摘 要
近年来,随着生成式对抗网络这种深度学习模型的发展,其相互博弈学习所产生的输出表现越来越好,这使得分辨真假视频的难度也日益增加。Deepfake 假脸视频技术便是利用生成式对抗网络,基于深度学习网络,学习目标视频中人脸的深层次特征,进而更加精确地将目标图像或视频当中的人脸替换为源视频的人脸,并且能够同步人脸的表情以及说话的口型。其逼真性和易操作性使其广泛使用。针对越来越多的假脸视频,我们在此提出基于图像的颜色直方图、SURF (Speeded Up Robust Features)、ELA (Error Level Analysis)三种特征的检测方法,以及基于支持向量机 SVM (Support Vector Machine)的模型训练和验证方法。特征提取之前,先要进行预处理,图像则统一大小和文件格式,视频则分帧存图。首先,我们先研究了上文提到的三种特征的提取方法,分别提取特征数据进行存储。然后,我们将提取到的特征进行绘图,以便形象化展示和进行对比,对比结果将在第四章节展示。接着,我们将提取的特征数据输入 SVM 分类器,进行特征训练,建立二分类模型并保存。最后,我们用上面训练好的 SVM 模型进行人脸测试集的测试并得出结论。结果表明:对于一般的假脸视频,该模型还是能够起到 60%以上的辨别真伪能力。
关键词:特征提取;生成对抗网络;深度造假;颜色直方图;加速鲁棒特性;误差等级分析;支持向量机
Abstract
In recent years, with the development of the deep learning model of generative adversary network, the output performance of mutual game learning is getting better and better, what makes it increasingly difficult to distinguish the original and fake videos. Deepfake fake face video technology is to learn the deep features of the face in the target video based on the deep learning network by using the generative confrontation network, so as to replace the target face with the source video face more accurately, and can synchronize the expression of the face and the speech pattern. Its verisimilitude and easiness of operation make it used in the world widely. In view of more and more fake face videos, we propose three detection methods based on color histogram, SURF (Speed Up Robot Features), ELA (Error Level Analysis), as well as model training and verification methods based on SVM (Support Vector Machine). Before feature extraction, preprocessing should be carried out, pictures should be in uniform size and file format, and videos should be stored per some frames. First of all, we study the three methods of feature extraction mentioned above, respectively extract feature data for storage. Then, we draw the extracted features into pictures for visualization and comparison, and the comparison results will be shown in Chapter 4. Then, we input the extracted face feature data into Support Vector Machine classifier for feature training, build a two-classification model and save it. Finally, we use the SVM model trained before to test the face test set and draw a conclusion. The results show that: for the general fake face video, the model can still distinguish the true and false with more than 60% accuracy.
Keywords: Feature Extraction;GAN;Deepfake;Color Histogram;SURF;ELA;SVM
目 录
摘 要 II
Abstract III
目 录 IV
第一章 绪论 1
1.1 GAN 简介 1
1.2 Deepfake 简介 1
1.3 研究背景及意义 2
1.3.1 研究背景 2
1.3.2 研究意义 3
1.4 国内外研究现状 3
1.5 论文结构 5
第二章 相关工作 6
2.1 图像人脸提取方法的比较 6
2.1.1 方法简介 6
2.1.2 实验对比 7
2.2 视频分帧存图的实现 9
2.3 颜色直方图简介 10
2.4 SURF 概念原理简介 12
2.5 ELA 概念原理简介 13
2.6 SVM 概念原理简介 15
2.6.1 线性可分 16
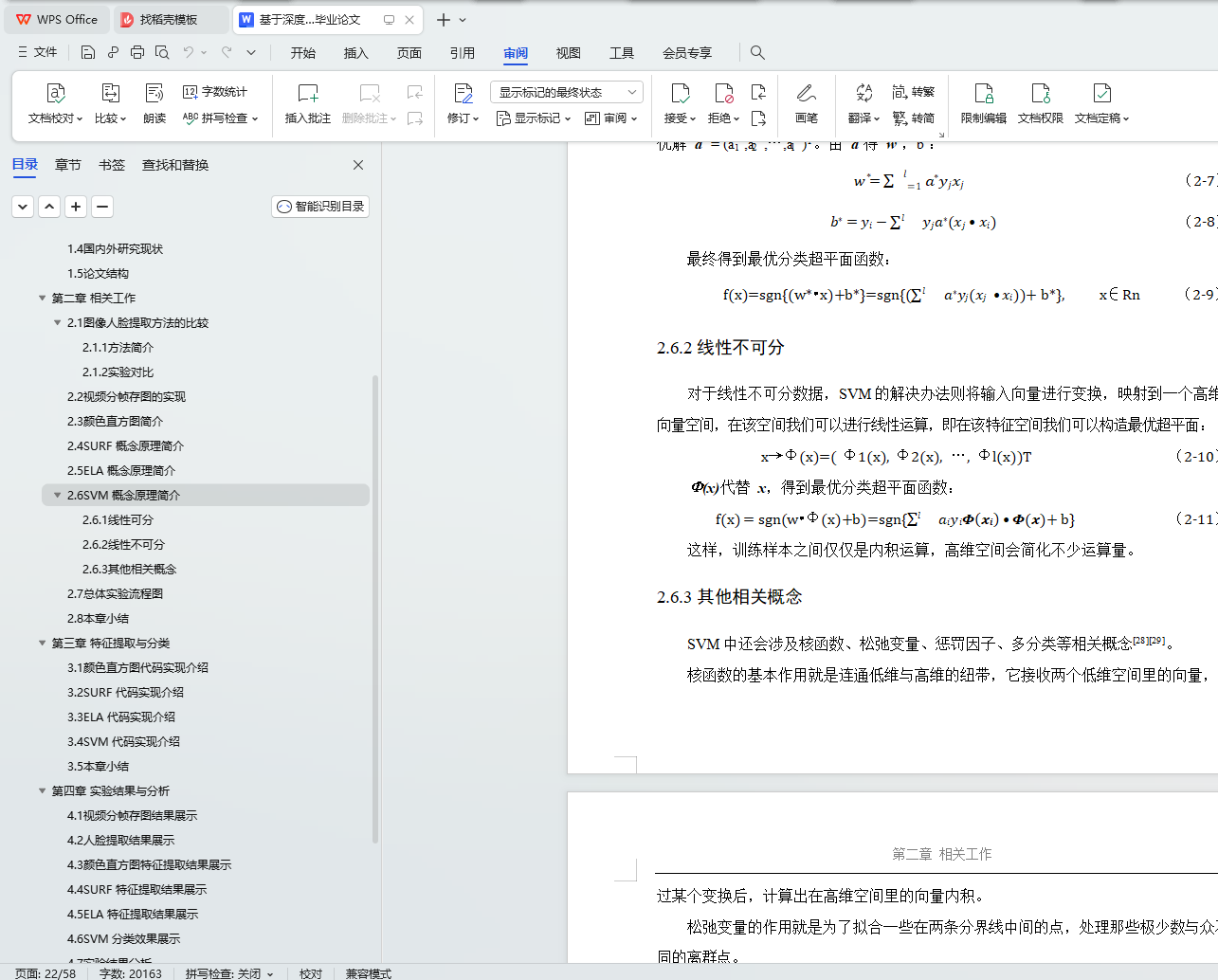
2.6.2 线性不可分 16
2.6.3 其他相关概念 16
2.7 总体实验流程图 17
2.8 本章小结 18
第三章 特征提取与分类 19
3.1 颜色直方图代码实现介绍 19
3.2 SURF 代码实现介绍 20
3.3 ELA 代码实现介绍 24
3.4 SVM 代码实现介绍 26
3.5 本章小结 28
第四章 实验结果与分析 29
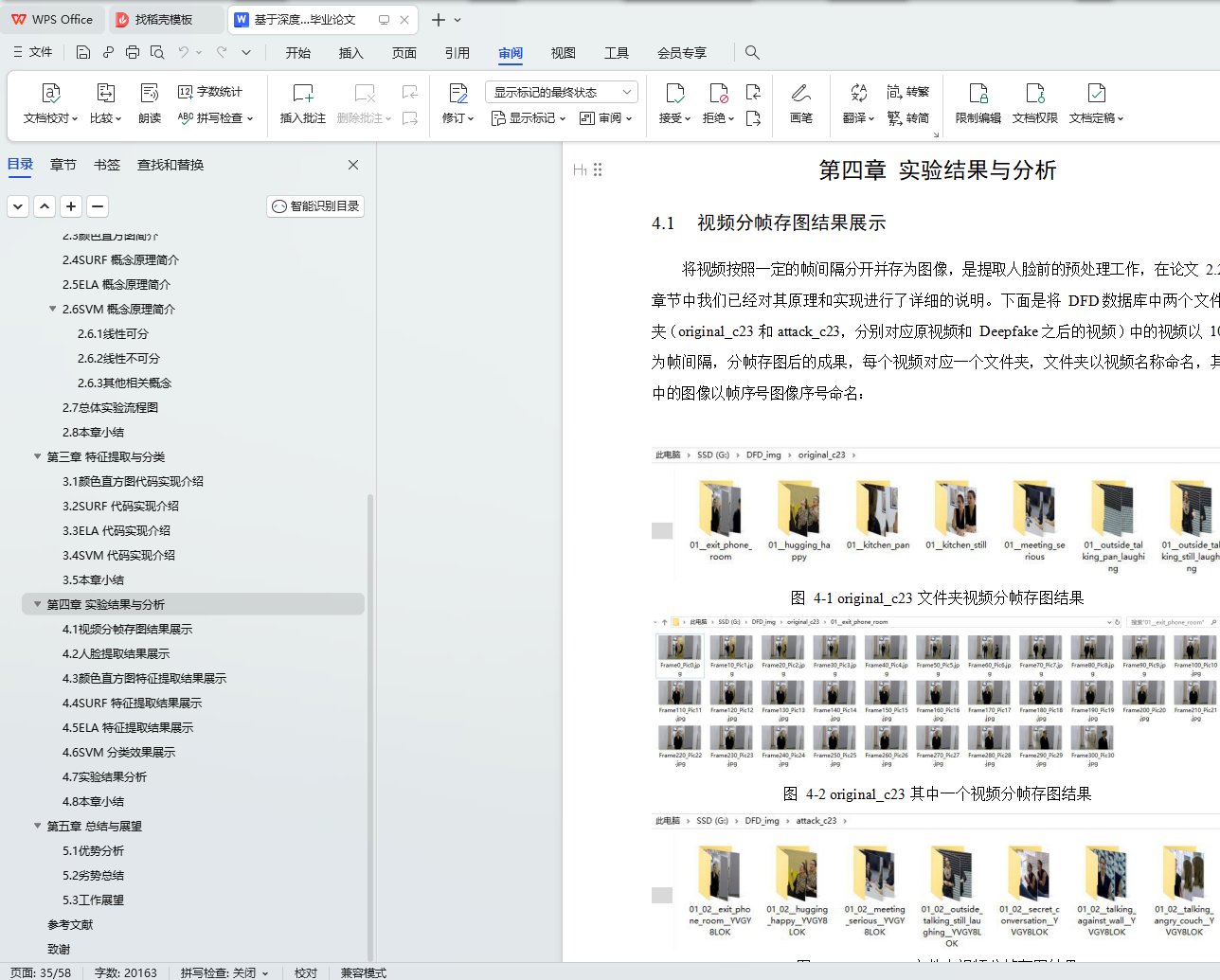
4.1 视频分帧存图结果展示 29
4.2 人脸提取结果展示 30
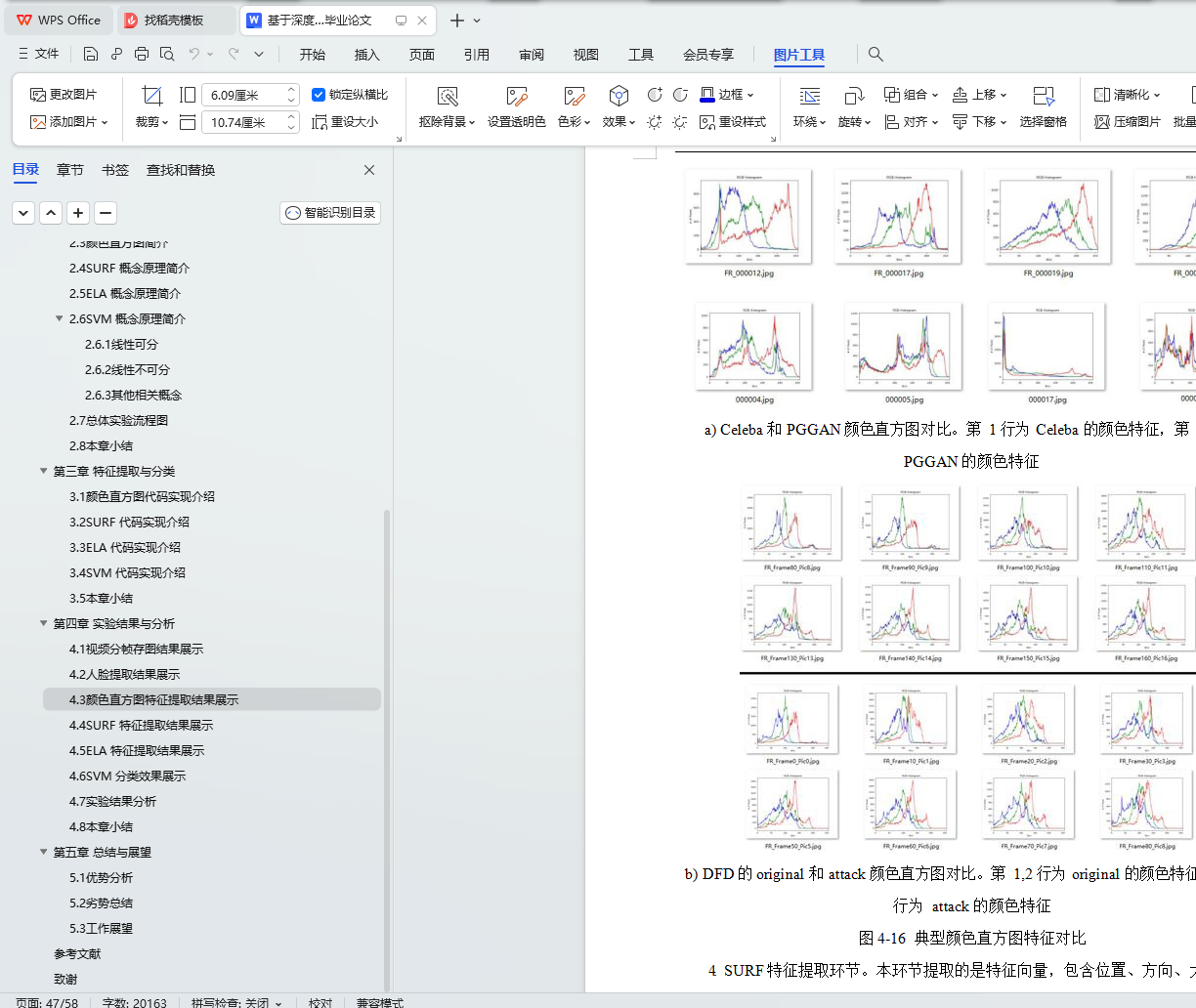
4.3 颜色直方图特征提取结果展示 31
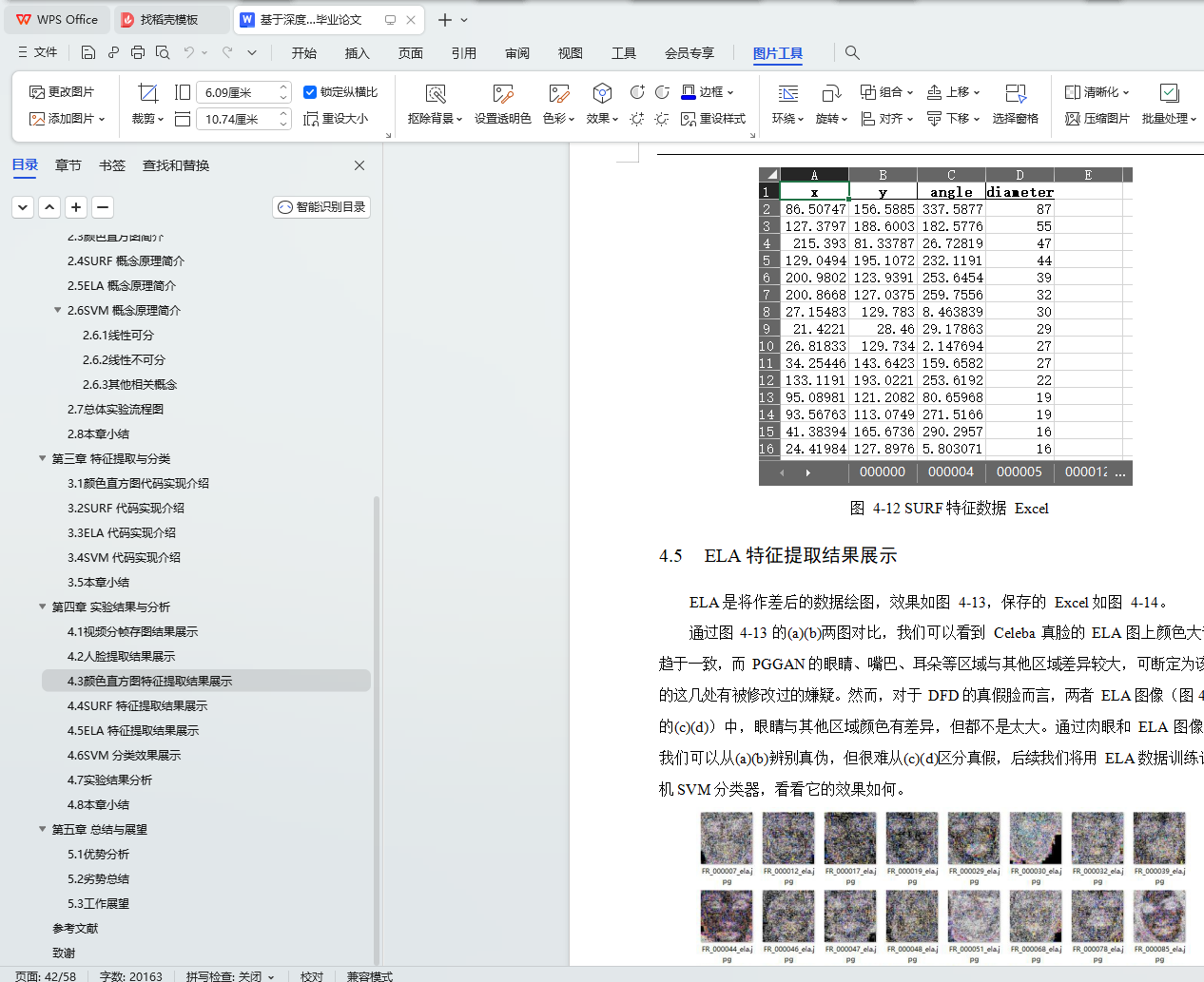
4.4 SURF 特征提取结果展示 34
4.5 ELA 特征提取结果展示 36
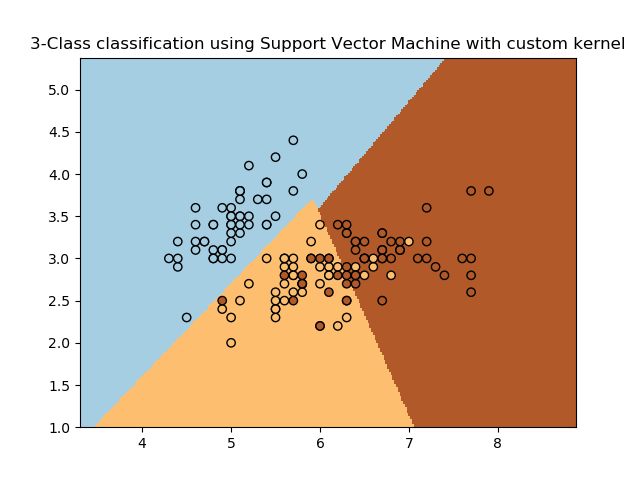
4.6 SVM 分类效果展示 38
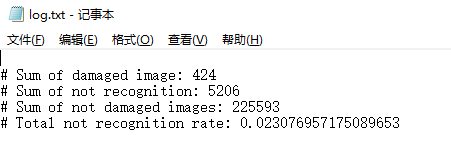
4.7 实验结果分析 39
4.8 本章小结 45
第五章 总结与展望 46
5.1 优势分析 46
5.2 劣势总结 46
5.3 工作展望 47
参考文献 48
致谢 52