6.6 图算法案例
图具有极强的抽象性与灵活性,相比线性表、层次树等组织方式,图在结构和语义等方面具有更强的表示能力,是最常用、最重要的数据结构之一。正是由于图结构丰富的表现力,现实生活中的诸多应用场景都需要用图结构表示,例如社交网络、文献网络、交通网络与知识图谱等。对这些应用场景构建的图进行完整的刻画、计算和分析即为图计算。
在图计算中,基本的数据结构表达就是:G=(V,E,D),其中V是图中是所有顶点的集合,E是图中边的集合,D代表图中所有顶点和边的属性。由于图数据结构极强的抽象性与灵活性,现实生活很多应用问题都可以抽象成图来表示并求解。图计算的算法可以分为两大类:一类是图拓扑属性计算[14]如万维网(WWW)中广泛使用的网页排名(PageRank)算法、广度优先搜索(BFS)算法、单源点最短路径(SSSP)算法等;另一类则是图数据管理和查询如子图同构、可达性查询等。以下两小节将分别对这两类图计算案列进行介绍。
6.6.1 拓扑属性算法
一、广度优先搜索算法BFS
广度优先搜索(BFS)算法是连通图的一种遍历策略,它采用一个图G =(V,E)和一个起始顶点r∈V,并计算一个以r为根的包含所有从r可到达的节点的广度优先搜索树。最近有许多关于利用共享内存机器开发并行广度优先搜索算法的工作,并且这些算法已经被证明对于许多现实世界的图是实用的,一个基础的广度优先搜索算法的实例伪代码如图。

图 6-6-1 广度优先搜索(BFS)算法伪代码
广度优先搜索(BFS)算法如图 6-6-1所示。首先使用一个Parents数组(初始化为-1,除了根节点r,其中Parents[r] = r),其中每个顶点的对应值将保存其在BFS树中指向的父节点编号。最初创建一个只包含根结点(r)的节点子集Active,来表示活跃顶点边界,每轮迭代遍历从Active可到达所有的顶点。使用EDGEPRO,每一步检查活跃顶点边界的邻居,查看哪些没有被访问,更新对应Parents数组,并将它们添加到下一轮迭代的Active子集中(第13行)。其中COND函数检查顶点是否被访问,若没有被访问,UPDATE用于更新该顶点的父节点值,即Parents数组,并将它添加到下一轮迭代的Active子集中。重复此迭代,直至Active集合为空时,表示BFS算法已经完成。
二、网页排名算法PageRank
网页排名(PageRank),又称佩奇排名,是一种由搜索引擎根据网页之间相互的超链接计算的技术,而作为网页排名的要素之一,以Google公司创办人拉里・佩奇(Larry Page)之姓来命名,是Google首先用来计算网页相对重要性的算法[35]。
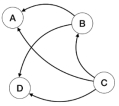
图 6-6-2 网页链接拓扑图
PageRank算法根据网页间的链接情况,反映网页的重要性。网页的PR(PageRank)值根据所有链向它的页面的重要性来决定,如图 6-6-2所示,假设一个由4个页面组成的小团体A、B、C、D。如果B、C页面都链向A,那么A的PR值将是B、C的总和:
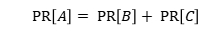 (6-6-1)
(6-6-1)
然而B、C分别有链接链向D,同时C有链接链向B,根据规则一个页面不能“投票”两次,所以B给每个链向的页面投半票,对C也是同样的逻辑,所以修正后A的PR值如下:
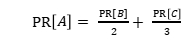 (6-6-2)
(6-6-2)
值得注意的是,为了处理那些“没有向外链接的页面”(这些页面就像“黑洞”会吞噬掉用户继续向下浏览的概率)带来的问题,公式中增加了阻力系数γ,其意义是在任意时刻用户到达某页面后并继续向后浏览的概率,该数值是根据上网者使用浏览器书签的平均频率估算而得;1-γ就是用户停止点击,随机跳到新URL的概率,更新后PR值计算公式如下:
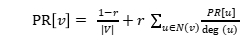 (6-6-3)
(6-6-3)
PageRank算法的伪代码在图 6-6-3中给出。它以图G =(V,E),阻尼系数0≤γ≤1和收敛常数ε作为输入。初始化时将图中所有顶点对应的PR值初始化为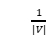 ,并对所有顶点PR值迭代地应用等式(6-6-3)计算各点PR值,直到迭代之间所有顶点Rank值的差之和小于
,并对所有顶点PR值迭代地应用等式(6-6-3)计算各点PR值,直到迭代之间所有顶点Rank值的差之和小于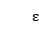 。在每轮迭代中,依次遍历图中所有的顶点。维护两个数组pcurr和pnext,pcurr中存放当前图中所有顶点Rank值,pnext中存放本次迭代计算的PR值。对于图中每一个顶点,pcurr被初始化为
。在每轮迭代中,依次遍历图中所有的顶点。维护两个数组pcurr和pnext,pcurr中存放当前图中所有顶点Rank值,pnext中存放本次迭代计算的PR值。对于图中每一个顶点,pcurr被初始化为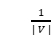 ,pnext被初始化为全部的0。每轮迭代首先依次遍历图中所有顶点,根据公式计算对应顶点的PR值(第17-20行)。然后计算各节点本轮迭代PR值与上一轮迭代的绝对差值(第21-22行),并将pcurr重置为 0.0为下一次迭代做准备(因为pnext和pcurr的值以交换),直到误差值小于ε,结束循环,算法完成。
,pnext被初始化为全部的0。每轮迭代首先依次遍历图中所有顶点,根据公式计算对应顶点的PR值(第17-20行)。然后计算各节点本轮迭代PR值与上一轮迭代的绝对差值(第21-22行),并将pcurr重置为 0.0为下一次迭代做准备(因为pnext和pcurr的值以交换),直到误差值小于ε,结束循环,算法完成。

图 6-6-3 网页排名(PageRank)算法伪代码
三、单源点最短连接算法SSSP
单源点最短路径(SSSP)其解决的问题是:给定有权图G和源顶点s,找到从s至图中所有顶点的最短路径。解决这一问题有多种算法,其中包括Bellman-Ford[36]算法和 Dijkstra 算法,其中Dijkstra 算法要求图 G 中边的权值均为非负,而 Bellman-Ford算法能适应一般的情况,本小节将介绍Bellman-Ford 算法。
Bellman-Ford算法采用动态规划(Dynamic Programming)进行设计,大致分为三个部分。首先,初始化源顶点s到图中所有顶点的距离的集合DisSet。然后,在循环内部遍历所有的边,进行松弛计算,循环执行 n-1 次;最后,检测图中是否有负权边形成了环,遍历图中的所有边,判断是否存在点u对于s存在更小距离的情况,若存在则因算法为无法收敛而导致不能求出最短路径。
算法的伪代码如图 6-6-4所示,给定输入有权图G、源点s,数组DisSet[i]记录从顶点i到源点s到的路径长度,将源点的值设为0,其它的点的值设为无穷大(表示不可达);然后,对于每一条边edge(u, v),如果DisSet [u] + w(u, v) < DisSet [v],则使DisSet [v] = DisSet [u] + w(u, v),其中w(u, v)为边edge(u, v)的权值,执行循环执行n-1次(第10-13行);最后检测负权回路(第14-16行),对于所有边,只要存在一条边edge(u, v) 使得DisSet [u] + w(u, v) < DisSet [v],则该图存在负权回路,即无法收敛而导致不能求出最短路径,返回FALSE,否则返回TURE。

图 6-6-4 Bellman-Ford算法伪代码
图拓扑属性计算过程中,在处理边时,由于经常要访问不同点的属性,并且这些访问局部性很差,导致大量的缓存缺失及带宽浪费,极大影响了计算的效率。针对这个问题MOSAIC[26]采用了一种希尔伯特顺序化对原始的图数据进行预处理,这种特定的顺序化,能够有效的提高数据的局部性;Graphicionado[32]通过将点数据访问转移至片上缓存,极大地缩短了点数据的访存时延,并有效减少了内存带宽的浪费;比尔肯大学的研究人员从细分化的角度对传统Cache架构进行的改进[33]来缓解此问题。如6.5节介绍,为了充分挖掘计算过程中的并行性, 许多工作利用GPU[23]、MIC[26]、FPGA[32]和ASIC[32] [33]等硬件加速器与图计算特性进行结合,以克服传统CPU架构在处理图应用时面临并行度较低等问题。
6.6.2 图数据管理和查询算法
一、子图同构
子图同构算法在图像检索,文档处理,声音数据检索,生物信息检索等领域都有着广泛的应用。已经有很多成熟的算法如Ullmann [37],QuickSI[38],SPath [39],GraphQL [40]对子图匹配问题进行研究,Ullmann算法是第一个处理这个问题的算法,同时也是目前应用最为广泛的子图判定算法之一,本小节将详细介绍此算法。
子图同构是给定两个图A和B,判定A是否是B的子图并报告其匹配位置,如图 6-6-5所示对于B存在多个与A相匹配的子图。
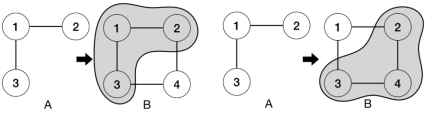
图 6-6-5 图A与图B子图同构关系
在Ullmann算法中存在一条定理,如果图A关于映射f子图同构与图B,令 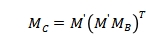 ,则有
,则有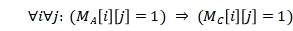 。
。
Ullmann算法的基本思想是找到满足条件的映射矩阵。其执行步骤如图 6-6- 6所示,首先初始化矩阵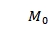 ,由
,由 行和
行和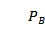 列个元素组成,
列个元素组成,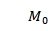 中为1的元素满足B这个图中的度大于等于A中元素的度,其余元素为0,以图 6-6- 5为例,
中为1的元素满足B这个图中的度大于等于A中元素的度,其余元素为0,以图 6-6- 5为例,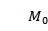 为:
为:
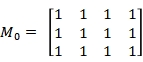

图 6-6-6 Ullmann算法步骤
{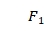 ,
,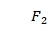 ,…,
,…,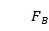 }用来记录列计算的中间状态,
}用来记录列计算的中间状态,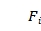 为1表示第i列已被使用。{
为1表示第i列已被使用。{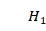 ,
,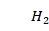 ,…,
,…,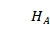 }记录深度为d的哪一列已经被选择。初始化完成后,执行第二步,如图 6-6-6例子所示,存在j使得
}记录深度为d的哪一列已经被选择。初始化完成后,执行第二步,如图 6-6-6例子所示,存在j使得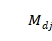 =1且
=1且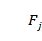 =0,如
=0,如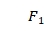 =0,
=0, 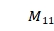 =1,所以执行顺序到第三步,完成后得
=1,所以执行顺序到第三步,完成后得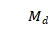 为:
为:
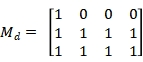
更新 对应值后返回第二步进行迭代计算,直至找到所需的映射矩阵,或不存在满足条件的映射矩阵从第七步终止算法。通过不断枚举和验证可以找到其它的映射矩阵。
对应值后返回第二步进行迭代计算,直至找到所需的映射矩阵,或不存在满足条件的映射矩阵从第七步终止算法。通过不断枚举和验证可以找到其它的映射矩阵。
二、可达性查询
可达性查询在与图结构化数据的许多重要应用程序中出现得非常频繁。测试两个节点之间的可达性对应于一个重要的问题,被认为是许多应用程序的一个非常基本的图形查询类型。例如,在蛋白质-蛋白质相互作用网络中,可以用它来回答两个蛋白质是否相关。
可达性查询:令���=(���,���)是一个有向图,有���个节点和���条边。 一个可达性查询被表示为u v,其中u和v是G中的两个节点。当且仅当有向图G中有一条从u到v的直接路径,u
v,其中u和v是G中的两个节点。当且仅当有向图G中有一条从u到v的直接路径,u v可达。当图的规模非常小时,利用深度优先遍历(DFS)显然可以处理查询。但是由于图的规模越变越大,基于DFS方法的查询效率太低这种方法不再适用。为了加速图数据可达性的查询,大量的可达性索引方法被提出。本小节将具体介绍基于树的索引方法,它被广泛应用于各种应用。
v可达。当图的规模非常小时,利用深度优先遍历(DFS)显然可以处理查询。但是由于图的规模越变越大,基于DFS方法的查询效率太低这种方法不再适用。为了加速图数据可达性的查询,大量的可达性索引方法被提出。本小节将具体介绍基于树的索引方法,它被广泛应用于各种应用。
Optimal-tree[41]是这一类方法最具代表性的算法。从原图中找出最优生成树以此能覆盖更多的可达性关系。最优生成的构建算法如图 6-6-7所示:

图 6-6-7 最优生成树伪代码
pred(j)是节点j的所有父节点的集合,并增量计算。如图 6-6-8所示,对于图 6-6-8(a)的最优生成图为图 6-6-8(b)。然后为每个节点分配一个编码区间,按照逆拓扑序,将区间合并到父节点中,得到相应区间集。最后判断节点u是否能到达节点v时,只需判断u区间是否包含v区间即可。
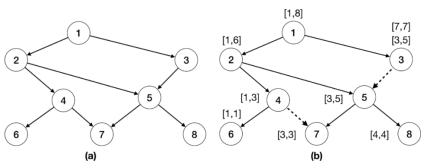
图 6-6-8 Optimal-tree实例
