汉语分词系统
目录
汉语分词系统 1
摘要 1
1 绪论 1
2 相关信息 1
2.1 实验目标 1
2.2 编程语言与环境 2
2.3 项目目录说明 2
3 训练测试 3
4 词典构建 3
5 正反向最大匹配分词实现 3
5.1 正向最大匹配分词-最少代码量 3
5.2 反向最大匹配分词-最少代码量 4
6 正反向最大匹配分词效果分析 5
7 基于机械分词系统的速度优化 6
摘要
绪论
中文分词技术,是由于中文与英文为代表的拉丁语系语言相比,英文以空格作为天然的分隔符,而中文由于继承自古代汉语的传统,词语之间没有分隔。古代汉语中除了连绵词和人名地名等,词通常就是单个汉字,所以当时没有分词书写的必要。而现代汉语中双字或多字词居多,一个字不再等同于一个词。且在中文里,“词”和“词组”边界模糊。
中文分词中存在歧义识别和新词识别两大难题。
相关信息
2.1实验目标
本次实验目的是对汉语自动分词技术有一个全面的了解,包括从词典的建立、分词算法的实现、性能评价和优化等环节。本次实验所要用到的知识如下:
基本编程能力(文件处理、数据统计等)
相关的查找算法及数据结构实现能力
语料库相关知识
正反向最大匹配分词算法
N 元语言模型相关知识
分词性能评价常用指标
2.2编程语言与环境
Python 3.7.9 ,Windows11,VScode
2.3项目目录说明
目录中存在Code和io_files两个文件夹,Code文件夹中存放第一部分到第四部分实验代码,io_files文件夹中存放第一部分到第四部分实验产生文件和依赖文件。
io_files文件夹:
199801_sent.txt 为标准文本,是1998 年 1 月《人民日报》未分词语料,用于产生训练集和测试集
199801_seg&pos.txt 为标准文本,是1998 年 1 月《人民日报》的分词语料库,用于产生测试集对应的分词标准答案
dic.txt为自己形成的分词词典,存放根据训练集产生的词典
train.txt 为训练集,取分词语料库中 的数据作为训练集用于生成词典
std.txt 为标准答案, 取分词语料库中另外 的数据作为标准答案,与分词结果进行比对计算准确率、召回率和F 值
test.txt 为测试集,在未分词语料中取与标准答案相对应的 的数据作为测试集产生分词结果
seg_FMM.txt 为全文的分词结果,使用正向最大匹配分词,使用train.txt文件作为训练集,将199801_sent.txt文件进行分词
seg_BMM.txt为全文的分词结果,使用反向最大匹配分词,使用train.txt文件作为训练集,将199801_sent.txt文件进行分词
score.txt为第三部分生成的评测分词效果的文本,其中包括准确率(precision)、召回率(recall)和F 值
seg_FMM_1_10.txt 为测试集分词结果,使用正向最大匹配分词,使用train.txt文件作为训练集,将test.txt文件进行分词
seg_BMM_1_10.txt 为测试集分词结果,使用反向最大匹配分词,使用train.txt文件作为训练集,将test.txt文件进行分词
better_seg_FMM.txt 为测试集分词结果,使用优化后的正向最大匹配分词,使用train.txt文件作为训练集,将test.txt文件进行分词,计算分词时间与seg_FMM_1_10.txt分词时间进行比较
better_seg_BMM.txt 为测试集分词结果,使用优化后的反向最大匹配分词,使用train.txt文件作为训练集,将test.txt文件进行分词,计算分词时间与seg_BMM_1_10.txt分词时间进行比较
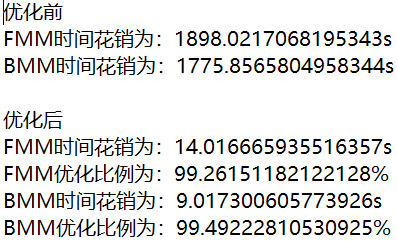
TimeCost.txt 为分词所用时间,存放优化前和优化后的分词时间
Code文件夹:
part_1.py 为实验第一步词典的构建代码,其中包括生成分词词典函数以及生成训练集、测试集和标准答案的函数
part_2.py 为实验第二步正反向最大匹配分词实现代码,其中包括读取词典内容函数、正向最大匹配分词函数和反向最大匹配分词函数
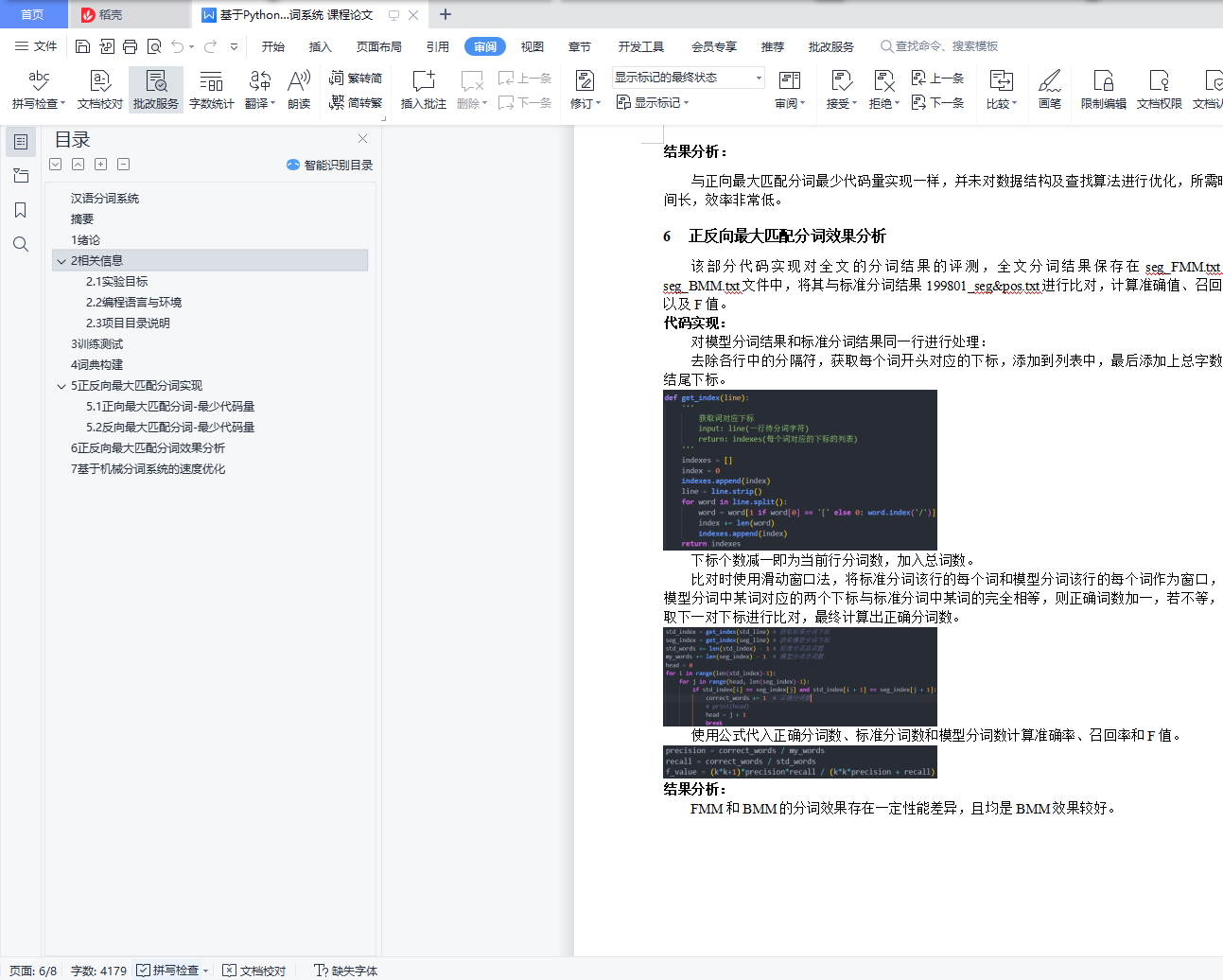
part_3.py 为实验第三步正反向最大匹配分词效果分析代码,其中包括计算评测得分函数,计算总词数和正确词数函数,计算准确率、召回率和f值函数以及获取词对应下标的函数
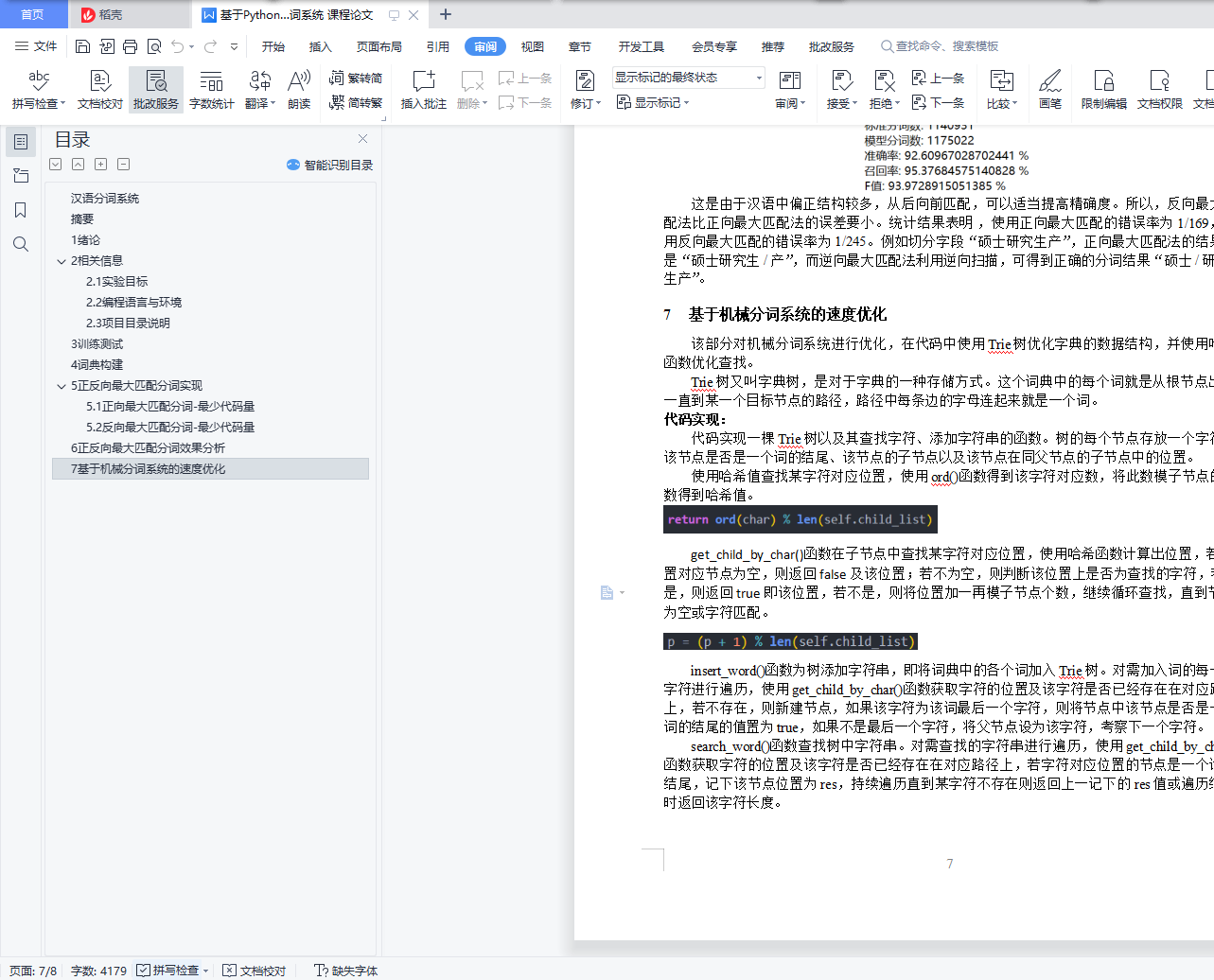
part_4.py 为实验第四步基于机械匹配的分词系统的速度优化代码,其中包括Trie树的实现以及其中添加字符串函数,查找字符串函数,在子节点中查找字符对应位置函数和返回哈希值函数,还有获得正向最大匹配的词典树函数,获得反向最大匹配的词典树函数,优化后正向最大匹配分词函数,优化后反向最大匹配分词函数,全文分割函数以及计算时间函数