摘要
随着互联网技术的飞速发展,网络信息以指数型趋势高速增长。对于一个要对数据进行统计分析的系统而言,搜集数据的过程是冗长枯燥的。基于这一现实,分布式爬虫系统获得了发展的契机。系统通过多台服务器的协调运行,成倍地提高了爬虫的效率。当然,分布式系统在获得效率提升的同时也大大增加了系统的复杂程度,开发人员需要考虑多方面因素以确保系统的正常运转。
本文对分布式爬虫系统的架构做了深入的讨论,给出了选择该架构的原因。项目使用了JMS消息队列技术在节点之间异步传递消息,起到应用解耦的效果。使用apache出品的activeMQ作为JMS服务器,能够跨语言跨平台传递消息,而且具有延迟接受的特性,一定程度上降低了网络延迟对系统性能的阻碍。中心节点的任务分配采用线程池技术,缓解了由于任务积累产生的效率瓶颈。
本文先介绍了项目研究背景,然后介绍了分布式爬虫相关知识和本项目所用技术,最后展示了项目的需求分析和体系结构。最终实现的分布式爬虫系统能够做到中心节点分配爬虫任务,任务节点执行爬虫程序并存储数据。同时系统针对一些分布式系统常用的性能需求做了设计,提高了系统的可扩展性和可靠性。
关键词:分布式系统,爬虫,JMS
ABSTRACT
With the rapidly development of Internet technology, network information has grown at an exponential rate. For a system that requires statistical analysis of data, the process of collecting data is tedious. Based on this reality, the distributed crawler system has gained an opportunity for development. The system multiplies the efficiency of crawler by coordinating within several servers. However, the distributed system increases the complexity of the system while gaining efficiency. Developers need to consider various factors to ensure the normal operation of the system.
This article makes an in-depth discussion of the architecture of the distributed crawler system and gives the reasons for choosing certain architecture. The project uses JMS technology to deliver messages asynchronously between nodes, which has the effect of applying decoupling. The project also uses activeMQ from apache as the JMS server, which has the feature of cross-language and cross-platform messages delivery. In addition, activeMQ has the characteristics of delay acceptance. To some extent, it reduces the network delay on the performance of the system. The task allocation of the central node adopts the thread pool technology, which relieves the efficiency bottleneck caused by task accumulation.
In this article, first I introduced the project research background. Then I introduced the distributed crawler knowledge and technology used in this project. Finally I demonstrated the project's requirement analysis and architecture. The distributed crawler system this article implemented can distribute tasks by central node, and execute crawler programs and store data by task nodes. At the same time, the system is designed for the common performance requirements of distributed systems, which improves the system's scalability and reliability.
KEY WORDS: distributed system, crawler, JMS
目录
本科生毕业论文(设计)中文摘要 I
本科生毕业论文(设计)英文摘要 II
目录 I
图目录 III
表目录 IV
第一章 引言 1
1.1 研究背景 1
1.1.1 SourceForge.net 1
1.1.2 需求复用 1
1.1.3 实验项目 1
1.1.4 爬虫简介 2
1.2 国内外研究现状 2
1.2.1 java爬虫框架 2
1.2.2 python爬虫框架 2
1.3 本文的主要研究内容 3
1.4 论文的主要工作和组织结构 3
第二章 分布式爬虫综述 4
2.1 分布式爬虫类型 4
2.1.1 应用于搜索引擎 4
2.2.2 基于主题的爬虫 4
2.2.3 用户个性化爬虫 4
2.2 MapReduce 5
2.3 分布式爬虫系统的架构 6
2.3.1 主从式 6
2.3.2 自治式 7
2.3.3 混合式 7
2.4 爬取策略 8
2.5 部署网络 8
第三章 技术基础 9
3.1 网络通信技术 9
3.1.1 RPC 9
3.1.2 WebService 9
3.1.3 RMI 10
3.1.4 JMS 11
3.1.5 activeMQ 14
3.2 队列 14
3.3 线程池 14
3.4 jsoup 16
第四章 需求分析和概要设计 17
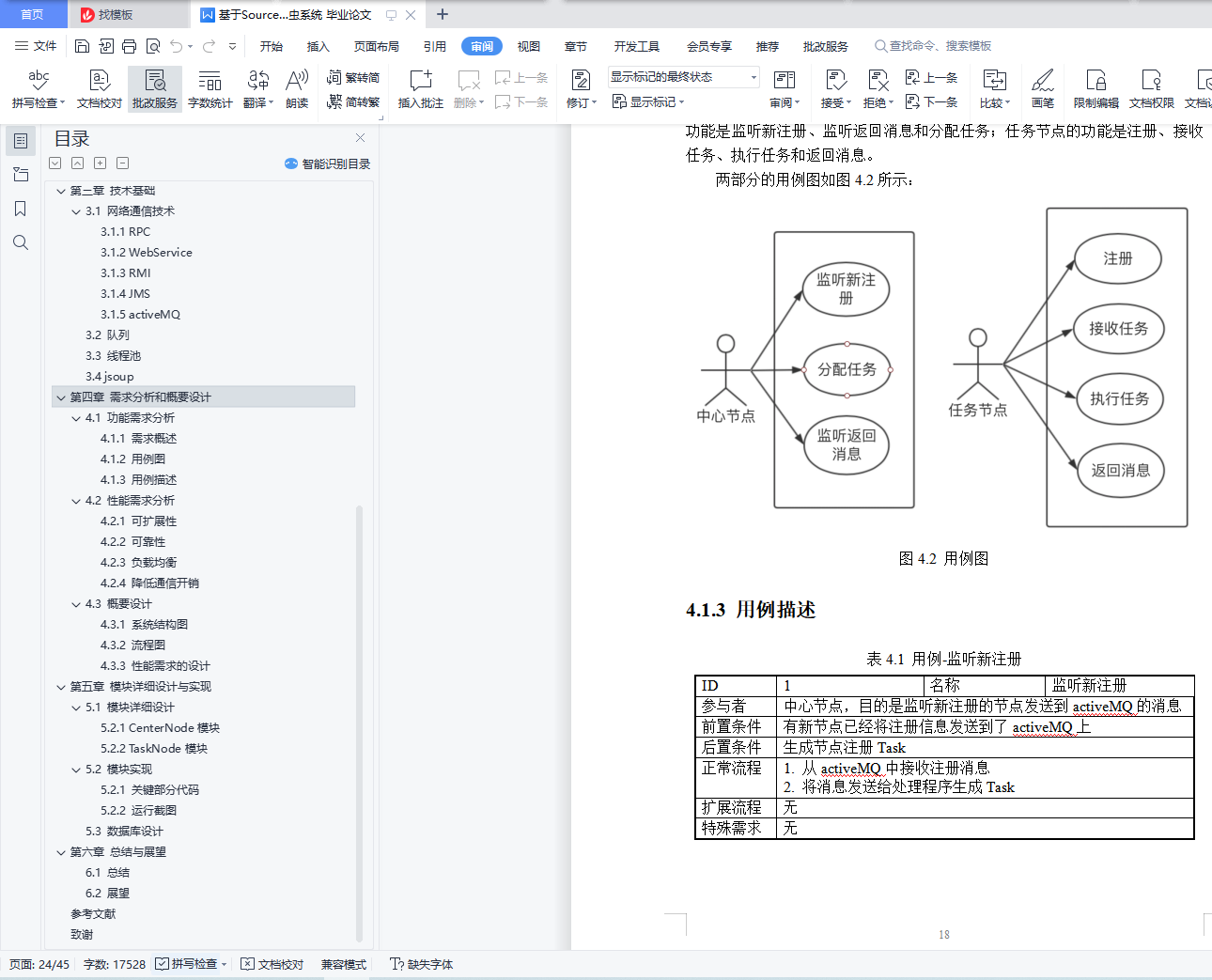
4.1 功能需求分析 17
4.1.1 需求概述 17
4.1.2 用例图 18
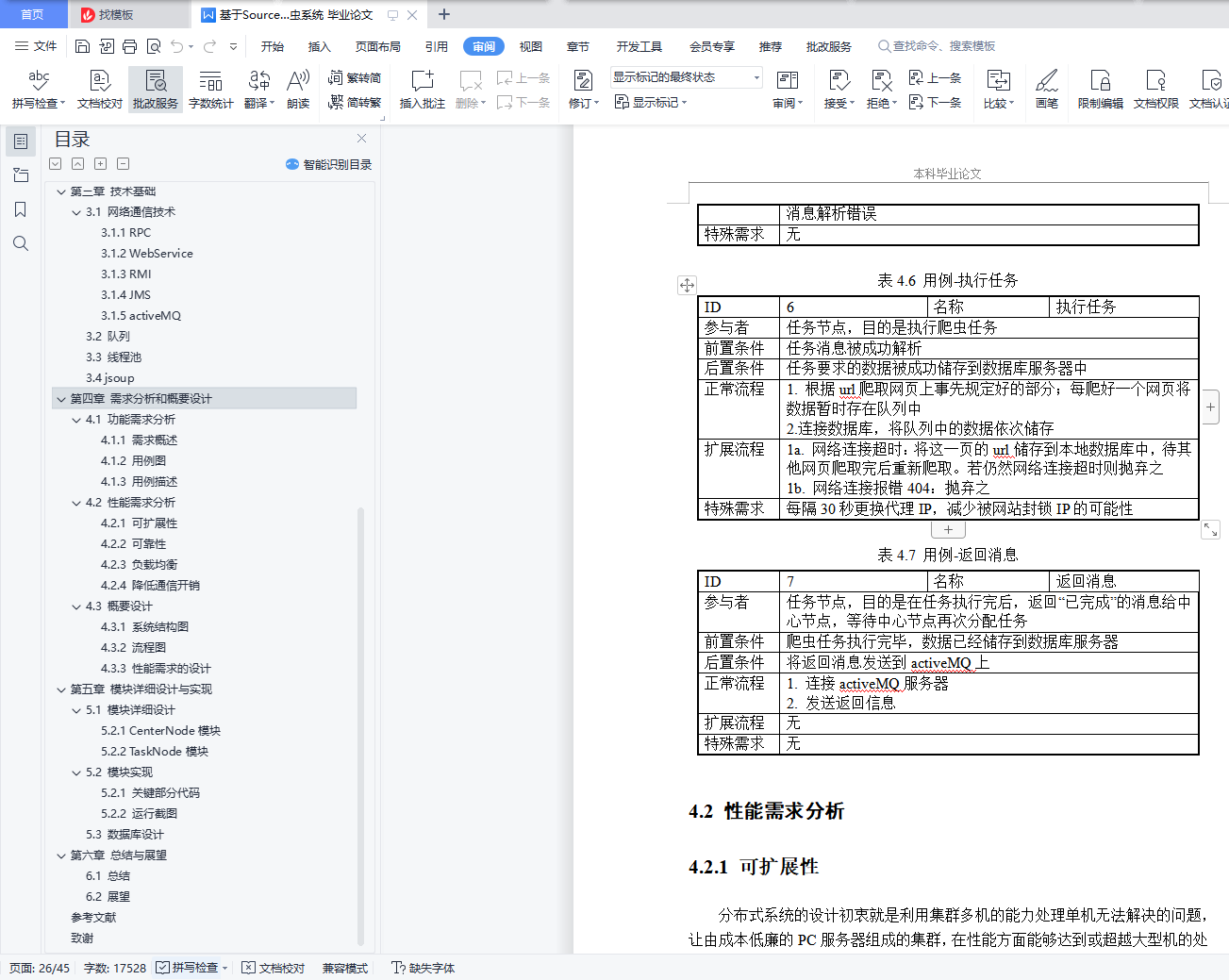
4.1.3 用例描述 18
4.2 性能需求分析 20
4.2.1 可扩展性 20
4.2.2 可靠性 21
4.2.3 负载均衡 21
4.2.4 降低通信开销 21
4.3 概要设计 21
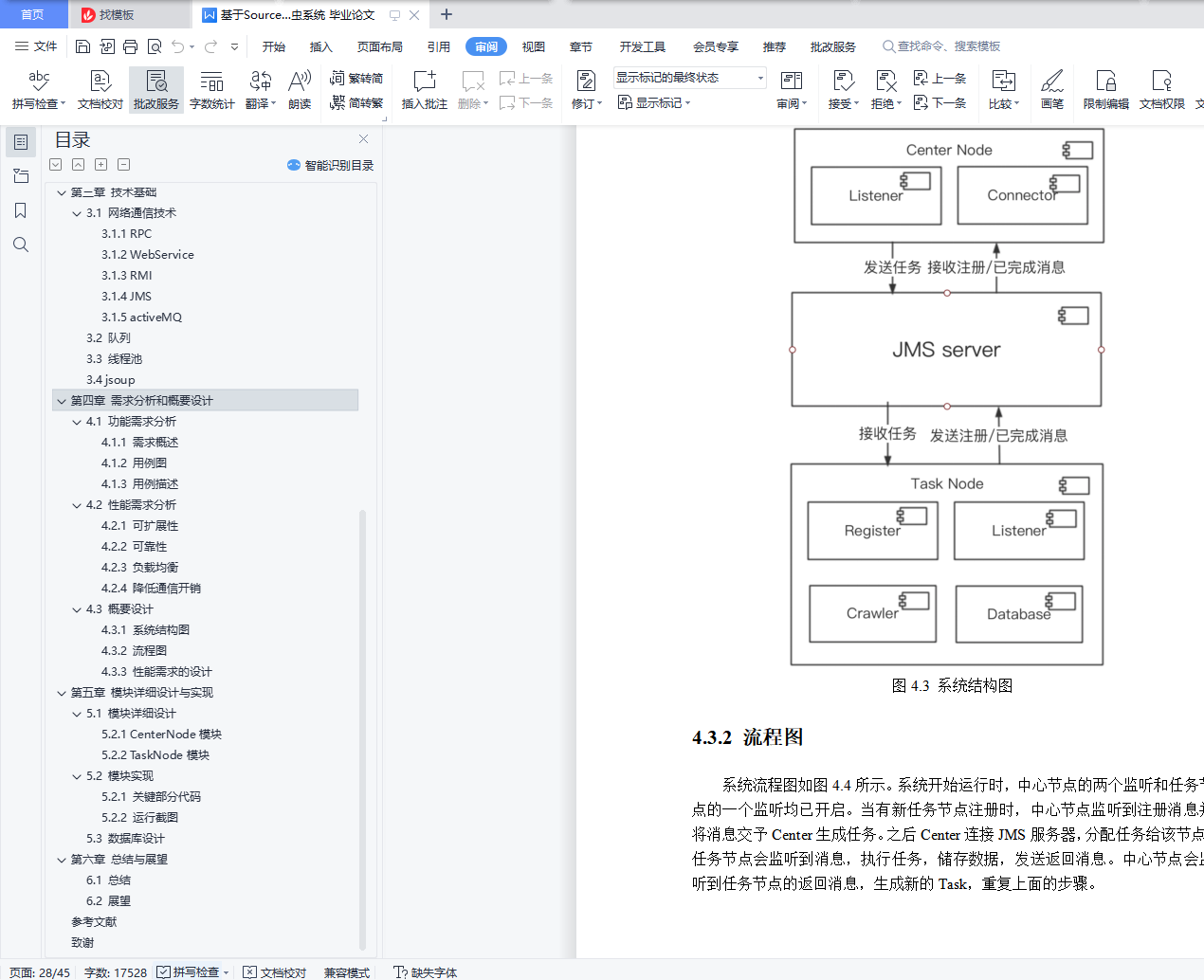
4.3.1 系统结构图 21
4.3.2 流程图 22
4.3.3 性能需求的设计 23
第五章 模块详细设计与实现 25
5.1 模块详细设计 25
5.2.1 CenterNode模块 25
5.2.2 TaskNode模块 27
5.2 模块实现 30
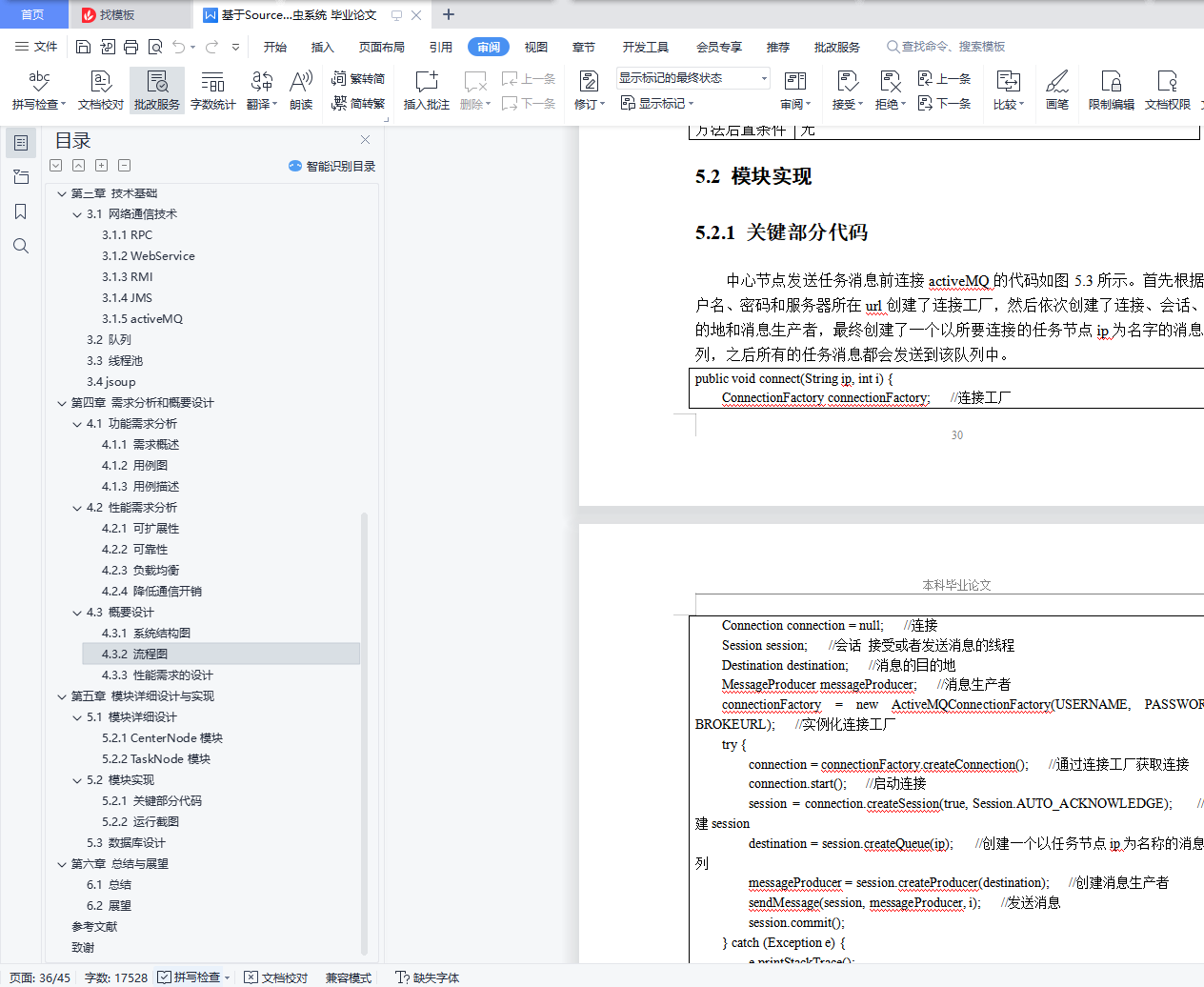
5.2.1 关键部分代码 30
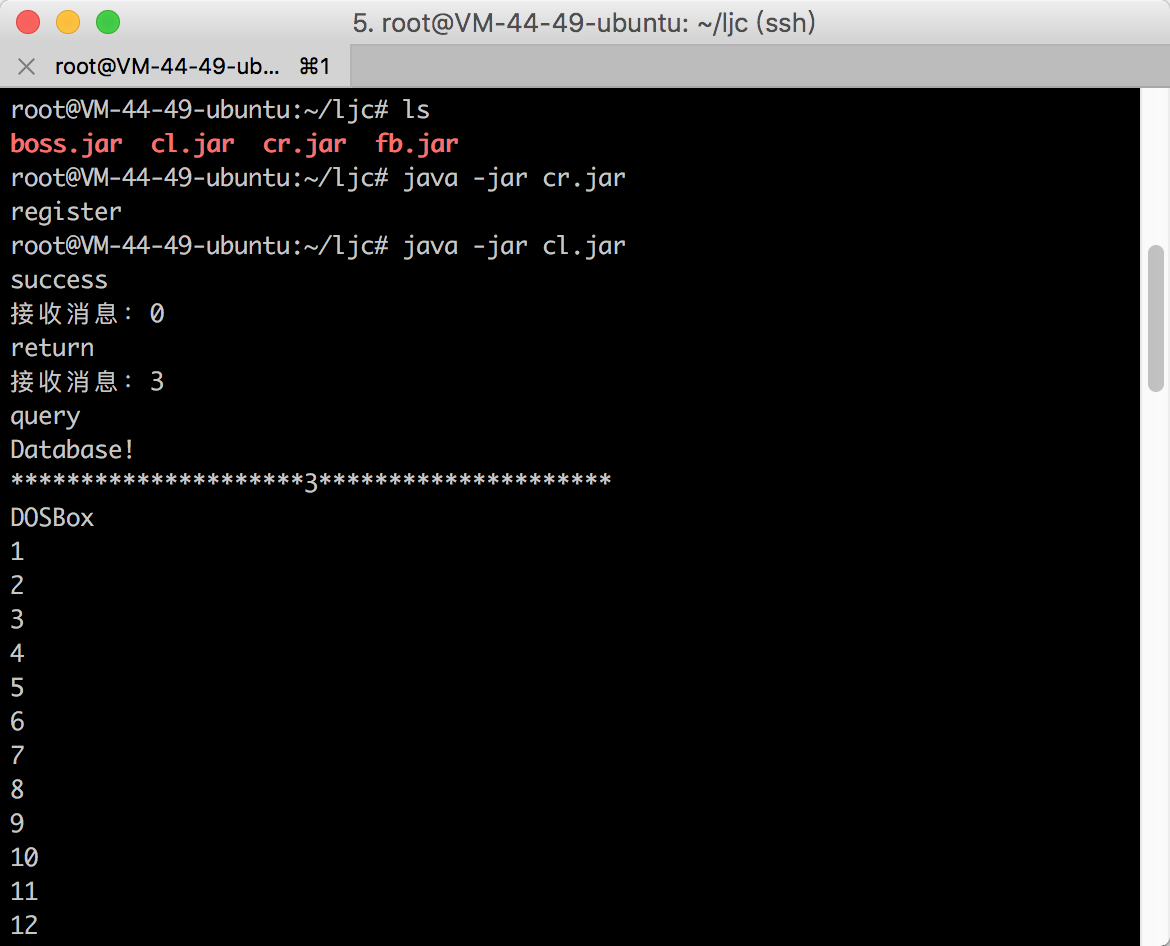
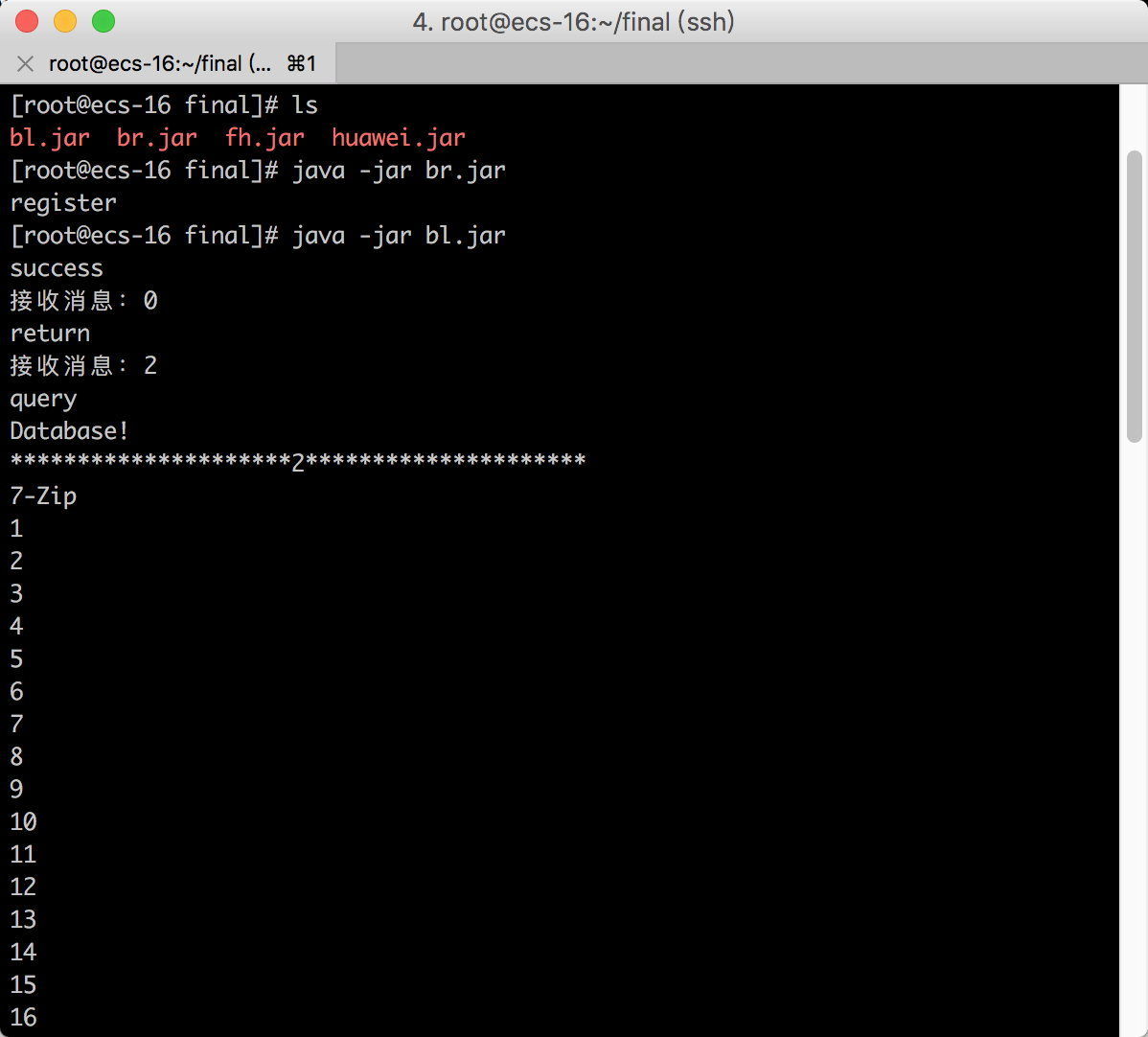
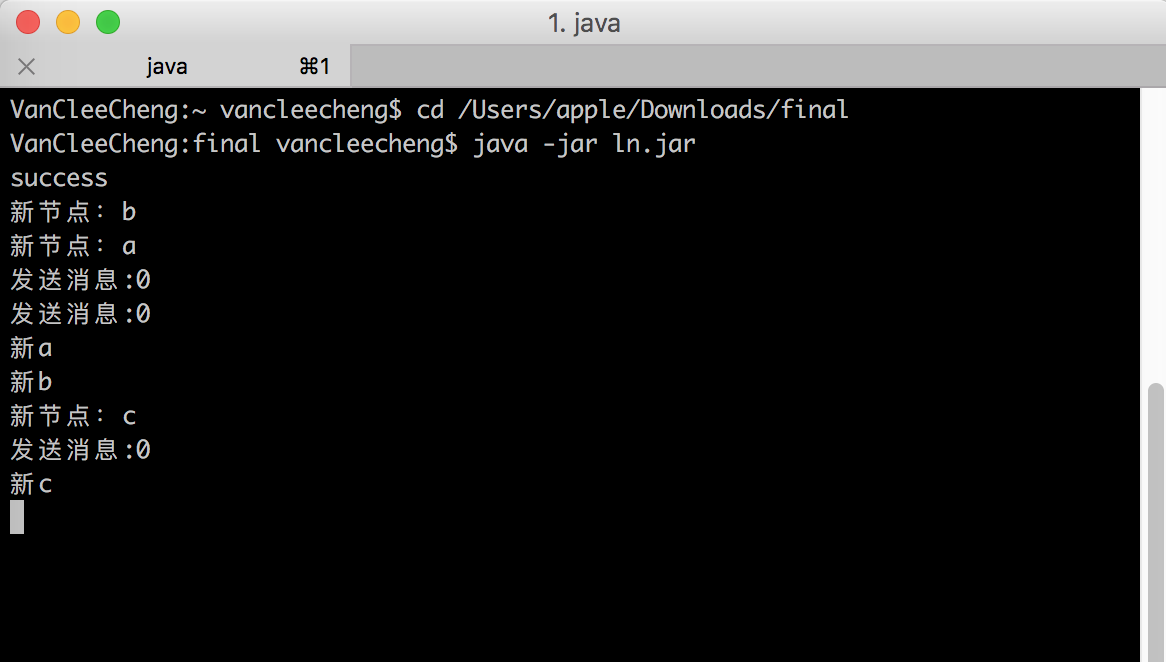
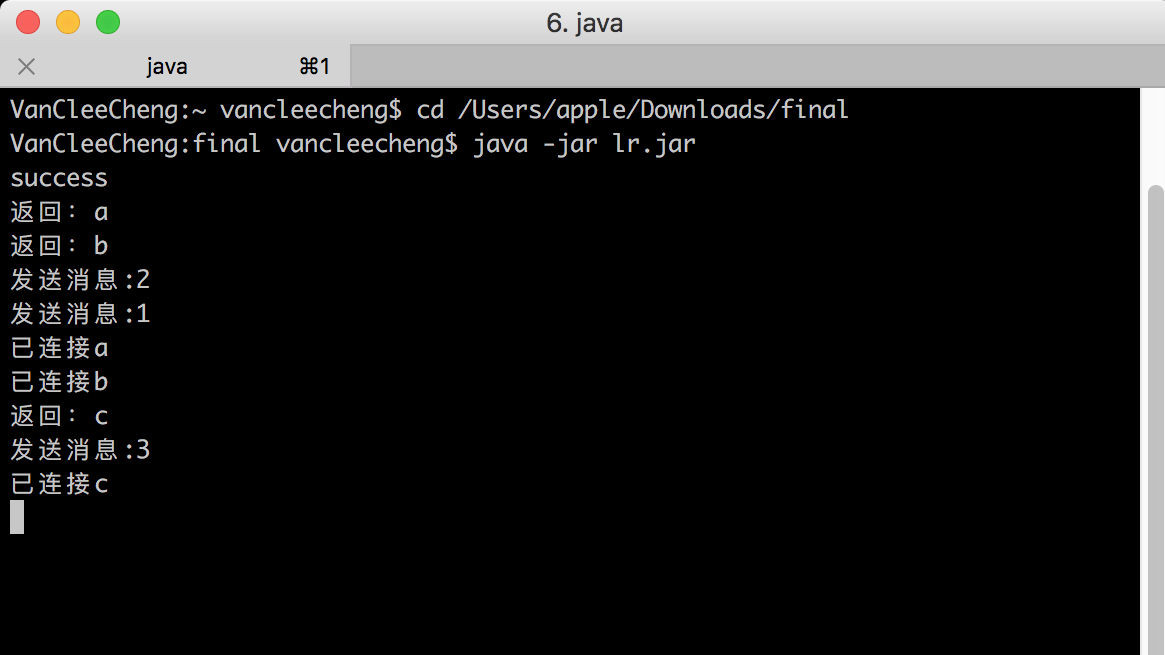
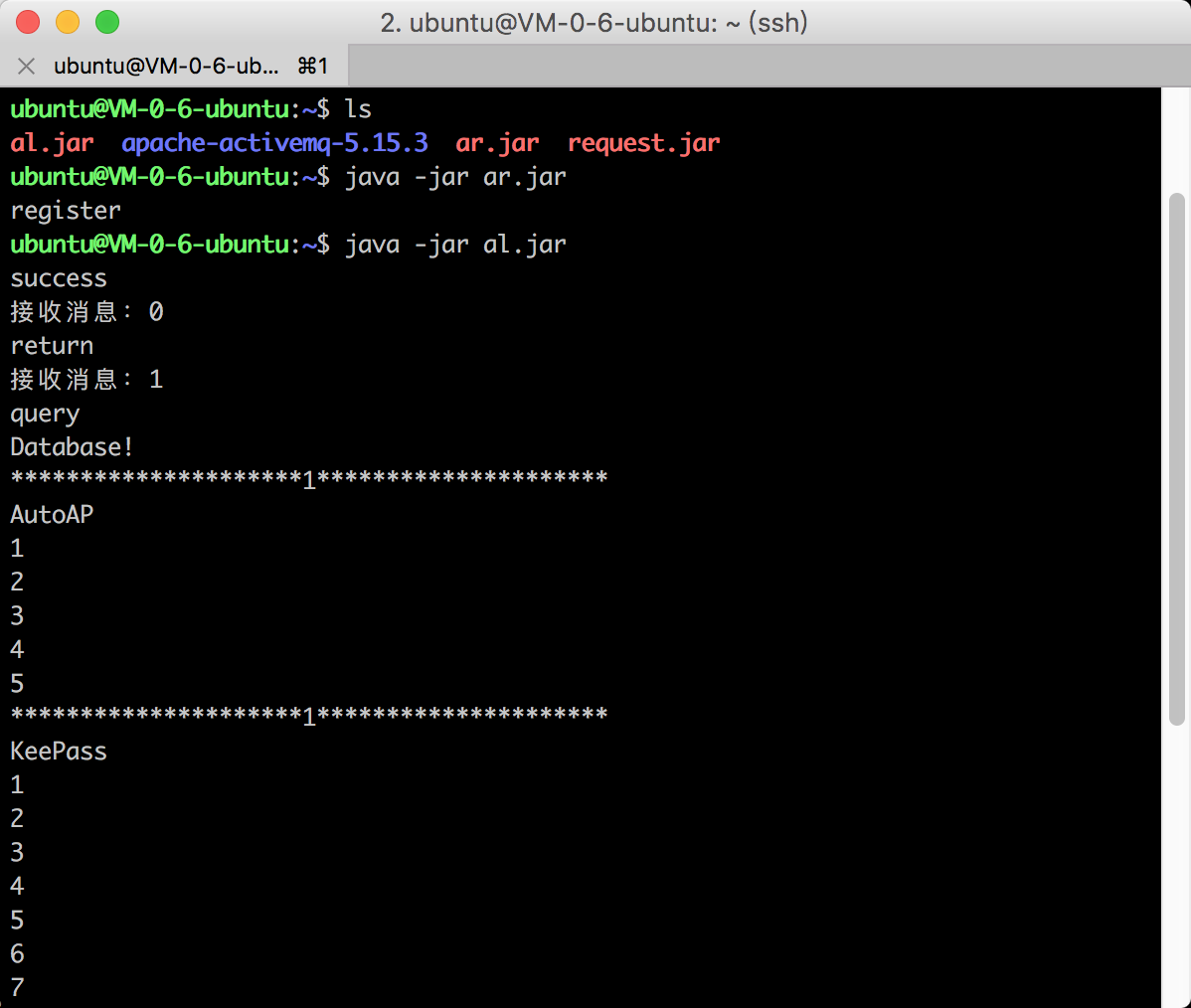
5.2.2 运行截图 33
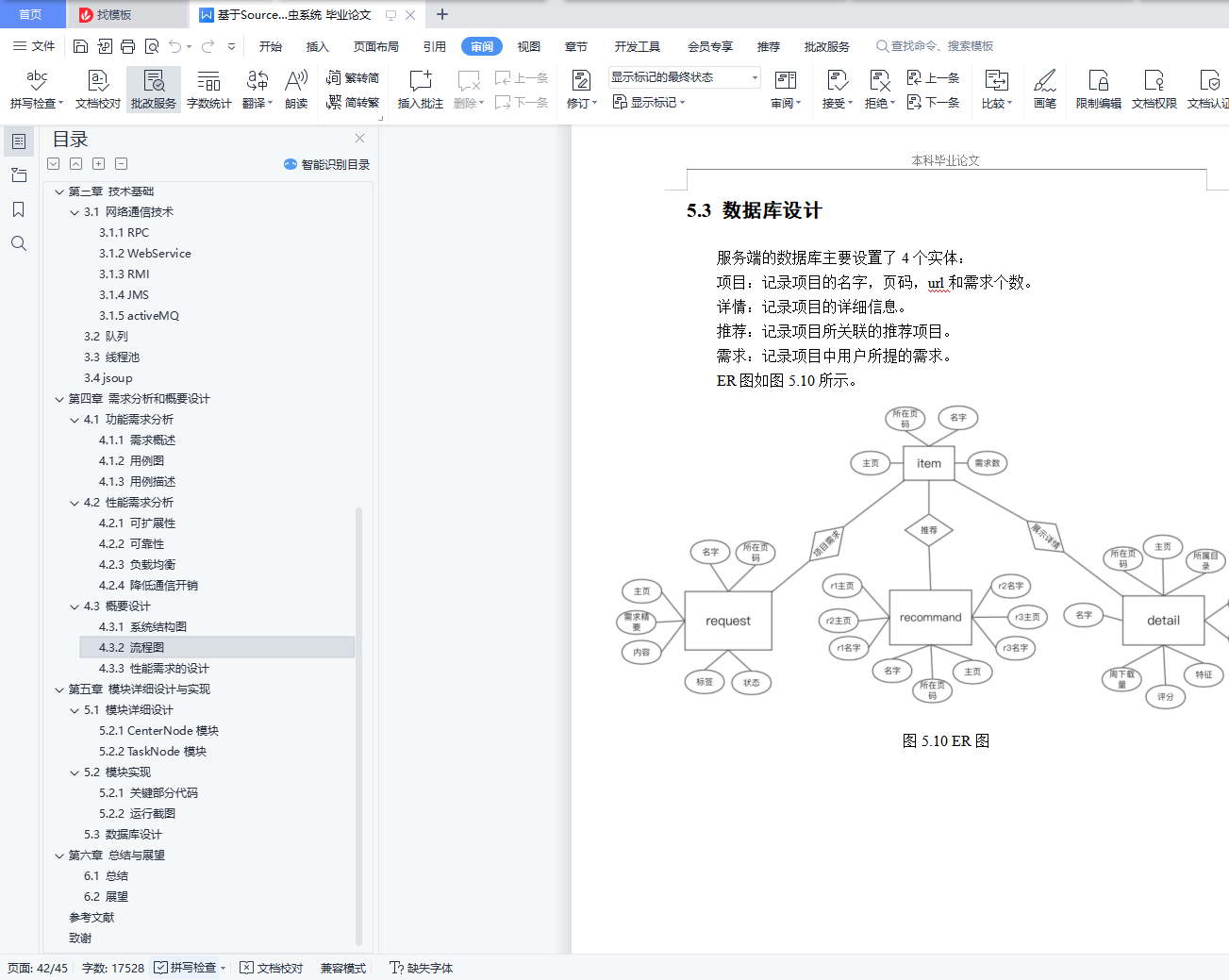
5.3 数据库设计 36
第六章 总结与展望 37
6.1 总结 37
6.2 展望 37
参考文献 38
致谢 39