摘 要
随着互联网技术的飞速发展,Internet 上的 Web 页面呈指数型增长。对于如何自动对这些海量数据有效处理和管理,来取代低效繁琐的人工管理,Web 文本分类技术成了关键技术。目前对于这方面的研究已经有了很大进展,并且产生了一系列分类方法,比较著名的有支持向量机(VSM)、卷积神经网络(CNN)、神经网络和贝叶斯(Bayes)算法等。在这些算法中,CNN 算法由于其简单、有效、参数无关,目前的应用非常广泛。但是,CNN 算法有着不少的缺陷,最关键的两个缺陷是运行速度太慢和分类精度不高。
本设计对CNN算法的缺陷产生原因进行了分析,并对其进行了改进:在特征提取上引入了基于改进的 CHI 方法使得特征提取更加合理;在CNN分类器运行速度的改进方面引入了 Rocchio 算法的思想和一些其他简单的思路对分类器进行速度的提升,使得新的分类器的分类速度得到大幅度提升;在CNN分类器分类精度的改进方面,通过在相似度计算上引入了基于属性熵值的相似度改进和基于CNN类别加权的改进,使得改进的CNN算法又在分类精度上得到了大幅度提高。在基于上述这些改进后,搭建出了一个真正具备高效、实用的网站文本分类系统。
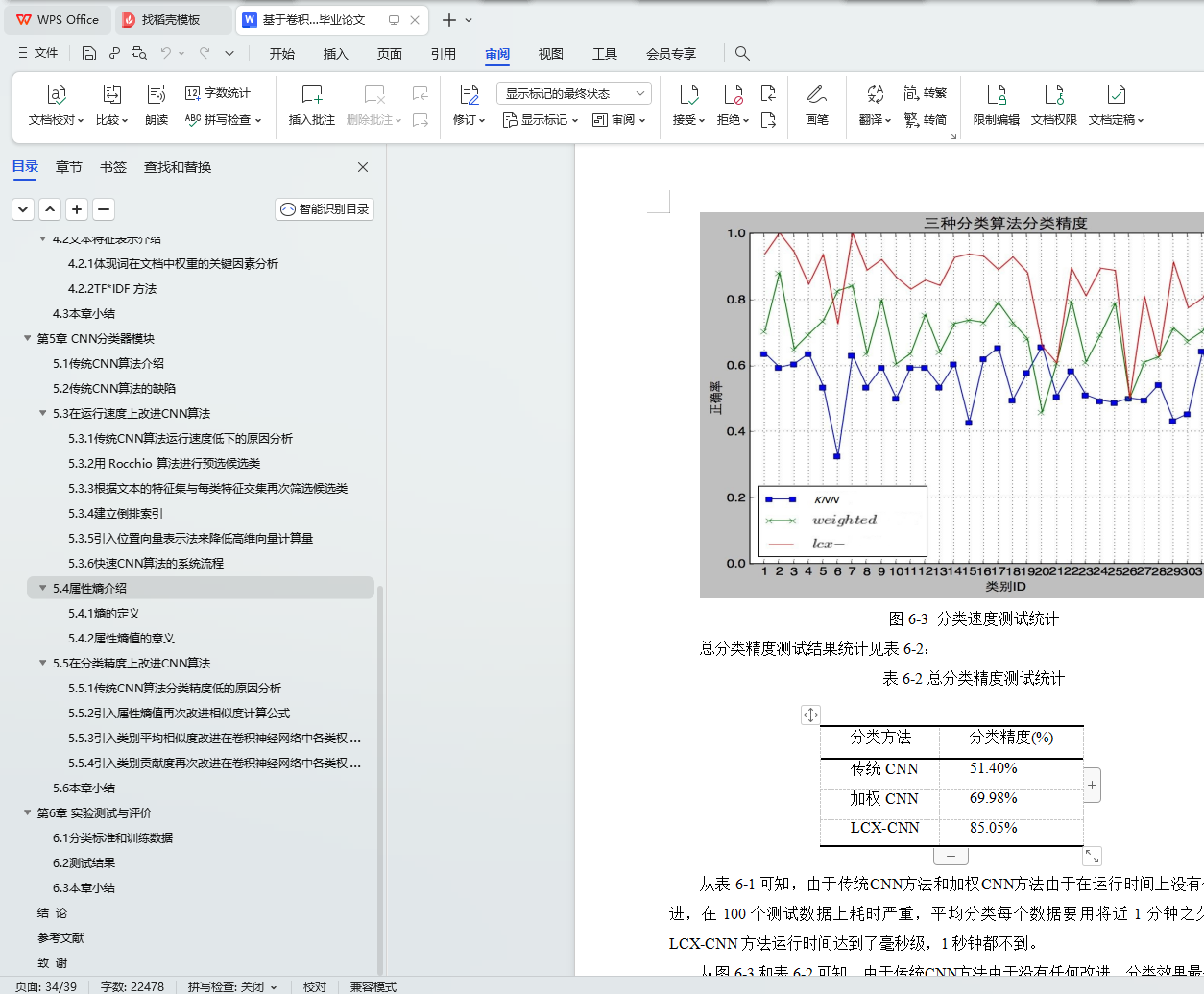
本文完成了分类器系统的实现,并且利用个 3578 个真实网站内容作为测试集对系统进行了性能测试。通过对实验结果进行分析,得出本文提出的新的CNN分类器在测试集数据的环境下达到了高速分类和分类正确率远高出传统方法的结论。本文提出的新的高效CNN算法作为网站文本分类器比原有的CNN分类方法和加权CNN方法有更快的速度,同时比两者有更高的分类精度。
关键词:高效网站文本分类;改进特征提取;快速分类;高精度分类;属性熵值分析
Abstract
With the rapid development of the Internet,web pages on the Internet is growing exponentially. On the issue of how to organize and deal with these massive data effectively, automatically and how to take the place of manual management which is too inefficient and cumbersome, Web text classification has became a key technology. At present,the research in this area has made great progress,and there are a series of classification methods. And there are some well-known methods such as support vector machine (VSM), K-nearest neighbor(CNN), neural networks and Bayes algorithm.CNNmethod is widely used due to that it is sample,effective and regardless of parameters. However,the traditionalCNNmethod has two critical flaws, one flaw of them is thatCNNmethod is running too slow, the other flaw is that the accuracy of this method is not sufficiently high.
This paper analyzed the causes of detects inCNNmethod and made major improvements: In the feature extraction module,we introduced an improved method based on CHI method,which makes the feature extraction more reasonable. In the classifier speed improvements, we introduced the idea of Rocchio method and some other simple ideas to improve classification running speed. Thus new classifier will be greatly improved in the speed. In the classifier accuracy improvements, we made the classification accuracy significantly improved through the introduction of an improved similarity calculation based on the entropy of properties and some ideas based on class weightedCNNmethod.
Based upon these improvements, we built out a definitely efficient and practical web classification system. This paper completed the implementation of the new classification system,and we used 3578 real web content as a test set to test the performance of our system. Through the analysis of experimental results, we drew a conclusion that in our test data set environment, our improved classifier has achieved high-speed sorting and much higher accuracy rate than traditionalCNNmethod. Web classifier based on new efficient improvedCNNmethod proposed in this paper has much faster speed and much higher classification accuracy rate than the originalCNNmethod and weightedCNNmethod.
Keywords: efficient site classification, improved feature extraction, rapid classification, precision classification, property entropy analysis
目 录
摘 要
Abstract
第1章 绪论
1.1课题的研究背景和意义
1.1.1目前网站文本分类的研究情况
1.1.2基于特征熵值分析的网站文本分类系统的设计目标
1.2论文的研究内容与组织结构
1.2.1论文的研究内容
1.2.2论文的组织结构
第2章 系统模块组成介绍
2.1系统总体架构
2.2爬虫模块功能与技术
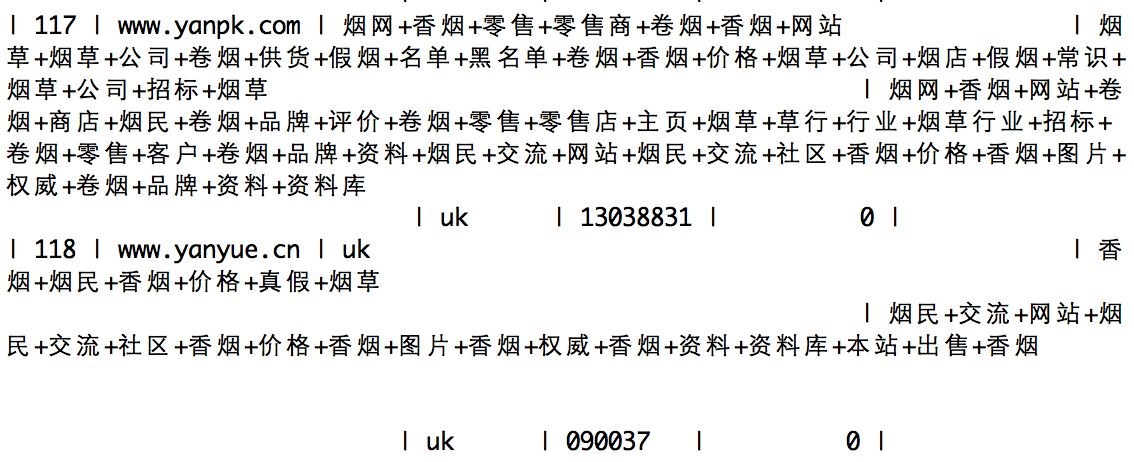
2.3网页处理模块功能与技术
2.4特征提取与文本特征表示模块功能与技术
2.5分类器模块功能与技术
2.6本章小结
第3章 爬虫模块和页面处理模块
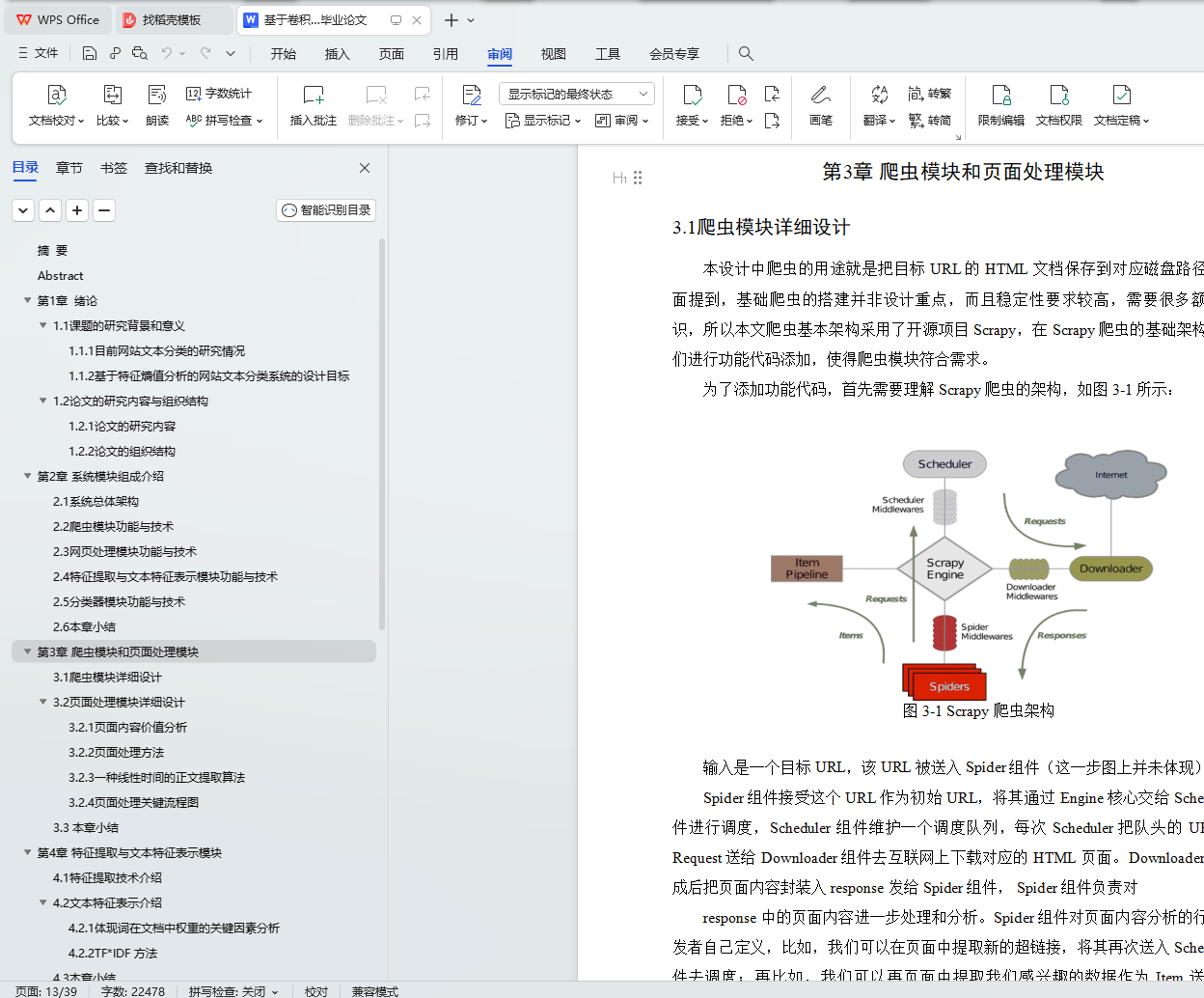
3.1爬虫模块详细设计
3.2页面处理模块详细设计
3.2.1页面内容价值分析
3.2.2页面处理方法
3.2.3一种线性时间的正文提取算法
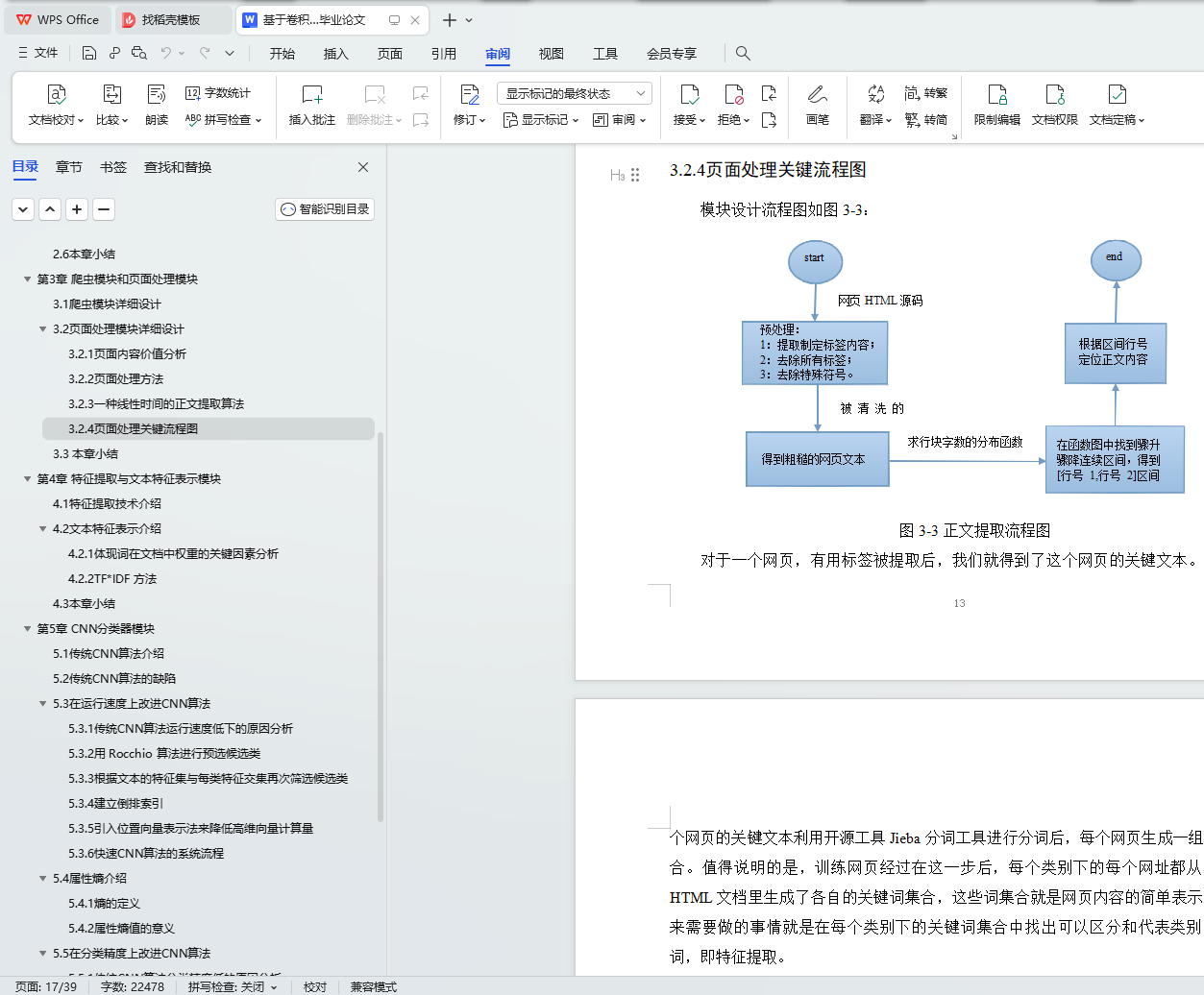
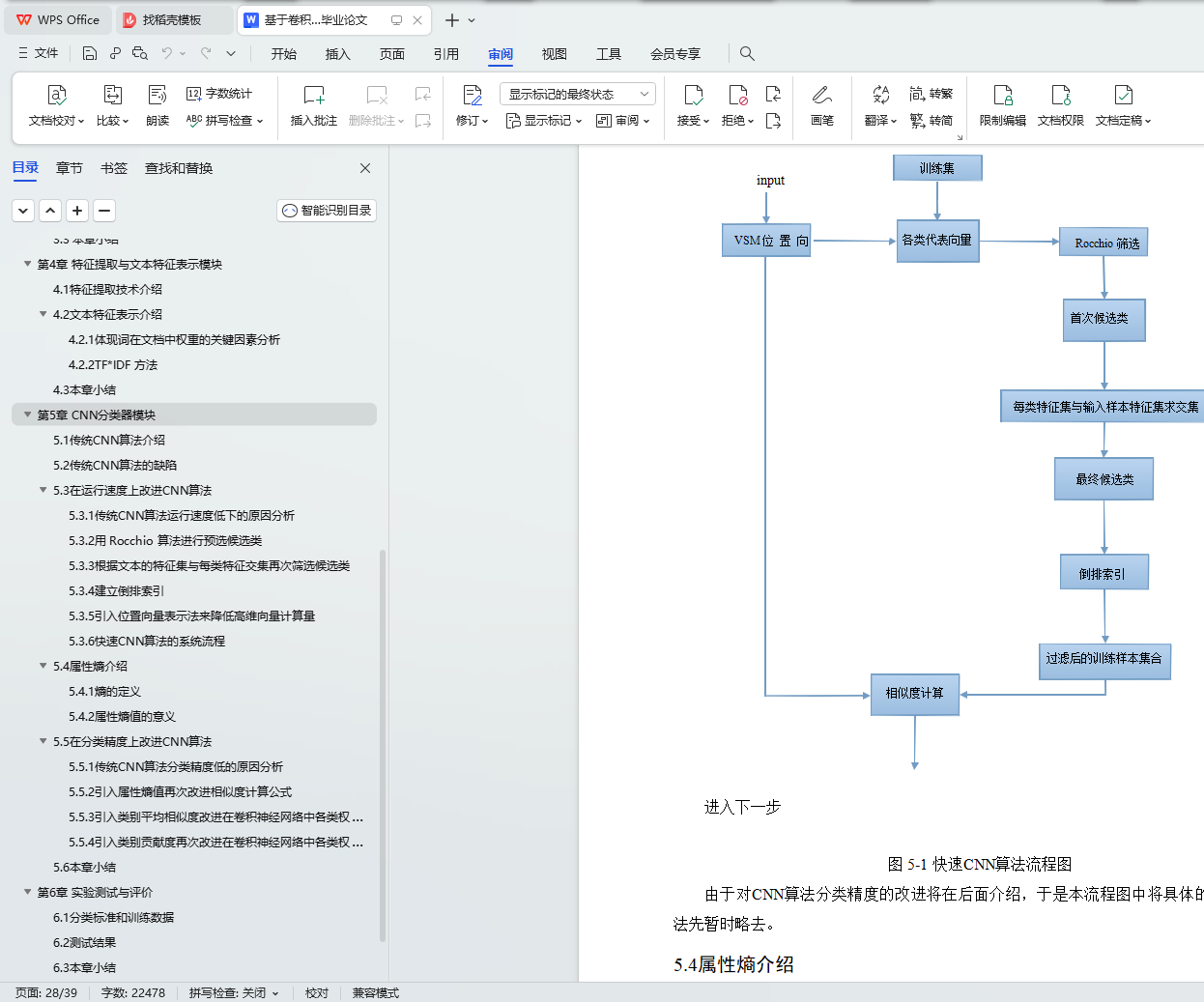
3.2.4页面处理关键流程图
3.3 本章小结
第4章 特征提取与文本特征表示模块
4.1特征提取技术介绍
4.2文本特征表示介绍
4.2.1体现词在文档中权重的关键因素分析
4.2.2TF*IDF 方法
4.3本章小结
第5章 CNN分类器模块
5.1传统CNN算法介绍
5.2传统CNN算法的缺陷
5.3在运行速度上改进CNN算法
5.3.1传统CNN算法运行速度低下的原因分析
5.3.2用 Rocchio 算法进行预选候选类
5.3.3根据文本的特征集与每类特征交集再次筛选候选类
5.3.4建立倒排索引
5.3.5引入位置向量表示法来降低高维向量计算量
5.3.6快速CNN算法的系统流程
5.4属性熵介绍
5.4.1熵的定义
5.4.2属性熵值的意义
5.5在分类精度上改进CNN算法
5.5.1传统CNN算法分类精度低的原因分析
5.5.2引入属性熵值再次改进相似度计算公式
5.5.3引入类别平均相似度改进在卷积神经网络中各类权重公式
5.5.4引入类别贡献度再次改进在卷积神经网络中各类权重公式
5.6本章小结
第6章 实验测试与评价
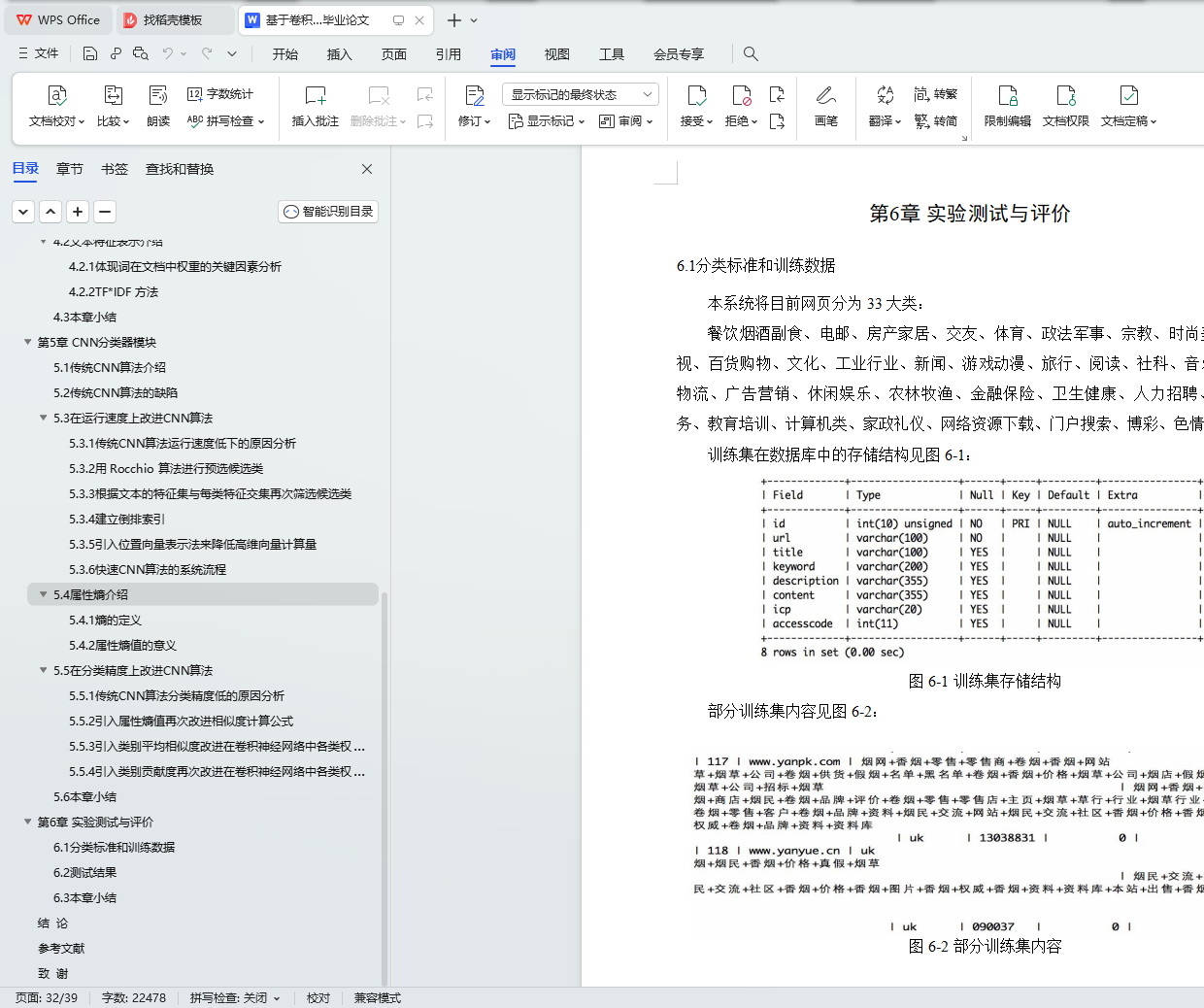
6.1分类标准和训练数据
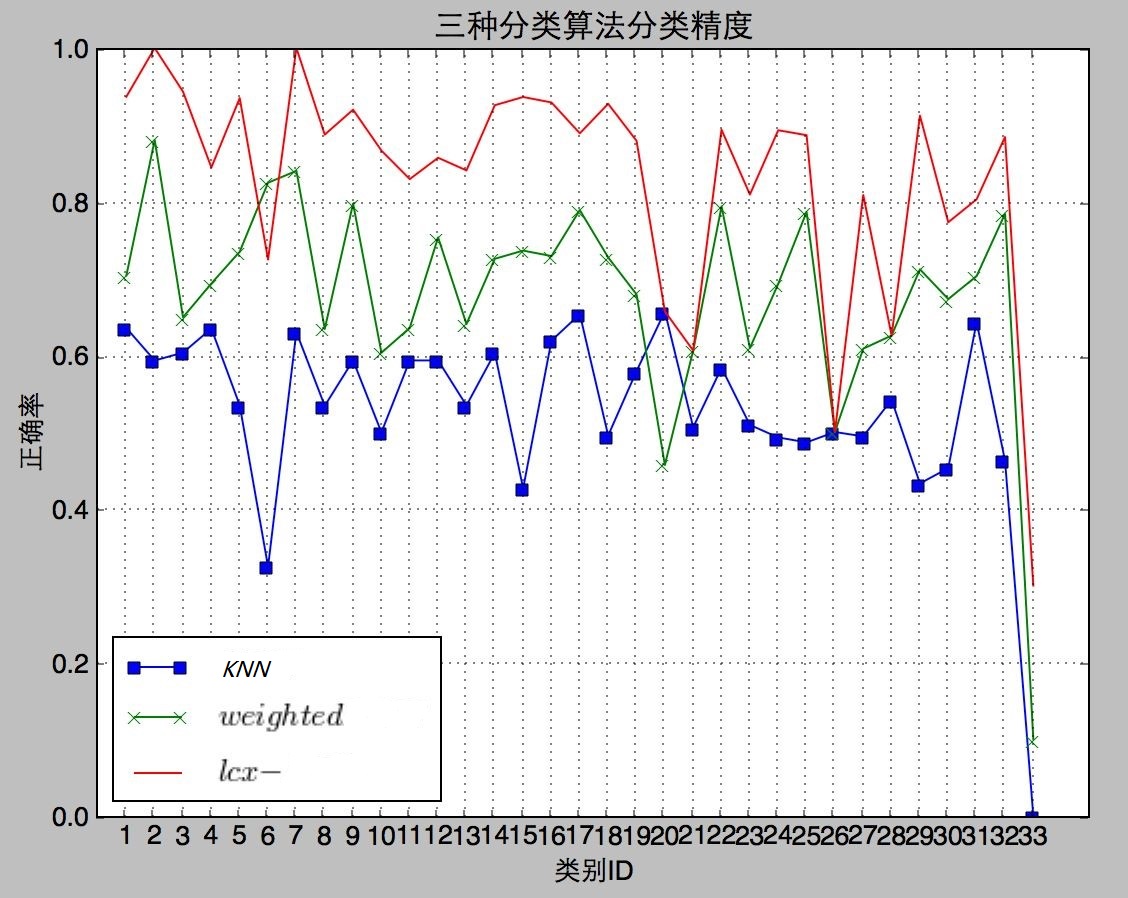
6.2测试结果
6.3本章小结
结 论
参考文献
致 谢