摘要
随着科技迅速发展、IT行业发展速度加快,人才缺口逐渐增大,招聘信息层出不穷。但许多求职者求职目标不明确,不了解就业行情,屡次与理想的企业擦肩而过,而企业也难以招聘到所需的技术人才。针对这一日益突出的就业问题,本文提出基于大数据技术开发用于对当前IT行业岗位信息进行分析与展示的系统。该系统底层架构采用Spark分布式计算引擎处理海量求职信息,向下兼容Hadoop集群,并且做到GUI界面交互操作与可视化智能分析。
本论文中,首先简要阐明论文研究背景与研究意义,对相关理论技术进行了必要介绍;其次,分别从对系统可行性、功能性需求及非功能性需求三个方面进行研究剖析。从中确立了系统目标,设计了系统总体架构,对数据集合结构及数据展示大屏进行了设计;再次,从设计流程、思路详解及代码实现对系统主要功能模块,包括数据爬取、存储、清洗、分析以及可视化进行了详细说明;最后,交代了系统关键工具的部署方法,对系统功能模块进行了详细测试,并评估了测试结果,说明了修改进度。
关键词:大数据;IT就业;岗位分析;数据可视化
ABSTRACT
With the rapid development of technology, IT industry development speed up, the talent gap is gradually increasing, recruitment information is endless. However, many job seekers do not have a clear job target, do not understand the employment market, and repeatedly pass by the ideal enterprise, and the enterprise is difficult to recruit the required technical personnel. To address this increasingly prominent employment problem, this paper proposes a system based on big data technology development for analyzing and displaying current IT industry job information. The underlying architecture of the system adopts Spark distributed computing engine to process massive job information, is backward compatible with Hadoop cluster, and achieves GUI interface interaction and visual intelligent analysis.
In this thesis, firstly, we briefly explain the background and significance of the thesis research, and introduce the relevant theoretical technologies; secondly, we analyze the feasibility, functional requirements and non-functional requirements of the system respectively. From there, the system objectives are established, the overall architecture of the system is designed, and the data collection structure and data display large screen are designed; again, the main functional modules of the system, including data crawling, storage, cleaning, analysis and visualization, are explained in detail from the design process, detailed explanation of ideas and code implementation; finally, the deployment method of the key tools of the system is explained, and the functional modules of the system are tested in detail, and Finally, the deployment method of the key tools of the system is explained, the detailed testing of the functional modules of the system is conducted, and the test results are evaluated and the modification progress is explained.
Keywords:big data; IT jobs; job analytics; data visualization
目 录
摘要 I
ABSTRACT II
1 引言 1
1.1 研究背景 1
1.2 研究意义 1
1.3 研究内容与组织结构 1
2 相关理论与技术介绍 3
2.1 HDFS简介 3
2.2 Spark简介 4
2.3 MongoDB数据库简介 6
2.4 爬虫技术简介 7
2.5 Echarts简介 8
2.6 Pyqt5简介 8
2.7 本章小结 8
3 系统需求分析 9
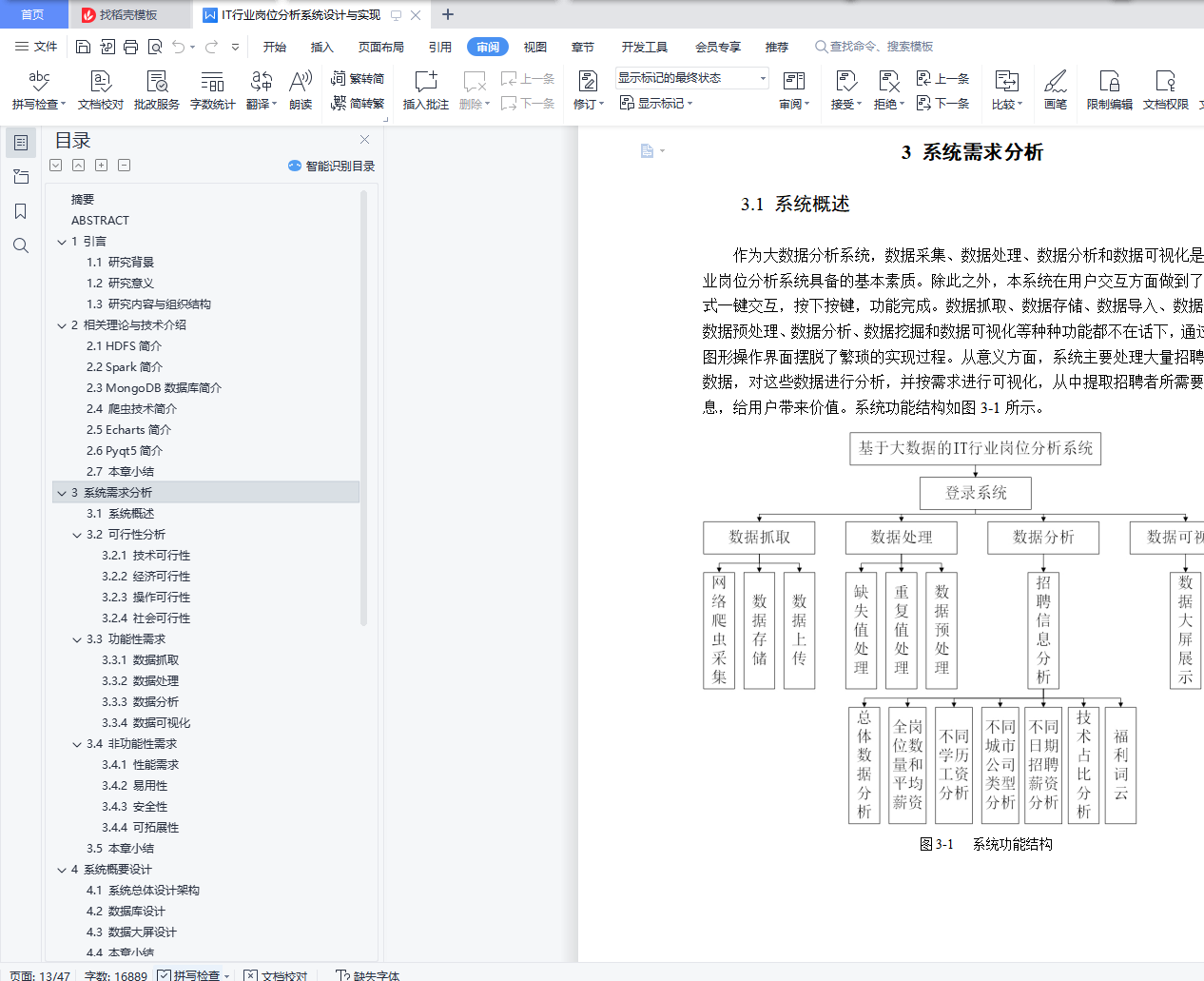
3.1 系统概述 9
3.2 可行性分析 10
3.2.1 技术可行性 10
3.2.2 经济可行性 10
3.2.3 操作可行性 10
3.2.4 社会可行性 11
3.3 功能性需求 11
3.3.1 数据抓取 11
3.3.2 数据处理 11
3.3.3 数据分析 12
3.3.4 数据可视化 12
3.4 非功能性需求 13
3.4.1 性能需求 13
3.4.2 易用性 13
3.4.3 安全性 13
3.4.4 可拓展性 13
3.5 本章小结 14
4 系统概要设计 15
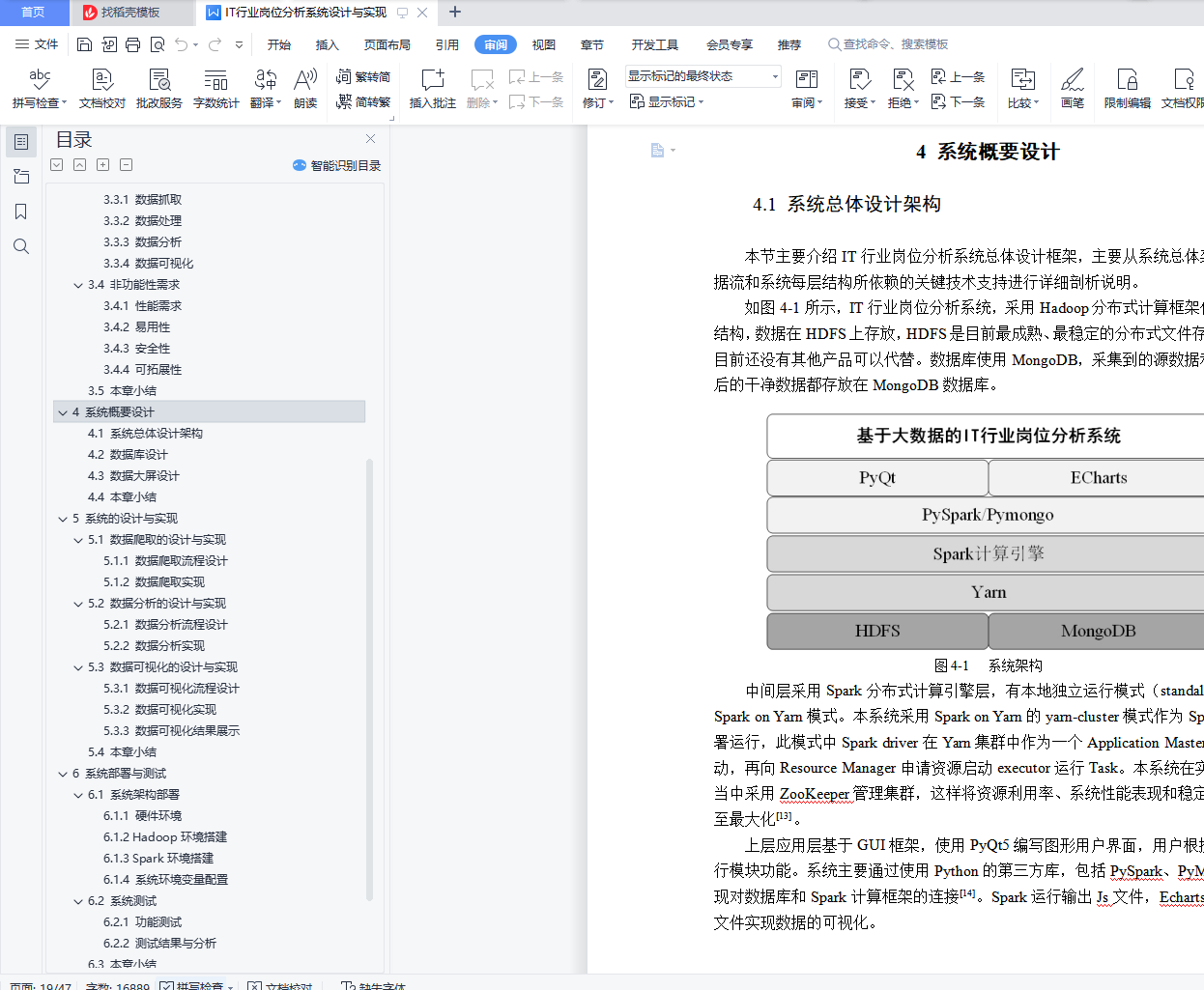
4.1 系统总体设计架构 15
4.2 数据库设计 16
4.3 数据大屏设计 17
4.4 本章小结 18
5 系统的设计与实现 19
5.1 数据爬取的设计与实现 19
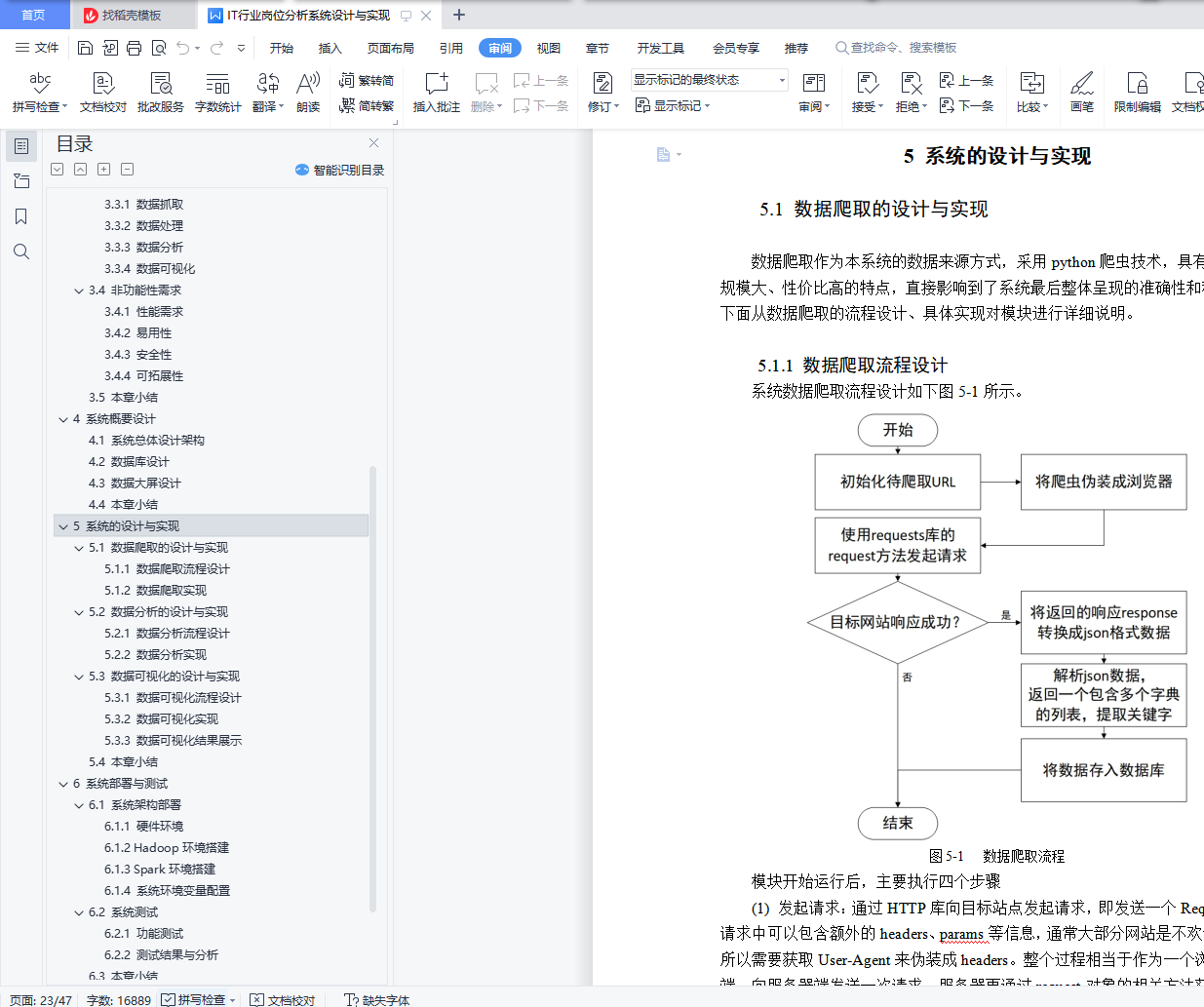
5.1.1 数据爬取流程设计 19
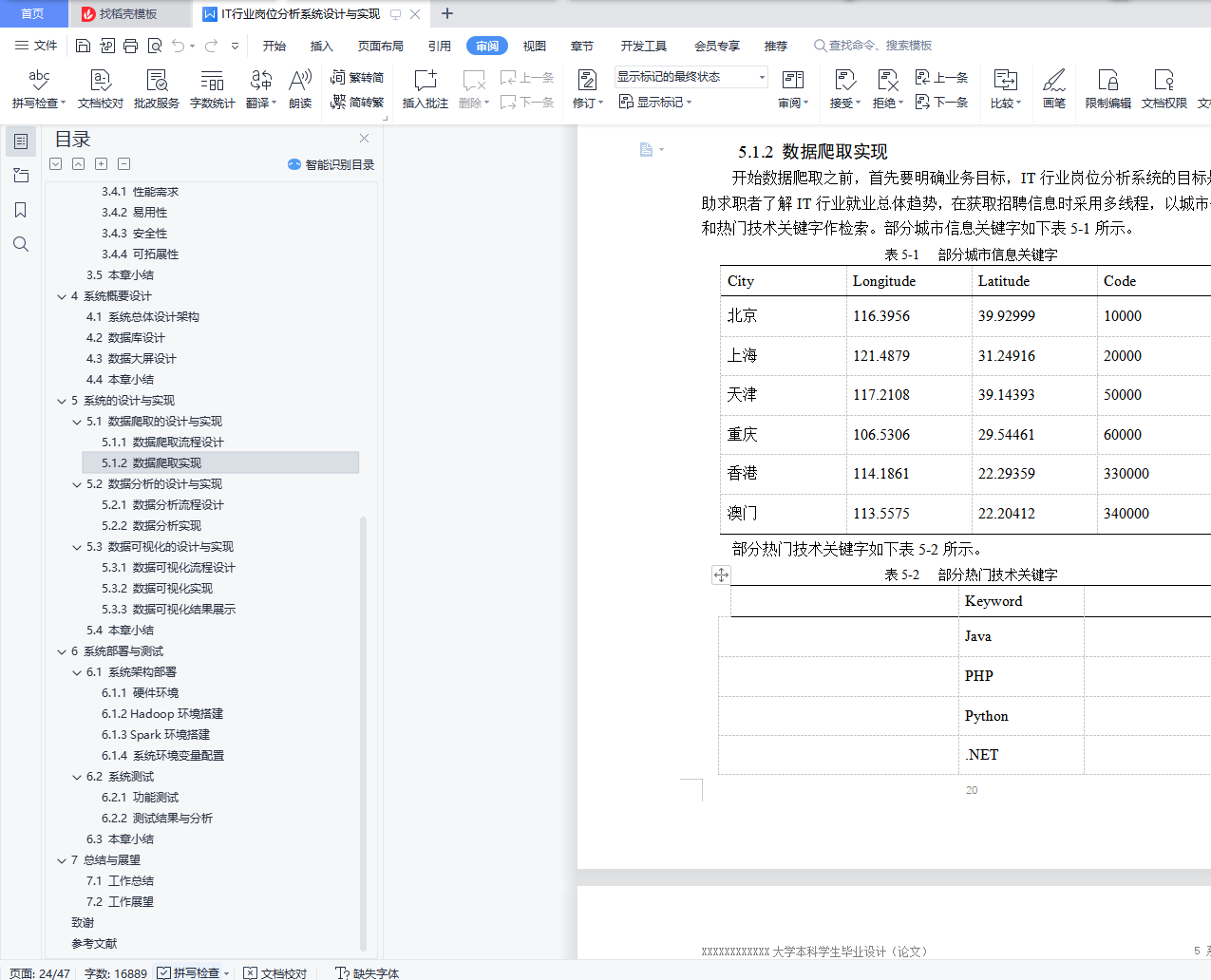
5.1.2 数据爬取实现 20
5.2 数据分析的设计与实现 22
5.2.1 数据分析流程设计 22
5.2.2 数据分析实现 23
5.3 数据可视化的设计与实现 26
5.3.1 数据可视化流程设计 27
5.3.2 数据可视化实现 28
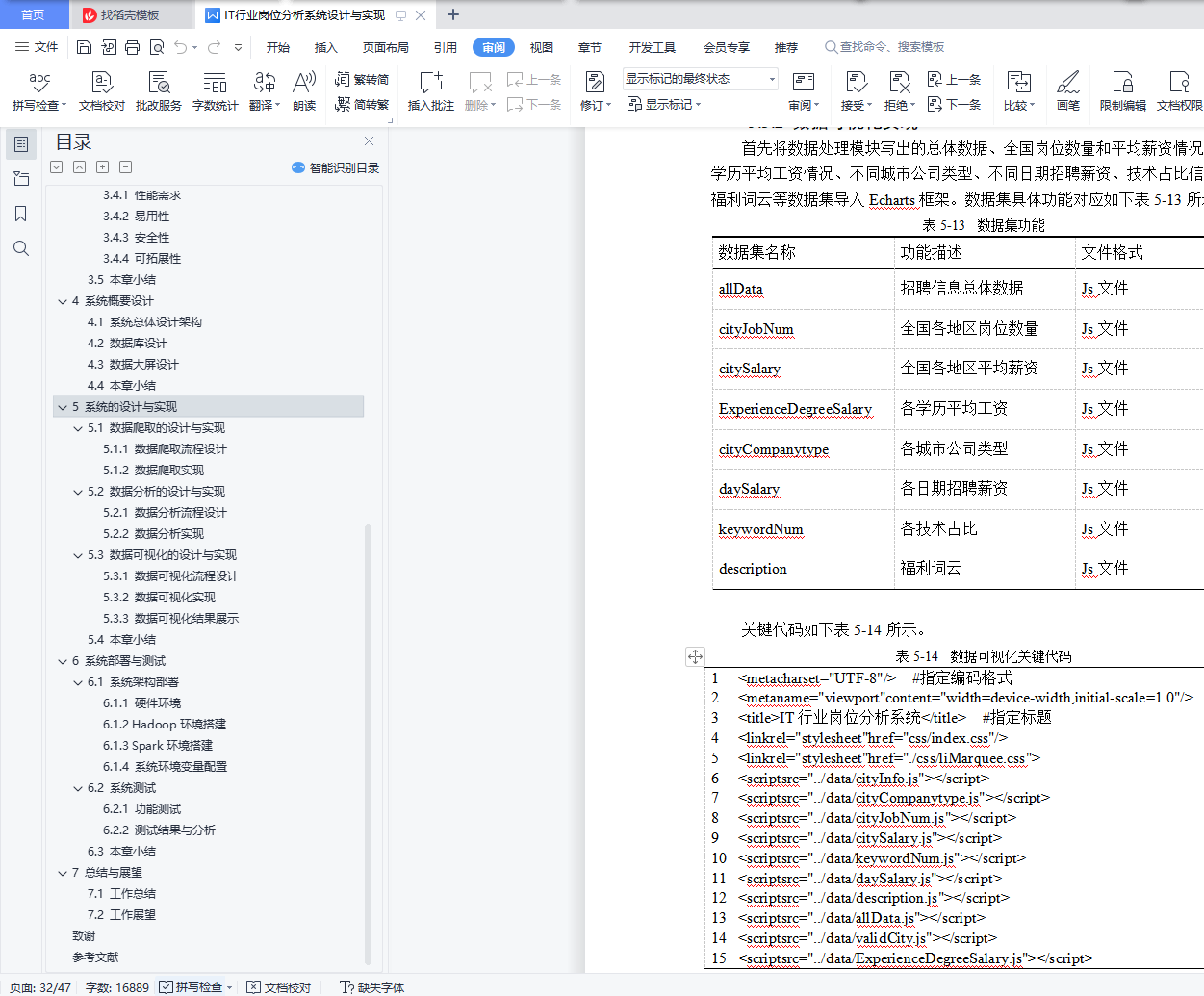
5.3.3 数据可视化结果展示 30
5.4 本章小结 31
6 系统部署与测试 32
6.1 系统架构部署 32
6.1.1 硬件环境 32
6.1.2 Hadoop环境搭建 32
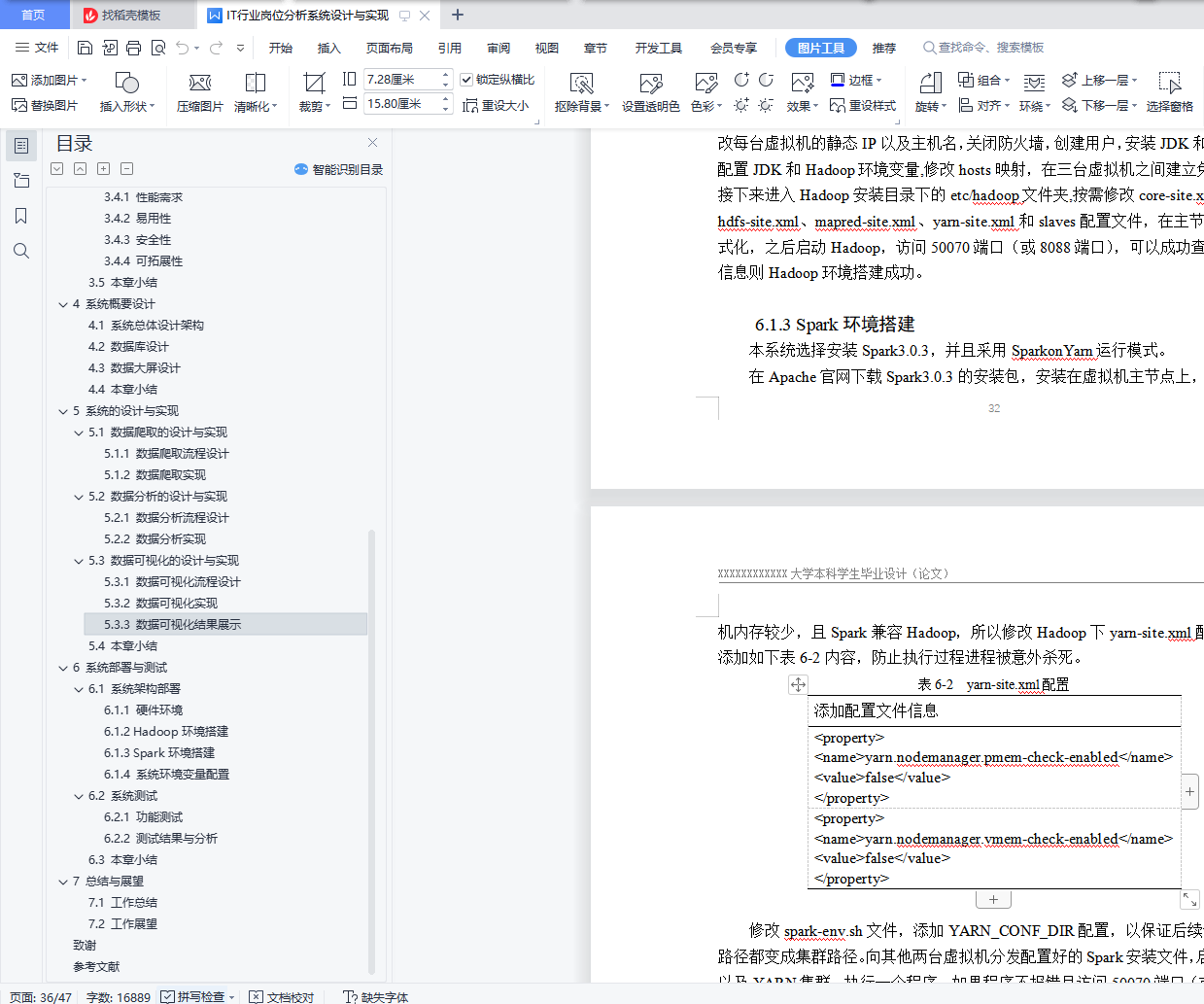
6.1.3 Spark环境搭建 32
6.1.4 系统环境变量配置 33
6.2 系统测试 33
6.2.1 功能测试 34
6.2.2 测试结果与分析 38
6.3 本章小结 38
7 总结与展望 39
7.1 工作总结 39
7.2 工作展望 40
致谢 41
参考文献 42