xt-indent: 2em; margin-top: 0px; margin-bottom: 0px; -ms-text-justify: inter-ideograph;">6. ��FPGA��ʵ��BFS��breadth-first-search���㷨�������š���ο�6.6����BFS�㷨��6.7����Graph500���������ؽ��ܣ���������Ҫ�����ʵ�֣�
a) ѡ����ʵ����ݽṹ���ɽ���R-MATͼ������ͼ������ʱ�䣨ͼ���ݹ�ģScale < 23, Edge-factor = 16����
b) ѡ����ʵı�����ԣ�OpenCL��Verilog�ȣ���FPGA��ʵ��BFS�㷨���ڸ�����ͬ���ڵ������¼���ÿ�������ȣ�����ƽ�����ﵽ��TEPSָ�ꣻ
c) ��ǰ������Ľ��������֤�ͷ�����
�����
[1]. ������. �����ݼ���ԭ����Ӧ��[M]. �����ʵ������, 2015.
[2]. Malewicz G, Austern M H, Bik A J C, et al. Pregel: a system for large-scale graph processing[C]. Proceedings of the 2010 ACM SIGMOD International Conference on Management of data. 2010: 135-146.
[3]. Salihoglu S, Widom J. GPS: a graph processing system. Proceedings of the 25th International Conference on Scientific and Statistical Database Management. 2013: 1�C22.
[4]. Kyrola A, Blelloch G E, Guestrin C. Graphchi: Large-scale graph computation on just a pc. Proceedings of the10th USENIX Symposium on Operating Systems Design and Implementation, 2012: 31�C46.
[5]. Gonzalez J E, Low Y, Gu H, et al. Powergraph: distributed graph-parallel computation on natural graphs. Proceedings of the 10th USENIX Symposium on Operating Systems Design and Implementation. 2012: 17�C30.
[6]. Roy A, Mihailovic I, Zwaenepoel W. X-stream: Edge-centric graph processing using streaming partitions. Proceedings of the Twenty-Fourth ACM Symposium on Operating Systems Principles. 2013: 472-488.
[7]. Salihoglu S, Widom J. Optimizing graph algorithms on pregel-like systems. Proceedings of the VLDB Endowment, 2014, 7(7): 577-588.
[8]. The Laboratory for Web Algorithmics, http://law.di.unimi.it/datasets.php.
[9]. Tian Y, Balmin A, Corsten S A, et al. From think like a vertex to think like a graph. Proceedings of the VLDB Endowment, 2013, 7(3): 193-204.
[10]. Yan D, Cheng J, Lu Y, et al. Blogel: A block-centric framework for distributed computation on real-world graphs. Proceedings of the VLDB Endowment, 2014, 7(14): 1981-1992.
[11]. The Center for Discrete Mathematics and Theoret- ical Computer Science, http://www.dis.uniroma1.it/challenge9/download.shtml.
[12]. Simmhan Y, Kumbhare A, Wickramaarachchi C, et al. Goffish: A sub-graph centric framework for large-scale graph analytics. Proceedings of the 2014 European Conference on Parallel Processing. 2014: 451-462.
[13]. Xie W, Wang G, Bindel D, et al. Fast iterative graph computation with block updates. Proceedings of the VLDB Endowment, 2013, 6(14): 2014-2025.
[14]. J. Shun, G. E. Blelloch. Ligra: a lightweight graph processing framework for shared memory. Proceedings of the 2013 ACM SIGPLAN Symp. Principles and Practice of Parallel Programming, 2013: 135�C146.
[15]. Nguyen D, Lenharth A, Pingali K. A lightweight infrastructure for graph analytics. Proceedings of the Twenty-Fourth ACM Symposium on Operating Systems Principles. 2013:456-471.
[16]. YUAN, P., ZHANG, W., XIE, C., et al. Fast iterative graph computation: a path centric approach. Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, 2014:401�C412.
[17]. Zhu X, Han W, Chen W. GridGraph: large-scale graph processing on a single machine using 2-level hierarchical partitioning. Proceedings of the Usenix Conference on Annual Technical Conference. 2015:375-386.
[18]. LOW, Y., BICKSON, D., GONZALEZ, J., et al Distributed graphlab: a framework for machine learning and data mining in the cloud. Proceedings of the VLDB Endowment, 2012, 5(8):716�C727.
[19]. Beamer S, Asanovic K, Patterson D. Direction-optimizing Breadth-First Search. Proceedings of the International Conference for High PERFORMANCE Computing, Networking, Storage and Analysis. 2012:1-10.
[20]. Liu H, Huang H H. Enterprise: breadth-first graph traversal on GPUs. Proceedings of the International Conference for High PERFORMANCE Computing, Networking, Storage and Analysis. 2015:1-12.
[21]. Pascal Architecture Whitepaper �C Nvidia. https://images.nvidia.com/content/pdf/tesla/whitepaper/pascal-architecture-whitepaper.pdf
[22]. Merrill D, Garland M, Grimshaw A. Scalable GPU graph traversal. Acm Sigplan Notices, 2012, 47(8):117-128.
[23]. Wang, Yangzihao, et al. "Gunrock: A high-performance graph processing library on the GPU." Proceedings of the 21st ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming. 2015: 265-266.
[24]. Han W, Mawhirter D, Wu B, et al. Graphie: Large-Scale Asynchronous Graph Traversals on Just a GPU. Proceedings of the International Conference on Parallel Architectures and Compilation Techniques. 2017:233-245.
[25]. Jeffers, James, James Reinders, Avinash Sodani. Intel Xeon Phi Processor High Performance Programming: Knights Landing Edition. Morgan Kaufmann, 2016.
[26]. Maass S, Min C, Kashyap S, et al. Mosaic: Processing a Trillion-Edge Graph on a Single Machine. Proceedings of the Twelfth European Conference on Computer Systems. 2017:527-543.
[27]. S. Beamer, K. Asanovic, D. Patterson, ��Locality Exists in Graph Processing: Workload Characterization on an Ivy Bridge Server,�� Proceedings of IEEE International Symposium on Workload Characterization, 2015:56-65
[28]. L. Nai, Y. Xia, I. G. Tanase, et al, ��GraphBig: Understanding Graph Computing in the Context of Industrial Solutions,�� Proceedings of IEEE International Conference for High Performance Computing, Networking, Storage and Analysis, 2015:1-12.
[29]. G. Dai, T. Huang, Y. Chi, et al. ��ForeGraph: Exploring Large-Scale Graph Processing on Multi-FPGA Architecture,�� Proceedings of ACM International Symposium on Field-Programmable Gate Arrays, 2017:217-226
[30]. S. Zhou, C. Chelmis, V. K. Prasanna, ��High-Throughput and Energy-Efficient Graph Processing on FPGA,�� Proceedings of IEEE International Symposium on Field-Programmable Custom Computing Machines, 2016:103-110.
[31]. G.Dai, Y. Chi, Y. Wang, et al, ��FPGP: Graph Processing Framework on FPGA: A Case Study of Breadth-First Search,�� Proceedings of ACM International Symposium on Field-Programmable Gate Arrays, 2016: 105-110.
[32]. T. J. Ham, L. Wu, N. Sundaram, et al, ��Graphicionado: A High-Performance and Energy-Efficient Accelerator for Graph Analytics,�� Proceedings of IEEE International Symposium on Microarchitecture, 2016:1-13.
[33]. M. M. Ozdal, S. Yesil, T. Kim, et al, ��Energy Efficient Architecture for Graph Analytics Accelerators,�� Proceedings of ACM/IEEE Annual International Symposium on Computer Architecture, 2016:166-177.
[34]. N. Sundaram, N. Satish, M. M. A. Patwary, et al, ��GraphMat: High Performance Graph Analytics Made Productive,�� Proceedings of the VLDB Endowment, 2015, 8(11): 1214-1225.
[35]. https://en.wikipedia.org/wiki/PageRank
[36]. https://en.wikipedia.org/wiki/Bellman%E2%80%93Ford_algorithm
[37]. Ullmann J R. An algorithm for subgraph isomorphism[J]. Journal of the ACM, 1976, 23(1): 31-42.
[38]. Shang H, Zhang Y, Lin X, et al. Taming verification hardness: an efficient algorithm for testing subgraph isomorphism[J]. Proceedings of the VLDB Endowment, 2008, 1(1):364-375.
[39]. Zhao P, Han J. On graph query optimization in large networks[C]. Proceedings of the VLDB Endowment, 2010, 3(1):340-351.
[40]. He H, Singh A K. Graphs-at-a-time: query language and access methods for graph databases. Proceedings of the 2008 ACM SIGMOD international conference on Management of data. 2008: 405-418.
[41]. Agrawal R, Borgida A, Jagadish H V. Efficient management of transitive relationships in large data and knowledge bases. Acm Sigmod Record, 1989, 18(2):253-262.
[42]. Graph500 : http://www.graph500.org/
[43]. Chakrabarti D, Zhan Y, Faloutsos C, et al. R-MAT: A Recursive Model for Graph Mining. Proceedings of the siam international conference on data mining, 2004: 442-446.
[44]. SNAP : http://snap.stanford.edu/
[45]. The Game Trace Archive : http://gta.st.ewi.tudelft.nl/
[46]. Murphy R C, Wheeler K B, Barrett B W, et al. Introducing the graph 500. Cray Users Group, 2010, 19: 45-74.
[47]. �ⶬ��, ����, ������,��. ����ԭ��ϵͳ��BFS�㷨���ʵ������Է���. ������������ѧ, 2017, 39(1):27-34.
����
ASIC 42
BSP��Bulk Synchronous Parallel��5
���ģ�� 5
����ͼ���� 20
FPGA 40
GAS��Gather-Apply-Scatter��7
Graph500 53
�߷ô�/����� 4
�ֲ��Բ� 4
��ϻ��� 16
MIC 38
Push��Ϣ����ģʽ 17
Push��Ϣ����ģʽ 17
PSWģ�� 26
SIMD 35
˫�������� 33
ͬ��ģʽ 18
ͼ���� 2
ͼ���� 14
���������㷨 45
ͼ���ݽṹ 1-2
ͼ�������� 4
ͼ���ݹ����Ͳ�ѯ�㷨 50
TLAV��Think Like a Vertex�� 5
�첽ģʽ 19
�Ա�Ϊ����ģ�� 8
�Ա�Ϊ���Ļ��� 15
�Ե�Ϊ����ģ�� 5
�Ե�Ϊ���Ļ��� 15
��·��Ϊ����ģ�� 9
����ͼΪ����ģ�� 13
, 6.7 ͼ������������
���Ŵ�����ʱ���ĵ�����ӿ�ֳ�Խ��Խ������ݷ���Ӧ�ã�����ҽ�ƴ����ݲ�ѯ��������Ϣ��������罻�����ϵ�����ھ�ȡ�������ЩӦ�ã�ͼ�����㷨�����ǵĺ��IJ��֡�ͼ������㷨�봫ͳ�Ĺ��������ȣ��ڼ���ͷô���ǧ��������Ų�ͬ���������Ժͽṹ�������Դ�ͳ������������һ��Ӧ���Ѿ������д����ԣ�ؽ���µ��������
Graph500��������ѧ���硢��ҵ�����ʵ���ҵĶ�λ����HPCר�ҹ�ͬΪ���������ܼ��Ĵ��ģͼ����Ӧ������������[42]�����ڻ������ͼ������Kronecker���ɵ������ͼ��ִ�й������������Breadth-First Search, BFS������Դ���·(Single Source Shortest Path, SSSP)�㷨������ȫ��ضԳ��������ϵͳ���ܽ������ۡ���ͼ 6-7-1��ʾ��Graph500�����Գ���benchmark����Ҫ����ͼ���ɡ�ͼ������Kernel 1����ͼ������Kernel 2-BFS��Kernel 3-SSSP���ò�����BFSΪ��������ϸ˵��������֤��������[47]��

ͼ 6-7-1 Graph500�����Գ�������ʾ��ͼ
ͼ���ɣ�����չ���������������������ڵ㣨vertex����ʶ���ı�Ԫ�飨edge tuples���б�����Ԫ�����<StartVertex, EndVertex, Weight>����ʽ�����ڱ�ʾÿһ������ߡ�����StartVertex��һ���ڵ��ʶ��EndVertex����һ���ڵ��ʶ��Weight�DZߵ�Ȩ�ء��ڵ��ʶ�ռ���[0,N)��N��ͼ�нڵ����������������ϡ�Ȩ�ؿռ���[0,1)�ĵ����ȸ��������ϡ������Ԫ����������BFS������Ҫ���ɱ�Ȩ�ء�ͼ�Ĺ�ģ�������û�����IJ���SCALE��edgefactorȷ���ģ�����SCALE��ʾͼ�ڵ��ģ��edgefactor��ʾͼ�ı�������ڵ���֮�ȣ���ͼ�нڵ��ƽ����������ʵ�ϣ�Graph500 �Ƽ�edgefactor ��Ϊ16��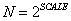 ��ʾͼ�ڵ����������ʹ������N����ͬ�����ļ������Խڵ���б�ţ�����ÿ���ڵ��ű������ٷ���48��bit����Ҫ�����Ϊ��Ȩ�ط���32��bit��
��ʾͼ�ڵ����������ʹ������N����ͬ�����ļ������Խڵ���б�ţ�����ÿ���ڵ��ű������ٷ���48��bit����Ҫ�����Ϊ��Ȩ�ط���32��bit��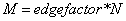 ��ʾͼ������ͼ�������������ڵݹ����R-MAT����ͼ�����㷨��Kronecker[43]��Ϊ�˱������ۣ����R-MAT������ʹ����һ���ڽӾ������ݽṹ; Ȼ��������ʵ�ֿ���ʹ���κ���������������Ԫ��ĵȼ��б�����ģ�ͽ�ͼ���ڽӾ���ݹ��ϸ��Ϊ�ĸ���ȴ�С�ķ��������Բ��ȸ�������Щ�����ڷֲ��ߡ�������ڽӾ����ǿյģ�����һ������һ���ߣ�ÿ���߷ֱ���A��B��C��D�ĸ���ѡ���ĸ������е�һ������Щ����Ҳ�ǹ̶��ģ�A=0.57��B=0.19��C=0.19��D=1-(A+B+C)=0.05����Ȩ�ش�[0,1)�������ѡȡ�����ȷֲ���ͼ�����������������ڵ�֮�䴴�������Ķ������ڵ��ڵ��ϴ������������ļ����У����Ժ��Զ���ߡ��������Ľڵ㣬�����뽫��������ṩ��ͼ�������ֵı��б��С����㷨�����ɾ��и߶Ⱦֲ��Ե�����Ԫ�顣��ˣ���Ϊ���һ������������û��ڵ�����Ȼ�����������Ԫ�顣ͼ���ɽ�����������������������������������£��б�Ҫȷ���ڵ�ȫ���������������ɵ����ݲ������κξֲ��ԡ���� 6-7-1��ʾ������Graph500�����Գ�����������IJ�ͬ�����Խ�������⻮��Ϊ������ͬ�����ݹ�ģ���ֱ�ΪToy��Mini��Small��Medium��Large��Huge[42]���� 6-7-2�ܽ���Graph 500���Ľ������ݼ���𣬴����˹ؼ�����ҵ�Ϳ�ѧ���⡣�㷺ʹ�õ����ݼ���SNAP[44]��The Game Trace Archive[45]��
��ʾͼ������ͼ�������������ڵݹ����R-MAT����ͼ�����㷨��Kronecker[43]��Ϊ�˱������ۣ����R-MAT������ʹ����һ���ڽӾ������ݽṹ; Ȼ��������ʵ�ֿ���ʹ���κ���������������Ԫ��ĵȼ��б�����ģ�ͽ�ͼ���ڽӾ���ݹ��ϸ��Ϊ�ĸ���ȴ�С�ķ��������Բ��ȸ�������Щ�����ڷֲ��ߡ�������ڽӾ����ǿյģ�����һ������һ���ߣ�ÿ���߷ֱ���A��B��C��D�ĸ���ѡ���ĸ������е�һ������Щ����Ҳ�ǹ̶��ģ�A=0.57��B=0.19��C=0.19��D=1-(A+B+C)=0.05����Ȩ�ش�[0,1)�������ѡȡ�����ȷֲ���ͼ�����������������ڵ�֮�䴴�������Ķ������ڵ��ڵ��ϴ������������ļ����У����Ժ��Զ���ߡ��������Ľڵ㣬�����뽫��������ṩ��ͼ�������ֵı��б��С����㷨�����ɾ��и߶Ⱦֲ��Ե�����Ԫ�顣��ˣ���Ϊ���һ������������û��ڵ�����Ȼ�����������Ԫ�顣ͼ���ɽ�����������������������������������£��б�Ҫȷ���ڵ�ȫ���������������ɵ����ݲ������κξֲ��ԡ���� 6-7-1��ʾ������Graph500�����Գ�����������IJ�ͬ�����Խ�������⻮��Ϊ������ͬ�����ݹ�ģ���ֱ�ΪToy��Mini��Small��Medium��Large��Huge[42]���� 6-7-2�ܽ���Graph 500���Ľ������ݼ���𣬴����˹ؼ�����ҵ�Ϳ�ѧ���⡣�㷺ʹ�õ����ݼ���SNAP[44]��The Game Trace Archive[45]��
�� 6-7-1 Graph500���������ݹ�ģ
|
���ݹ�ģ
|
SCALE
|
Edgefactor
|
�洢��СTB
( BFS,64BITS/EDGE��
|
�洢��СTB
( BFS,48BITS/EDGE��
|
�洢��TB( SSSP, 48BITS+32BITS/
EDGE��
|
|
Toy (level 10)
|
26
|
16
|
0.017
|
0.013
|
0.022
|
|
Mini (level 11)
|
29
|
16
|
0.137
|
0.103
|
0.172
|
|
Small (level 12)
|
32
|
16
|
1.100
|
0.825
|
1.374
|
|
Medium (level 13)
|
36
|
16
|
17.592
|
13.194
|
21.990
|
|
Large (level 14)
|
39
|
16
|
140.738
|
105.553
|
175.921
|
|
Huge (level 15)
|
42
|
16
|
1125.900
|
844.425
|
1407.375
|
ͼ������kernel 1�����ò��ֽ���Ԫ��ת��Ϊ���ں������ֵ��κα�ʾͼ�����ݽṹ������CSR ��ѹ��ϡ���У���CSC��ѹ��ϡ���У��������ɵ����ݽṹ���ܱ��������ָ��ġ��û�ֻ��ҪΪ�ò����ṩ�߱��ͱ߱��Ĵ�С���������Ϣ��Ҫ�ڸò��ּ��㣬�綥��������ȡ���Ҫע����Ǹù��̵�����ʱ���Ϊͼ����ʱ�䣬���������ܼ��㡣
�� 6-7-2 Graph500��������ݼ����[46]
|
����
|
���ʹ�С
|
˵��
|
|
���簲ȫ
|
ÿ�����150�ڸ���־����Դ�����ҵ��
|
����������ɨ����Ҫ�˵�������
|
|
ҽѧ��Ϣѧ
|
��5000������˼�¼��ÿ����¼���ܰ���20-200���ֶ�
|
ʵ����������Ҫ
|
|
�����ھ�
|
PB��������ݣ�����ࣩ
|
���纣����ǧ�����ݿ⣬�����м�ǧ��Ļ��˼�¼
|
|
�罻����
|
����û������
|
���磺Facebook��Renren��
|
|
��������
|
PB���������
|
���磺�˵Ĵ���Ƥ����250�ڸ���Ԫ��ÿ���д�Լ7000������
|
ͼ������kernel 2�CBFS��kernel 3-SSSP���������������һ�����ڵ㣬BFS�ӵ������ڵ㿪ʼ��Ȼ��ֽεط��ֺͱ�������ھӣ�Ȼ���������ھӵ��ھӵȡ�Graph500ָ��BFS���������������ҶԼ���ʩ��һЩ���ơ�Ȼ������������BFS�㷨������ѡ��ֻҪ������һ����ȷ��BFS����Ϊ������ⲿ������ʱ��������ܼ��㣬���Ǹ��ڵ������ʱ�䲻�������ܼ��㡣
��֤����ÿ�����ڵ��ͼ�������֮�ò��ֻ���������������֤���ò�������ʱ�䲻�������ܼ��㡣��֤������Ҫȷ������������
1. ͼ�����β����Ľ��BFS/SSSP�������ṹ������������
2. BFS���ϵ�ÿ�������ӵ������ڵ����ȣ�ÿ���ڵ������Ǹýڵ㵽���ڵ�ľ��룩��Ϊ1��SSSP���ϵ�ÿ�������ӵ������ڵ����Ȳ�����Ϊ�ñߵ�Ȩ�ء�
3. ��������ı�Ԫ����ÿһ���ߵ������ڵ����Ȳ����1�����BFS�����Ȩ�أ����SSSP���������������ڵ㶼�������ϡ�
4. ���ϵ����������ڵ㶼��ͨ��
5. ���ϵı�Ϊ��Ԫ���еıߡ�
ͼ������֤����ѭ��ִ��64�Σ�ÿ���������һ���ǹ����ڵ���Ϊ���ڵ㡣
��������������������ͼ��ģSCALE���ڵ�ƽ������edgefactor�����ڵ���Ŀ���Լ�һЩͳ�ƽ������Ҫ��BFS/SSSPͼ����ʱ�䡢���ʱ�����ÿ�����������TEPS,traversed edges per second����BFS/SSSPͼ����ʱ��ӷ��ʸ��ڵ㿪ʼ��ʱ����д���ڴ�ʱ��ֹ��ʱ������ʱ�κ�I/O��Graph500�����������������ܣ�����Ϊ�˼����ֵ����������64����������¼ÿһ��������ʱ�䡣Ϊ�˱Ƚϸ�����ϵ�ṹ�����ģ�ͺͿ����graph500��ͼ������ʵ�ֵ����ܣ����Ƕ������µ�����ָ�꣬��Ϊÿ�����������TEPS���� ������
������ Ϊ����ͼ�ı�����
Ϊ����ͼ�ı����� Ϊͼ�������ֵ�ʱ�䡣Graph500���ս��������TEPSָ�꣬�ֱ�Ϊ��Сֵ���ķ�֮һλ��������ƽ��ֵ���ķ�֮��λ�������ֵ��
Ϊͼ�������ֵ�ʱ�䡣Graph500���ս��������TEPSָ�꣬�ֱ�Ϊ��Сֵ���ķ�֮һλ��������ƽ��ֵ���ķ�֮��λ�������ֵ��
���һ��ͼ����ϵͳ������ָ����Ҫ����ͼ����BFS����ָ�ꡢBFS���ܹ��ı�ָ�ꡢÿ�ֵ�������ʱ�䡢����չ�ԡ����磬����һ������FPGA��ͼ����ϵͳ�û������Դ�����ָ���������һBFS����ָ�꣬���е�FPGA��������ԼΪ0.3GTEPS���ο�ForeGraph������Graph500�����Է���������SCALE������22��ͼ���ݼ�����BFS�����룬����ʵ�����ܲ��ԣ����ڶ�BFS���ܹ��ı�ָ�꣬�����CPU��GPUϵͳ���ܹ��ı�ԼΪ0.002GTEPS/W���ο�GraphChi��Medusa����ij������FPGA��ͼ����ϵͳ��BFS����ָ���0.3GTEPSԽ�����ܹ��ı�ָ���0.002GTEPS/WԽ��˵����ϵͳԽ�á�
�� 6-7-3 Graph500 2017��11�¹�����BFS����
|
����
|
����
|
��װ�ص�
|
������
����
|
�����ģSCALE
|
GTEPS
|
|
1
|
K computer
|
�ձ�����ѧ�о����������ѧ�о���(AICS)
|
663552
|
40
|
38621.4
|
|
2
|
����̫��֮��
|
�й����ҳ���������������
|
10599680
|
40
|
23755.7
|
|
3
|
DOE/NNSA/LLNL Sequoia
|
��������˹����Ī������ʵ����
|
1572864
|
41
|
23751
|
|
4
|
DOE/SC/Argonne National Laboratory Mira
|
��������ŵ���ް���������ʵ����
|
786432
|
40
|
14982
|
|
5
|
JUQUEEN
|
�¹�����ϣ�о�����
|
262144
|
38
|
5848
|
|
6
|
ALCF Mira - 8192 partition
|
��������ŵ���ް���������ʵ����
|
131072
|
36
|
4212
|
|
7
|
ALCF Mira - 8192 partition (5D torus)
|
��������ŵ���ް���������ʵ����DOE/ALCF
|
131072
|
36
|
3556.7
|
|
8
|
Fermi
|
�����CINECA������������
|
131072
|
37
|
2567
|
|
9
|
ALCF Mira - 4096 partition
|
��������ŵ���ް���������ʵ����
|
65536
|
35
|
2348
|
|
10
|
��Ӷ���
|
�й����ҳ�����������
|
196608
|
36
|
2061.48
|
�� 6-7-4 Graph500 2017��11�¹�����SSSP����
|
����
|
����
|
��װ�ص�
|
������
����
|
�����ģSCALE
|
GTEPS
|
|
1
|
Cray XE6 system
|
������ѧ
|
8192
|
31
|
12.88
|
|
2
|
University of Notre Dame cluster
|
����ʥĸ��ѧ
|
128
|
27
|
0.656085
|
|
3
|
Alkindi27-CPU
|
���ô��е߸��ױ��Ǵ�ѧ
|
56
|
27
|
0.1972
|
|
4
|
Alkindi28-CPU
|
���ô��е߸��ױ��Ǵ�ѧ
|
60
|
29
|
0.1567
|
|
5
|
Alkindi28
|
���ô��е߸��ױ��Ǵ�ѧ
|
60
|
30
|
0.1536
|
|
6
|
Alkindi27-CPU
|
���ô��е߸��ױ��Ǵ�ѧ
|
28
|
28
|
0.1375
|
|
7
|
LANL-LARP-hbchen-001
|
��˹����Ī˹����ʵ����
|
24
|
27
|
0.0547379
|
|
8
|
larp-hbchen-002
|
��˹����Ī˹����ʵ����UltraScaleϵͳ�о�����
|
24
|
29
|
0.0519326
|
|
9
|
Brokoli Cluster
|
ӡ��������Telkom��ѧ
|
48
|
22
|
0.00532283
|
��2010����ʳ��������ᣨSupercomputing Conference, SC10���״η���Graph500���а����ڲ�������������ڸ���ͼ����Ӧ�÷���������������Բ��䴫ͳ��TOP500��Green500�����µ�Graph500��2017��11�¹������������Ѿ�����235̨�������ɼ�ҵ���Graph500�����ӳ̶ȡ��� 6-7-3���� 6-7-4�г�������Graph500��ǰʮ��������
6.8 ������
ͼ�����Ǵ�����ʱ���Ĺؼ������ֶ�֮һ�����ܹ��ھ�����֮��DZ�ڲ��������ϵ��ͼ����Ӧ�ú����ϵͳ���о��ڽ�����һֱ���ڻ���״̬���������Ƚ�����ͼ�����Ӧ�������о���ͼ���㼸��������Ӧ�ó�������������ͼ������ص㣬�������ݷ��ʷǹ����ԡ��߷ô�/����ȵ��ص㡣ͼ�������Ȼ���Ը�ͼ����ϵͳ����ƴ����������ս��������������ͼ����ϵͳ����г����ļ����ֶΣ��������б��ģ�ͣ�ͼ���ֺ�ͨ�Ų��Եȡ����ţ������о��˵���ͼ����ϵͳʾ��������֮������˽������о����ȵ�ͼ������ټ������������˵�����������ʵ�ָ�Ч��ͼ���㡣����½����˳��õ�ͼ�㷨�Լ�ͼ�������������Graph500[42]������ȫ��ϵͳ�Ľ�����ͼ�����������ǰ�ص��о��ɹ�����δ��ͼ���������о�����һ���ο���ָ����
6.9ϰ��
���ʽ���
1. ������������
ͼ�ṹ��ͼ���㡢ͼ���֡�ͼ��ѯ������ͼ���㡢�ڴ�ͼ���㡢GTEPS
�������㷨�����
2. ����Scatter-Gather���ģ�ͣ�д��������������㷨BFS����ҳ�����㷨PageRank����Դ����������㷨SSSP��ǿ��ͨ�㷨SCCα���롣
�������㷨�����
3. ���Ĵ��ģͼ�����㷨��ɢ�л��֣���ÿ���������ȸ���Ψһ��ID�ţ���ͼ�Ķ���ɢ�л��ֵ�p�������У���ô
a) ÿ���߱��и����ѧ���� �Ƕ��٣����и�������ĸ��Ƶ㣬��ѧ�����Ƕ��ٸ���
�Ƕ��٣����и�������ĸ��Ƶ㣬��ѧ�����Ƕ��ٸ���
b) ����ָ��Ϊ��������ͼ�����и�������ĸ��Ƶ㣬��ѧ�����Ƕ��ٸ���
c) ɢ�л��ֵ����ƺ�ȱ����ʲô��
4. ��������ͼ�еĸ�ά�Ƚڵ㣨����Twitter�о��д�����˿��������ͳ���������¼��ִ�����ʽ��
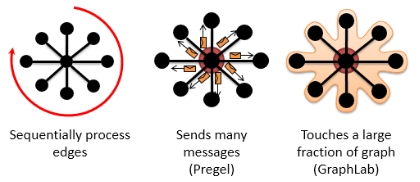
˳���� ������Ϣ �Ӵ���ͼ
����״̬���첽ִ�� ����״̬��ͬ��ִ��
��д�����ϼ��ַ�����ȱ�ݡ�
�۲��㻮���㷨��α���룬�����������Coarsening��Uncoarsening������
Multilevel Graph Partition (Graph G)
�� Take the weighted undirected graph as input
�� While (|V|> coarsening threshold) perform
Coarsening (Gi to Gi +1 )
�� For all v in V
If vertex degree (v) is high perform
Balanced partitioning
Else
Perform Greedy partitioning
�� Simulated annealing(initial partition)
�� While (Gi!= G) perform
Uncoarsening (Gi to Gi-1 )
5. ��ͼ�������С��Ļ���ԭ��������������볢��ʹ��α����д�����㷨��

Ӧ��ʵ��˼����
ȫ�ױ�ҵ��������ֳɳ�Ʒ��������ѯ
