人工智能实验:强化学习实验报告
目录
人工智能实验:强化学习实验报告
一、 基本原理
1.1 强化学习
1.2 Q学习方法
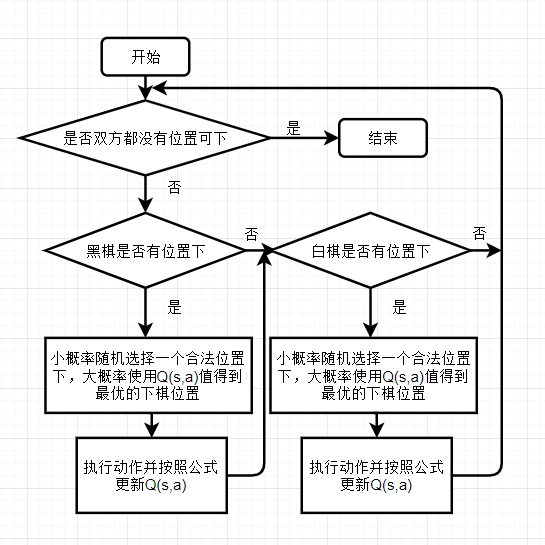
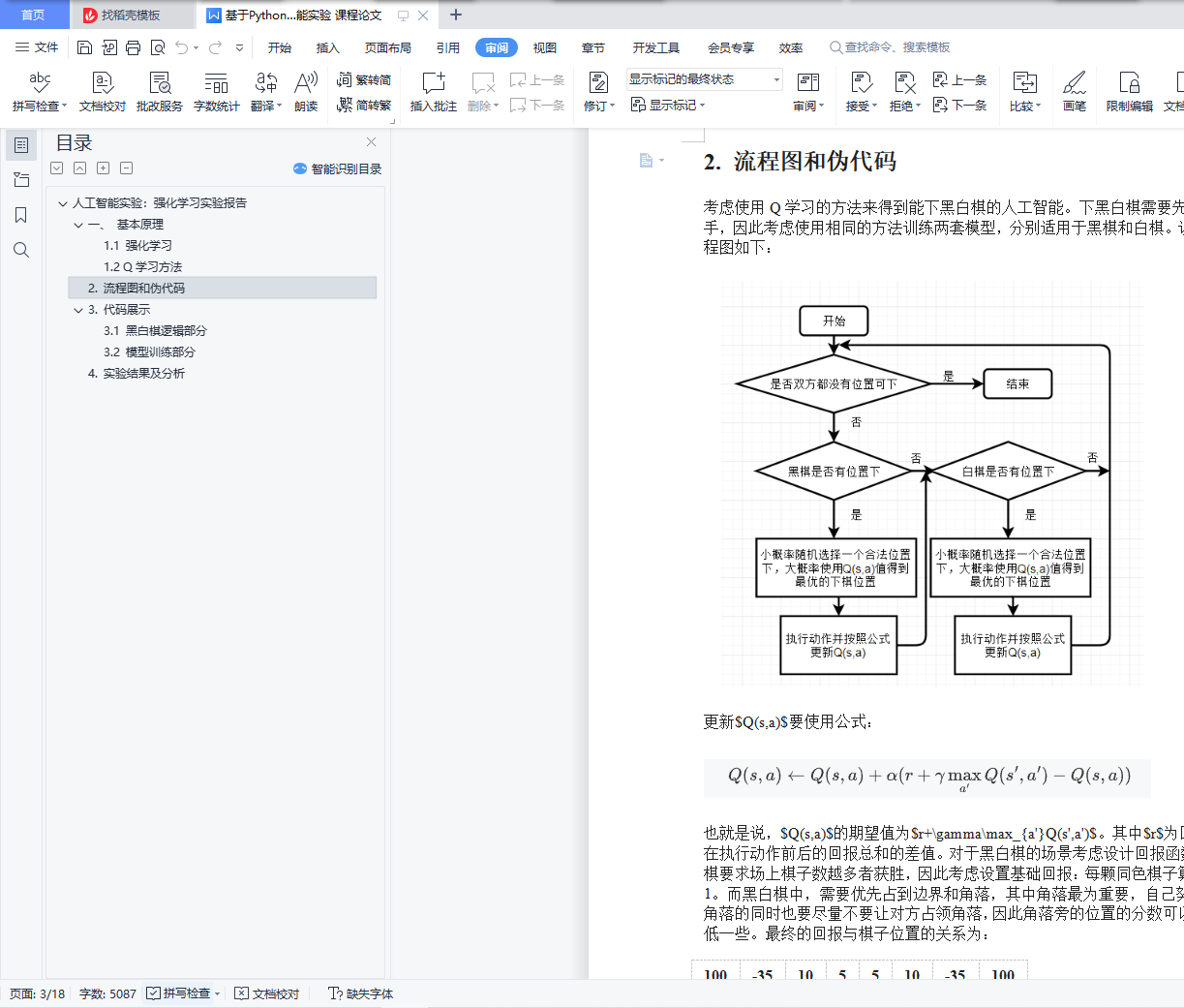
2. 流程图和伪代码
3. 代码展示
3.1 黑白棋逻辑部分
3.2 模型训练部分
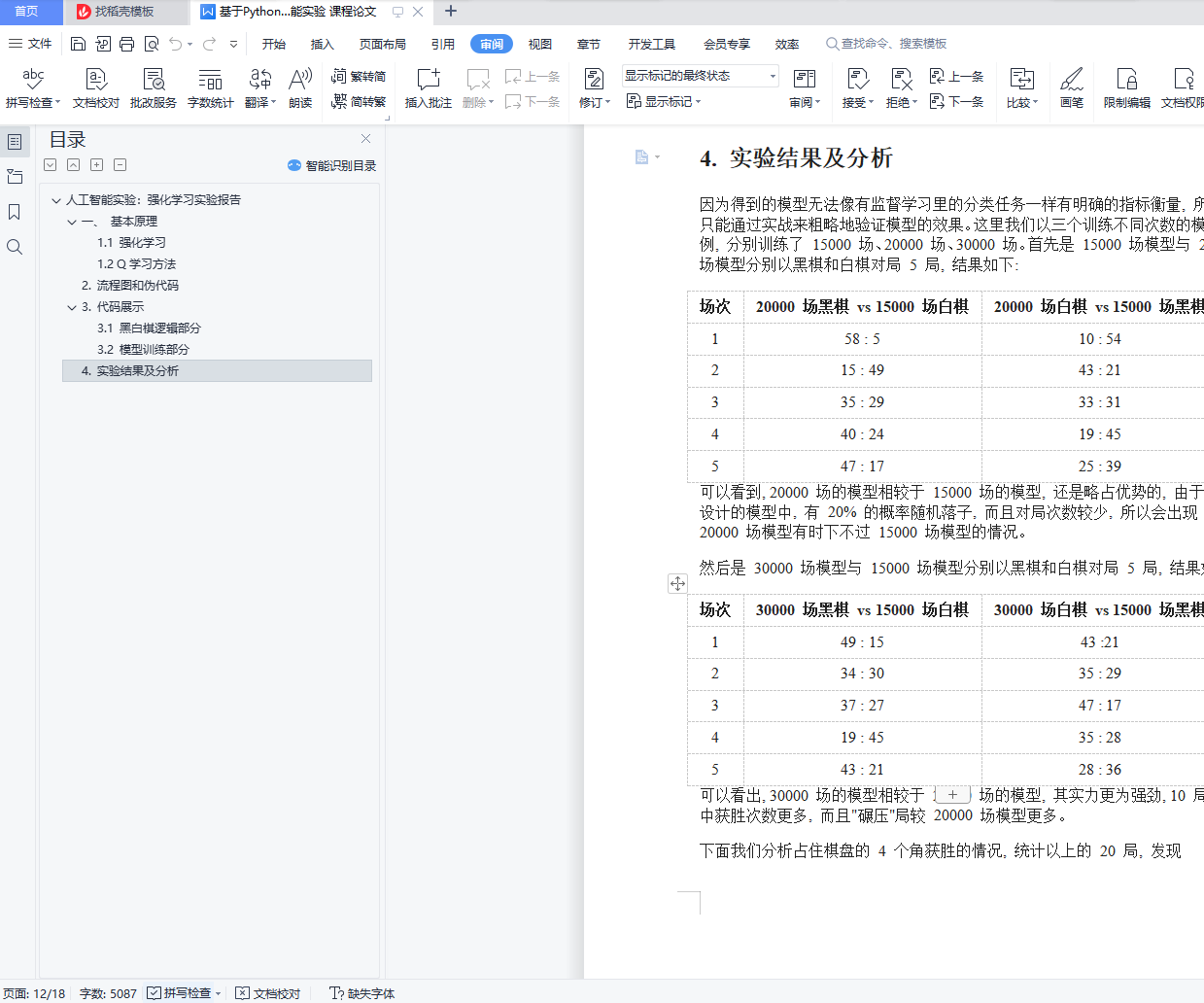
4. 实验结果及分析
一、 基本原理
1.1 强化学习
强化学习是指一类从(与环境)交互中不断学习的问题以及解决这类问题的方法。强化学习问题可以描述为一个智能体从与环境的交互中不断学习以完成特定目标(比如取得最大奖励值)。而强化学习的关键问题是在于每一个动作并不能直接得到监督信息,需要通过整个模型的最终监督信息(奖励)得到,并且有一定的延时性。所以我们要解决如何通过直接得到的监督信息,来获得每个状态中比较恰当的动作的问题。
在强化学习中,有两个可以进行交互的对象:智能体和环境。智能体可以感知外界环境的状态,并进行学习和决策。智能体的决策功能是指根据外界环境的状态来做出不同的动作,而学习功能是指根据外界环境的奖励来调整策略。环境是智能体外部的所有事物,并受智能体动作的影响而改变其状态,并反馈给智能体相应的奖励 。其要素包括:
・ 状态$s$:对环境的描述,可以是离散的或连续的,其状态空间为$S$
・ 动作$a$: 对智能体行为的描述,可以是离散的或连续的,其动作空间为$A$
・ 策略$\pi(a|s)$ :智能体根据环境状态$s$ 来决定下一步动作$a$ 的函数
・ 状态转移概率$p(s'|s, a)$ :在智能体根据当前状态$s$做出一个动作$a$之后,环境在下一个时刻转变为状态$s'$的概率
・ 即时奖励$r(s,a,s')$是一个标量函数,即智能体根据当前状态$s$做出动作$a$之后,环境会反馈给智能体一个奖励,这个奖励也经常和下一个时刻的状态$s'$有关