《大数据计算及应用》
【推荐系统】实验报告
目录
《大数据计算及应用》
【推荐系统】实验报告
【实验相关统计信息】
(1)统计用户数量:19835。
【实验原理】
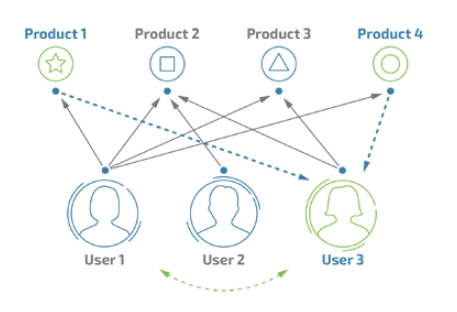
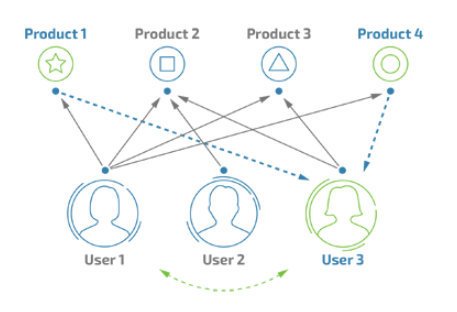
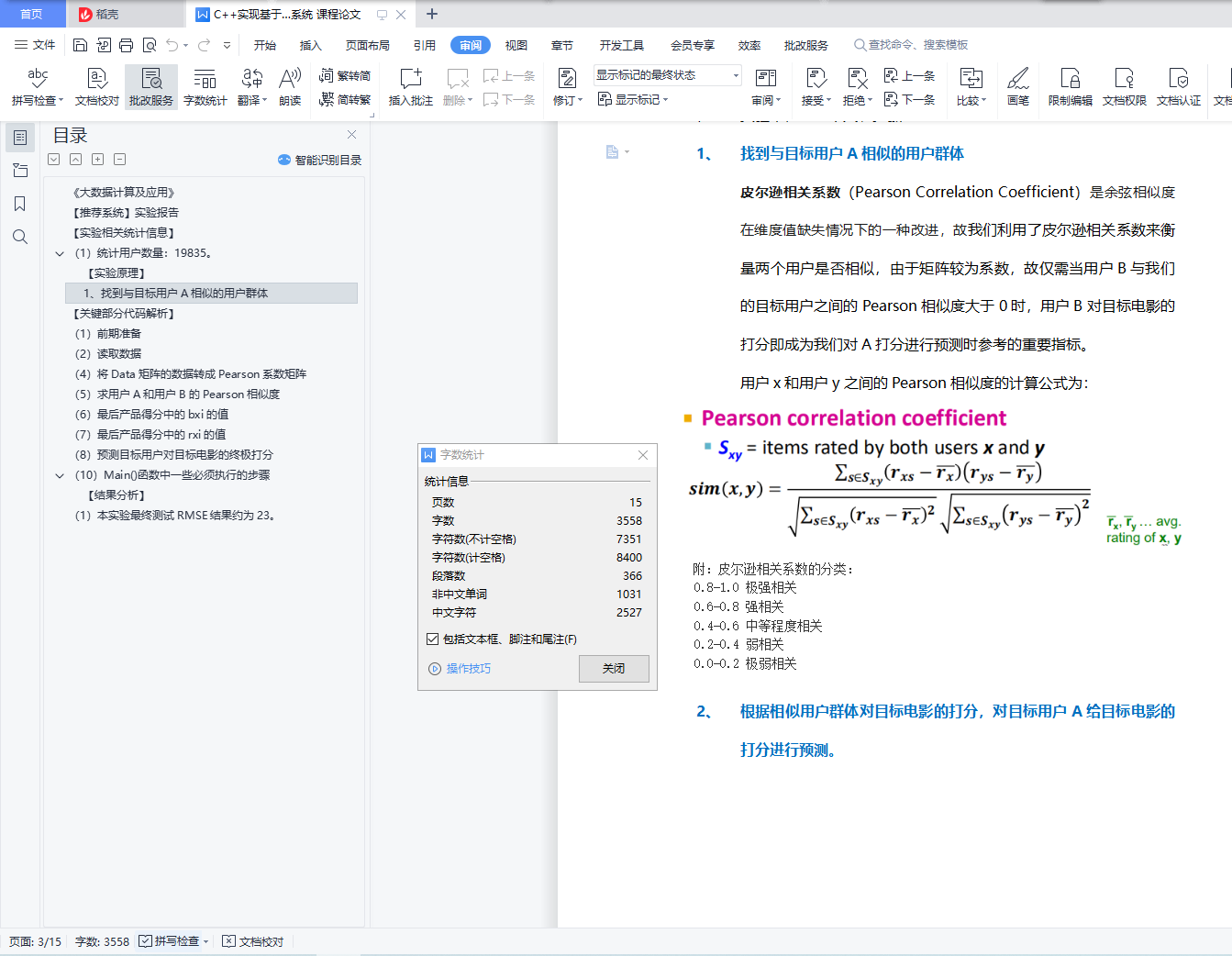
1、 找到与目标用户A相似的用户群体
【关键部分代码解析】
(1) 前期准备
(2) 读取数据
(4) 将Data矩阵的数据转成Pearson系数矩阵
(5) 求用户A和用户B的Pearson相似度
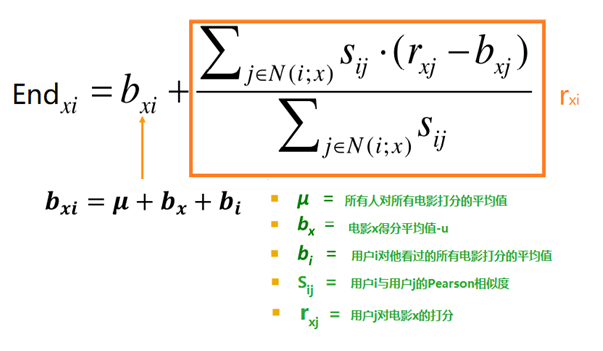
(6) 最后产品得分中的bxi的值
(7) 最后产品得分中的rxi的值
(8) 预测目标用户对目标电影的终极打分
(10) Main()函数中一些必须执行的步骤
【结果分析】
(1) 本实验最终测试RMSE结果约为23。
【实验相关统计信息】
(1)统计用户数量:19835。
(2)统计所有产品的得分平均值:49.545。
(3)统计每个用户看过的电影数目,在读取数据时将其存入数组int MovieNum[19835];中。
(4)统计计算Pearson系数需要的数据,存在Pearson矩阵中。
【实验原理】
核心算法:基于用户的协同过滤
如果已知用户A喜欢《蜘蛛侠》、《奇异博士》、《美国队长》、《绿巨人》等漫威超级英雄系列电影,另外用户B也都喜欢这些电影,此外B还喜欢《钢铁侠》,则A很有可能也喜欢《钢铁侠》,故我们可以预测用户A对于《钢铁侠》的打分会较高。