提出了一个完整的Android应用程序模型。 最后,对于Android恶意软件检测,本文使用FDR模型检测器,这是一个应用于CSP的正式工具。对样本行为建模的CSP过程被认为是需要验证的过程,它被简化为只包含属性过程中出现的事件,最终结果作为断言测试(如果存在)的反例生成。 本文使用模型检测工具FDR对目标信息流进行形式化分析。该工具引入了迹(Trace)的概念,用可以执行的有限通信序列的集合表示进程。基于迹模型(Traces model),FDR用迹提炼(traces refinement)来定义两个进程之间的特殊关系。 如果存在两个进程P和Q,Q的所有特定行为对于P来说都具有,那么称Q提炼P,或Q是P的一个提炼,记为P Í Q。 进一步,将迹模型应用到提炼的概念中:如果Q的所有通信事件序列对于P来说也是可能的,即traces(Q) Í traces(P),那么称Q迹提炼P,或Q是P的一个迹提炼,记为P ÍT Q。 在对信息流进行FDR分析检测时,将P作为抽象每条目标信息流特有性质的进程,将Q作为建模目标APK文件样本中信息流行为的进程。 在一次测试中,只将一个样本的待测进程与一个信息流进程同时输入FDR检测器,在样本进程只保留该性质中事件的基础上,判断其是否是信息流进程的迹提炼。如果模型检测通过,则说明该样本具有该信息流类型所具有的性质,因此报告该信息流路径;否则即认为样本不存在该进程类型的信息流路径,可以继续将该样本进程与其他信息流进程进行测试。 3.2 CSP形式化建模 为了更加便捷高效地对信息流传播过程进行建模,本文引入了Jimple中间语言。这种基于soot框架的三地址中间表示形式,语句种类较少且每条语句最多只会出现三个量值,非常适合对Java语言的分析及优化。信息流传播中涉及到的Jimple语句类型如图2所示。
图3.2 15种Jimple语句(If/Goto语句为一组) 如果将一段Jimple代码视为一个整体系统,那么其中包含的每一条语句都是它的组成部分,都可以建模成一个CSP进程。语句的进程名称由带参数类型的完整方法名和下标组成,第一个下标是当前语句在方法中的编号,然后是当前方法中的所有非静态局部变量、方法所在类的所有非静态成员变量以及方法中创建的所有类对象的非静态成员变量,以便更好地表明变量值的变化。例如某方法的第i条语句对应的进程名为可以表示为Test_example(int)i, r0, i0, …,其中i的值不大于该方法的Jimple语句总数(从定义语句后开始计数)。将不同种类的Jimple语句转换成对应的CSP进程时,所有的进程均可以被命名为Pi, r0, i0, …的形式。 当涉及类的成员变量或成员方法的变量时,需要在两个进程间传递数据。若是对其进行赋值,例如“c.<Class: int a> = temp$1”对应的CSP进程为 Pi, r0, i0, … = (set.class.a!temp$1 ® Pi+1, r0, i0, …) 否则,例如“temp$1 = c.<Class: int a>”对应的CSP进程为 Pi, r0, i0, …, temp$1, … = (get.class.a?a ® Pi+1, r0, i0, …, a, …) 其中set.class.a!temp$1是输出temp$1作为class.a赋值的事件,get.class.a?a是接收class.a的值的事件。 本文为每个类建模一个进程来管理类中所有成员变量和成员方法中变量的值,同时,为每个实例化的类建立编号ID。若类class中有一个上述类型的变量a,则它对应的CSP进程为 P(ID, a)= (ID.set.class.a?x ® Px | ID.get.class.a!a ® Pa) 其中编号ID能够实现对类的记录,通过编号值区分不同类的成员变量和成员方法中变量的值。set.class.a?x是class接收x作为a的赋值的事件,get.class.a!a是class输出a的值的事件。 典型的信息流行为模式包括数据流、控制流、反射、虚函数等。基于对不同种类的Jimple语句进行CSP建模分析,本文分别建立起了五种信息流行为的CSP模型。 3.2.1 数据流行为建模 数据流行为可以认为是由NopStmt,IdentityStmt和AssignStmt这三种类型的语句进行组合的行为。NopStmt表示变量值未发生变化的语句,这条语句没有经过任何能引起变量值变化的事件,此时直接进入下一条语句的进程;IdentityStmt表示将参数值赋值给变量的语句,将调用语句中的实参传入被调用方法;AssignStmt表示变量的一般赋值语句,体现变量被感染的过程。对数据流行为相关语句建模如图3所示。
图3.3 数据流行为建模 其中IdentityStmt语句的两种模型形式分别对应与参数有关的变量赋值语句和与this引用有关的变量赋值语句,param.method?arg表示当前方法method接收实参arg的事件。对涉及参数的赋值语句,需要在调用语句和被调用语句之间传递实参。在多参数情况下,按序进行的参数赋值更便于查找输入值。 3.2.2 过程内控制流行为建模 本文将过程内控制流行为认为是由IfStmt/ GotoStmt, TableSwitchStmt, LookupSwitchStmt这三种类型的语句组合而成的行为。IfStmt/GotoStmt表示条件判断和跳转语句,能够指示满足判断条件时要进行处理的语句位置;TableSwitchStmt是表转换语句,用于switch分支的条件值分布比较集中的情况;LookupSwitchStmt是查找转换语句,用于switch分支的条件值分布比较稀疏的情况。对控制流行为相关语句建模如图4所示。
图3.4 过程内控制流行为建模 其中IfStmt/GotoStmt语句的第一种模型形式中的j是跳转目标的语句序号。为了得到j的值,需要在当前方法的后续语句范围内搜索该label标记。该进程不执行任何实际的事件,只是跳转到标号所在的语句进程继续执行。第二种模型形式的进程提供两个选择,如果IfStmt给出的判断条件成立,则按照相应label标记处的语句进程继续执行;否则按照下一条语句的进程顺序执行。 TableSwitchStmt和LookupSwitchStmt语句分别通过键值匹配和索引访问跳转表,模型中k是case分支的条件值,goto(k)是处理该情况的语句的起始编号。该进程表示在选择合适的case分支后,跳转到相应标号位置处继续执行。两种代码的形式完全相同,因此共享相同的CSP进程。 3.2.3 过程间控制流行为建模 过程间控制流行为包括函数调用行为,反射行为以及虚函数,本章将依次对这三种情况进行建模分析。 1)函数调用建模 本文将函数调用行为认为是由InvokeStmt,ReturnStmt和ReturnVoidStmt这三种类型的语句进行组合形成的。InvokeStmt表示调用语句;ReturnStmt指有返回值的返回语句,ReturnVoidStmt指没有返回值的返回语句“return”。对函数调用行为相关语句建模如图5所示。
图3.5 函数调用行为建模 其中对于InvokeStmt调用语句,当被调用的method有参数和返回值时,CSP模型中的param.method!arg0、param.method!arg1等表示向method依次传递实参的事件,retval.method?val表示从method接收val的事件,call.method和return.method分别表示method调用开始和结束的事件。当被调用的方法没有参数或返回值时,在进程表达式中去掉相应的事件,通过IdentityStmt语句进行实参接收。 新线程的创建过程也遵循InvokeStmt方法调用的形式,但是有所不同的是,它不需要像一般调用中那样等待被调用方完成后才能继续执行,因此具有如图中所示的新的CSP模型形式,其中thread.run指要创建的线程类thread的run方法对应的进程。 对于ReturnStmt语句的CSP模型进程,retval.method!val是当前方法method返回变量val的事件。该进程表示返回需要的结果后结束所在方法的此次执行,并回到方法开始处等待下次调用。 对于ReturnVoidStmt语句的CSP模型进程,用method表示当前方法,该进程不返回任何值,只用于结束所在方法的此次执行。 在对过程间通信行为进行建模时,需要考虑系统调用的同步机制。为了确保任意方法在同一时刻最多只能被另一个方法调用,用SYNM进程来描述系统的调用同步机制,如图6所示。系统调用同步机制模型由各个调用同步事件的控制进程SYNM_method组成,其中method指代被调用的方法,method1、method2等则是系统中不同的被调用方法。
图3.6 系统的调用同步机制 被调用方法有两个参数和一个返回值,每个方法的开始和结尾处分别设置了提示事件begin和end。由于方法的起始语句不确定,因此将begin事件额外作为第一个进程的前缀;而返回语句通常为方法的最后一条语句,因此将end事件放入返回语句的进程表达式中。由此得出method对应的CSP进程为method = (begin.method ® method1, r0, i0, …) 调用语句与被调用方法之间的同步关系如图7所示。在调用语句中,call和return事件将分别作为本次调用的开始和结束事件。SYNM进程的同步集是call、begin、end、return事件,被调用方法执行完毕后会将控制返回到InvokeStmt的下一条语句。
图3.7 InvokeStmt及被调用方法之间的同步 2)反射行为建模 反射行为作为Java语言独特的功能,能够在过程间信息流中动态获取信息并调用对象方法,需要单独进行建模分析。为了静态地解析反射,本文定义allclasses数组来记录程序中的所有类。反射行为中包含forName、getMethod和invoke三种比较重要的方法调用,每种方法调用的示例分别如图8-(a)(b)(c)所示。
图3.8 反射行为中的方法调用 对于图8-a中所示的forName方法的调用,在allclasses数组中查找名称为cla的值的类,并将其索引allclasses_index(cla)赋值给c,对应的CSP进程如图9-a所示。 对于图8-b中所示的getMethod方法的调用,在cla类的方法数组allmethodc中查找名称为send,参数类型为ARG_ type的值的方法,并将其索引m_index(“send”,ARG_type)&c赋给m,相应的CSP进程如图9-b所示。 对于图8-c中invoke方法的调用,主要负责反射调用的具体执行,CSP进程如图9-c所示。
图3.9 反射行为建模 程序中每个动态加载的方法都被记录下来后,构造相应的反射过程来控制方法的执行,如图10所示。
图3.10 构造反射过程 3)虚函数建模 虚函数调用以Java的继承机制为基础,也是Java语言一种独特的函数调用方式,因此单独进行建模分析。Java支持继承,允许创建层次类。子类不仅可以继承父类的特性和行为,还可以通过虚调用使用父类的方法。 与对反射行为的建模过程类似,同样要为程序中所有类依照从属关系建立一个数组allclasses来存储它们的父类。此外,还要为一个类c建立一个数组allmethodc来记录类中的所有方法名。 在处理调用语句时,首先检查被调用方法的类层次结构是否正确,如果正确,则根据上述规范对流程进行建模。否则,搜索其父类并依次执行,直到找到方法为止,并用模型中实际调用的方法名替换该方法。图11-a所示语句即为一个虚函数调用,getIMEI()方法在源类中不存在,但可以在其父类SourceFather中找到该方法。因此,相应的CSP过程模型如图11-b所示。
图3.11 虚函数建模 3.3 信息流性质刻画与验证 3.3.1 信息流性质刻画 在信息流泄露事件中,部分信息流行为模式普遍存在,是构成泄露事件的重要步骤。即使这些行为模式存在多种不同的具体实现方式,然而信息流传播逻辑相同,形式化表达方式也相同。因此本文将不同种类的信息流行为模式认定为信息流的性质,结合对典型信息流行为模式的建模,刻画出泄露事件的信息流性质。 首先,为了简化FDR模型检测的复杂程度,对CSP模型中与信息流传播不相关的代码行为进行隐藏,流程为:uselessevents={|transfer,calldeal,api.normalx|},SAFE_SAMPLE=SAMPLE\uselessevents。接下来定义信息流发生泄露的性质为:PROPERTY=source.taint->sink.taint->STOP。基于上述对简化信息流CSP模型和信息流泄露性质的定义,得出在CSP模型中发现信息流泄露路径的方式为:assert SAFE_SAMPLE [T= PROPERTY。 最终结果作为断言测试的反例生成,当判定结果为真时,则认为存在信息泄露行为,并且FDR模型检测工具能够报告出满足判定结果为真的信息流路径,该路径即为本方法所求的目标信息流泄露路径。当此处判定结果为假时,则说明不存在信息泄露行为。 基于以上信息流性质和泄露路径提取方式,本文针对典型信息流分析过程,建立了细化的信息流检测CSP模型与FDR验证方法。 1)待分析程序中含有多个敏感信息源(source)和敏感信息泄露点(sink)时,例如将地理位置、麦克风、通话记录信息等认定为敏感源,将网络发送、短信发送、写入本地文件等认定为敏感信息泄漏点。为了找出从所有source点到所有sink点的信息流,即找出所有可能存在的隐私敏感信息泄露路径,本文提出如下CSP模型检测方法:Leakage_Flow ≡(sink.{sinklist}.taint.{sourcelist}|sinkList<-{1..MAX}, sourcelist<-{1..MAX});PROPERTY ≡ CHAOS(Σ\Leakage_Flow);PROPERTY [T= Assert SYSTEM。此方法将从所有source点出发到达所有sink点的信息流路径作为系统CSP模型的迹提炼输出,能够得到覆盖所有source点和sink点的信息流路径。 2)针对某应用程序进行分析时,有需要挖掘从指定source点到指定sink点的信息流路径的需求,即信息流定向搜索需求。例如,针对地理位置信息,搜索是否存在以地理位置信息为敏感源,以写入本地文件为泄漏点的信息流路径,就属于信息流定向搜索。本文针对此类情况提出如下CSP模型检测方法:Leakage_Flow ≡ (sink.sinkx.taint.sourcex);PROPERTY ≡ CHAOS(Σ\Leakage_Flow);PROPERTY [T= Assert SYSTEM。此方法通过将确定的source点和sink点引入模型检测过程,完成定向搜索功能。 3)在恶意应用程序中,某条信息流同时包含多个敏感信息的情况也比较常见,即一条信息流路径同时被多个敏感源感染,有多个source点。例如,恶意软件可能将通话记录和通信录以及其他非敏感信息打包,经过一条信息流路径,向网络发送。这种多污点聚合类的信息流分析对于传统的静态信息流分析工具也是不小的挑战。本文针对此类多污点聚合发送的信息流分析问题提出如下CSP模型检测方法:Leakage_Flow ≡ (sink.taint.{sourcelist}|sourcelist<-{sourcea,sourceb,sourcec…sourcen});PROPERTY ≡ CHAOS(Σ\Leakage_Flow);PROPERTY [T= Assert SYSTEM。此方法针对指定的sink点,对n个source点进行迹提炼,从而挖掘出多污点聚合发送复杂信息流路径。 4)由控制行为触发的复杂信息流路径是传统静态信息流分析的难点,控制行为对信息流分析产生的影响在进行静态分析时很难识别。当某条信息流需要控制行为才能触发时,例如,当用户点击发送某张图片时,触发泄露地理位置信息,产生了传统静态分析方法无法识别的信息流。本文针对这种情况提出如下CSP模型检测方法:Leakage_Flow ≡ (sink.event.taint.source|event<-{button.click.OK});PROPERTY ≡ CHAOS(Σ\Leakage_Flow);PROPERTY [T= Assert SYSTEM。 形如上述类型的复杂信息流分析模型,都能够转化为以CSP模型描述的信息流性质,进而应用到模型检测中实现信息流分析挖掘功能。 在实际应用中,往往不是针对应用程序的源码进行分析,而是只有APK文件资源。此时需要首先调用SOOT框架,直接将APK文件转化为Jimple中间代码形式,再进行后续CSP建模和FDR模型检测分析。 3.3.2 信息流性质验证 本文使用精化检测工具FDR对建立的形式化模型进行分析。FDR已广泛应用于学术界和工业界,在协议漏洞挖掘、软件安全性验证、数学逻辑运算方面获得了成功应用。FDR实现了CSP的三个验证模型,依次是:迹模型(trace model),稳定失败模型stable failures model和失败/发散模型(failures/ divergences model),三个模型验证进程间等价性的程度和需要验证的状态空间个数都是递增的。失败稳定模型可以验证非确定性(non-deterministic)行为,例如验证活性。失败/发散模型避免因进程加入屏蔽算子导致的发散对分析带来的影响,实际上,如果不是实际的存在发散迹,而是用于验证分析的出现发散迹,则发散攻击是不存在的,不一定要求发散迹也等价。而且迹模型可以对“不存在违背某个安全性质的反例”之类的断言进行验证。所以本文选取迹模型作为验证模型,降低复杂度且能满足本文的安全性性质要求。 FDR内部通过有限状态系统等价性分析验证断言的正确性,主要分析复杂信息流的可达性和关联关系。对于单个污点源,假设程序的变量个数为m,语句个数为n,则程序的CSP进程对应的有限状态机的状态个数最大为2m,每个状态的出度最大为n。FDR的精化算法采用互模拟等价原则分析程序的有限状态机M1和安全属性的有限状态机M2之间的等价包含关系。首先选择程序运行时的初始状态然后递归分析,对于M1中的每个状态q10,查找M2中是否存在等价状态q20,则查找复杂度为2m, 对于每一个备选的q20’,验证所有从该状态的出边是否等价,则验证复杂度为n。所以最坏情况下总的计算开销为n*22m,假设做k个不同污点源复杂信息流分析,则最坏情况的计算开销为n*22mk。 具体实现时,FDR采用了很多高效的方法进行了优化,例如状态可达性分析,只分析从初始状态可达的状态;状态压缩技术,包括explicate(枚举),sbisim(强节点标记互模拟),tau_loop_factor(循环消除),diamond(菱形消除),normalise(标准化)和model_compress(语义等价分解)。在本文研究的信息流复杂性分析中,1)一般程序全局/静态变量相对较少,大多数变量都是局部变量,离开了所在函数,这些局部变量没有意义,意味着绝大部分的状态变迁根本不会发生。2)每条语句通常只会影响0到几个少量变量的状态变化,意味着状态机中,总的边数通常不会超过10n。所以这些优化技术可以极大的降低信息流分析的复杂度。另外,大部分的信息流性质验证公式都验证的是作用了隐藏算子后的进程等价性分析,这其实是弱互模拟等价分析。验证所有从该状态的出边是否等价时,复杂度进一步大幅降低。本文的实验也表明了FDR在验证具体的信息流分析实例时具有良好的性能。 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
尚未解决的问题, 下一步的工作计划 |
(1)完善基于有限自动机的轻量级信息流路径跟踪优化技术的实验评估,形成闭环系统。(2021.09完成) (2)完善基于分布式策略的组件级信息流细粒度控制技术的模型,并对其进行充分的实验评估。(2021.09完成) (3)对提出的基于通信顺序进程的Android程序复杂信息流分析技术进行进一步完善,并进行充分的实验评估。(2021.09完成) (4)完成毕业论文撰写。(2021.10完成) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
取得 成果情况 |
1、 学术论文发表情况 (1)A Noninterference Model for Mobile OS Information Flow Control and Its Policy Verification. 《Security and Communication Networks》,2021年8月,已出版,SCI检索(000693886900001),第一作者。 (2)基于通信顺序进程的Android程序复杂信息流分析方法,《网络与信息安全学报》,2021年10月,已出版,2021年第7卷第5期,第一作者。 (3)基于路牌机制的Android敏感信息流分析方法,《电子学报》,2021年7月,在审,第一作者。 (4)FSAFlow: Lightweight and Fast Dynamic Path Tracking and Control for Privacy Protection on Android Using Hybrid Analysis with State-Reduction Strategy. The 43rd IEEE Symposium on Security and Privacy (IEEE S&P 2022),2021年4月,大修后再审,第二作者。 2.产品研发(程序设计等)情况 程序设计进展顺利,能够按计划如期完成。 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
一、基本情况 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
论文题目 |
基于信息流的移动智能终端隐私保护关键技术研究 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
研究方向 |
移动智能终端隐私保护 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
题目来源 课题名称 |
国家重点研发计划-面向智能移动终端的用户个人隐私保护技术的研究 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
题目来源 课题层次 |
国家级 |
军队 |
市级 |
自选 (横向、校级) |
有无合同 |
经费数 (万元) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
√ |
有 |
273 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
题目来源 课题性质 |
理论研究 |
应用基础 研究 |
应用与理论结合研究 |
开发性 研究 |
综合性工程项目 |
其它 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
√ |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
课题进展情况 |
本课题按开题报告所预定的内容及进度顺利进行,课题进展情况正常。目前已经在开题文献阅读的基础上,对Android隐私保护与信息流分析技术进行了深入研究,挖掘出了信息流分析技术应用于隐私保护领域时存在的问题,并初步提出解决方案。 以保护用户隐私的现有相关技术作为切入点,经过分析得出基于信息流分析的隐私保护技术是目前最理想的解决方案。为了解决信息流分析面临的性能开销过大,跟踪逻辑部分与程序运行分离不彻底等问题,对信息流跟踪分析技术进行了深入研究,提出了基于有限自动机的轻量级信息流路径跟踪优化技术。以此为基础,已经具备了在路径的释放点处的实现初步信息流控制的条件。接下来,为了将用户的隐私保护落到实处,对信息流控制进行了深入研究,提出了一种基于细粒度跟踪优化的不可信组件分布式信息流控制技术,借助细粒度的静态信息流分析和插桩技术,在动态运行时实时调整安全标记,实现了对Android应用程序敏感信息流的实时控制。 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
解决问题的方法和已解决的主要问题 |
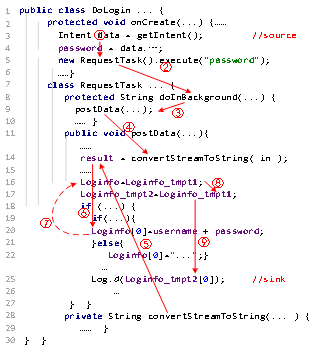
实现智能移动终端的隐私泄露检测与防护对于网络空间安全意义重大,前景可观。一方面,成型的隐私泄露检测与保护系统可广泛应用于政府机关、军队、企业等高安全需求人员相关的智能设备,为杜绝由使用终端的录音、摄像功能,使用移动应用软件及相关服务引起的各类信息泄露提供技术支持,满足相关领域对敏感数据保护的需求,保障信息安全,社会效益显著。另一方面,以部署到智能移动终端为目标,保护普通用户的安全隐私需求,研究成果具有良好的实用价值和推广意义,可有效弥补现有移动操作系统的不足,降低由于个人信息泄露和滥用带来的经济损失和潜在风险,引领移动应用市场与行业的健康发展,市场潜力巨大。 本课题以保护用户隐私的现有相关技术作为切入点,分析得出基于信息流分析的隐私保护技术是目前最理想的解决方案。针对Android应用程序的信息流分析技术对信息流的跟踪分析往往开销较大,对第三方组件的跟踪往往无法完成或粒度较粗,对复杂信息流难以分析。为了使信息流分析技术能够真正实际应用到用户的隐私信息保护中,针对现有相关研究中存在的亟待解决的问题,本课题进行了以下研究: 1.基于有限自动机的轻量级信息流路径跟踪优化技术 尽管在各种安全应用中动态污点分析(DTA)已被证明是有效的,但可用的DTA原型所实现的低性能影响了它们被生产系统广泛采用,尤其是计算和存储资源有限的Android系统。同时,由于DTA的低代码覆盖率,其误阴率也很高。 为了克服DTA性能开销的瓶颈,目前的研究工作旨在将污染跟踪逻辑与程序执行解耦。基于这一研究方向,这项工作提出了一种新型的混合污染跟踪和控制系统FSAFlow,以显著减少DTA开销,同时确保Android隐私保护的良好效果。在FSAFlow中,将路径跟踪逻辑与相应的污染跟踪逻辑进一步分离,并优化了信息流路径的控制。具体地说,首先实现了潜在敏感信息流路径的全程序静态搜索,并用关键节点序列对搜索到的路径进行抽象,从而在程序控制流图中高效、唯一地识别目标路径。然后,选择违反用户预定义隐私保护策略的潜在路径,并使用有限状态自动机(FSA)对这些路径的状态进行编码。在FSA的基础上,路径监控和控制的嵌入使用了轻量级的检测工具,将不受信任的程序转换为策略执行程序。最后,程序在FSAFlow的监控下运行,动态防止不符合策略的数据泄漏,并且可以输出完整路径进行取证,无需日志分析。 1.1 问题提出 本节通过提供InsecureBankv2的一段具体示例来说明一种典型的数据泄漏行为。以得出本项研究的出发点。InsecureBankv2由Paladion Inc.开发。此应用程序中故意保留一些安全漏洞,使其容易受到攻击,专门用于评估信息流分析工具的效率。并且,该程序设计的一些数据泄漏行为与实际应用中的基本相同。 图1.1显示了InsecureBankv2的代码片段。首先,在onCreate方法中,可以将data隐私数据的初始位置(第3行)视为敏感信息源。隐私信息最终流向log方法(第25行),该方法可视为敏感信息释放点。此代码在日志中打印,很容易发生泄漏,这显然是一个严重的隐私泄露问题。
图1.1 InsecureBankv2代码片段 众所周知,安卓系统目前无法防止此类信息泄露。Android的权限控制机制只决定应用程序可以根据用户的选择访问哪些源(如位置、麦克风、IMEI等)或释放点(如写入文件、发送到网络、发送消息等)。Android系统通常会给出“是否允许程序读取位置信息”等提示,但无法提供控制数据从源到释放点传播的机制,也无法提供“是否允许程序将位置信息写入文件”等信息流控制策略。信息流策略对于隐私保护非常重要。 由于商业利益或不受信任的第三方组件,一些热门的应用程序,如即时通讯、照相机和导航软件等,不仅使用隐私数据来完成正常功能,而且在不通知用户的情况下传播隐私数据。在这种情况下,需要对信息流进行跟踪和控制,以防止超出正常功能的泄漏路径。然而,目前的信息流分析和控制方法存在以下问题: 1)这种泄漏路径可以通过传统的静态地层流动跟踪和控制方法找到,但在log.d上采取何种控制措施尚不清楚。在图1中,有两条路径汇聚到该释放点。一条路径包含代码信息(从第19-20行开始的if-then路径),另一条路径不包含代码信息(从第21-22行开始的if-else路径)。log.d中没有运行时上下文信息。实际上,释放点通常包含来自源的多条路径。简单的禁止或许可将造成可用性或安全问题。 2)如果采用动态信息流跟踪和控制,可以提供动态上下文信息进行正确的控制。然而,主要问题是单步指令跟踪的运行开销过大。同时,尽管 DTA可以很容易地报告释放点泄漏了哪些敏感信息,但是一旦它不能保存所有信息流事件的日志,则很难输出完整路径作为证据。 为了解决这些问题,本研究提出了一种新的混合分析方法FSAFlow。核心是在运行时采用全局路径跟踪而不是微污染跟踪。同时,通过基于有限状态自动机的最优状态管理实现路径监控,保证了运行时信息流跟踪的效率。路径的状态为控制提供上下文信息,并确保控制的准确性。静态分析阶段实现了对高覆盖路径的全面搜索。此外,FSAFlow不需要审核泄漏分析的所有执行。相反,由于它根据路径跟踪流量,可以直接输出完整的泄漏路径作为证据。 1.2 系统整体架构 FSAFlow由云服务器和移动客户端组成,FSAFlow的工作流程如图2所示。首先,用户可以使用客户端为手机上的任何应用程序自定义信息流策略。通过管理从源到释放点的信息流路径,用户可以获得定制的隐私策略,例如位置信息是否可以通过网络发送或写入本地文件。然后,将个人信息流策略文件与要处理的相应APK文件一起上传到云服务器。 在服务器端,FSAFlow根据上传的信息流策略执行静态分析和检测处理。在静态分析阶段,将考虑所有潜在路径,并控制违反策略的路径。同时,在该阶段记录这些路径的关键节点信息。在静态检测阶段,对受监控路径的重要节点进行检测,以实现有效的路径状态管理。然后,重新打包插入指令的代码以生成新的APK文件并发送回客户端。基于此,安全增强的应用程序将在用户的手机上高效运行和监控。
图1.2 FSAFlow工作流程 1.3 静态分析 静态分析阶段旨在有效地搜索整个程序,并标记潜在的敏感信息泄漏路径。由于分支跳转是区分不同路径的关键节点,因此将记录路径上分支节点的上下文。监测点主要安装在分支机构上。此外,函数调用和返回的上下文将被记录为辅助信息,用于在检测阶段定位分支的函数体。 FSAFlow的静态分析部分是通过修改经典的IFDS框架和FlowDroid工具实现的。许多静态分析问题,包括污点分析、指针分析、活动变量和常量传播,都可以通过IFDS使用特殊的图可达性算法来解决。 IFDS问题由一个元组(G#, D, F, M, G#由一些流图{G1,G2,…}的集合组成(每个函数一个)。函数p的流图Gp由唯一的开始节点sp、唯一的结束节点ep和表示p中语句和谓词的剩余节点组成。在G#中,调用函数q的语句m由两个节点表示,一个call节点cm和一个return-site节点rm。三条边用于连接m和q:从cm到rm的call-to-return边,从cm到sq的call-to-start边,从eq到rm 的exit-to-return边。 为了将静态分析问题转化为图的可达性问题,将G#扩展为超图G*=(N*,E*),其中N* = N#× (D∪∅) 和E*={<u, dx> →<v, dy> | (u, v)∈E#, dy∈fu(dx) }。例如,如果y在n1之前被污染,则(n1: x=y → n2: z=x) ∈E#可以扩展到{(<n1,y>→ <n2, y>, <n1,x>→ <n2, y>)} ∈ E*。注意∅表示一组事实的空集。 基于流函数的定义,IFDS算法从源语句执行ICFG的宽度优先遍历,并在E*中搜索以释放点语句结尾的所有路径。因此,如果G *中存在从节点<n0: y=source(), ∅>到节点<nfinal: sink(x),z>的路径,则路径上节点对应的语句序列构成了从源到释放点的信息流路径。 FSAFlow继续将G*扩展到G^=(N^,E^),其中N^= N*×string和E^={<u, dx, PFSA >→<v, dy, P’FSA> | (u, v)∈E*, dy∈fu(dx)}。PFSA记录目前为止用于识别路径的关键信息,包括分支语句和调用/返回语句的上下文等。同时执行搜索和记录。具体的静态分析如算法1-1所示。
在算法1中,通过读取用户策略文件获得输入Sourcelist和Sinklist,通过调用Soot工具生成G#。首先,搜索G#以查找源语句集。然后,以每个源语句作为一个起点,遍历E^,搜索到达目标释放点的路径。已搜索的边记录在变量pathedge中,并且不会再次搜索这些边(第12-13行)。变量Worklist记录仍需搜索的边集,新找到的边将添加到Worklist(第7、23、27行等),已搜索的旧边将从Worklist中删除(第11行)。 字符串数组PFSA按顺序存储每个关键节点的信息。在PFSA中,不同的节点信息通过一个特殊的分隔符进行分割。FSAFlow为不同的语句类型提取不同的关键信息。 1)语句类型sink(第16-18行)。它表示已找到信息流路径。此时,终止路径扩展并输出PFSA。 2)语句类型function call(第19-27行)。如果第一次遇到此节点,则会将有关调用方和被调用方的call-site信息附加到PFSA,并将路径扩展到被调用方。否则,可以从总结函数Summaryhash中提取关于被调用方的新的扩展路径片段PartFSA,然后在return-site节点上执行搜索。 3)语句类型function return(第28-33行)。附加总结函数到Summaryhash以重用。然后,算法返回到call节点并继续扩展下一条语句。Summaryhash存储信息流流经函数时的路径片段。 4)语句类型assignment(第34-38行)。PFSA将不会更新。赋值语句不是FSAFlow的关键信息,但在这种情况下需要考虑别名问题。FSAFlow执行按需别名分析。当变量被污染时,FSAFlow会向后搜索它的别名,然后再污染它们。向后别名分析函数输出的结果变量、当前的语句和PFSA一起在N^中形成一个新节点。将利用此节点继续进行正向数据流分析。 5)语句类型branch(第39-47行)。后续分支路径的第一条语句ms的信息mp作为节点附加到PFSA。节点mp由元组<sn, size, no, type, sn', m >组成,其中sn表示mp在PFSA中的位置,size表示分支的分支编号,no表示目标路径的分支序列号,type表示节点类型,表示所选分支属于哪个分支类型。节点类型可以是in(插入循环体)、out(退出循环体)和x(其他)。如果ms在当前函数内的路径上出现多次,则sn'用于记录PFSA中ms的第一个对应位置。m代表语句本身。最后,当输出PFSA时,在PFSA中从该节点移除m。有关分支信息的使用,请参阅后文。 以上文中的代码片段为例,给出算法1的路径分析过程。在释放点处被污染的过程可以抽象为①-⑧ 如图1.3所示。同时,静态分析得到的路径的主要结构如图1.4所示。FSAFlow对Jimple代码进行操作,因此输出路径也由Jimple语句表示,以便于后续的检测。
图1.3 信息流路径分析
图1.4 信息流路径编码 在步骤①, 受污染的变量c开始向前传播。在步骤②, 类RequestTask被污染。当污染的变量被postData调用,步骤③继续跟踪。在④, 受污染的变量被ConvertStreamToString调用。步骤⑤ 表示函数调用的返回。受污染的变量继续向前传播通过⑥,由于if语句经过两个分支。在⑥, loginfo被污染了。这将通过步骤⑦和⑧触发反向别名分析, 找到loginfo的别名loginfo_tmpt2,然后作为正常污点向前传播。最后,在⑨, 受污染的变量loginfo_tmpt2在释放点处泄漏。 FSAFlow调整PFSA的输出格式,并根据类和方法聚合节点。静态分析完成后,输出路径的关键信息并写入路径文件。 1.4 静态插桩 根据静态分析结果和用户定义的流策略,为源节点、分支节点和释放节点提取和插桩不允许的路径。 在插桩之前,FSAFlow会预处理路径文件。由于循环结构的存在,语句可能会重复出现在路径上。设SN为出现语句m的路径上所有位置(sn)的集合。FSAFlow将SN附加到m第一次出现在路径上的节点,以便m的位置只被插桩一次。附加后,关于m的其他节点保留在路径上,以确保在插桩以下节点时控制流的一致性。此外,路径中涉及的每个循环结构都被分配一个惟一的ID,用于嵌套循环中的状态监控。关于回路ID的使用,请参考后文。 此外,根据类、方法和路径标识,通过多级哈希表HashMappolicy对所有路径进行分层统一管理。这样,每个参与的类和方法只遍历一次。HashMappolicy的数据结构为<classname, <method, <pathid, pathfragment>>>,通过多级键值直接访问。基于此,方法索引的每个键值都可以存储多条路径的片段信息。pathfragment仅存储分支节点。与路径上的函数调用关联的节点可以删除,并且不会出现在HashMappolicy中。后续检测是基于HashMappolicy执行的。 FSAFlow扩展了Soot的BodyTransformer,实现了internalTransform方法以遍历所有方法体的单元(语句),并在指定位置插入监控代码。算法1-2详细描述了代码插入的过程。
本类最新文章
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||