互联网文本的法律法条引用跟踪分析
目录
互联网文本的法律法条引用跟踪分析 1
一.任务介绍 1
二.核心算法介绍 3
2.1 整体模型概览 3
2.2 法律法条识别确定有限自动机 5
2.3 历史版本区分 5
(3)历史版本中没有对应的法条。 7
(1) 7
(3) 7
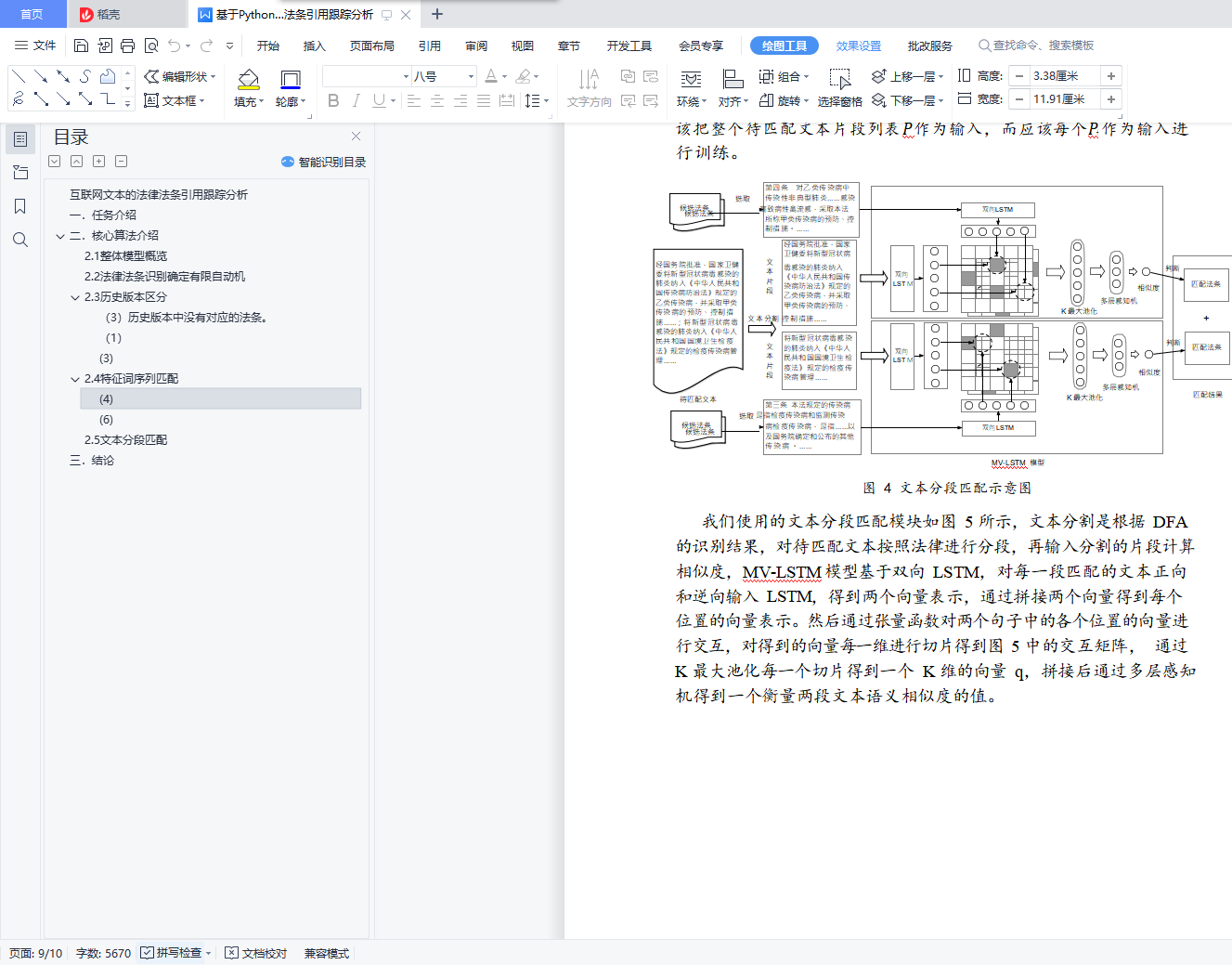
2.4 特征词序列匹配 7
(4) 10
(6) 11
2.5 文本分段匹配 11
三.结论 13
一.任务介绍
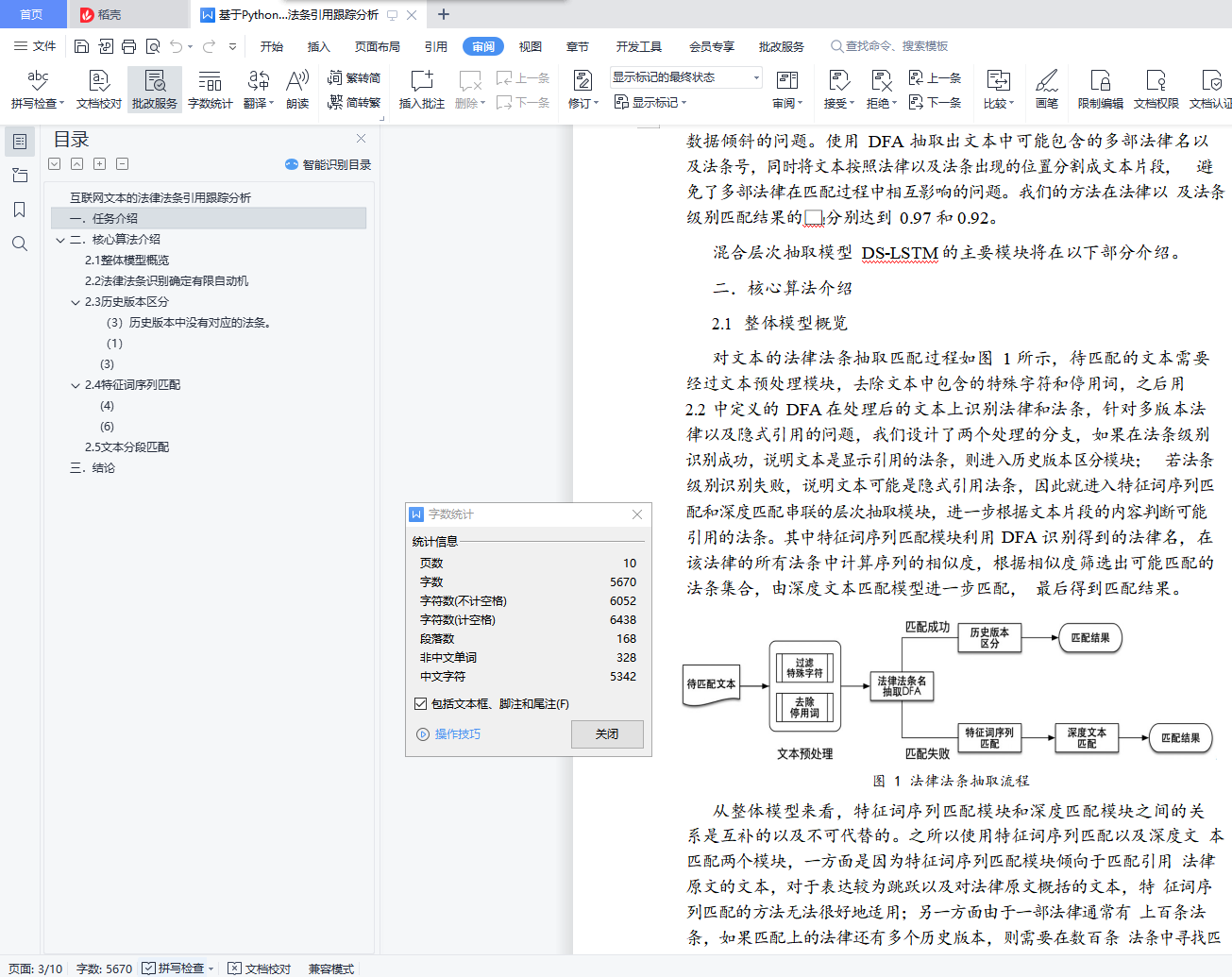
我们致力于提出一种能够有效解决法律相关特有问题的高准确度的法律法条引用信息抽取算法。由于互联网文本和法律条文并不属于 同一类型的文本,两者在篇幅、用词、表达规范方面具有显著的区别, 互联网文本中通常只有一小部分包含法律内容,而传统的文本匹配方 法中,根据词汇相似度判别的词袋模型(BOW)和未考虑词序的向量 空间模型(VSM)无法简单地应用于引用法条的抽取问题。近来,深度匹配模型取得较多进展,然而这类模型训练需要大量标注的文本数 据,而且由于一部法律往往有上百条法条,能够匹配成功的法条数绝 大部分在 1 至 2 条,正例与负例的比例相差太大,直接标注全部法条数据得到的训练集数据不均衡,文本和法条的匹配过于稀疏,难以直 接训练出有效匹配的模型。
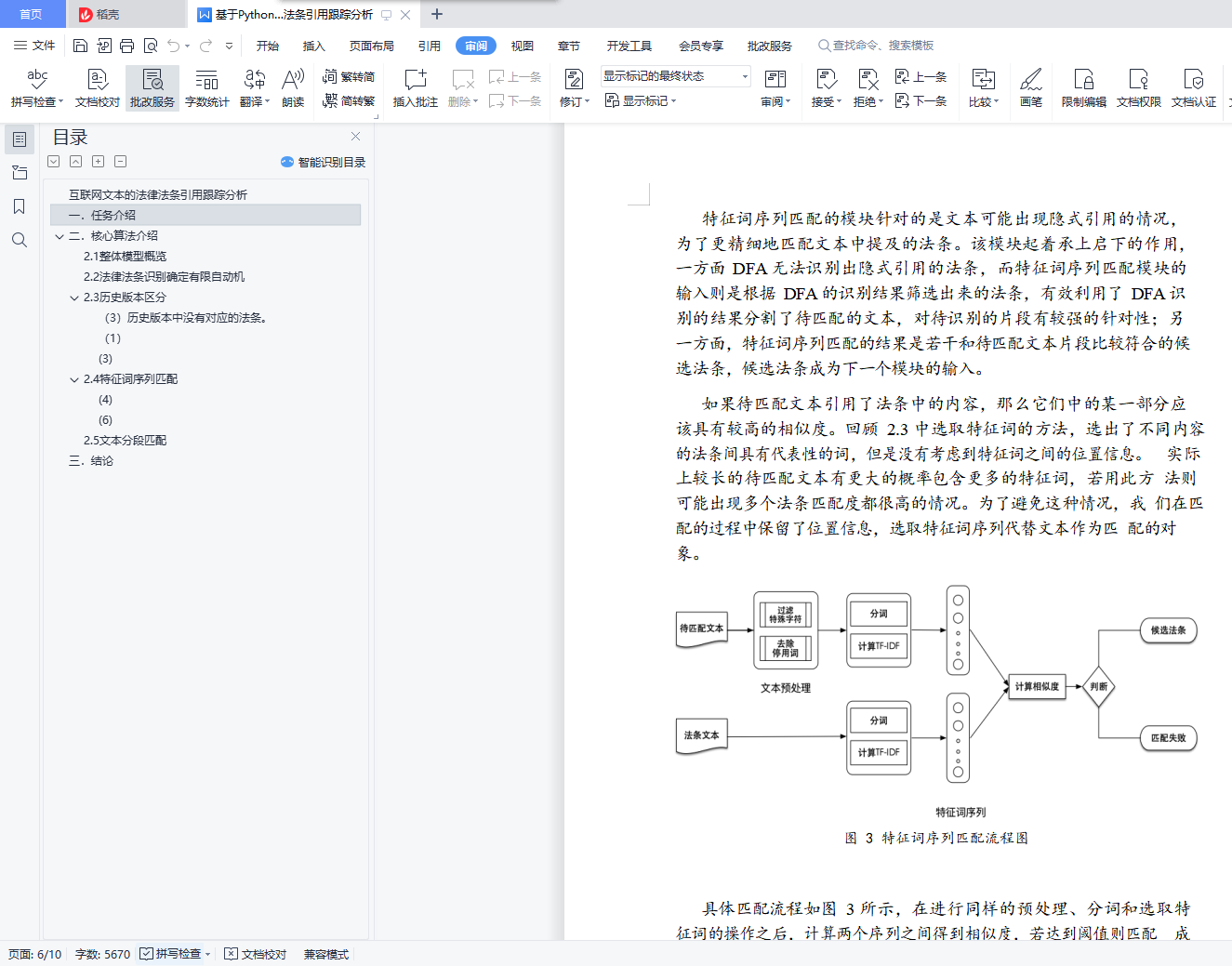
基于前述任务特点,我们提出了一种融合确定有限自动机(DFA)、特征词序列和深度匹配的混合层次抽取模型 DS-LSTM。首先使用DFA 从文本中进行初步匹配,通过法律名和法条号来初步筛选和过滤可能匹配的法条。对于已经抽取了法条号的文本,进一步通过比较各个历史版本的法条,做到精确分类;对于没有获取法条号的文本, 通过构建特征词序列来表示文本,计算序列之间的相似度来衡量文本和法条的匹配程度,据此给出候选的法条,再使用 MV-LSTM 模型计算文本与候选法条之间的语义相似度,根据语义相似度来判断法条与文本是否匹配。
本研究的主要贡献是根据法律法规文本匹配问题,提出了融合多 种抽取方法的混合层次抽取模型,而不是单纯使用深度模型或者 DFA 进行简单的匹配。虽然目前存在许多效果较好的深度匹配模型,但是 在文本的法律法条抽取任务中,待匹配的文本引用的法律法条数量不 同、表达方式不同造成需要大量各种类型训练数据的问题,以及待匹 配的法律法条数量众多,实际匹配数量只有一两条法条造成的数据倾 斜问题,直接使用深度文本匹配模型并不能实现高精度的抽取质量, 而引入 DFA 进行抽取可以很好地缩小可能匹配的法律以及法条范围。同时根据识别结果区分出多种不同类型的文本,可以有效地避免训练
数据倾斜的问题。使用 DFA 抽取出文本中可能包含的多部法律名以 及法条号,同时将文本按照法律以及法条出现的位置分割成文本片段, 避免了多部法律在匹配过程中相互影响的问题。我们的方法在法律以 及法条级别匹配结果的𝐹!分别达到 0.97 和 0.92。
混合层次抽取模型 DS-LSTM 的主要模块将在以下部分介绍。