摘 要
以大数据为代表的新一代信息技术浪潮渗透在包括医疗卫生、健康管理在内的诸多领域,有力地改变着传统医学的统计分类方法和思维模式,并可能为人类提供高效准确的数据挖掘和疾病风险分类评估能力。然而,医学数据,尤其是人群队列的医学调研数据,通常观测大量属性,单个样本呈现出个体差异性,使这些医学数据具有高维复杂的特征,其数据挖掘和疾病风险分类在具有重大研究价值的同时,也面临着更大的技术挑战。
论文选取乳腺癌人群队列调研数据为研究对象。乳腺癌是全球女性发病率最高的恶性肿瘤类型,早期的疾病风险分类可以提前介入治疗从而极大地降低发病率和死亡率。欧美国家的乳腺癌风险分类模型不适合用于中国女性,,亟需建立适合中国国情的低漏警率、低成本和易推广的乳腺癌风险分类模型。因此,乳腺癌人群队列数据挖掘和疾病风险分类具有重大而迫切的现实价值,同时在数据类型上也具有典型的代表性。
论文围绕以乳腺癌人群队列数据为代表的复杂高维医学数据,从数据挖掘和疾病风险分类方面的主要工作和创新包括:
(1)针对医学数据的高维性和非平衡性特征,论文提出了单类F-score特征选择法进行特征筛选,并建立了基于单类F-score特征选择法的朴素贝叶斯分类模型。该模型仅用8个特征即获得漏警率9.1%、受试者工作特征曲线(ROC曲线)下面积0.776的效果,优于其它对比算法,且已具备一定的临床指导价值,表明单类F-score特征选择具备良好地应对高维非平衡数据分类的能力。
(2)针对单类F-score特征选择在筛选特征子集时未考虑特征之间相关性的问题,论文提出了改进型的单类F-score诱导的基于遗传算法的特征选择法。实验结果证明改进后的模型ROC曲线下面积达到0.823,具备更好的分类效果。
(3)为了支持疾病风险分类模型在我国巨大人口基数中的推广,论文进一步研究了上述分类算法的显性化和分级的疾病风险显性化评估。前者实现了论文所提出的两类分类算法的闭式解表达,将分类算法中隐式的分类过程以查表计算的方式具象化。后者提出了一类树状结构的分级疾病风险评估框架,以概率的形式给出了分级模型不同分类结果下显示的患病风险量化值。
论文以单类F-score特征选择为基础,建立了一系列医学数据的挖掘和分
类算法,在乳腺癌人群队列数据上的效果已具备临床指导价值,并可以推广到相似疾病的数据挖掘和风险分类。
关键词: 朴素贝叶斯分类,单类F-score特征选择,遗传算法,分级模型
Study on the data mining and risk classification for high-dimensional complex medical data
Abstract
A new generation of information technology represented by big data has penetrated into health care, health management and many other fields. It effectively changes the statistical classification method and thinking pattern of traditional medicine, and provides the outstanding capability of data mining and disease risk assessment capabilities for human beings. The medical survey data of the population cohort are complex and high dimensional, which contain a huge number of attributes and individual differences. It is of great significance for data mining and disease risk classification, and facing technical challenges at the same time.
The cohort study data of breast cancer are chosen as the research data. Breast cancer has the highest incidence of all the malignant tumors in women worldwide. The breast cancer risk classification model can help reduce the incidence rate of breast cancer. It is necessary to build an efficient classification model to perform accurate and economical diagnoses. Only the respondents classified into the high risk group need further checks to determine the breast cancer patients. The classification model must have a low false-negative rate, must be low-cost and also can easy to be extended.
The main work and innovations in the field of data mining and disease risk classification of this paper include:
(1)Aiming at the characteristics of high dimension and imbalance of medical data, this paper proposes a one-class F-score feature selection method for feature selection, and establishes a Naive Bayesian classification model based on one-class F-score feature selection method. The experiment results show that, with the presented method, the false-negative rate is decreased to 0.09 and the area under the receiver operating characteristic curve (AUC) is 0.776 with 8 features selected only. Compared with related methods, our method leads to the lowest false-negative rate and the lowest number of features selected and has a certain clinical value. It shows that the one-class F-score feature selection is capable of dealing with high dimensional balance data classification.
(2)This paper proposes an improved one-class F-score induction feature selection based on genetic algorithm. The experimental results of the improved model showed that the AUC reached 0.823 and obtain a better classification effect.
(3)In order to support the promotion of the disease risk classification model in China's huge population base, this paper focus on the closed-form solution of the aforementioned classification algorithm and the explicit assessment of the classification of disease risk in the further studies. On the one hand, this paper proposed a closed-form formulation to describe the classification process. On the other hand, we proposed a method to express the risk probability of illness by tree structure based on probability.
This paper sets up a series of data mining and classification algorithms on medical data base on the one-class F-score feature selection. It has the clinical guidance value on breast cancer and can be extended to data mining and risk classification of similar diseases.
Key Words: naive Bayesian classifier, one-class F-score feature selection, genetic algorithm, hierarchical model
目 录
致 谢 I
摘 要 III
Abstract V
1 引言 1
1.1 课题研究背景及意义 1
1.2 研究内容 3
1.3 论文组织结构 4
2 研究综述 6
2.1 疾病风险分类模型的基础知识 6
2.1.1 表浅数据与疾病的相关性 6
2.1.2 乳腺癌风险分类模型的研究进展 7
2.2 非平衡数据分类的研究现状 8
2.2.1 数据的非平衡问题 8
2.2.2 非平衡数据的分类算法 9
2.3 特征选择的研究现状 11
2.3.1 特征选择的概述 11
2.3.2 特征子集的生成方法 12
2.3.3 特征的评价准则 13
2.4 本章小结 14
3 基于单类F-score特征选择的朴素贝叶斯分类模型 16
3.1 数据来源及处理 16
3.2 分类模型的评估标准 16
3.3 基于单类F-score特征选择的朴素贝叶斯分类 17
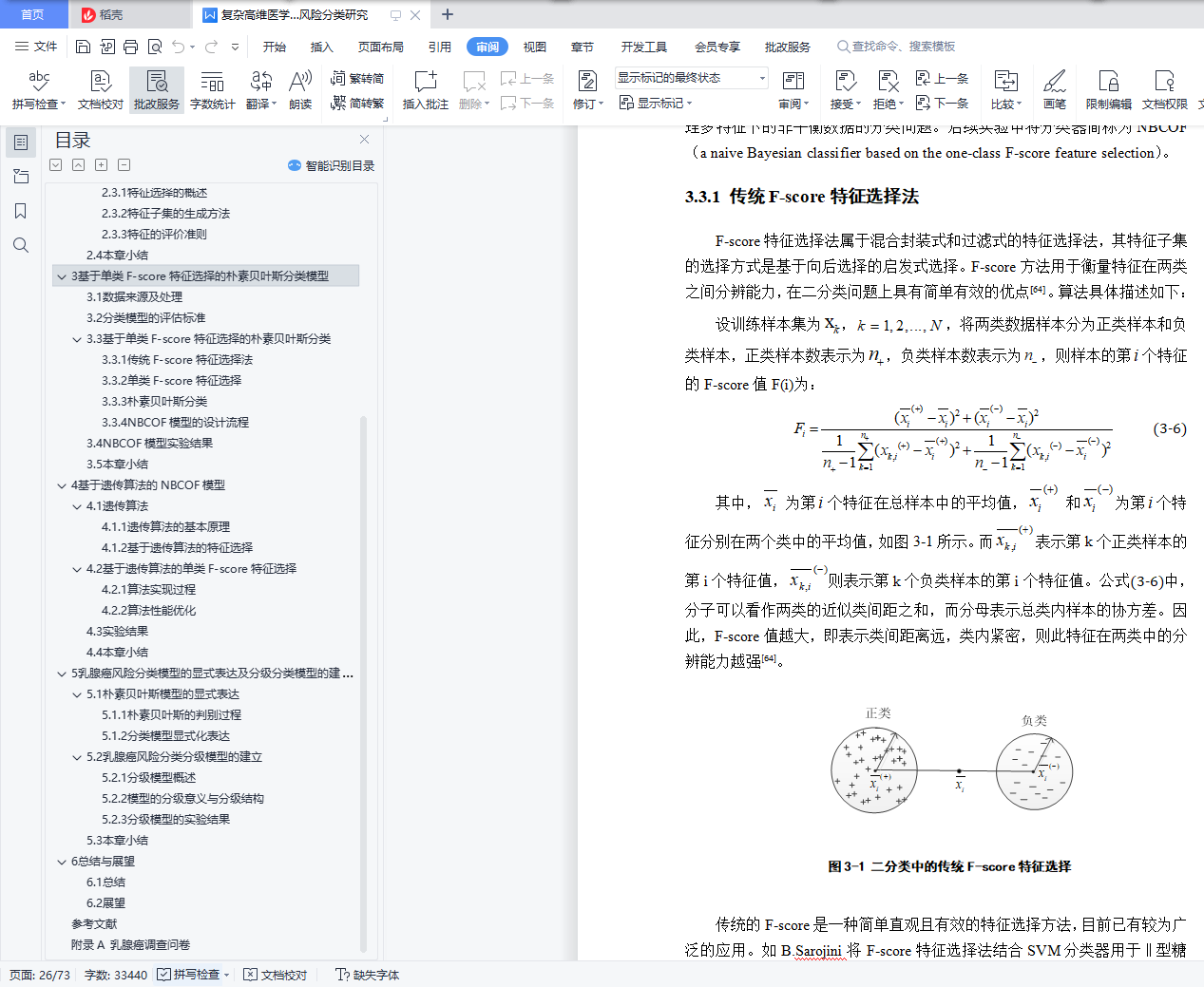
3.3.1 传统F-score特征选择法 18
3.3.2 单类F-score特征选择 19
3.3.3 朴素贝叶斯分类 20
3.3.4 NBCOF模型的设计流程 21
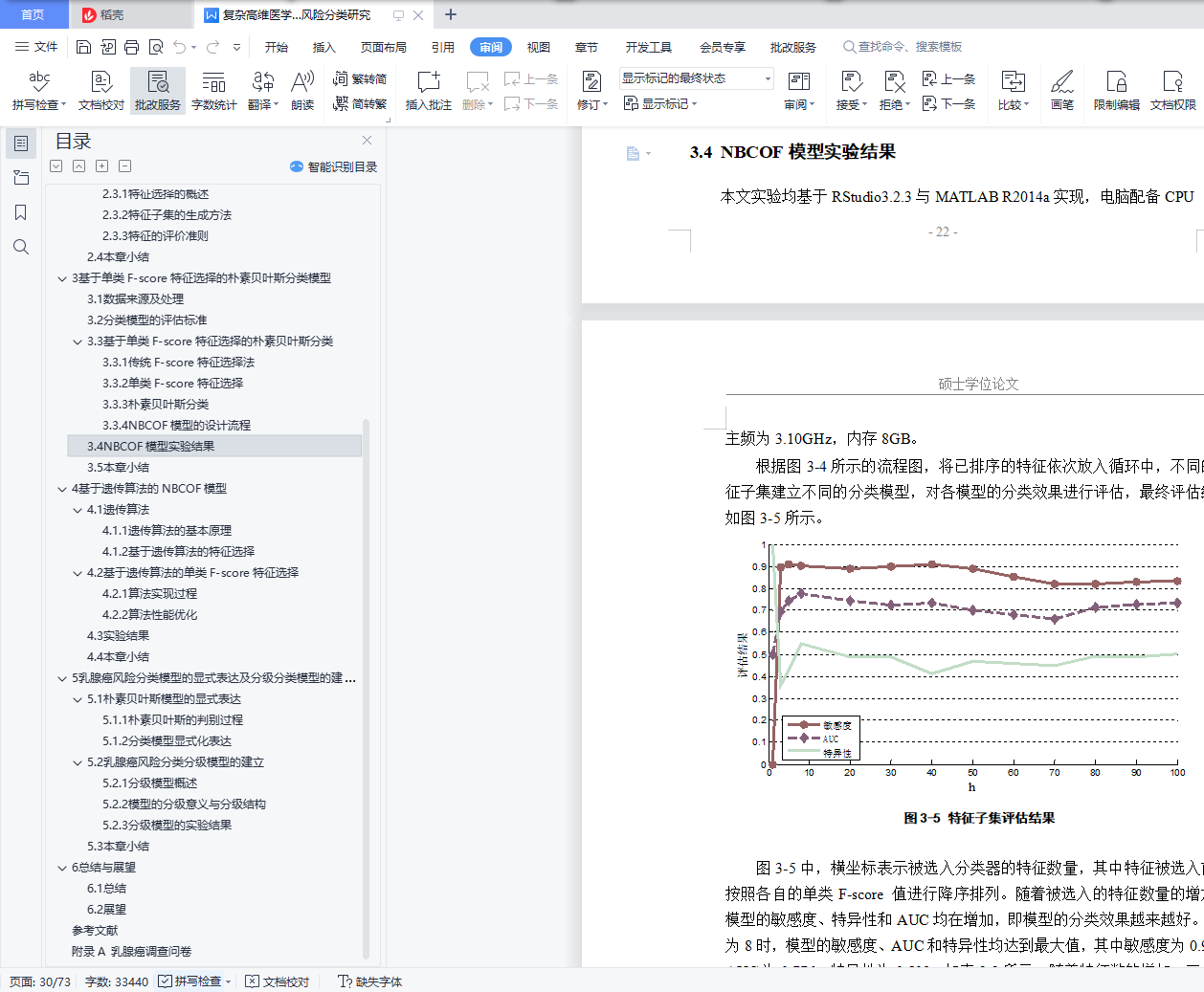
3.4 NBCOF模型实验结果 22
3.5 本章小结 25
4 基于遗传算法的NBCOF模型 26
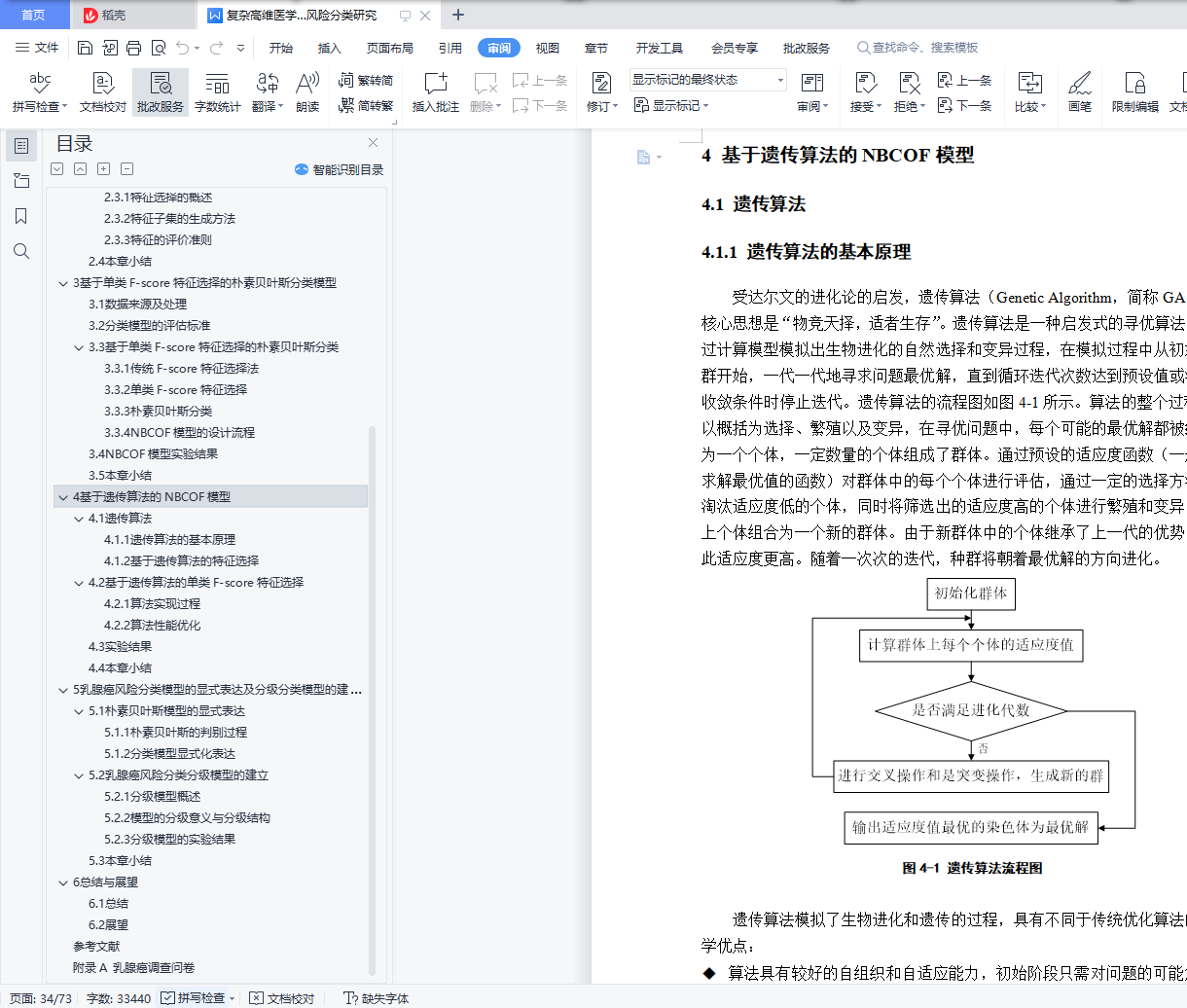
4.1 遗传算法 26
4.1.1 遗传算法的基本原理 26
4.1.2 基于遗传算法的特征选择 27
4.2 基于遗传算法的单类F-score特征选择 28
4.2.1 算法实现过程 28
4.2.2 算法性能优化 30
4.3 实验结果 33
4.4 本章小结 35
5 乳腺癌风险分类模型的显式表达及分级分类模型的建立 37
5.1 朴素贝叶斯模型的显式表达 37
5.1.1 朴素贝叶斯的判别过程 37
5.1.2 分类模型显式化表达 39
5.2 乳腺癌风险分类分级模型的建立 44
5.2.1 分级模型概述 44
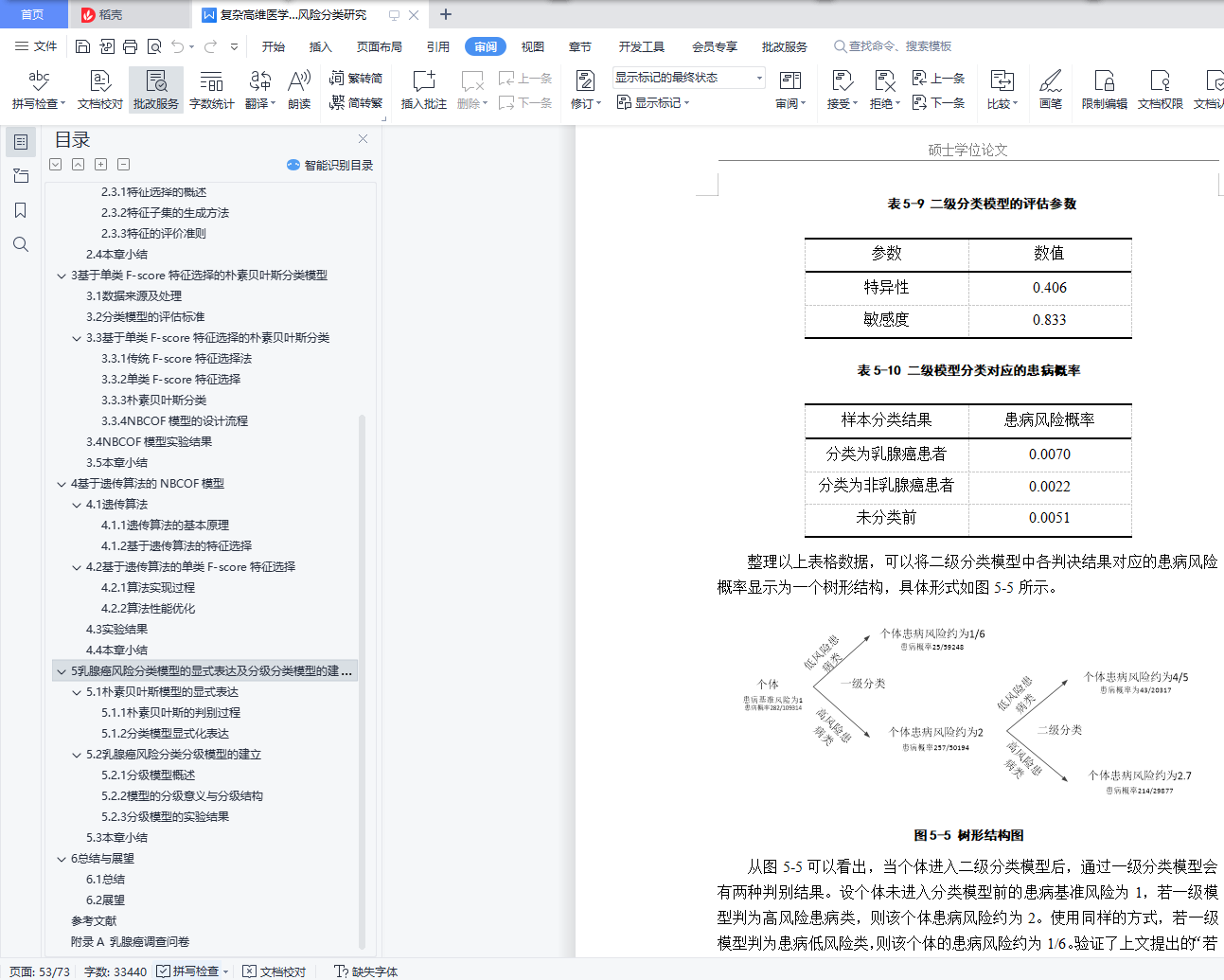
5.2.2 模型的分级意义与分级结构 45
5.2.3 分级模型的实验结果 48
5.3 本章小结 50
6 总结与展望 52
6.1 总结 52
6.2 展望 52
参考文献 55
附录A 乳腺癌调查问卷 61