关于电影推荐的自然语言处理
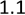 语料库的建立
语料库的建立
进行语料处理时我们会遇到的主要问题之一就是如何将大的数据集读入内存当中然后进行相应的处理。

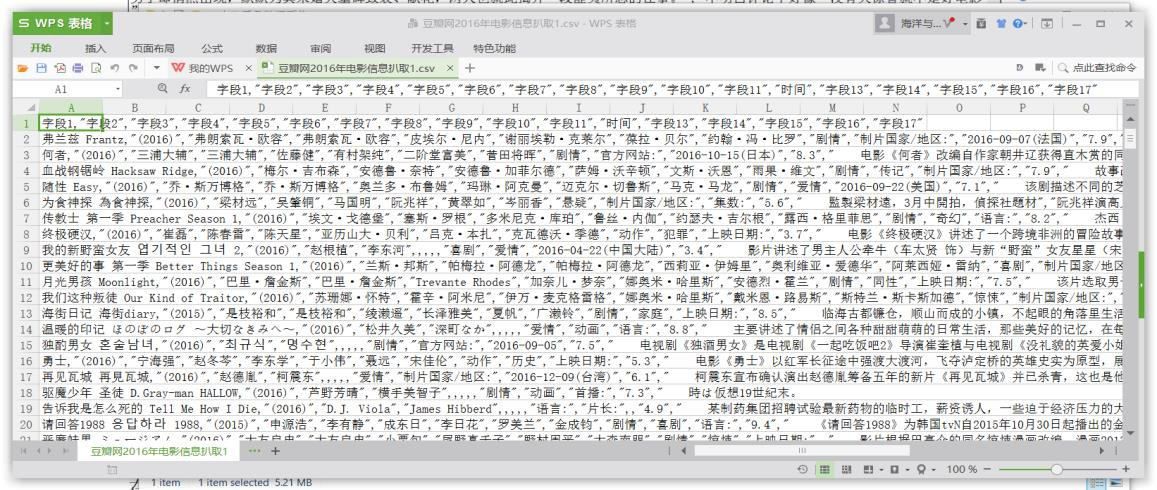
(图中所示的数据集是豆瓣网上 5000 部电影描述信息的分词结果,每一行的数据是一部电影的所有信息。不过从数据大小上看,该数据集属于小的数据集,大的数据集从容量上讲就是以 GB 甚至以 TB 为单位)
1.1.1 Linecache 模块
对于大的数据,python 提供了很多的功能进行读取,其中之一就是 linecache 模块。
Linecache 模块功能非常强大,其中包含了多种函数进行调用 linecache.getlines(filename)可以读取文件中的所有内容。linecache.getline(filename,lineno)可以读取文件中的任意行。另外, 普通的文件读取方式都是类似于:m=open("F:\\Programming…, 在 python 语言当中,这样的文件读取方式是非常不适合大型数据的读取的,因为一旦采用这种形式进行数据的读取,就会导致所读文件整体被写入内存当中,如果文件过大,内存就无法存储,读取一定会失败。不过,linecache 模块的读取是一种类似于迭代器形式的读取,从而可以使得在读取大的文件的时候不会将所有的文件一次性全部读入,导致因为内存不够产生的程序错误。