| 设计 任务书 文档 开题 答辩 说明书 格式 模板 外文 翻译 范文 资料 作品 文献 课程 实习 指导 调研 下载 网络教育 计算机 网站 网页 小程序 商城 购物 订餐 电影 安卓 Android Html Html5 SSM SSH Python 爬虫 大数据 管理系统 图书 校园网 考试 选题 网络安全 推荐系统 机械 模具 夹具 自动化 数控 车床 汽车 故障 诊断 电机 建模 机械手 去壳机 千斤顶 变速器 减速器 图纸 电气 变电站 电子 Stm32 单片机 物联网 监控 密码锁 Plc 组态 控制 智能 Matlab 土木 建筑 结构 框架 教学楼 住宅楼 造价 施工 办公楼 给水 排水 桥梁 刚构桥 水利 重力坝 水库 采矿 环境 化工 固废 工厂 视觉传达 室内设计 产品设计 电子商务 物流 盈利 案例 分析 评估 报告 营销 报销 会计 |
|
|
|
| 首 页 | 机械毕业设计 | 电子电气毕业设计 | 计算机毕业设计 | 土木工程毕业设计 | 视觉传达毕业设计 | 理工论文 | 文科论文 | 毕设资料 | 帮助中心 | 设计流程 |
您现在所在的位置:首页 >>计算机毕业设计 >> 文章内容 |
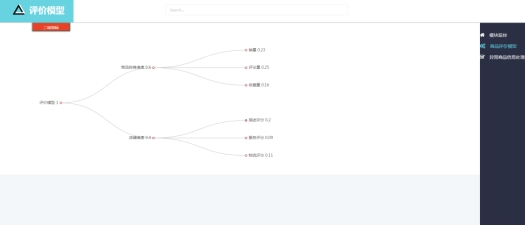
模糊评价模型三级指标表Indicators3
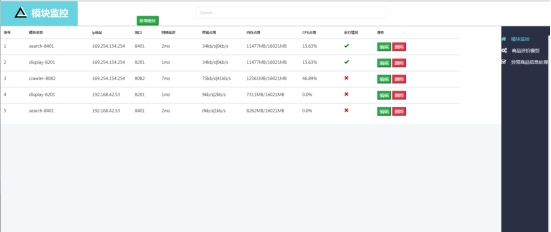
模块节点信息表(module-info)
参与贡献1. Fork 本仓库 2. 新建 Feat_xxx 分支 3. 提交代码 4. 新建 Pull Request , |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
伦理名 |
物理名 |
属性 |
主键 |
外键 |
说明 |
|
编号 |
id |
Int(16) |
Y |
||
|
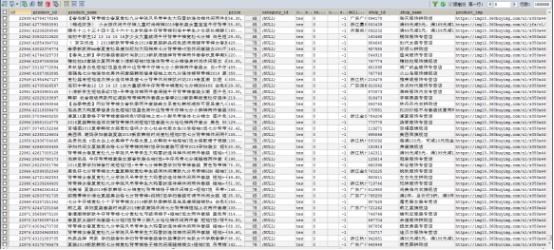
商品编号 |
product_id varchar(32) |
||||
|
商品名称 |
product_name varchar(256) |
||||
|
商品价格(历史价格 ‘,’隔开) |
price |
text |
|||
|
商品分类ID |
category_id |
varchar(32) |
|||
|
商品分类名称 |
Category_name |
varchar(32) |
|||
|
销量 |
sellCount |
varchar(32) |
|||
|
评论量 |
reviewCount |
varchar(32) |
|||
|
收藏量 |
collectCount |
varchar(32) |
|||
|
库存量 |
stock |
Int(8) |
|||
|
发货地址 |
Delivery_Add |
Varchar(32) |
|||
|
店铺ID |
Shop_id varchar(32) |
||||
|
店铺名称 |
Shop_name |
varchar(256) |
|||
|
商品图片 |
Product_img |
text |
|||
|
店铺描述评分 |
Shopdsr_ms |
Double(2) |
|||
|
店铺服务评分 |
Shopdsr_fw |
Double(2) |
|||
|
店铺物流评分 |
Shopdsr_wl |
Double(2) |
|||
|
商品sku信息 |
product_sku |
text |
|||
|
商品URL |
Product_Url |
varchar(1024) |
|||
|
商品详情 |
Product_detail |
text |
|||
|
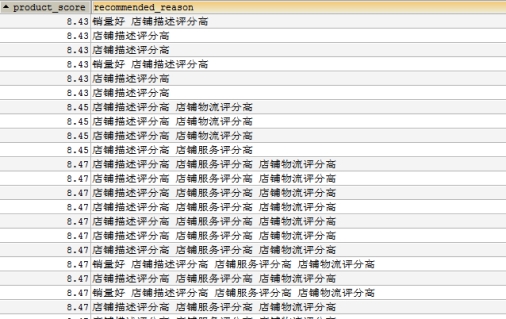
商品系统评分 |
Product_score |
Double(4) |
|||
|
推荐理由 |
Recommended_reason |
varchar(1024) |
|||
|
爬取时间 |
Update_time |
text |
|||
|
备用字段1(当前价格) |
spare_field1 |
double |
|||
|
备用字段2 |
spare_field2 |
text |
|||
|
备用字段3 |
spare_field3 |
text |
商品种类信息表(category)
|
伦理名 |
物理名 |
属性 |
主键 |
外键 |
说明 |
|
编号 |
id |
Int(16) |
Y |
||
|
商品种类ID |
category_id |
varchar(32) |
|||
|
商品种类名称1 |
category1_name |
VARCHAR(64) |
|||
|
商品种类名称2 |
Category2_name |
VARCHAR(64) |
|||
|
商品种类名称3 |
Category3_name |
VARCHAR(64) |
代理ip信息表(proxyIp)
|
伦理名 |
物理名 |
属性 |
主键 |
外键 |
说明 |
|
编号 |
id |
Int(16) |
Y |
||
|
Ip地址 |
Ip_address |
varchar(32) |
|||
|
Ip端口号 |
Ip_port |
VARCHAR(8) |
|||
|
服务器地址 |
Server_address |
VARCHAR(64) |
|||
|
验证时间 |
Check_time |
VARCHAR(64) |
|||
|
更新时间 |
Update_time |
date |
模糊评价模型一级指标表Indicators1
|
伦理名 |
物理名 |
属性 |
主键 |
外键 |
说明 |
|
编号 |
id |
Int(16) |
Y |
||
|
类目名称 |
Indicators_1_name |
varchar(64) |
|||
|
类目权重 |
Indicators_1_weight |
Double(4,2) |
|||
|
备用字段1 |
spare_field1 |
Varchar(128) |
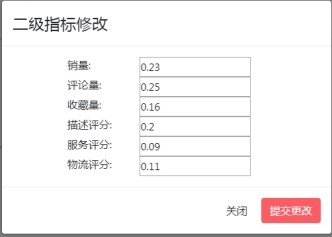
模糊评价模型二级指标表Indicators2
|
伦理名 |
物理名 |
属性 |
主键 |
外键 |
说明 |
|
编号 |
id |
Int(16) |
Y |
||
|
类目名称 |
Indicators_2_name |
varchar(64) |
|||
|
类目权重 |
Indicators_2_weight |
Double(4,2) |
|||
|
对应一级类目id |
Indicators_1_id |
全套毕业设计论文现成成品资料请咨询微信号:biyezuopinvvp QQ:1015083682
返回首页
如转载请注明来源于www.biyezuopin.vip
|
|||
| |
|