使用 python 进行音频处理
目录
使用 python 进行音频处理 1
实验目的及实验内容 1
实验目的: 1
实验内容: 1
原理分析: 1
实验环境 6
实验步骤及实验过程分析 8
解码结果: 56
实验结果总结 57
实验目的及实验内容
(本次实验所涉及并要求掌握的知识;实验内容;必要的原理分析)
实验目的:
使用 python 进行音频处理
实验内容:
学习音频相关知识点,掌握 MFCC 特征提取步骤,使用给定的 chew.wav 音频文件进行特征提取。音频文件在实验群里下载。
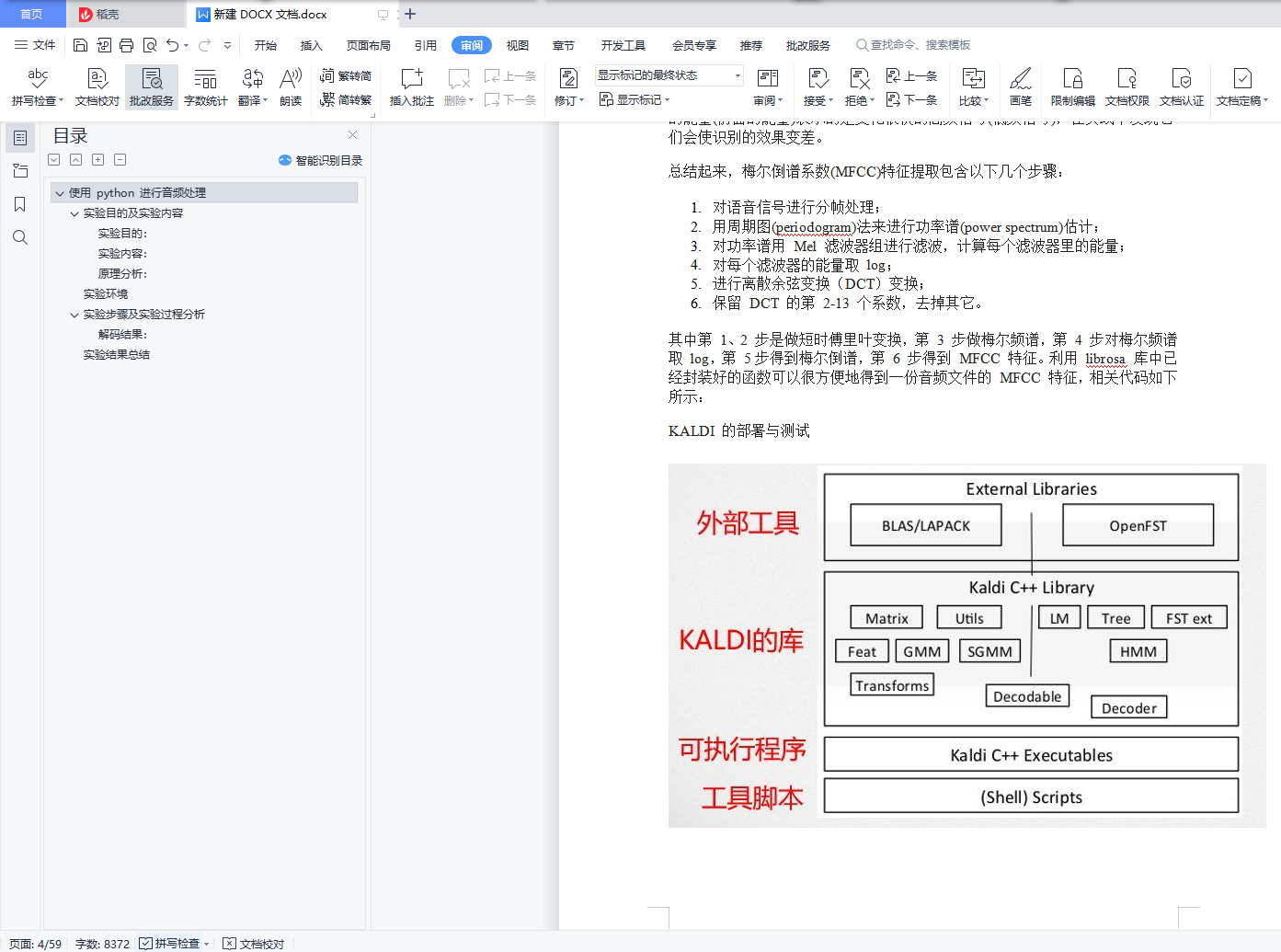
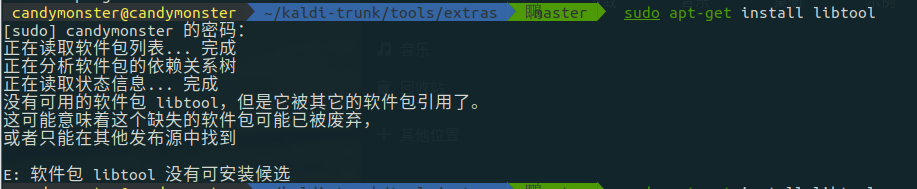
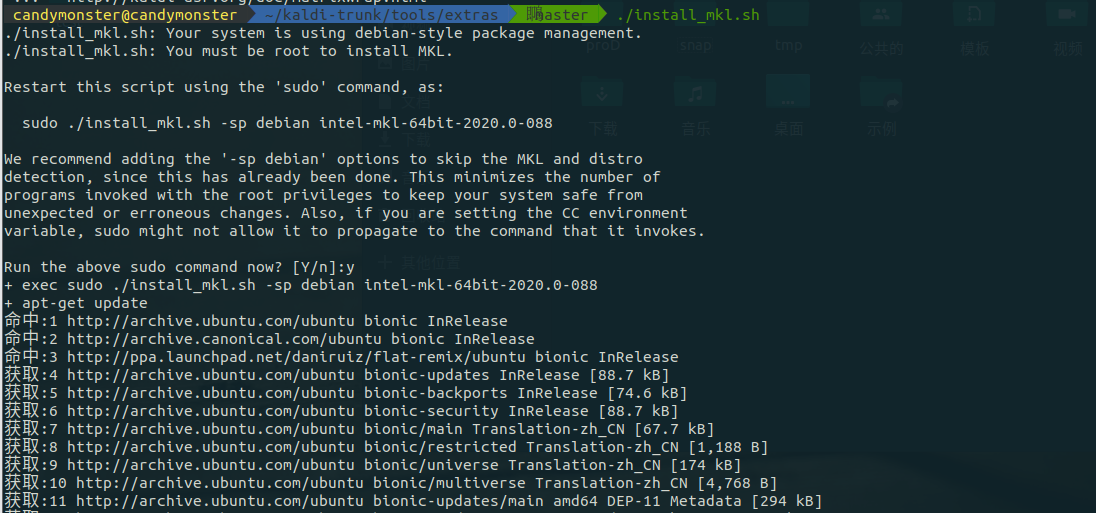
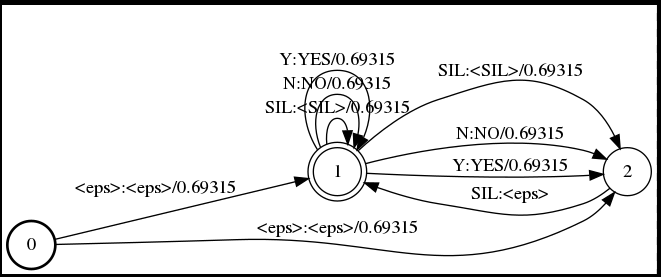
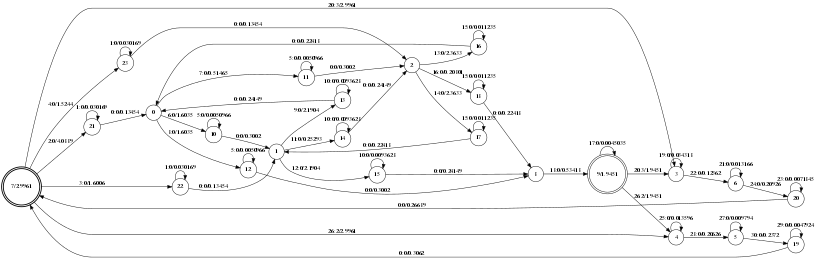
部署 KALDI,简要叙述部署步骤运行 yes/no 项目实例,简要解析发音词典内容,画出初步的 WFST 图(按 PPT 里图的形式)。
调整并运行 TIMIT 项目,将命令行输出的过程与 run.sh 各部分进行对应,叙述顶层脚本run.sh 的各部分功能(不需要解析各训练过程的详细原理)。
原理分析:
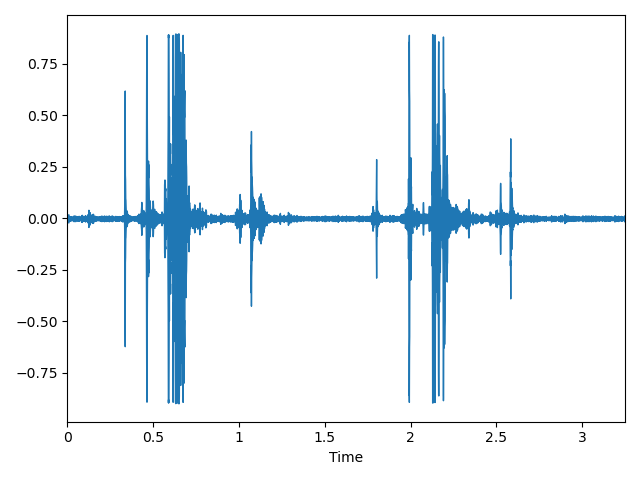
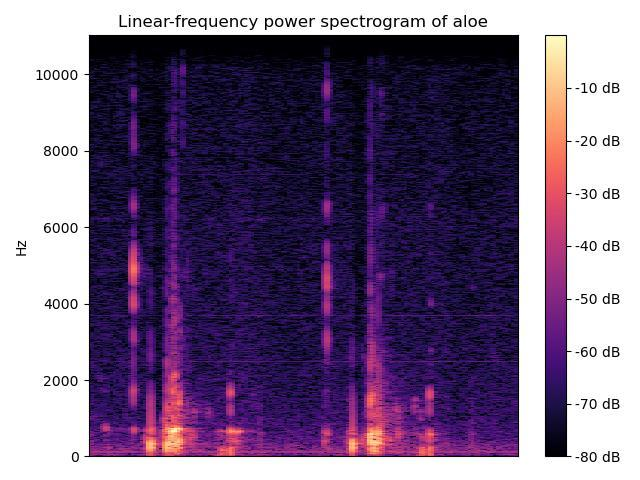
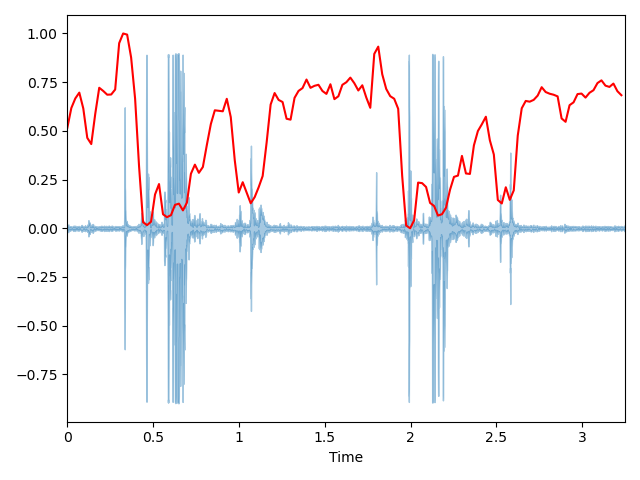
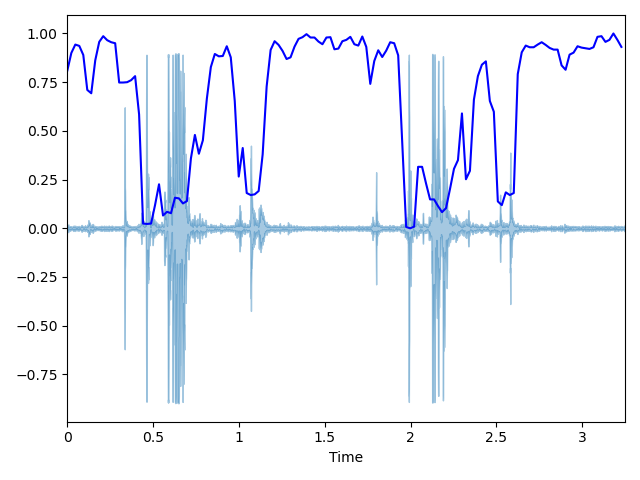
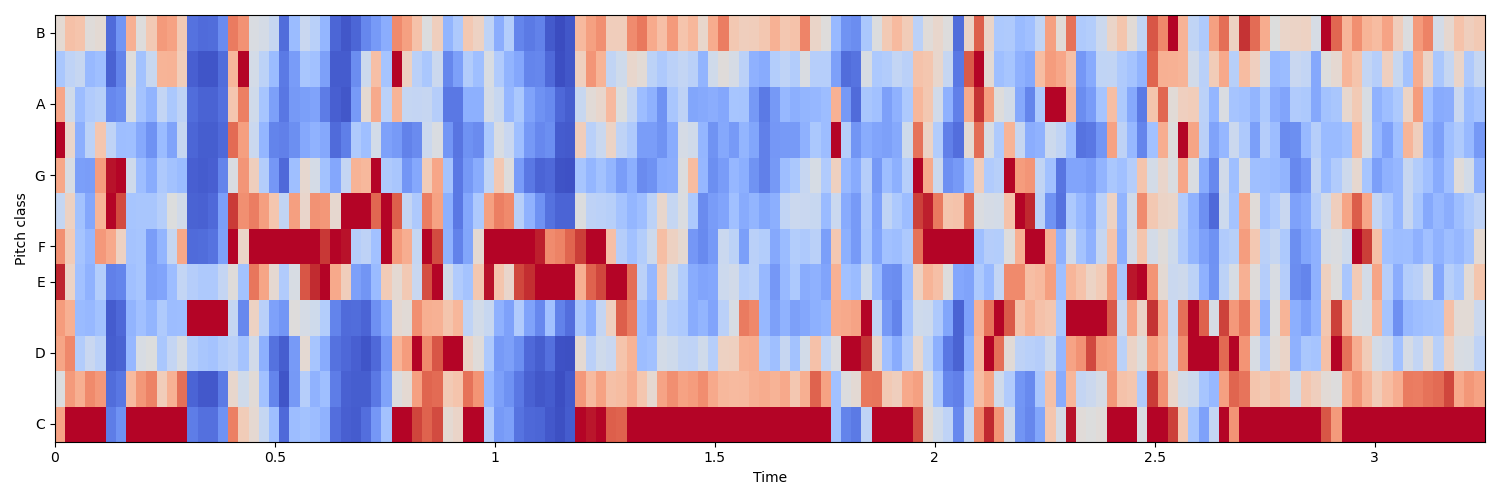
对 chew.wav 进行特征提取声音信号本是一维时域信号(声音信号随时间变化),我们可以通过傅里叶变换将其转换到频域上,但这样又失去了时域信息,无法看出频率分布随时间的变化。短时傅里叶(STFT)就是为了解决这个问题而发明的常用手段。
所谓的短时傅里叶变换,即把一段长信号分帧、加窗,再对每一帧做快速傅里叶变换(FFT),最后把每一帧的结果沿另一个维度堆叠起来,得到类似于一幅图的二维信号形式。
语音信号是不稳定的时变信号,但为了便于处理,我们假设在一个很短的时间内,如-40ms 内为一个稳定的系统,也就是 1 帧。但是我们不能简单平均分割语音,相邻的帧之间需要有一定的重合。我们通常以 25ms 为 1 帧,帧移为 10ms,因此 1 秒的信号会有 10 帧。