1.ʵ��һ
1.1 ʵ��Ŀ����Ҫ��
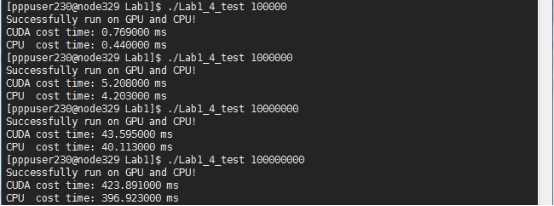
ʵ��Ŀ�ģ���Ϥ���п������������ղ��б�̵Ļ���ԭ���ͷ������˽�Linuxϵͳ��pthread��OpenMP��OpenMPI�ȹ��ߺͿ�ܵ��Ż����ܡ�
ʵ��Ҫ��ʹ��������ַ�������ÿ���̣߳����̣����ѭ������һ��ѭ���Ĺ���������n���߳�ͬʱ���㣬�Ӷ�ʵ�ֶԻ��������ӷ�������Ż��������ӷ�����������ʾ��
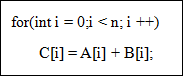
1.2 ʵ������
1.2.1 ʹ��pthread�������ӷ�
�㷨������

��������ȫ�ֱ���vector_a[]��vector_b[]��vector_result[]�ֱ��ʾ��������ͽ������,�̺߳���plus_pthread��vector_result[i] = vector_a[i]+vector_b[i]������
1.2.2 ʹ��OpenMP�������ӷ�
ʹ������ı���������䣬OpenMP���Զ���forѭ���ֽ�Ϊ����̣߳�Դ�����ij�������ʽ��

1.2.3 ʹ��OpenMPI�������ӷ�
�����ӷ����Կ�����һ�Զ��ͨ�Ż��ƣ���˲���MPI_Scatterɢ������ʵ�ֽ��̼�ͨ�š��㷨�������£�

MPI_Scatter()�����ӿ��У�sendBuf��ʾ���ͻ������������Ƕ����������n*1ά����������ɵ�n*2ά�ľ������飬sendCount��ʾ��������ʱ�����ݿ�Ĵ�С��MPI_FLOAT��ʾ���͵��������ͣ�recvBuf��ʾ���ջ�������recvCount��ʾ��������ʱ�����ݿ��С��source��ʾ�����̵Ľ��̺š���ʹ��mpirun ʱ���Cnp������СӦ��Ϊ��������n��
1.2.4 ʹ��CUDA�������ӷ�

ͼ1-1 CUDA�ڲ�����
���Ƕ������ĸ�128ά������host_a��host_b��host_c��host_c2���ֱ��ʾ�����˵�A��B��C������host_c2���ڼ���������Ƿ���ȷ��
Kernel�����������£� 
��ʼ��dimBlockΪ4*4*1��dim3���ͣ�ִ���߳̿������ά�ȣ��������ά��1�����˻�Ϊ4*4�Ķ�ά�߳̿顣Ϊ������У�����ÿһ���̸߳���һ�������ӷ�����ô��Ҫ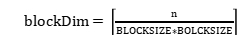 ���߳̿飬��block��ά����С�������߳�����grid��grid��СΪ
���߳̿飬��block��ά����С�������߳�����grid��grid��СΪ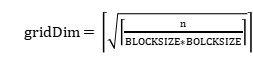 ����grid��ά�ȣ�Gridֻ���Ƕ�ά���£�������ά������Ĭ�Ϻ��ԡ������в�������ȡ����Ϊ�˱�֤������һ���߳��������ÿ��Ԫ�ص���ӣ���ô�������ÿ��ܻᵼ���߳��������������ȣ������Kernel��������Ҫ����Щ�߳�ֱ���˳������������±�Խ�硣
����grid��ά�ȣ�Gridֻ���Ƕ�ά���£�������ά������Ĭ�Ϻ��ԡ������в�������ȡ����Ϊ�˱�֤������һ���߳��������ÿ��Ԫ�ص���ӣ���ô�������ÿ��ܻᵼ���߳��������������ȣ������Kernel��������Ҫ����Щ�߳�ֱ���˳������������±�Խ�硣
���߳̿��ΪblockIdx���̺߳�ΪthreadIdx���߳�ӳ�䵽��������������±꣺

��ˣ������ӷ�Kernel�����У��ȼ�����̲߳��������±�i����i < n����㣬������߳�ֱ���˳���Kernel�����������£�

��������ͼ��ͼ1-2��ʾ���Ƚ����ݴ������ڴ濽����GPU�ڴ��豸�ϣ�Ȼ���������������ӷ�Kernel�������豸�첽����ִ�У�����CPU������Kernel�������첽�ģ������������ȵ�GPUִ����kernel��ִ�к�����CPU���֣������ʾ����ͬ����������CPU���������ִ֤�н����ͳ��ִ��ʱ�䡣
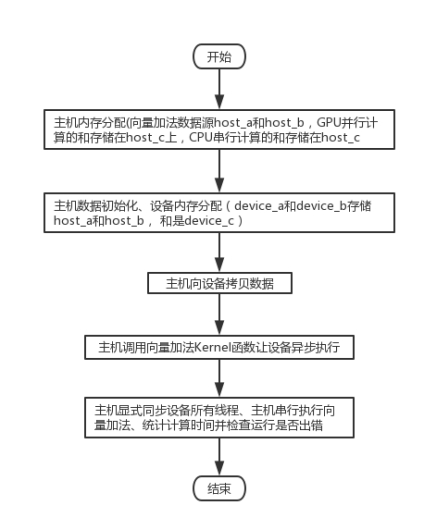
ͼ1-2 CUDA�������ӷ��㷨����ͼ
1.3 ʵ����
1.3.1 pthread
���룺gcc Lab1_1.c -o Lab1_1 -lpthread
����./Lab1_1
���Խ����ͼ1-3��ʾ��
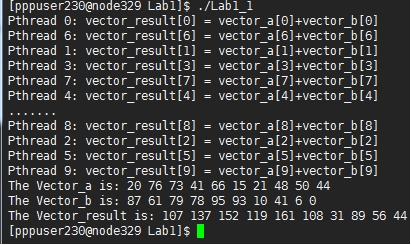
ͼ1-3 pthread����ʾ��
���ڽ�����ά��n����Ϊ10��ͼ�п��Կ���һ��������10�����̣�ÿ���̷ֱ߳�����һ�μӷ����㣬�����̲߳��У����Դ�ӡ�Ľ��������Աȼ�������֪��������ȷ��
1.3.2 OpenMP����
���룺gcc Lab1_2.c -o Lab1_2 �Copenmp
����./Lab1_2
���ڸ�ʵ����ͨ��OpenMP����ı�����������Զ���forѭ���ֽ�Ϊ����̲߳��еģ����Խ������ʮ��ֱ�ۣ���ͼ1-3��ʾ��������ǰ���������n����Ϊ100000����������ͼ1-4��ʾ����Ȼ�Ѿ�������n�ļ��������Ƕ�����еĽ�����Է��ֶ���ִ���ٶȲ���С����������ֻ��һ�μ�forѭ����OpenMP�ļ�������������ر����ԡ�
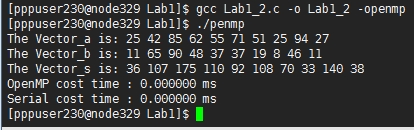
ͼ1-4 OpenMP���������ӷ�������n=10

ͼ1-5 OpenMP���������ӷ�������n=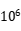
1.3.3 OpenMPI����
���룺mpic Lab1_3.c �Co Lab1_3
����mpirun �Cnp 4 ./Lab1_3
��һ��n*2ά��������ʾ����������ͨ��MPI_Scatter�ӿ�ÿ�ηַ���ͬ��С�����ݿ飬ÿ�����ݿ����ͬ������Ԫ�أ�ÿ������ִ��һ�μӷ����㡣����Ч����ͼ1-5��ʾ��
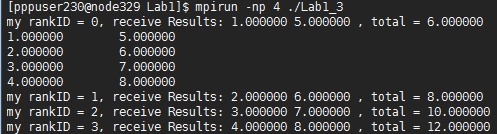
ͼ1-6 OpenMPI�������������ӷ�
1.3.4 CUDA����
���룺nvcc Lab1_4.cu �Co Lab1_4
����./Lab1_4
��ͼ1-7�У������ڳ�����������������n=128�����Сblocksize=4����֤��������ȷ������ִ��Ч��Զ����CPU����ִ�У����Ҳ��Ե�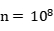 ʱ����Ч�ʼ�����ͬ��ͼ1-8Ϊ��blocksize=16��IJ��Խ�������ǿ�������������������CUDA�����ļ���Ч�������ӣ�������
ʱ����Ч�ʼ�����ͬ��ͼ1-8Ϊ��blocksize=16��IJ��Խ�������ǿ�������������������CUDA�����ļ���Ч�������ӣ�������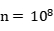 ʱЧ�ʳ�����CPU�������ǽ�blocksize����Ϊ32ʱ����Ч���ֽ������ˣ��������ϲ�֪��ÿ���߳̿飨Block��һ�������Դ���512�������̣߳���blocksize<=16��
ʱЧ�ʳ�����CPU�������ǽ�blocksize����Ϊ32ʱ����Ч���ֽ������ˣ��������ϲ�֪��ÿ���߳̿飨Block��һ�������Դ���512�������̣߳���blocksize<=16��
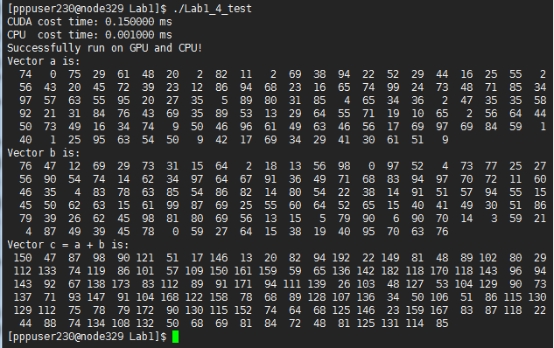
ͼ1-7 CUDA�������������ӷ���n=128��blocksize=4
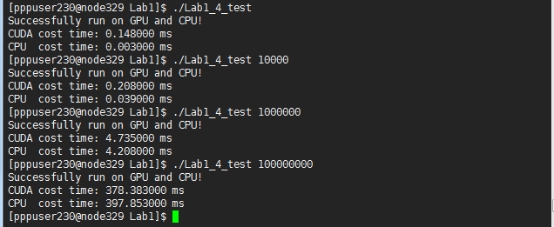
ͼ1-8 CUDA�������������ӷ���blocksize=16��n��ʾ����
ͼ1-9 CUDA�������������ӷ���blocksize=32��n��ʾ����
ʵ���
2.1 ʵ��Ŀ����Ҫ��
(1) ����ʹ��pthread�IJ��б����ƺ������Ż��Ļ���ԭ���ͷ�����
(2) �˽Ⲣ�б�������ݷ���������ֽ�Ļ���������
(3) ʹ��pthreadʵ��ͼ���������IJ����㷨��
(4) Ȼ��Գ���ִ�н�����мķ������ܽᡣ
2.2 �㷨����
CPU������
����ʼ;
Mat image = imread(); //����ͼ��
for����image���߽�����������ص㣺
ȡ���ĵ���Χ�����˴�С�����ؿ�point_ROI;
Convolute(point_ROI, kernel); //��������
�Ա߽�㸳ֵΪ0;
�������;
Pthread������
����ʼ;
Mat image = imread; //����ͼ��
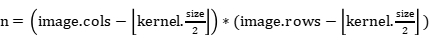 ;
;
����n��pthread;
ÿ���߳�ִ��һ��point_ROI*kernel����˲���image����ֵ��
�ȴ��߳̽�������ʾimage;
�������;
2.3 ʵ�鷽��
����������windows7+visual studio2017+opencv3.0.0
���л�����XshellԶ�����ӵ�Linux������
2.4 ʵ���������

ͼ2-1 windows7+VS2017+opencv3.0.0����Ч��
ִ�н���Աȣ�
ʵ����
ʵ����
ʵ����
��¼
��OpenCV3.0.0 + Visual Studio 2017�����´�������������á�
1. �½���Ŀ
����ļ����½���Visual C++ ����Ŀ��opencv_conv
2. �Ҽ������ļ����µġ�Դ�ļ������½����C++�ļ���conv_func.cpp��ȷ��
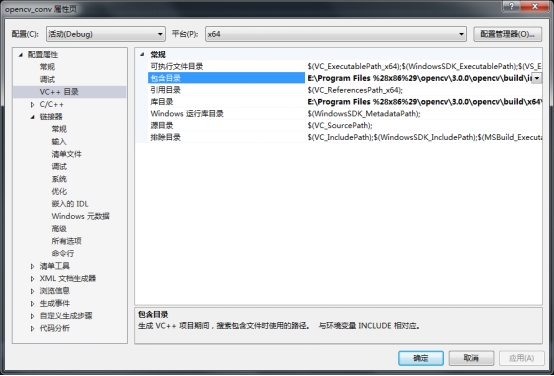
3. �Ҽ������ļ��С�opencv_conv�������ԡ���VC++Ŀ¼����
������Ŀ¼�����ӣ�
${OpenCV��ѹ·��}\opencv\build\include
${OpenCV��ѹ·��}\opencv\build\include\opencv
${OpenCV��ѹ·��}\opencv\build\include\opencv2
����Ŀ¼�����ӣ�
${OpenCV��ѹ·��}\opencv\build\x64\vc12\lib
4. ����������������������ӡ�opencv_ts300.lib���͡�opencv_world300.lib����һ��Ҫ�ֶ����룡��
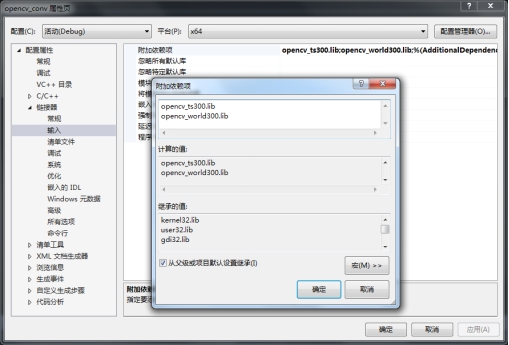
5. ����${OpenCV��ѹ·��}\opencv\build\x64\vc12\bin���еĶ�̬�����ļ����Ƶ���C:\Windows\System32���У����ļ���ΪWindows7ϵͳ�Ķ�̬�����ļ��У�����ʡȥÿ��ִ�С�opencv����.exe��֮ǰ�����������̬�����ļ����Ƶ���opencv.exe����ͬ�ļ����¡�
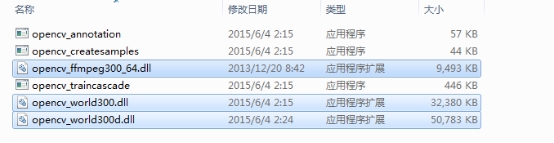
6. ���Ƴ�����������ӡ�ִ�С�.exe���ļ�

