一种基于Viterbi算法的汉语切词方法
【摘要】:针对汉语切词问题,本文主要从粗糙分割和识别、分段消歧、部分语音标记等未知字,首先在预处理阶段,结合最短路径方法和分割方法,在N―统计数据的基础上,进行最短路径分析,得到最佳的一组粗点结果;然后基于词典和隐马尔可夫切分词分割方法的结合,进一步优化切割词的结果,通过暂存词典不断扩充基本词典,改进隐马尔科夫模型主要通过改进维特比算法求解序列问题和改进的Baum Welch -算法求解参数问题;识别的未注册的话说,引入语法规则库,降低了主体尺寸的要求,提高了识别的准确性。为了进一步提高识别的效率,根据多个活跃代理的理论,增加了匹配的监控机制,这篇论文提出了一个基于多个活跃代理的中文的实体识别方法。最后,设计并实现了基于语法的中文词切分系统。通过分析实验结果,系统能够更好地识别和消除未注册的单词。在相关领域也得到了广泛运用
【关键词】:汉语切词;N-最短路径方法;隐马尔科夫模型
A Chinese word cut method based on the Viterbi algorithm
【Abstract】:According to Chinese word automatic cutting problem, this article mainly from the unknown words from coarse segmentation and recognition, segmentation disambiguation and part-of-speech tagging, first in the pretreatment stage,combined with the shortest path method and the segmentation method, the shortest path based on N - statistics a met model, N the optimal set of coarse points results; Then based on dictionary and hidden Markov cut method,combining with the result of cutting word further optimization, through the temporary dictionary constantly expanding the basic dictionary, improved hidden Markov model is mainly by improving the Viterbi algorithm solving the problem of sequence and improved Baum Welch algorithm solving the problem of parameter; For the recognition of unregistered words,the grammar rules library is introduced to reduce the requirements of the statistical method on corpus scale and improve the accuracy of recognition.For named entity recognition,in order to further improve the efficiency of recognition, according to the theory of multiple active agent, increased the matching monitoring mechanism, this paper proposes a Chinese named entity recognition method based on multiple active agent。 Finally,designed and implemented based on the grammar of Chinese word cutting system, by analyzing the experimental results,the unknown words from the system has good recognition ability and ambiguity resolution ability, is a good performance of cutting word system.
【Key Words】: Chinese word cut; N - the shortest path method; Hidden Markov model
目 录
1 引言
2 汉语切词技术研究
2.1 汉语切词的基本概念
2.2汉语切词的基本算法
2.2.1 基于机械的切词方法
2.2.2 基于统计的切词方法
3基于语法的汉语切词算法
3.1 语法规则库
3.1.1 语法规则
3.1.2 实体名规则库
3.2 基于语法的切词算法基本思想
3.2.1 统计模型基于N -最短路径
3.2.2 切词词典的结构
4 基于语法的分类系统的设计和实现
4.1基于语法的切词系统设计
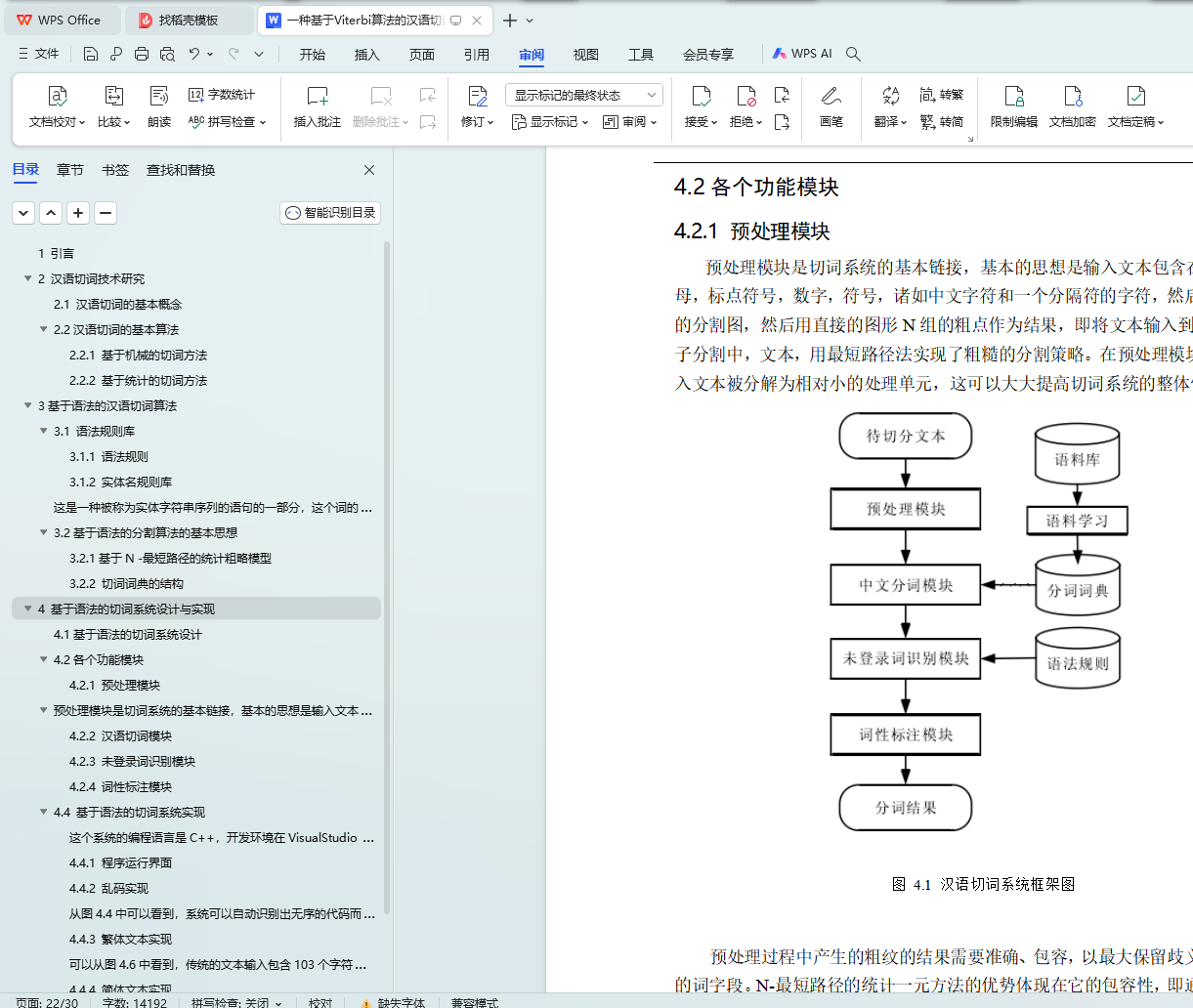
4.2各个功能模块
4.2.1 预处理模块
4.2.2 汉语切词模块
4.2.3 未登录词识别模块
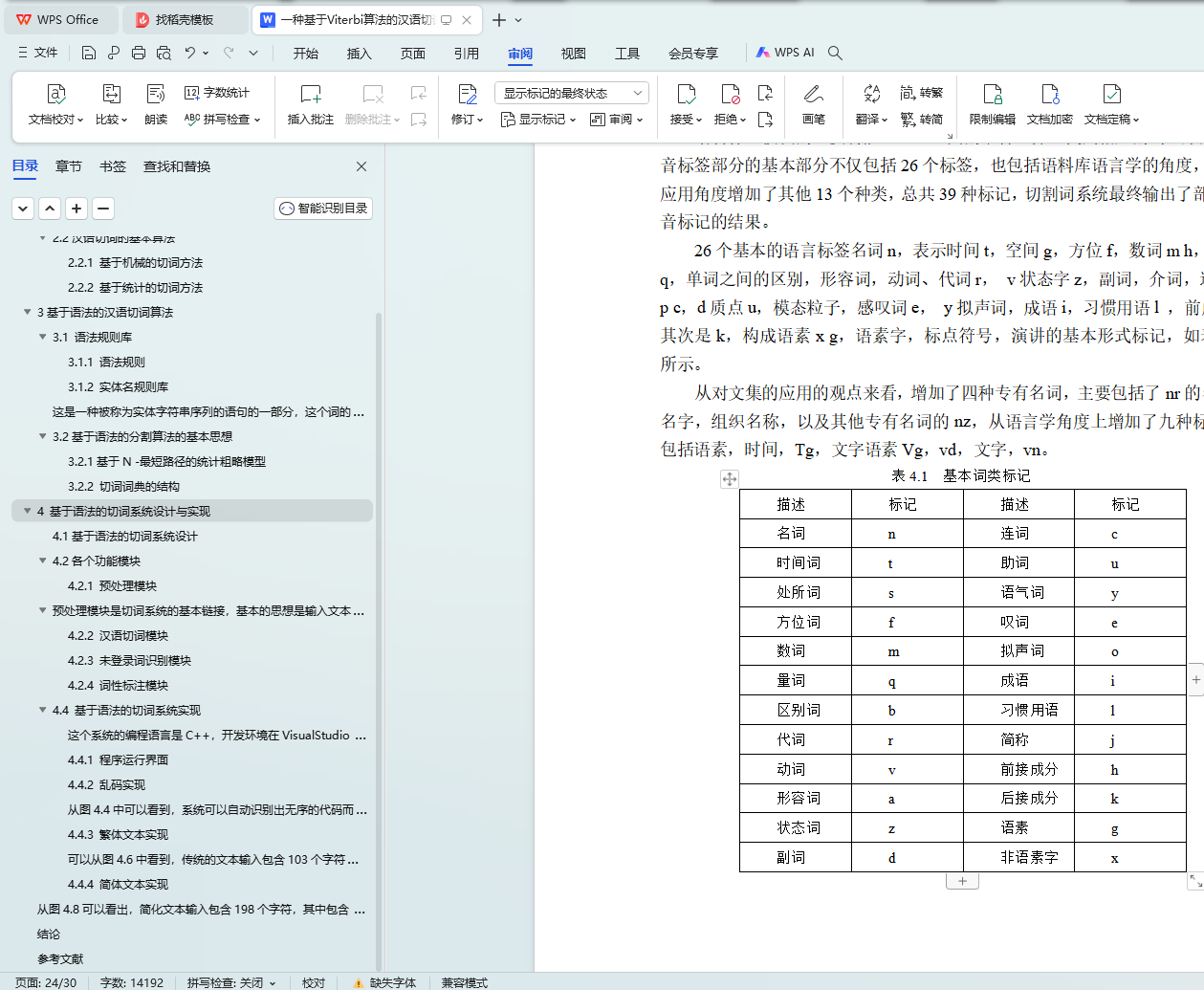
4.2.4 词性标注模块
4.4 基于语法的切词系统实现
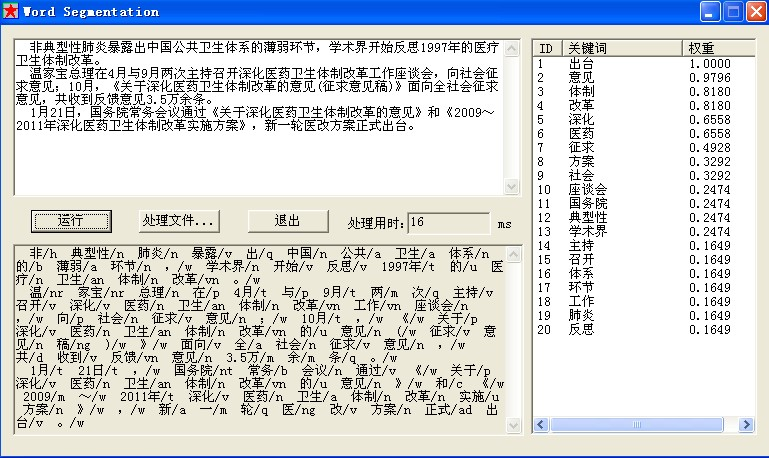
4.4.1 程序运行界面
4.4.2 乱码实现
4.4.3 繁体文本实现
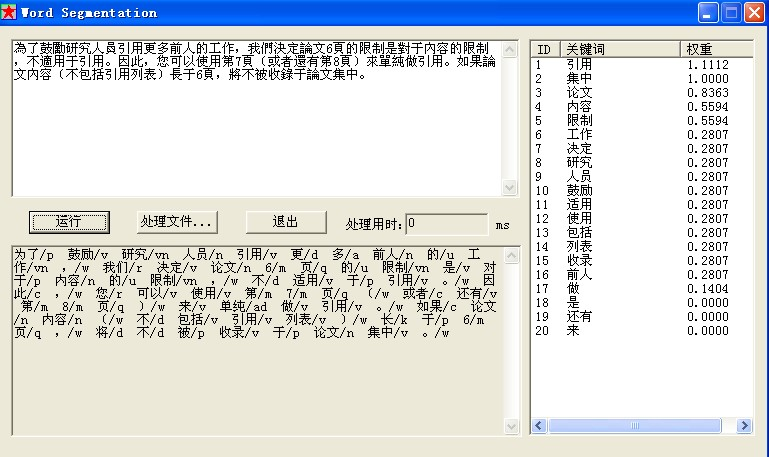
4.4.4 简体文本实现
结论
参考文献