实验目的及实验内容
目录
实验目的及实验内容 1
实验目的: 1
实验内容: 1
原理分析: 1
实验环境 2
实验步骤及实验过程分析 2
当当网图书榜爬取过程: 8
实验结果总结 15
实验目的:
使用 requests-BeautifulSoup-re 技术路线,编写程序爬取网页。
实验内容:
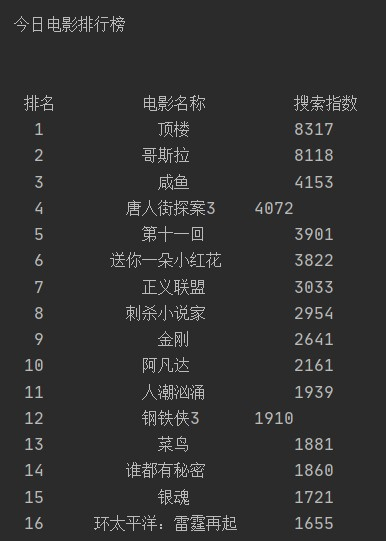
参考实例 4,爬取百度搜索风云榜 任一榜单,搜索结果按顺序逐行输出(含编号),榜单自选。
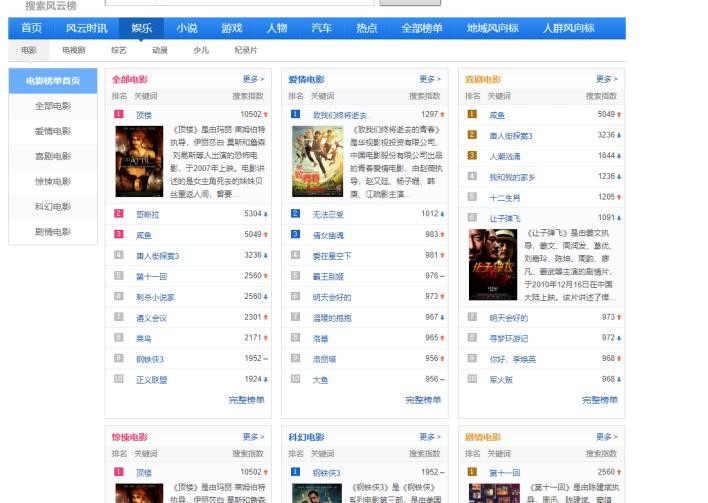
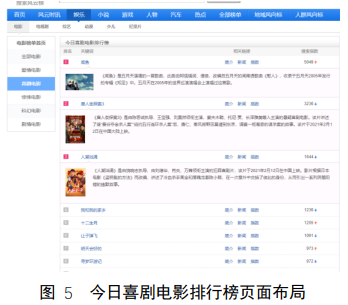
本次实验选取的目标榜单为“百度搜索风云榜-娱乐-电影榜”,结果将输出并保存该页面的六个榜单:全部电影榜单、爱情榜单、喜剧榜单、惊悚榜单、科幻榜单、剧情榜单这六个板块的搜索指数排名前 50 的电影名称及其搜索指数。
结果将额外被保存在 data 目录下的 txt 文本文档中。
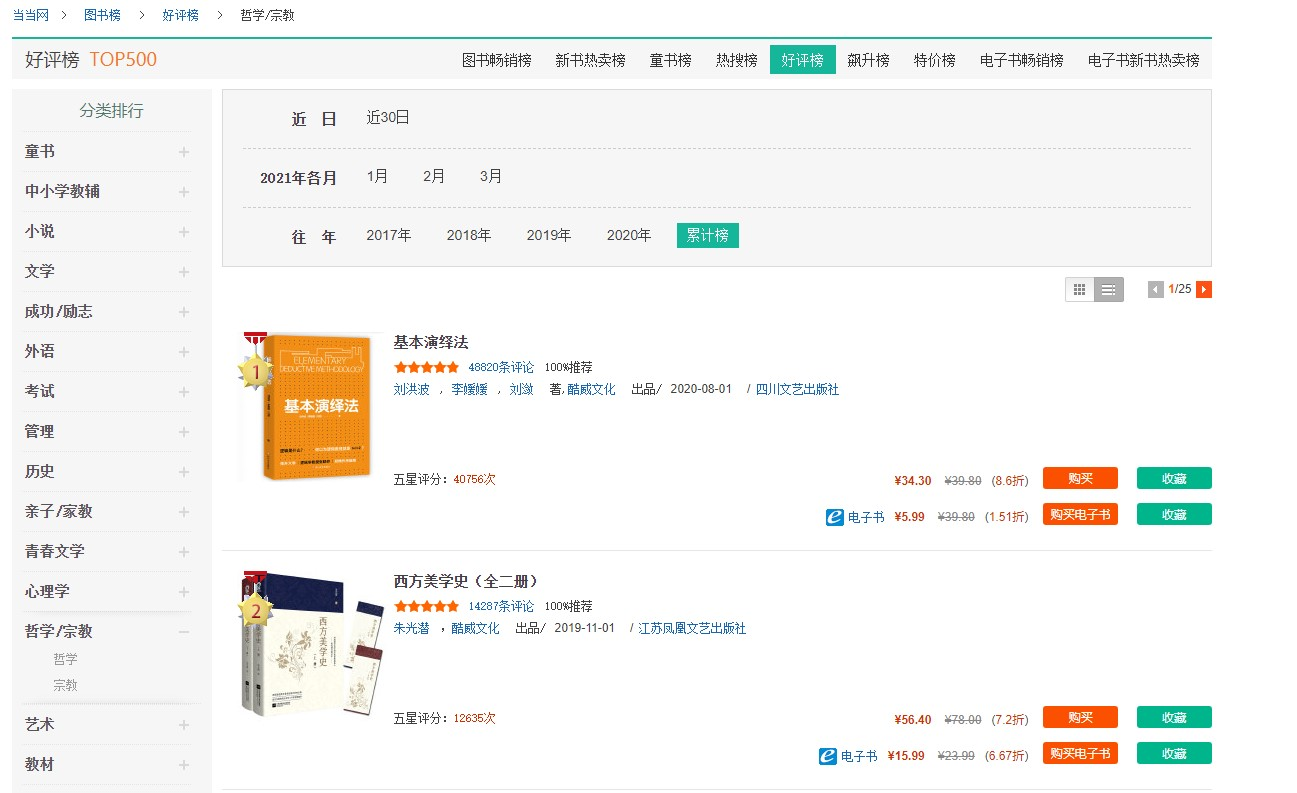
爬取当当图书排行榜(榜单自选),格式:爬取结果包含但不限于[排名 书名 作者],注意输出格式对齐。
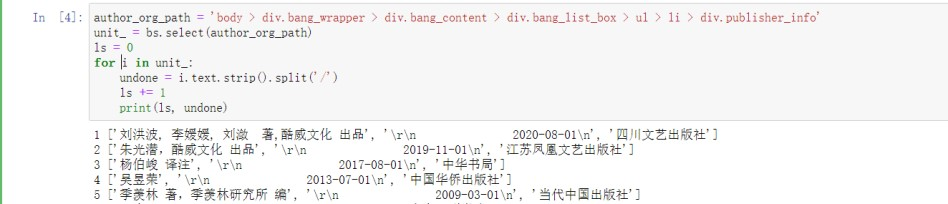
本次实验选取的目标榜单为“当当网-图书榜-好评榜(top 500)-哲学/宗教”(,结果将输出并保存宗教/哲学系列的累计好评榜排行前 500 本书的排名、书名、作者及出品方、出版社、出版年份、现价、原价、折扣信息。
结果将额外被保存在 data 目录下的 CSV 文件中。
原理分析:
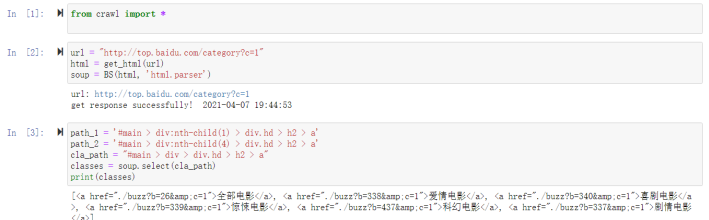
使用 python 的 request 库的 get 方法可以很方便地完成对网页的访问请求并获取网页的 HTML 源码;
使用 python 的 BeaustifulSoup 方法可以很方便、灵活地选择对 HTML 的解析方式(如 find 方法、select 方法等),进而获取每个节点的属性、内容,为爬虫爬取爬取者关注的、存储在网页上的数据创造条件;
使用 python 的 lxml 库的 etree 方法也可以对 HTML 源码进行解析,其原理与 BeaustifulSoup 方法的 find 方法、select 方法原理差不多,但更为灵活,我个人更喜欢用这种方法。鉴于实验要求使用 requests-BeautifulSoup-re 技术路线,因此 etree 方法在本实验中仅作为辅助方法被使用一次;
使用 python 的 re 库可以将正则表达式应用于对结果的过滤,从而从 HTML 节点中过滤并提取到自己想要的结构化数据,进而进行存储。
实验环境
(本次实验所使用的器件、仪器设备等的情况)
处理器:Intel(R) Core(TM) i5-9300H CPU @ 2.40GHz 2.40 GHz
操作系统环境:Windows 10 家庭中文版 x64 19042.867
编程语言:Python 3.8
其他环境:16 GB 运行内存
IDE 及包管理器:JetBrains PyCharm 2020.1 x64, anaconda 3 for Windows(conda 4.9.0)
借助的第三方库及使用目的:
BeautifulSoup:解析 HTML 网页结构并从中提取指定数据; CSV:用于结构化保存结果; lxml:解析 HTML 网页结构并从中提取指定数据;
os:用于判断文件是否存在、创建文件路径; random:创建随机选择; re:正则,用于网址过滤;
requests:模拟浏览器行为,发送 GET 请求以获取目标网站的数据; time:用于停止等待,避免因为访问过于频繁而被目标网页所在服务器限制访问。