电影推荐系统
目录
电影推荐系统
1. 数据描述
2. 变量说明
3. 程序介绍
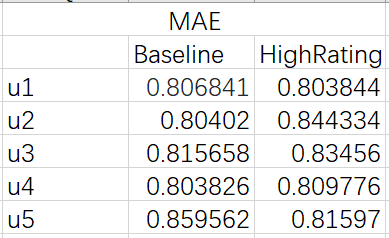
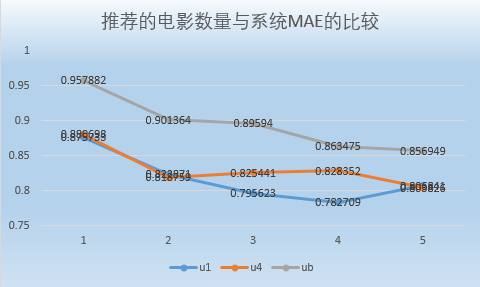
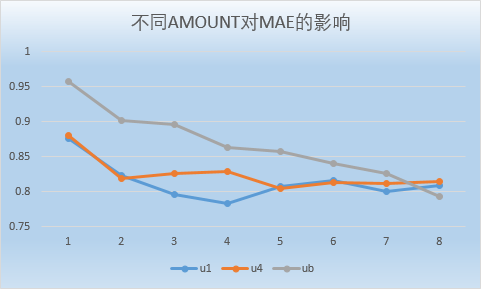
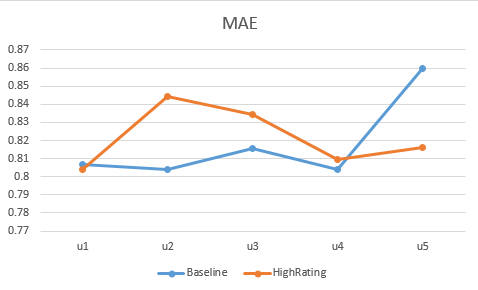
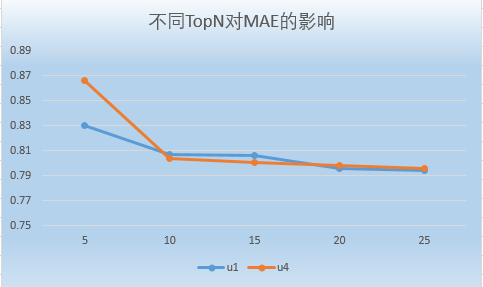
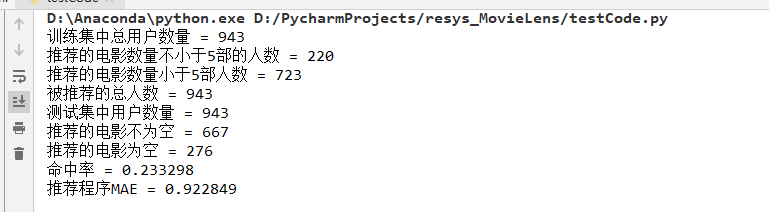
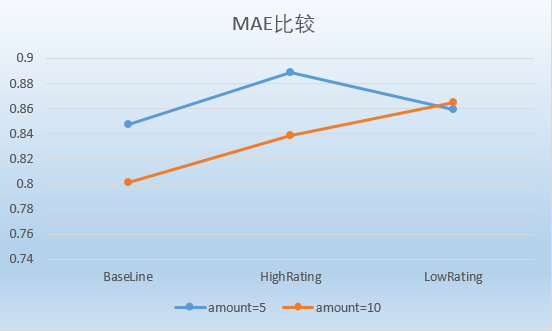
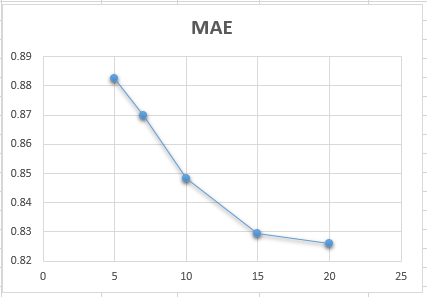
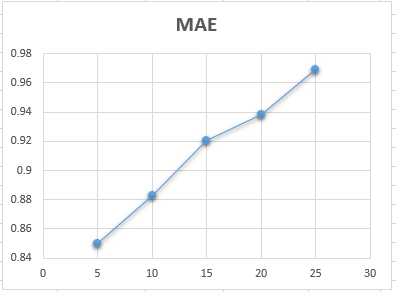
本次课程作业在 small-movielens 数据集的基础上,对用户、电影、评分数据进行了处理,然后根据 Pearson 相关系数计算出用户与其他用户之间的相似度,根据相似度进行推荐和预测评分,最后再根据数据集中的测试数据,计算该推荐系统的MAE等。
1. 数据描述
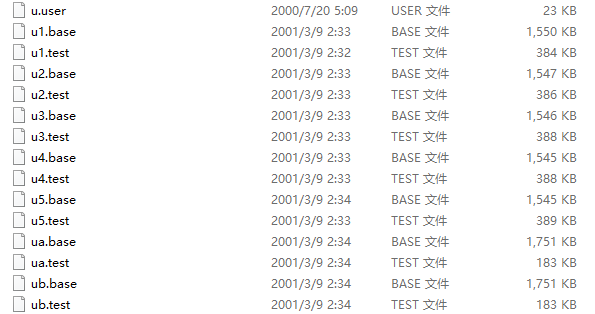
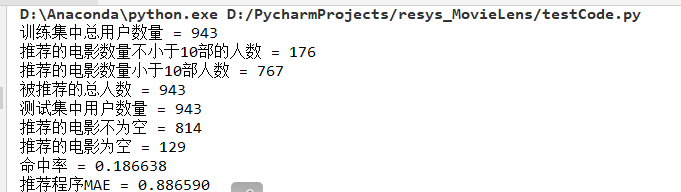
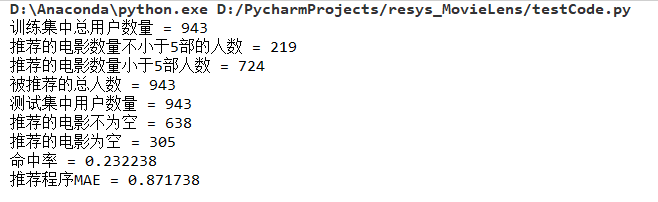
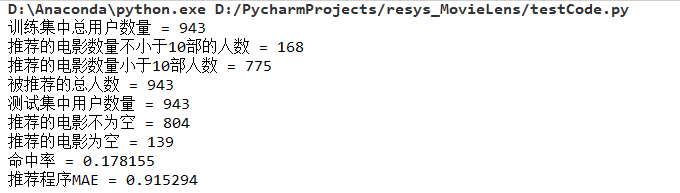
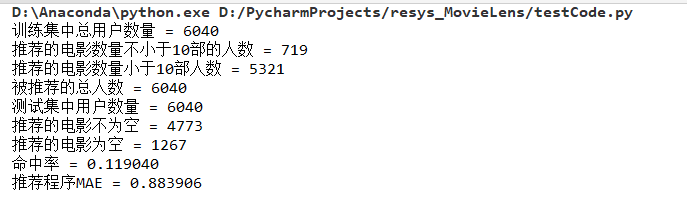
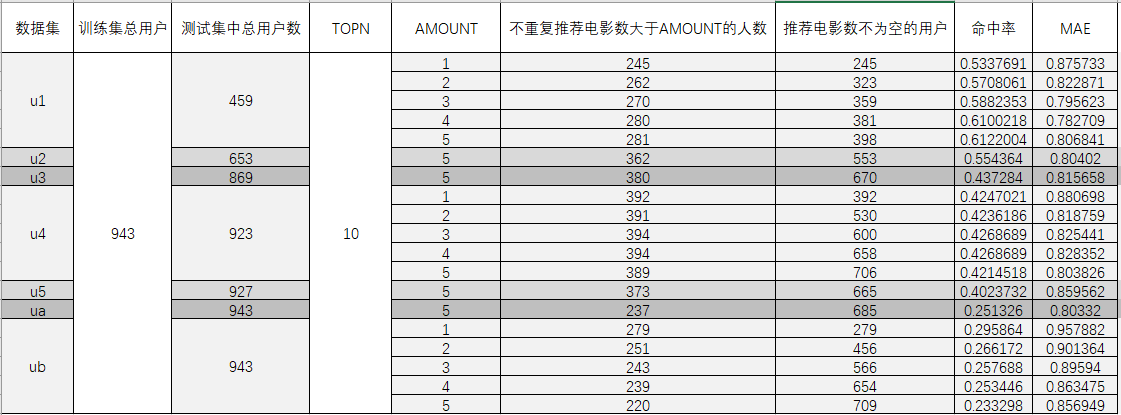
数据集来源于 MovieLens|GroupLens 网站。完整的数据集是由 943 个用户对 1682 个项目的 100000 个评分组成。每位用户至少对 20 部电影进行了评分。用户和项从 1 开始连续编号。数据是随机排列的。这是一个以选项卡分隔的:用户id|项id|分级|时间戳 列表。从 1970年1月1日 UTC 开始,时间戳是unix时间戳。在这些数据集的基础上,small-movielens 还包括 u1-u5,ua,ub 等七组测试集 (*.base)/训练集 (*.test) 数据。其中,u1-u5 是以 8:2 的比例随机生成互斥的训练集和测试集;ua、ub 是按照 9:1 的比例随机生成的互斥的训练集和测试集,不同的是,这两组数据的测试集中每个用户是对正好 10 部不同电影进行了评分。数据集如下图所示。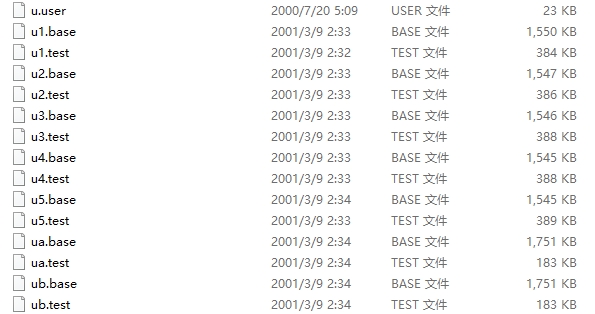
2. 变量说明
・ users :保存所有用户,不重复 list 类型 存储结构:[user1, user2,...]
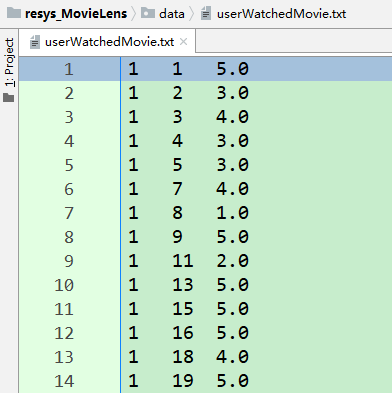
・ userWatchedMovie :保存所有用户看过的所有电影,字典嵌套字典类型 存储结构:{user1:{movie1:rating1, movie2:rating2, ...}, user2:{...},...}
・ movieUser :保存用户与用户之间共同看过的电影,字典嵌套字典嵌套 list 存储结构:{user1:{user2:[movie1,...],user3:[...],...},user2:{user3:[...],...},...}
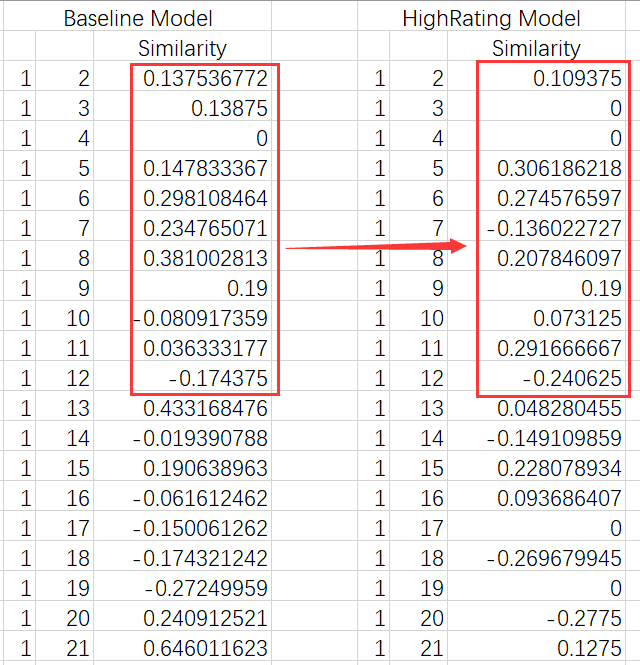
・ userSimilarity :保存用户与用户之间的相似度(皮尔逊相似度) 存储结构:{user1:{user2:sim, user3:sim,...}, user2:{user3:sim, ...}, ...}
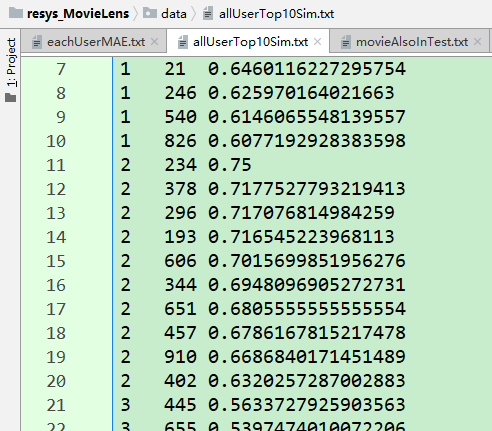
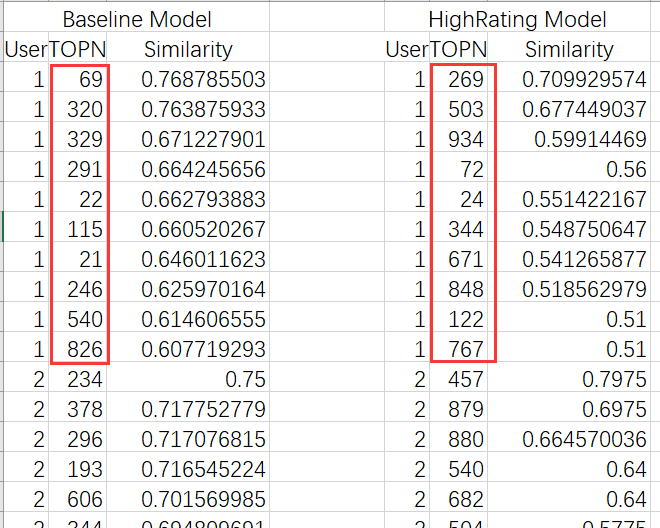
・ allUserTopNSim :保存每个用户都取前 n=10 个最相似的用户,以及相似度 存储结构:{user1:{user01:sim,user02:sim,...},user2:{user01:sim,...},...}
・ recommendedMovies :从最相似的用户中推荐,每个相似用户推荐两部,同时计算出预测值并保存在这个变量里 存储结构:{user1:{user01:{movie01:predictionRating,...},user02:[...],...},user2:{user01:[...],...},...}
・ usersTest :测试集文件中的所有用户 存储结构:同 users
・ userWatchedMovieTest :测试集文件中所有用户看过的所有电影 存储结构:同 userWatchedMovie
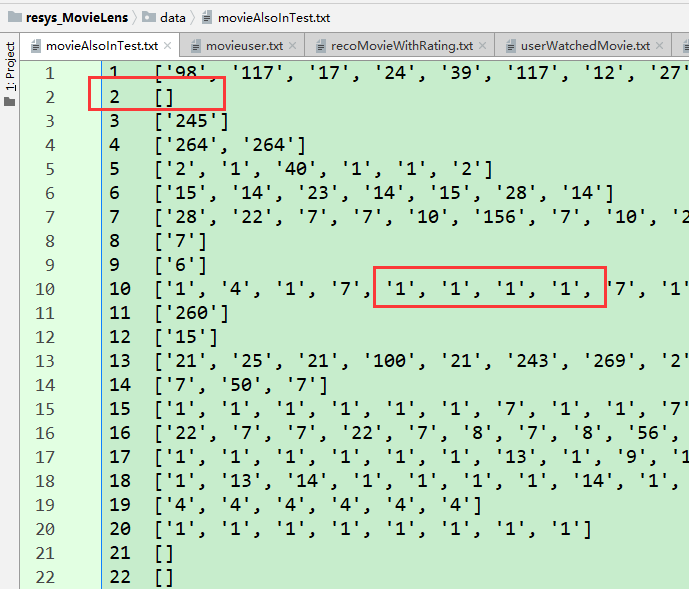
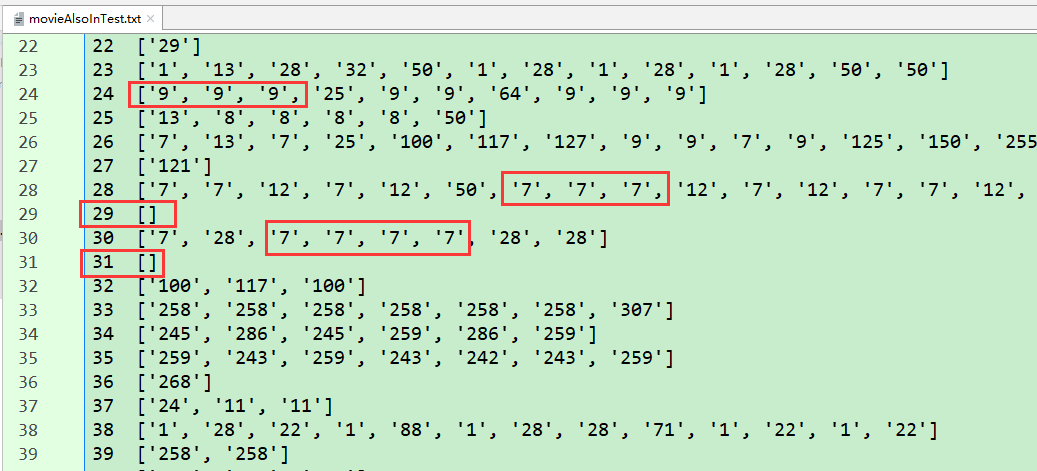
・ movieAlsoInTest :保存推荐的电影正好也在用户测试数据中看过的那一些电影,以便后面进行 MAE 计算 存储结构:{user1:[movie1,movie2,...],...}
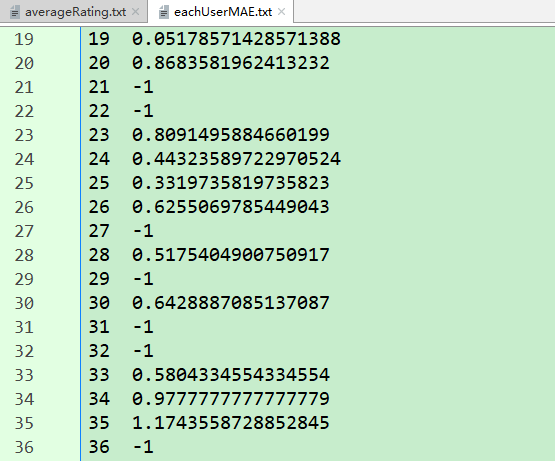
・ averageRating :保存每个用户对被推荐的电影的预测平均分 存储结构:{user1:{movie01:[count,sumPreRating,averageRating],...},...}
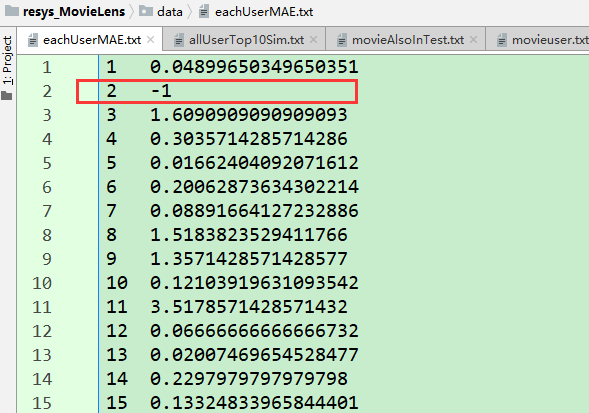
・ eachUserMAE :保存对每个用户而言计算出的 MAE 存储结构:{user1:MAE,user2:MAE,...}