目录
基于BERT的情感分析模型 1
一、 基于Transformer的词向量表示 1
各个词对 it 编码影响程度示意图 4
二、 数据收集及预处理 5
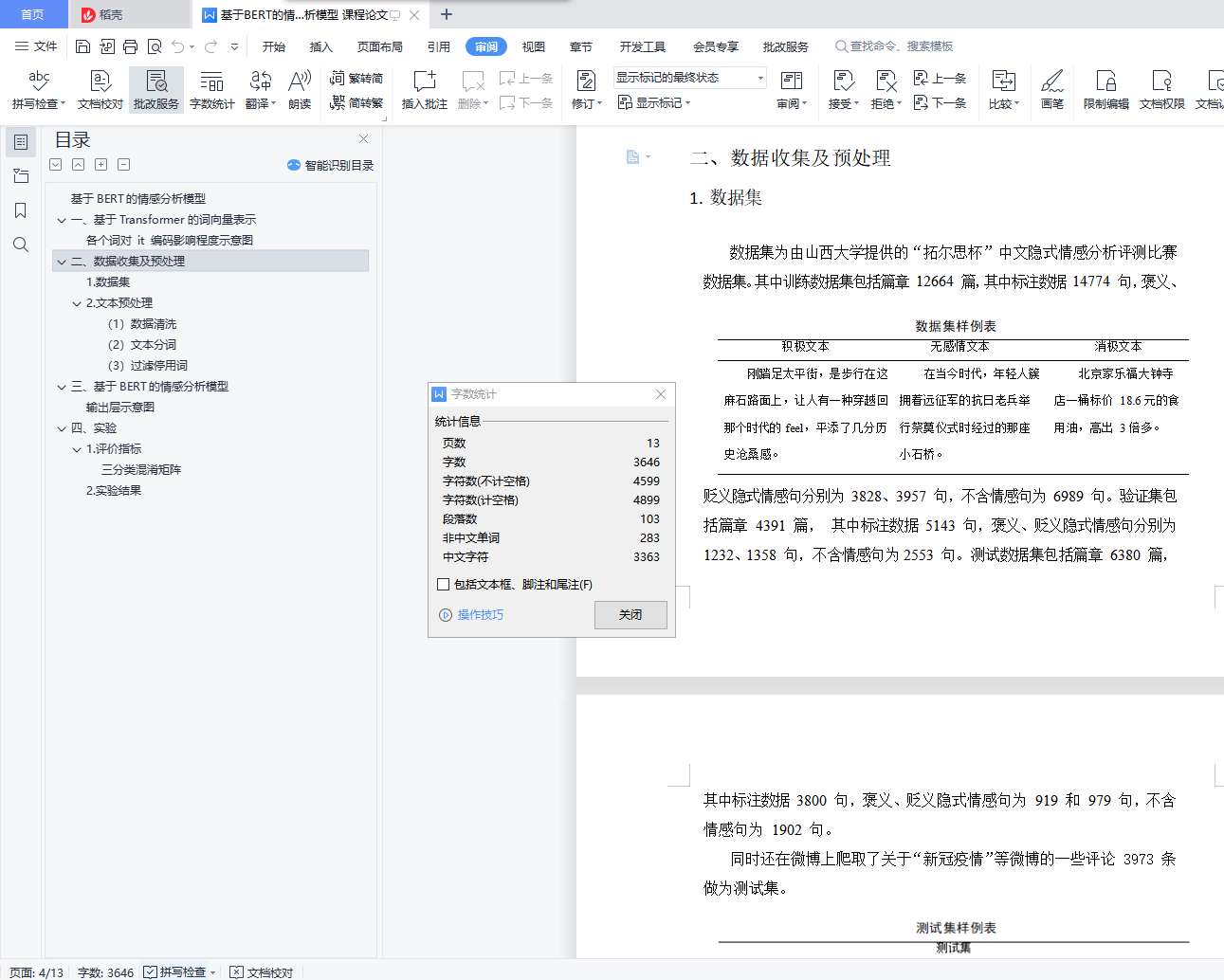
1. 数据集 5
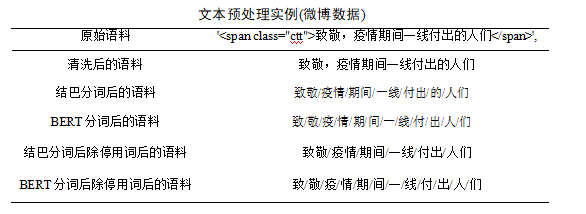
2.文本预处理 6
(1)数据清洗 6
(2)文本分词 7
(3)过滤停用词 7
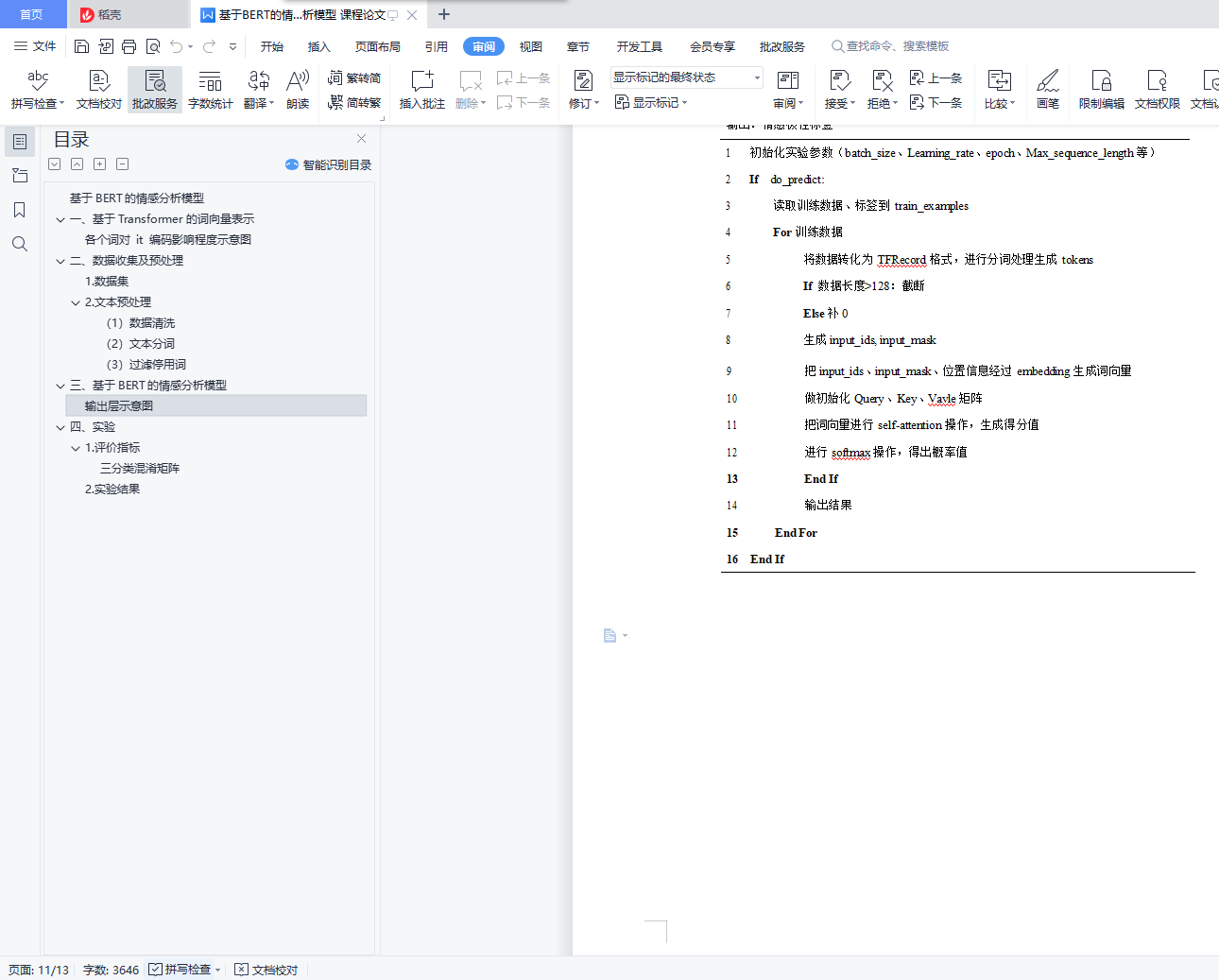
三、 基于BERT的情感分析模型 8
输出层示意图 12
四、 实验 14
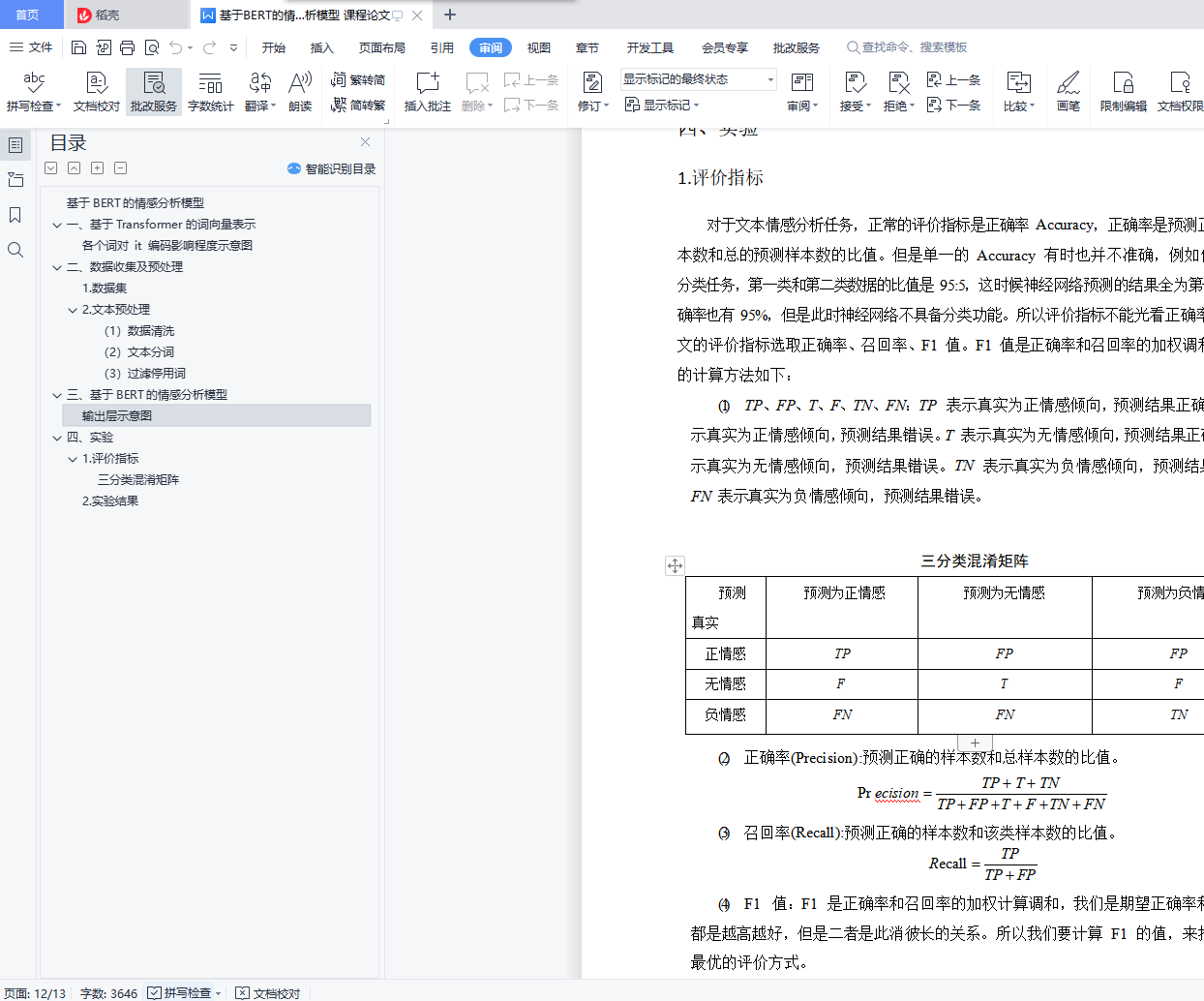
1.评价指标 14
三分类混淆矩阵 14
2.实验结果 16
基于BERT的情感分析模型
一、基于Transformer的词向量表示
Word2vec 由词义的分布式假设出发,每一个单词被映射到一个唯一的稠密向量。这显然无法处理一词多义的问题:自然语言中每个词都有可能有多个不同的意思,那么如果需要用数值表示它的意思,或至少不应该是固定的某一向量。例如:
例 2: ①The animal didn’t cross the street because it was too tired.
②The animal didn’t cross the street because it was too narrow.
通过这两个句子可以看出,其中的 it 分别指代 animal 和 street,对于我们而言很容易区分其中的区别,然而对于计算机而言却并不容易。使用传统的 Word2vec 产生的词表示是静态的,不考虑上下文的,如果对两个 it 进行向量化表示,得到的词向量是一样的,这显然是有瑕疵的。
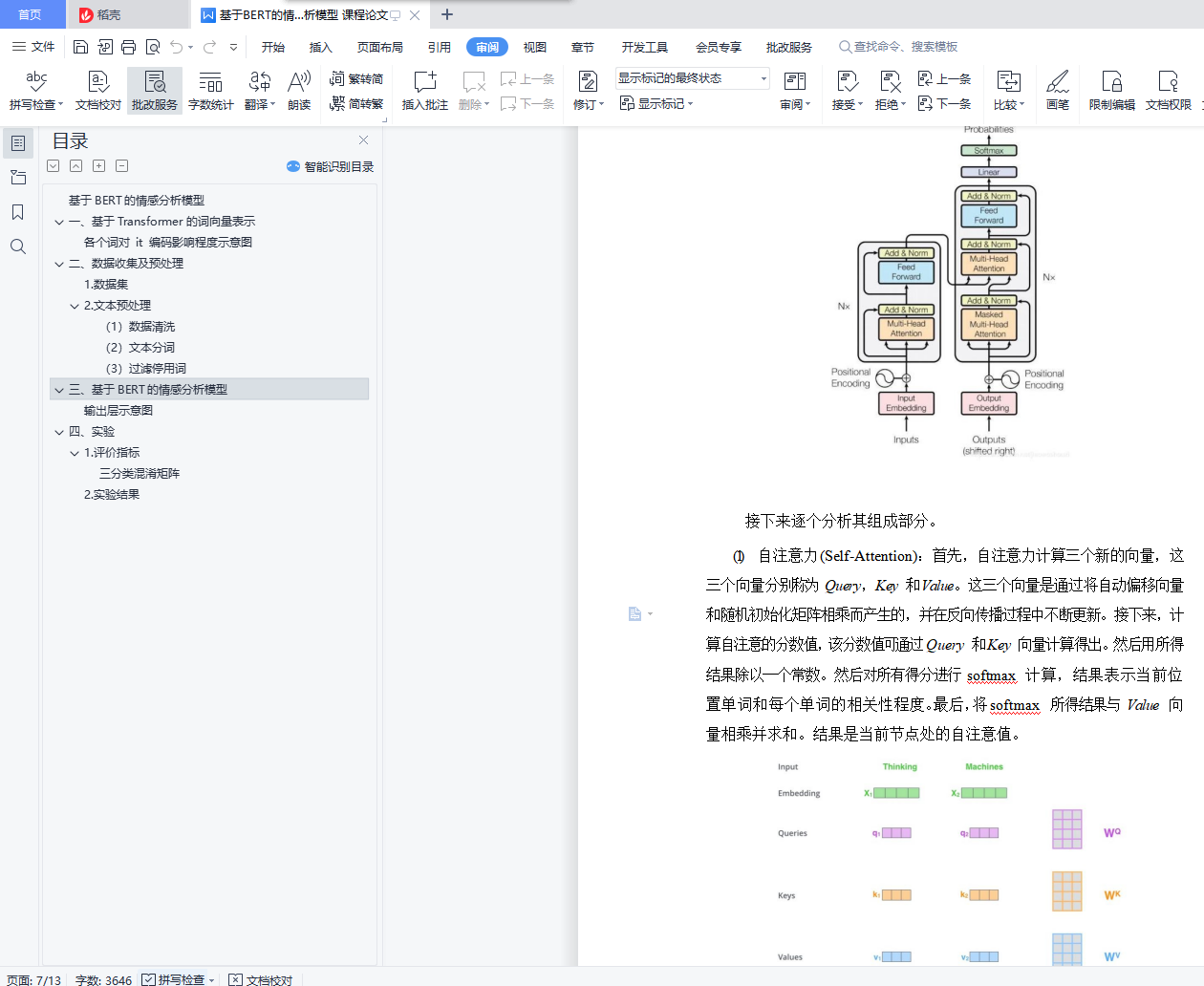
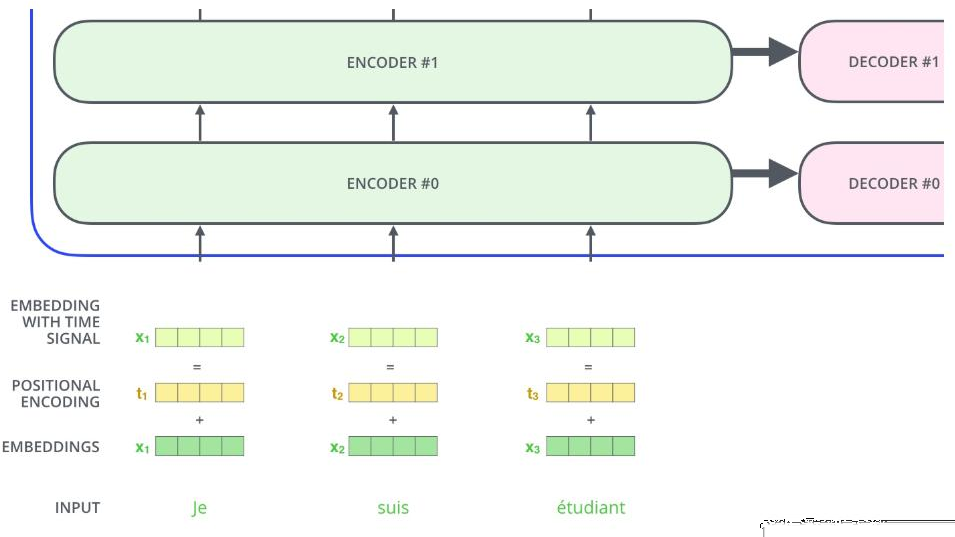
在介绍 Transformer 之前先来介绍一下注意力机制(Attention Mechanism),注意力机制最早被应用于图像研究领域。它源于对人类大脑工作原理的分析,其本质上是注意力资源分配的模型。例如,当我们看图片时,我们的注意力肯定会集中在某个部分, 随着眼睛的移动,注意力又转移到图片的另一个部分。任何时刻我们的注意力分布是不一样的。Google 公司在 2017 年,将注意力机制定义为查询作用于键值的过程。注意力机制有三个主要元素:输入、查询和注意力矩阵。三者相结合,产生“注意力权重”,根据产生的权重就可以区分不同语境对目标词的重要性。文本情感分析领域内的注意力机制主要被归纳为三个模型:文本注意力、特征- 文本注意力与自注意力。这里主要介绍自注意力(self-attention),self-attention 机制包含了不止一个特征,每个单词都依次与句子中所有的但那次相互作用。每一个单词都会通过这一系列的和计算得到一个其本身在该语境中的输出特征。所以 self-attention 的输出是多个单词的注意力特征的集合。