摘 要
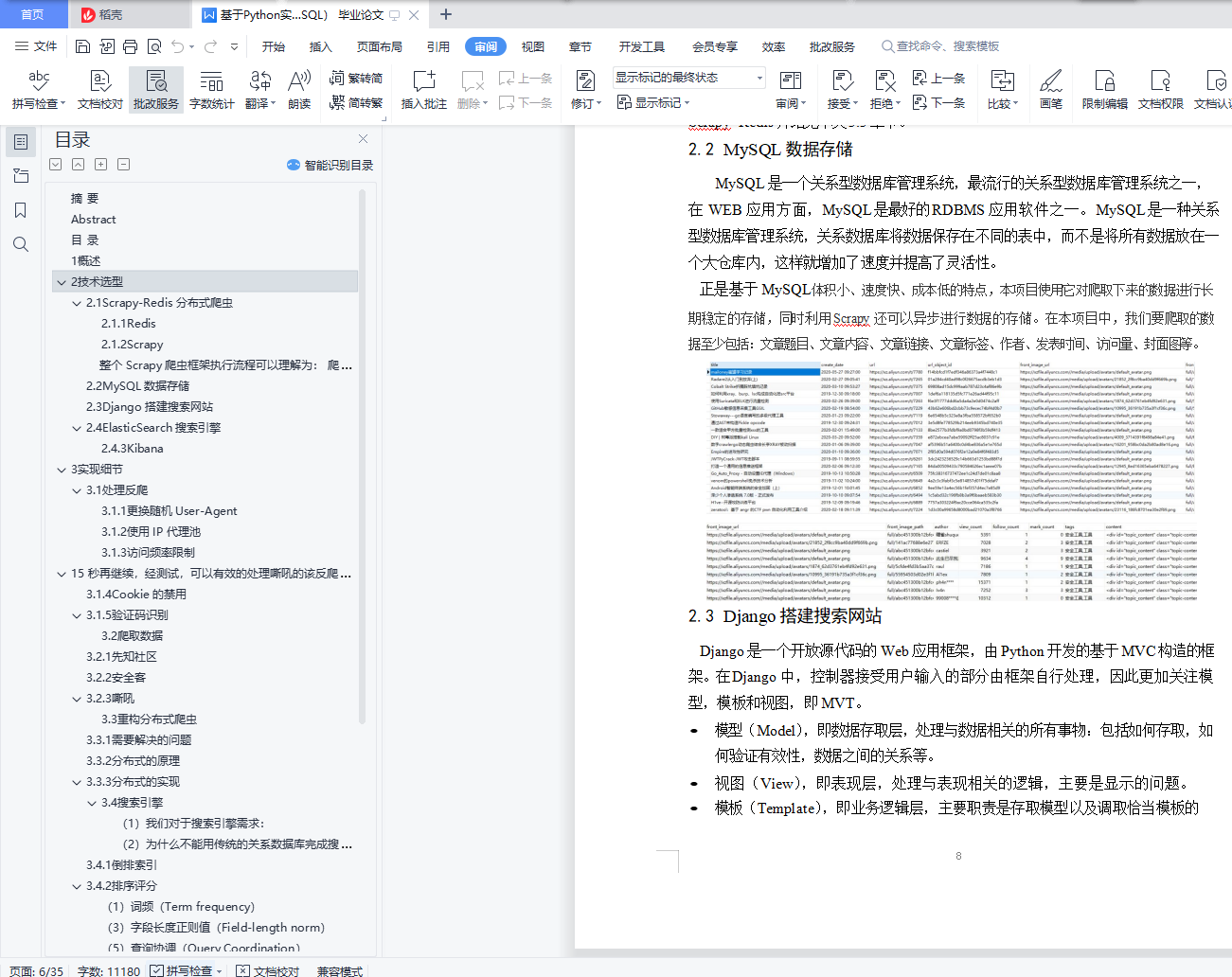
随着大数据时代的到来,信息的获取与检索尤为重要,如何在海量的数据中快速准确获取到我们需要的内容显得十分重要。因此本项目为了更好的整合利用安全领域特有的社区资源优势,首先使用 Scrapy 爬虫框架结合 NoSQL 数据库 Redis 编写分布式爬虫,并对先知、安全客、嘶吼三个知名安全社区进行技术文章的爬取;然后选取 ElasticSearch 搭建搜索服务,同时提供了 RESTful web 接口;最后通过 Django 搭建可视化站点,供用户透明的对文章进行搜索。
关键词: 分布式爬虫; Scrapy; 搜索引擎; Redis
Abstract
With the advent of the era of big data, the acquisition and retrieval of information is particularly important. How to get the content we need quickly and accurately in massive data is very important. Therefore, in order to better integrate and utilize the unique community resource advantage in the security field, this project firstly uses the Scrapy crawler framework combined with NoSQL database Redis to write distributed crawler, and then crawl for technical articles to three well-known security communities: XianZhi, AnQuanKe and RoarTalk. Then select ElasticSearch to build the search service while providing a RESTful Web interface. Finally, the visual site is built through Django for users to search articles transparently.
Key words: distributed crawler; Scrapy; Search engines; Redis
目 录
摘 要.............................................................. 1
1 概述.............................................................. 6
2 技术选型.......................................................... 6
2.1 Scrapy-Redis 分布式爬虫 ..................................... 6
2.1.1 Redis................................................. 6
2.1.2 Scrapy................................................ 7
2.2 MySQL 数据存储 .............................................. 8
2.3 Django 搭建搜索网站 ......................................... 8
2.4 ElasticSearch 搜索引擎 ...................................... 9
2.4.1 Elasticsearch-RTF..................................... 9
2.4.2 Elasticsearch-head................................... 10
2.4.3 Kibana............................................... 10
3 实现细节......................................................... 10
3.1 处理反爬................................................... 10
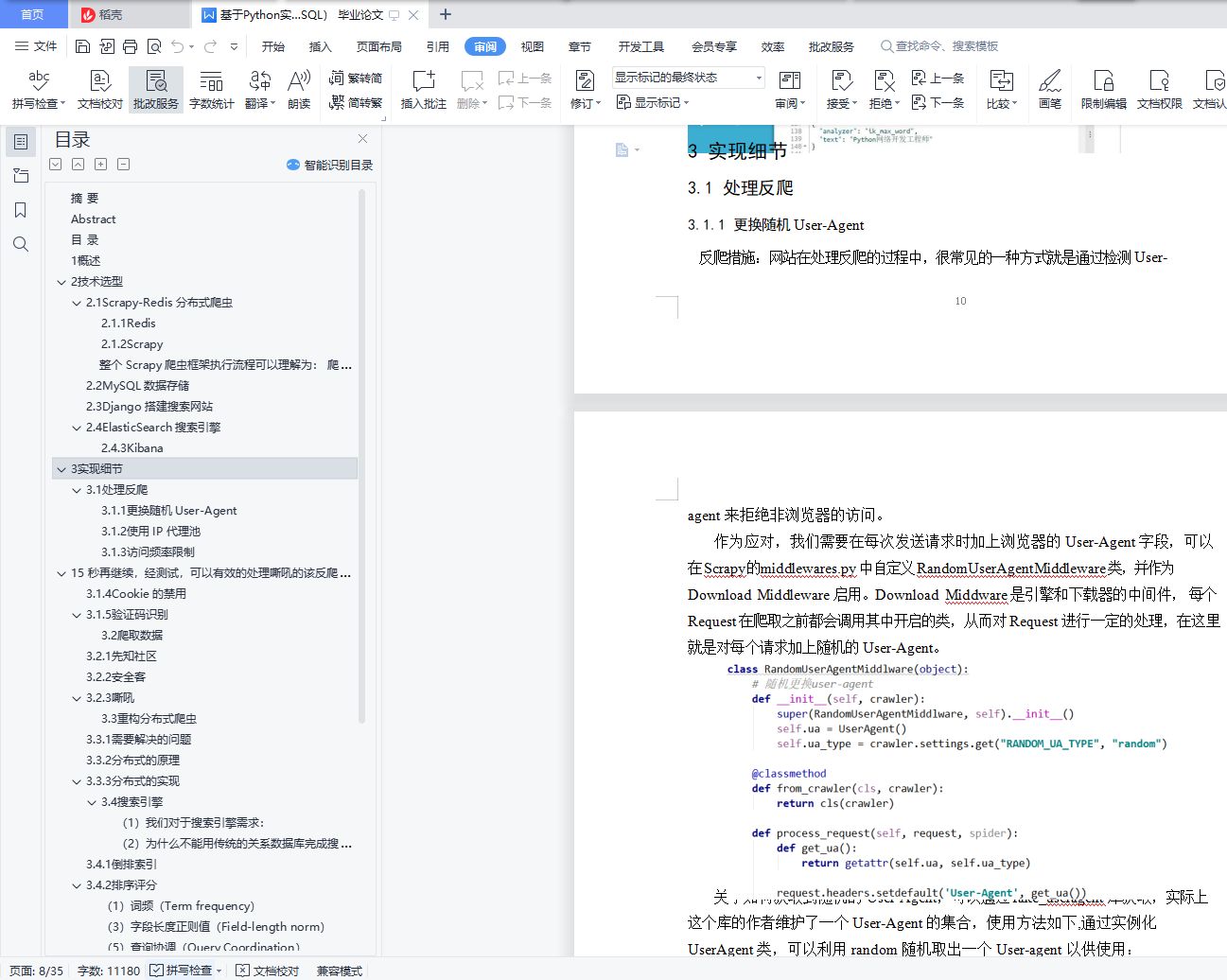
3.1.1 更换随机 User-Agent .................................. 10
3.1.2 使用 IP 代理池........................................ 11
3.1.3 访问频率限制......................................... 12
3.1.4 Cookie 的禁用 ........................................ 13
3.1.5 验证码识别........................................... 13
3.2 爬取数据................................................... 14
3.2.1 先知社区............................................. 14
3.2.2 安全客............................................... 17
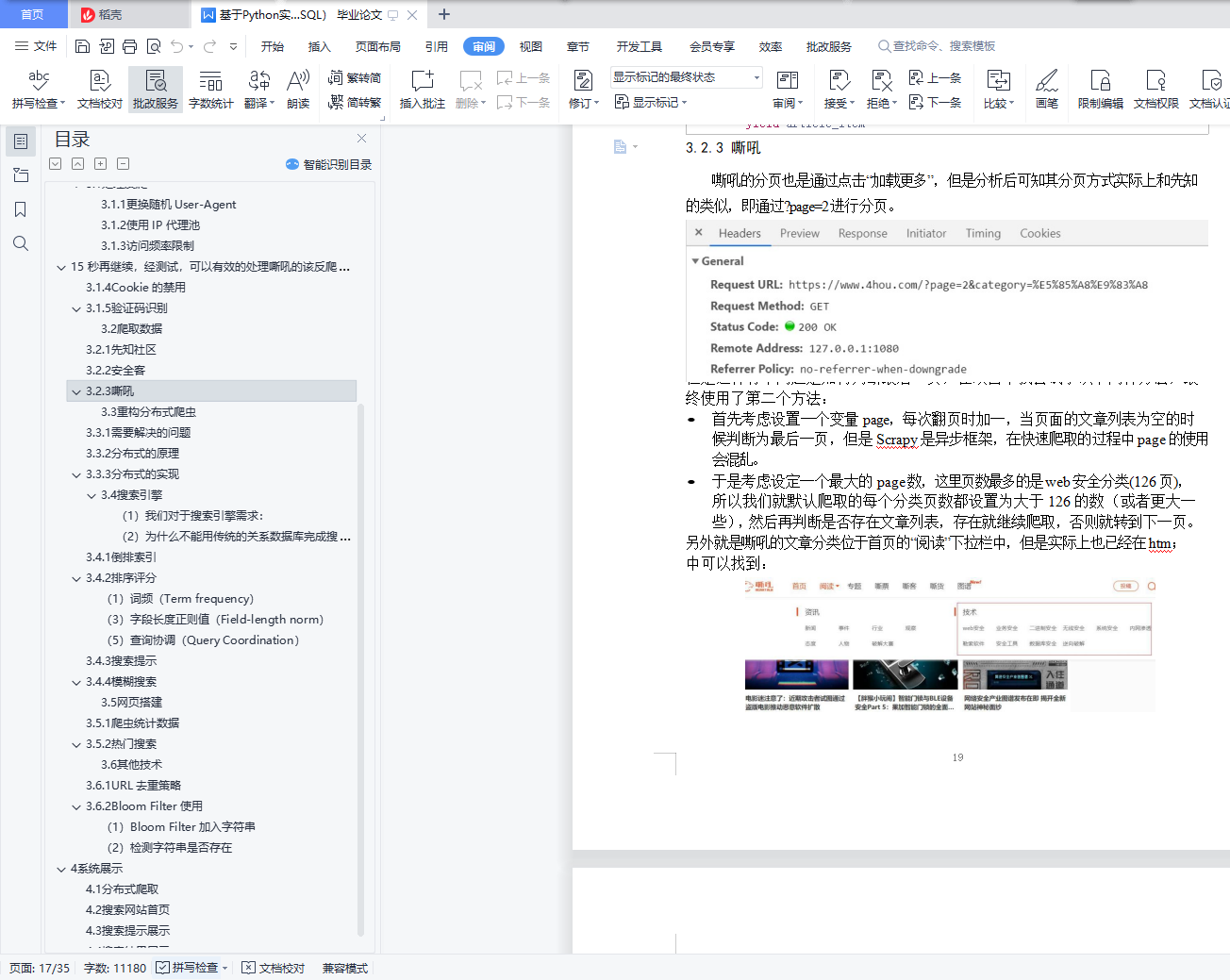
3.2.3 嘶吼................................................. 19
3.3 重构分布式爬虫............................................. 21
3.3.1 需要解决的问题....................................... 21
3.3.2 分布式的原理......................................... 22
3.3.3 分布式的实现......................................... 23
3.4 搜索引擎................................................... 24
3.4.1 倒排索引............................................. 24
3.4.2 排序评分............................................. 25
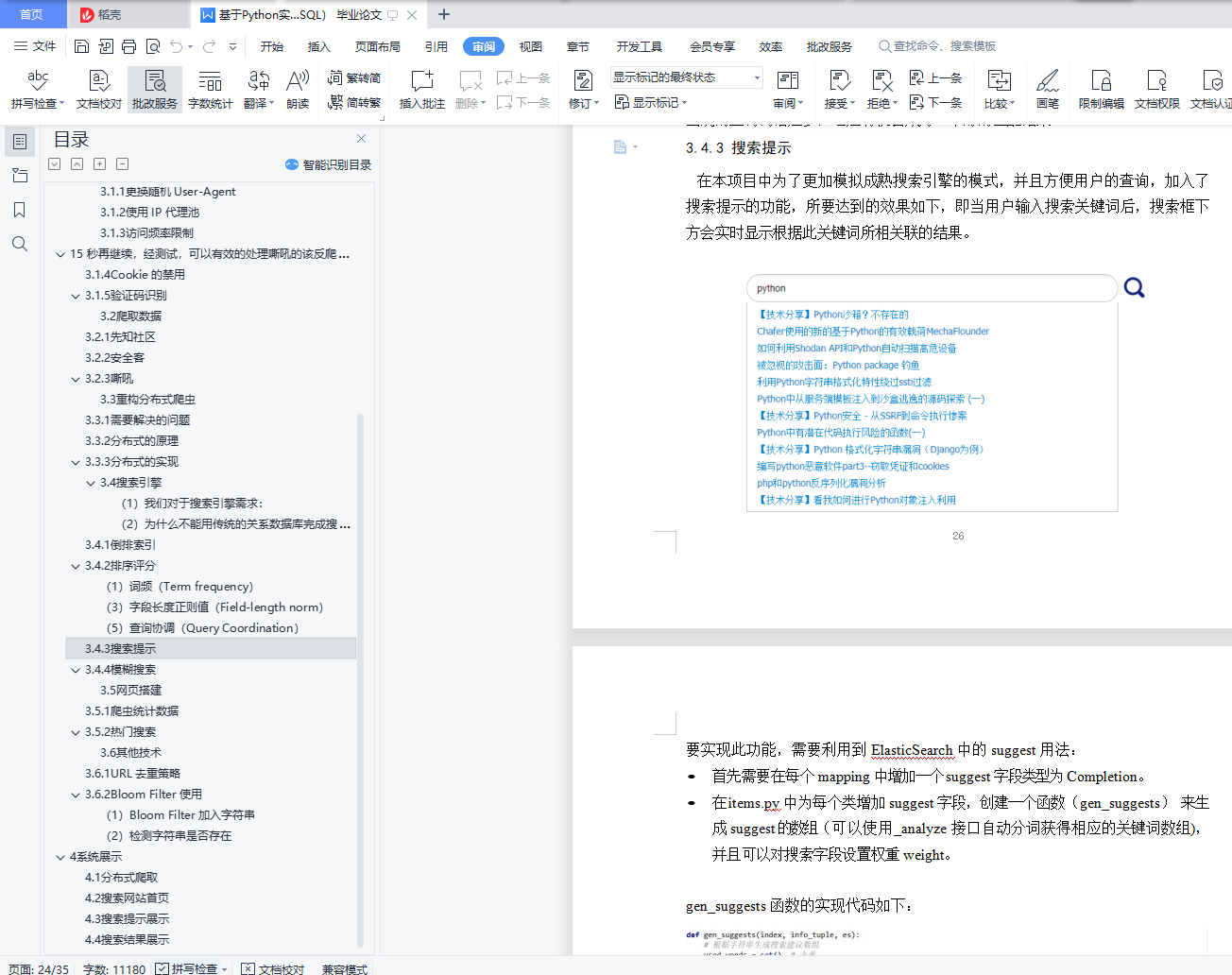
3.4.3 搜索提示............................................. 26
3.4.4 模糊搜索............................................. 27
3.5 网页搭建................................................... 28
3.5.1 爬虫统计数据......................................... 28
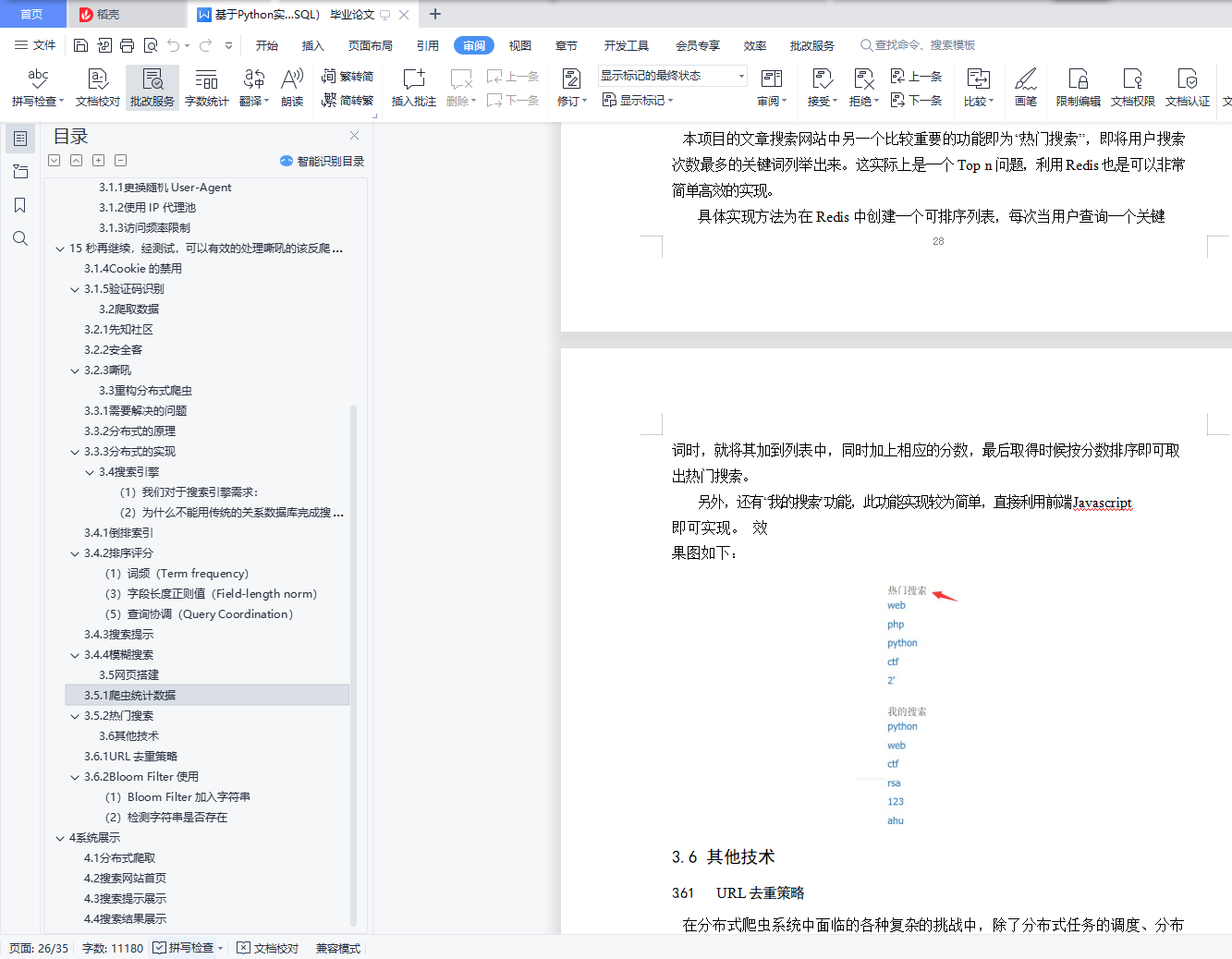
3.5.2 热门搜索............................................. 28
3.6 其他技术................................................... 29
3.6.1 URL 去重策略 ......................................... 29
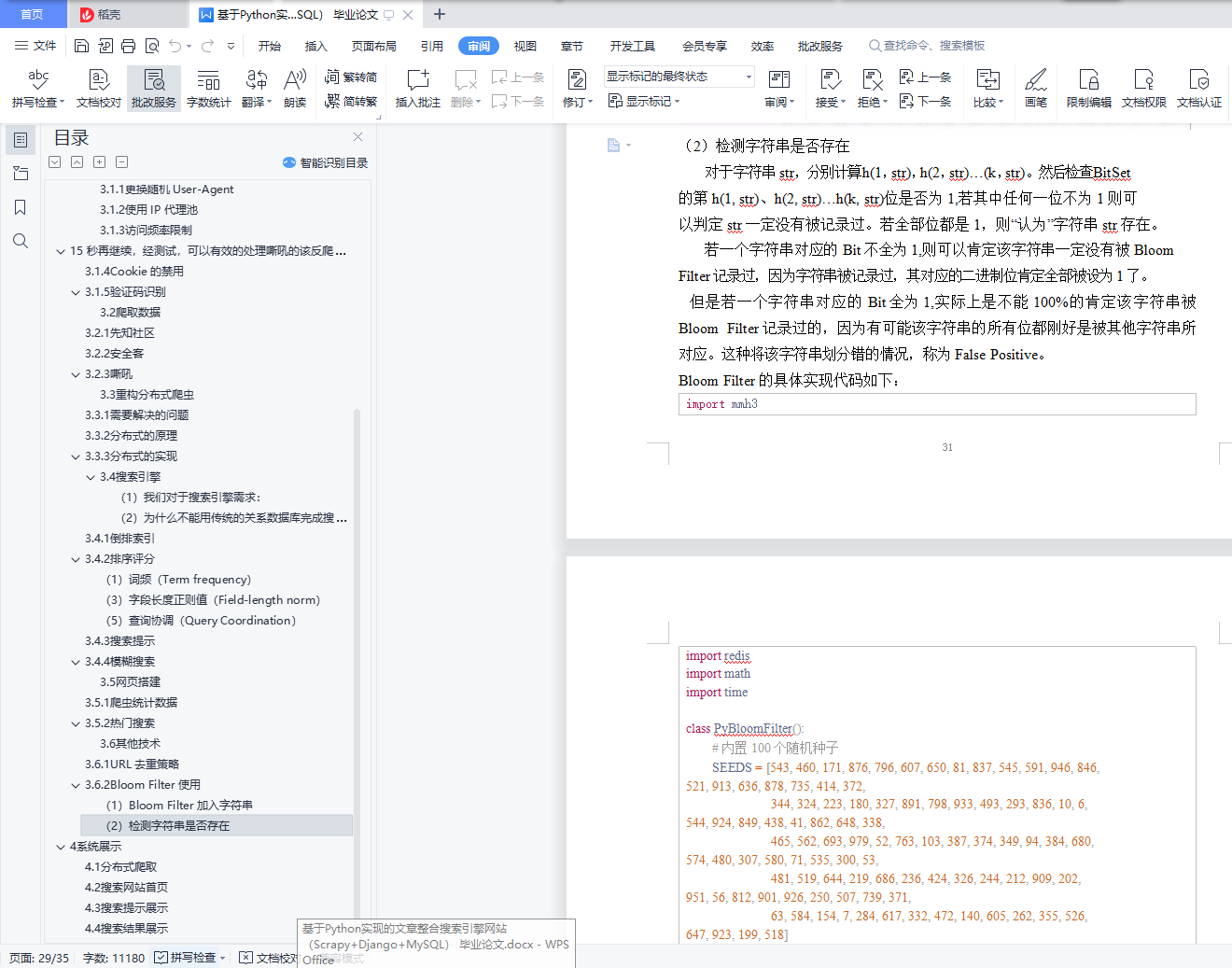
3.6.2 Bloom Filter 使用 .................................... 31
4 系统展示 ......................................................... 34
4.1 分布式爬取................................................. 34
4.2 搜索网站首页............................................... 36
4.3 搜索提示展示............................................... 36
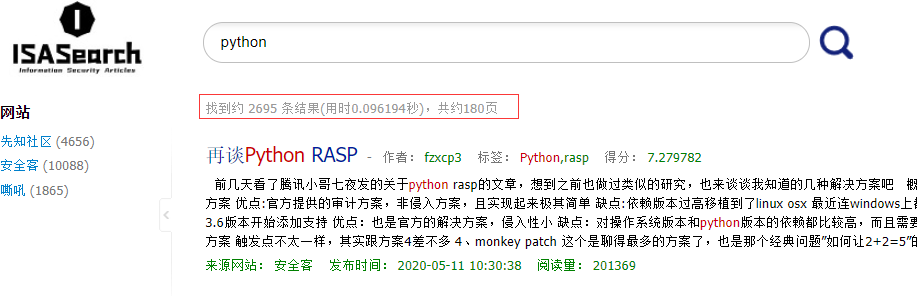
4.4 搜索结果展示............................................... 37