基于Bi-LSTM的古汉语自动分词及词性标注一体化模型
摘 要:本文针对古汉语自动分词和词性标注进行研究。近年来大多研究者把分词和标注视作对单字进行标签,本文借鉴了这种思路,首次提出使用二元标签模式,使一个标签同时带有分词和词性信息。利用双向长短期记忆神经网络(Bidirectional Long Short-Term Memory, Bi-LSTM)的特性,获取上下文信息,在一次计算中同时对单字进行分词及词性标记。利用同一程序进行分词和标注的结果具有统一性,避免了人工的理解差异造成的语料库分词标注标准不统一的问题。本文提出针对古代汉语的分词标注一体化模型的标签正确率可达到95%,且对于部分有疑问的标签结果可输出多种其他较为可能的结果供古文研究者选择校对。
关键词:古汉语,自动分词,词性标注,Bi-LSTM,二元标签
Automatic segmentation and labeling model for ancient Chinese based on Bi-LSTM
Abstract: This paper is aimed at the segmentation and part-of-speech tagging of ancient Chinese. In recent years, most researchers have process word segmentation and labeling as the idea of labeling words. In recent years, most researchers regard word segmentation and tagging as labeling for words. This paper uses this idea for reference, and proposes a binary tagging model for the first time to make a tag contain both word segmentation and part-of-speech information. By using the characteristics of the Bidirectional Long Short-Term Memory (Bi-LSTM) neural network, the context information is obtained, and the word segmentation and part-of-speech tagging are handled simultaneously in one calculation. The results of word segmentation and labeling using the same program are uniform, which avoids the problem that the corpus segmentation labeling standard is not uniform due to the difference of artificial understanding. This paper proposes that the word labeling model for ancient Chinese can achieve 95% correctness of the word label, In addition, for some questionable label results, a variety of other likely results can be output for the Ancient Chinese researchers to use.
Keywords: Ancient Chinese, word segmentation, Part-of-speech tagging, Bi-LSTM,binary tagging
目录
基于Bi-LSTM的古汉语自动分词及词性标注一体化模型 1
1 绪论 2
2 研究现状 2
3 古汉语自动分词及词性标注一体化模型 3
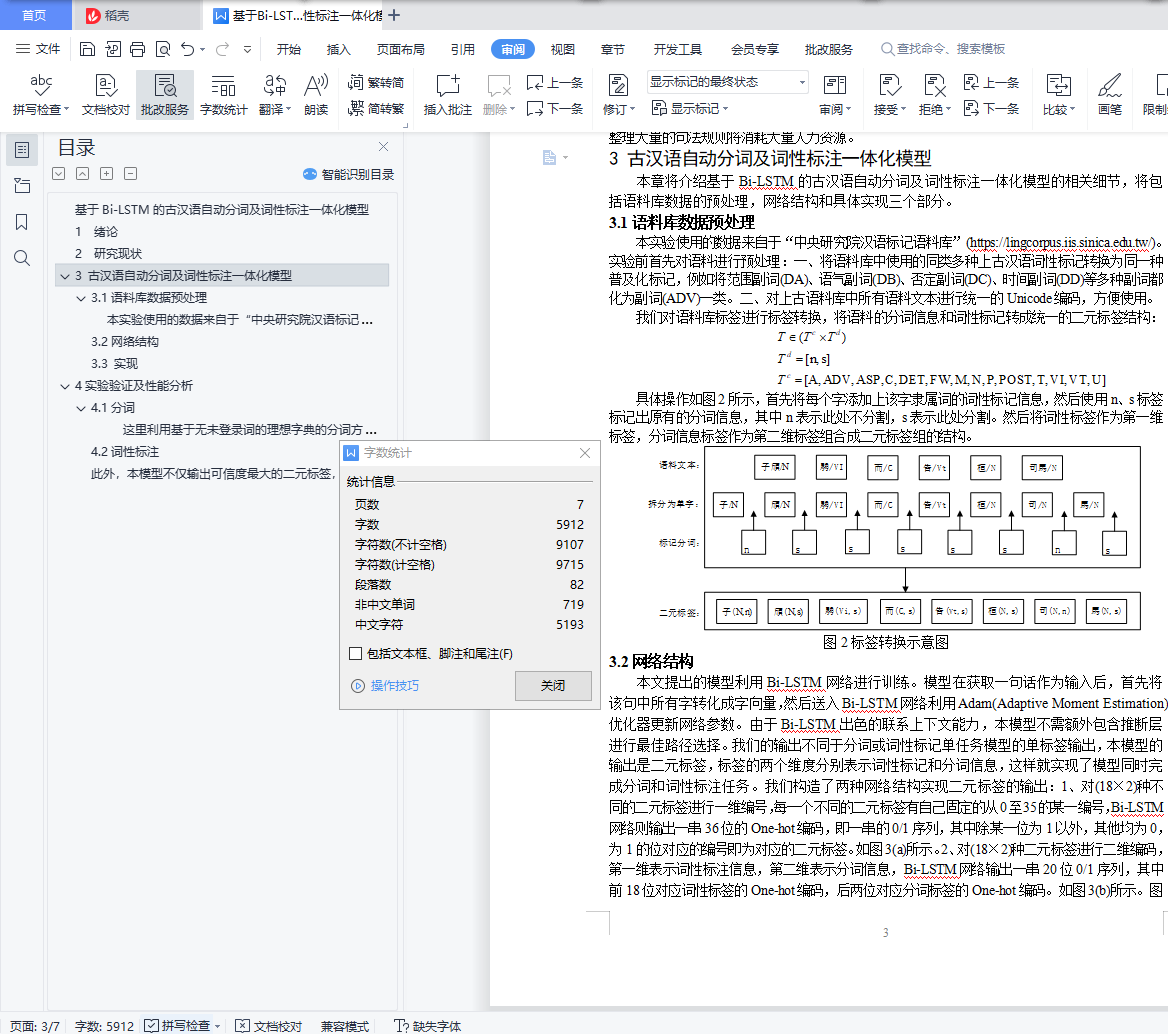
3.1语料库数据预处理 3
本实验使用的数据来自于“中央研究院汉语标记语料库”(https://lingcorpus.iis.sinica.edu.tw/)。实验前首先对语料进行预处理:一、将语料库中使用的同类多种上古汉语词性标记转换为同一种普及化标记,例如将范围副词(DA)、语气副词(DB)、否定副词(DC)、时间副词(DD)等多种副词都化为副词(ADV)一类。二、对上古语料库中所有语料文本进行统一的Unicode编码,方便使用。 3
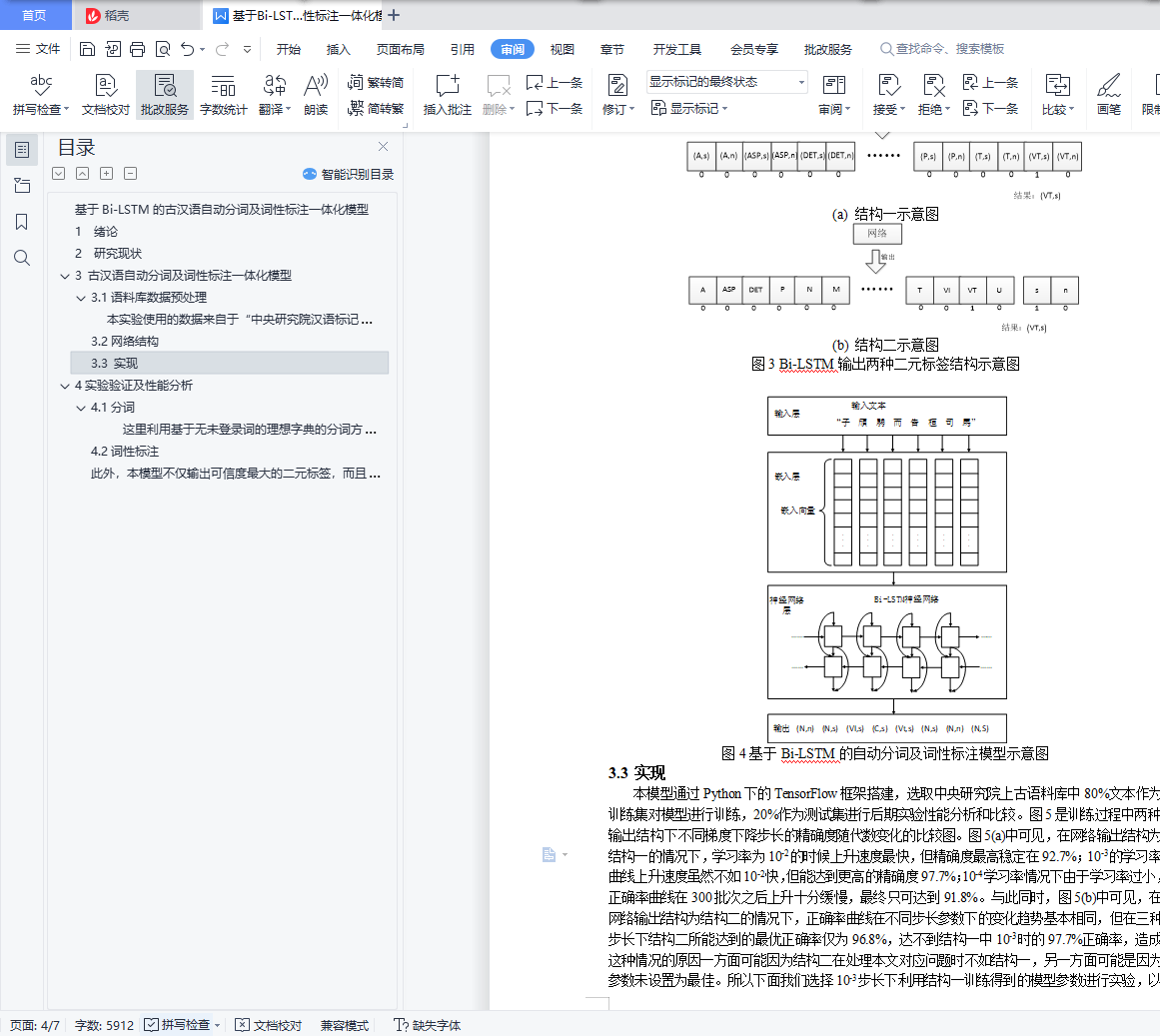
3.2网络结构 3
3.3 实现 4
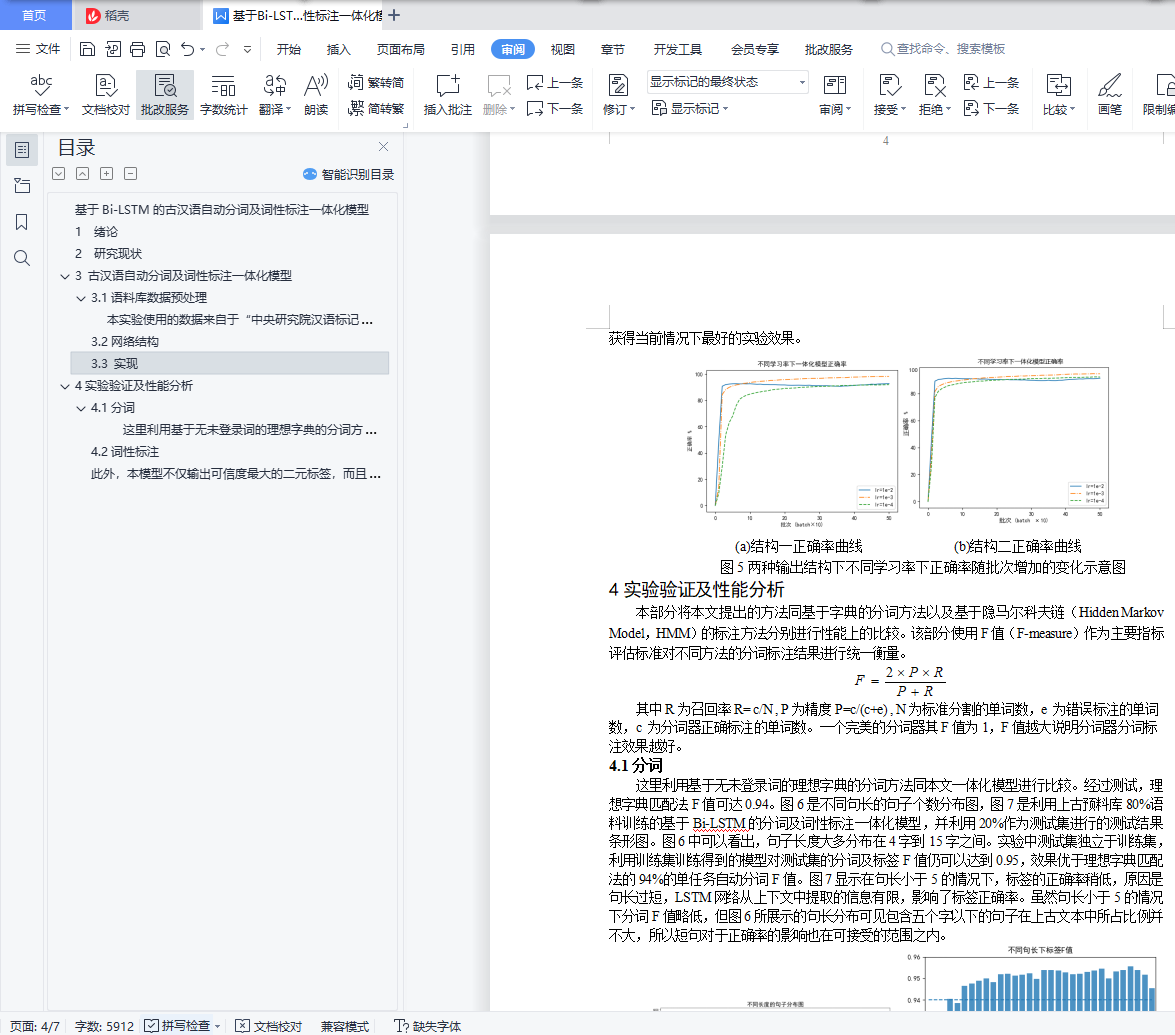
4实验验证及性能分析 5
4.1分词 5
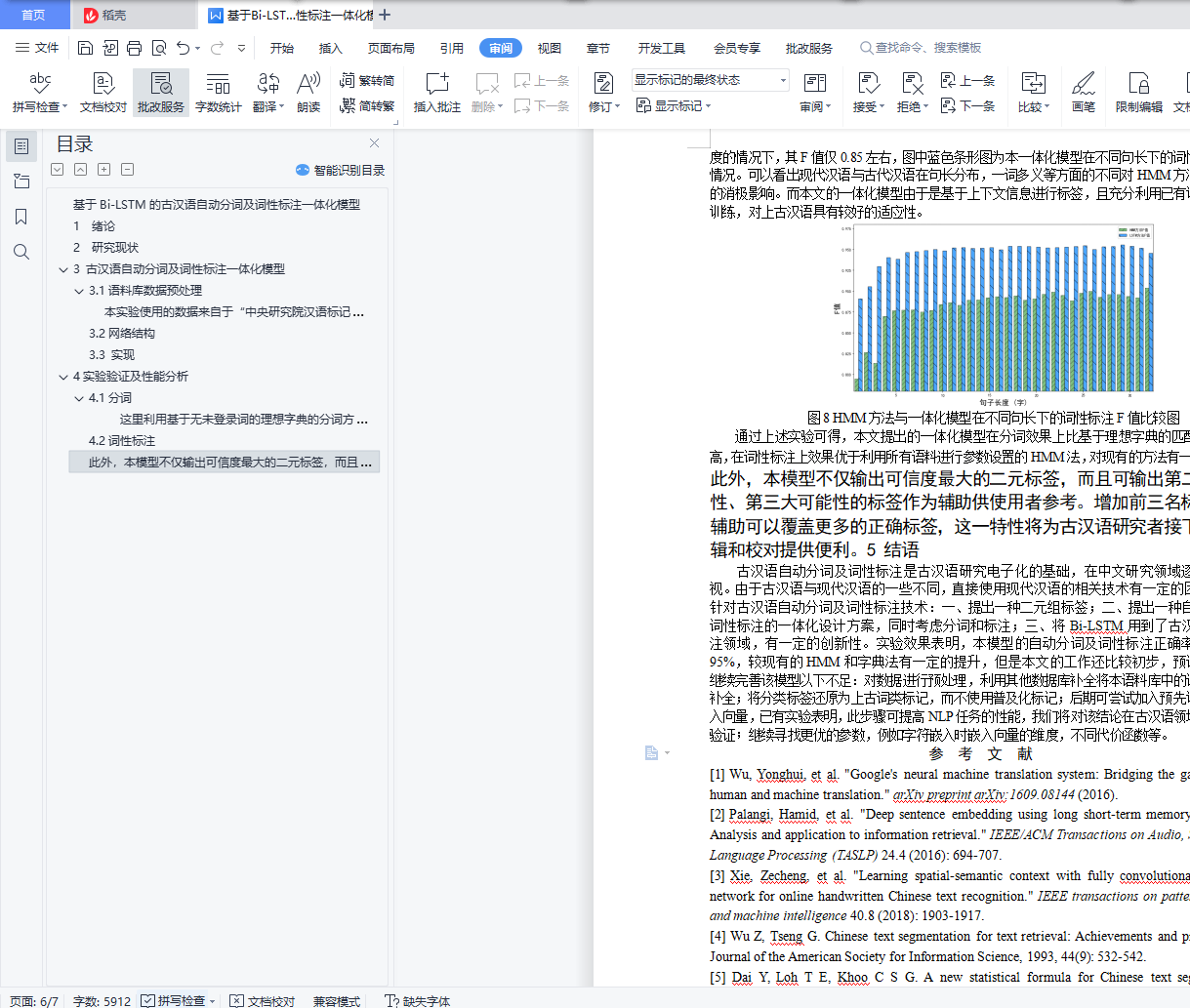
4.2词性标注 5
5 结语 6