基于电商网络的数据采集与分析
摘要:随着人类社会以及互联网的迅速发展,越来越多的人投身到网购大军中,但如何有效地获取商品的数据,进行分析归纳总结,从而减少学习成本和金钱成本,已经成为了热门话题。本文提出了基于Python语言的淘宝数据爬取系统,从指定网站上抓取商品信息,经处理后以特定格式存储到数据库,再对数据进行分析,实现对影响商品数据的各种因素的可视化,以帮助人们高效地了解该做哪些产品,该如何去做。
本文基于Python语言在PyCharm开发平台设计了淘宝数据爬虫系统,对获得的数据分析总结并利用pandas/numpy/matplot库进行可视化。最后实现了对淘宝网站数据的实时爬取,通过柱状图与散点图总结数据特点,并构建了两者的线性回归方式,使内容更加清晰明了。
关键词:Python;网络爬虫;数据库;商品数据;数据分析;数据可视化;
Data acquisition and analysis based on e-commerce network
Abstract:With the rapid development of human society and the Internet, more and more people are engaged in online shopping. However, it has become a hot topic how to effectively obtain the data of commodities, analyze and summarize them, so as to reduce the cost of learning and money. This paper proposes a Python based taobao data crawling system, which captures commodity information from designated websites, stores it in a specific format to the database after processing, and then analyzes the data to realize the visualization of various factors affecting commodity data, so as to help people effectively understand which products to make and how to make them.
Based on Python language, this paper designed taobao data crawler system on PyCharm development platform, analyzed and summarized the obtained data and visualized the pandas,numpy and matplot libraries. Finally, it realizes the real-time crawling of the data on taobao website, summarizes the characteristics of the data through the bar chart and the scatter chart, and constructs the linear regression method of the two to make the content more clear.
KeyWords: Python; Web Crawler; Database; Commodity data; Data analysis; Data Visualization;
目录
第一章 前言 - 1 -
1.1课题背景 - 1 -
1.2设计目的 - 2 -
1.3设计方案 - 2 -
第二章 Python及其环境搭建 - 3 -
2.1 Python简介 - 3 -
2.2 Windows系统下安装Python 3.8 - 4 -
2.3 PyCharm集成开发环境 - 5 -
2.4 MongoDB数据库介绍 - 5 -
2.5 本章小结 - 5 -
第三章 淘宝产品数据爬虫 - 6 -
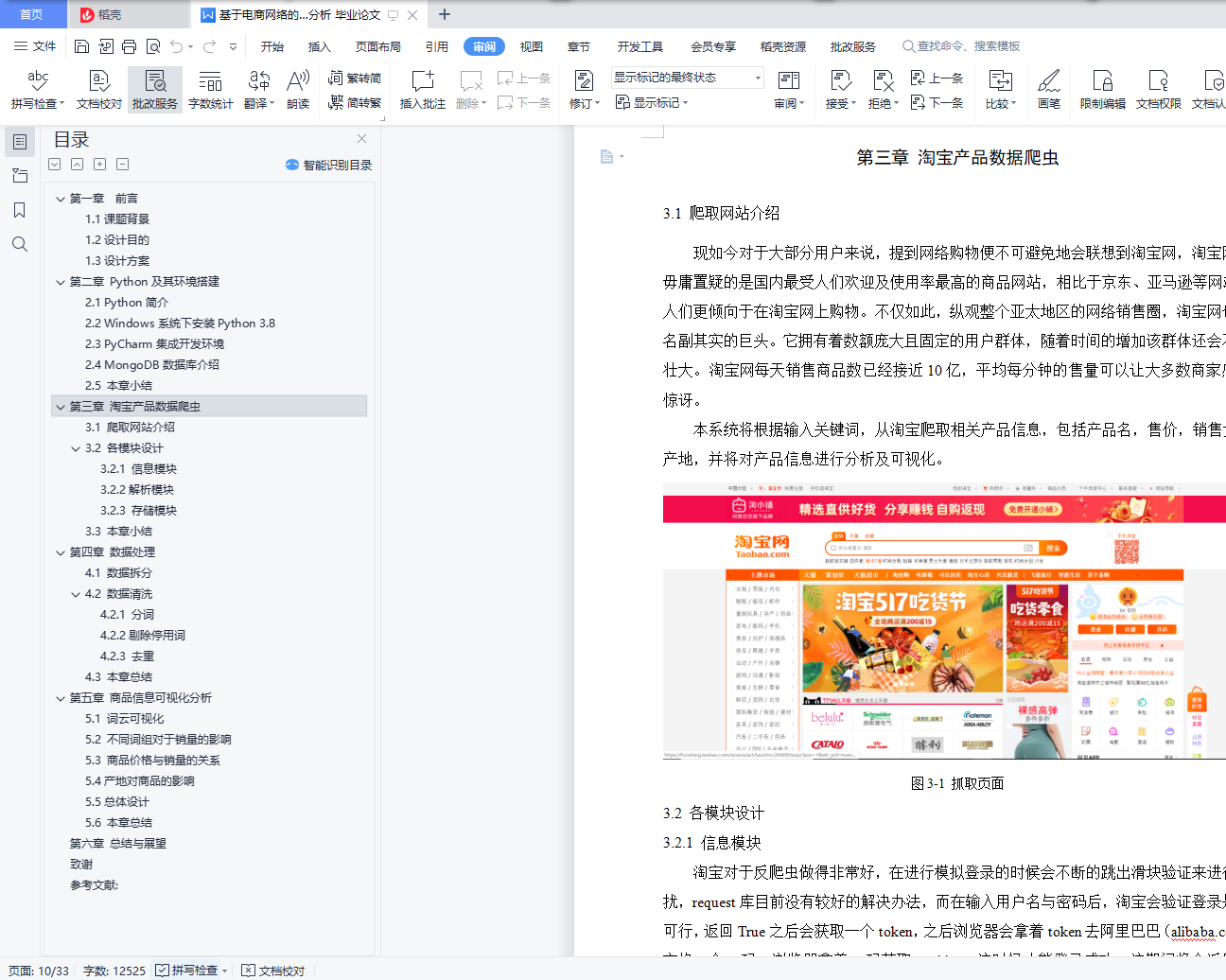
3.1 爬取网站介绍 - 6 -
3.2 各模块设计 - 6 -
3.2.1 信息模块 - 6 -
3.2.2解析模块 - 10 -
3.2.3 存储模块 - 12 -
3.3 本章小结 - 14 -
第四章 数据处理 - 15 -
4.1 数据拆分 - 15 -
4.2 数据清洗 - 16 -
4.2.1 分词 - 16 -
4.2.2剔除停用词 - 16 -
4.2.3 去重 - 17 -
4.3 本章总结 - 18 -
第五章 商品信息可视化分析 - 19 -
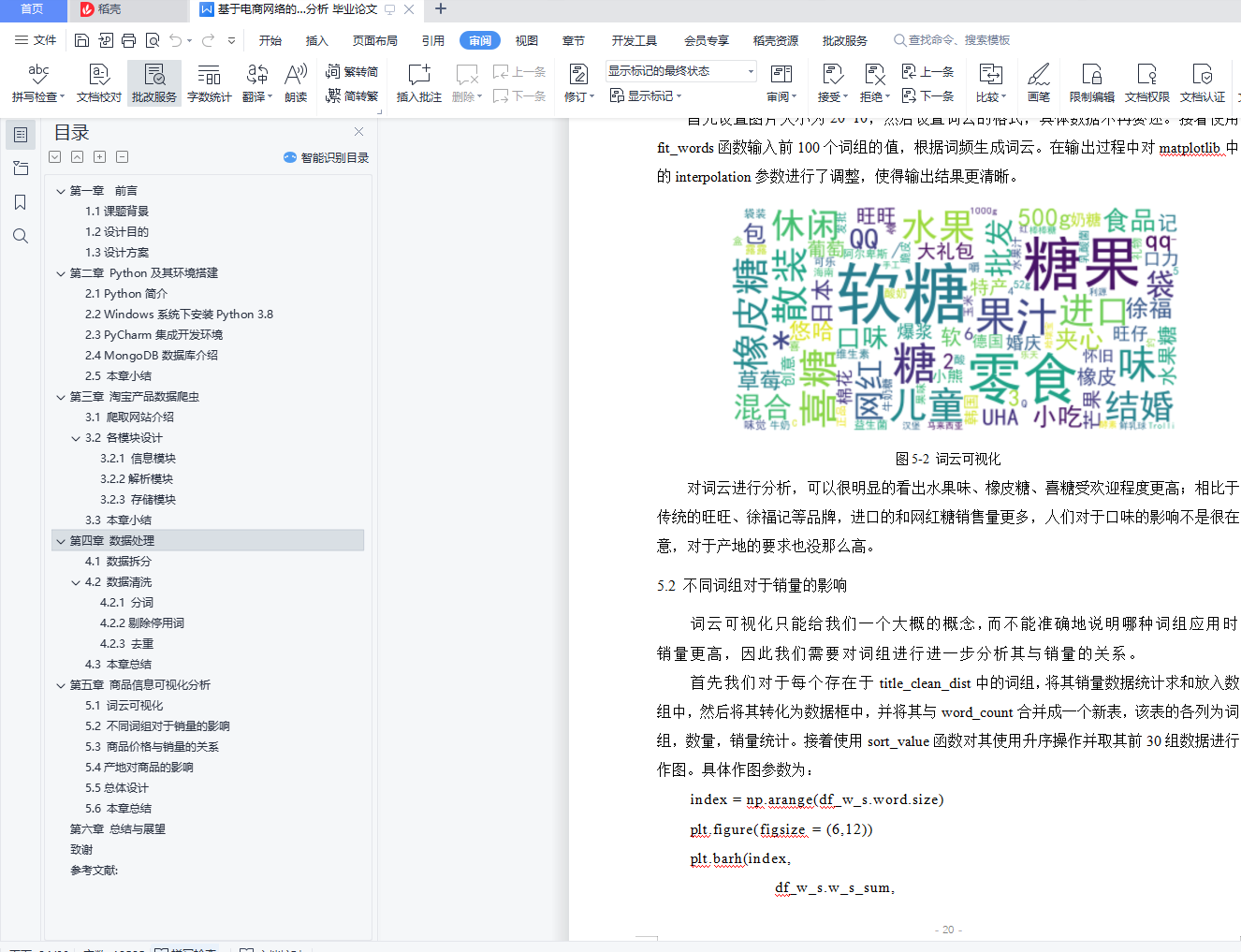
5.1 词云可视化 - 19 -
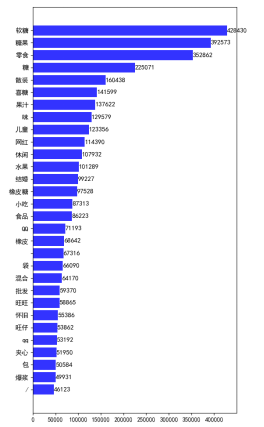
5.2 不同词组对于销量的影响 - 20 -
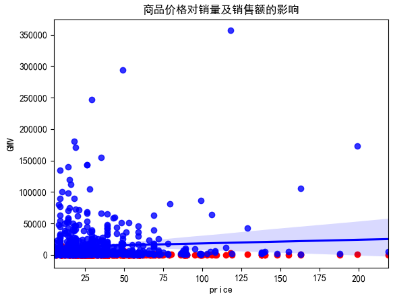
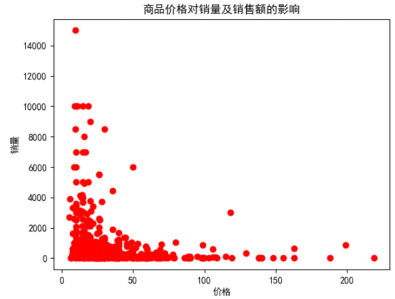
5.3 商品价格与销量的关系 - 21 -
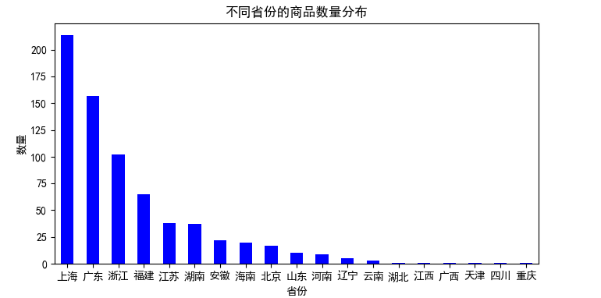
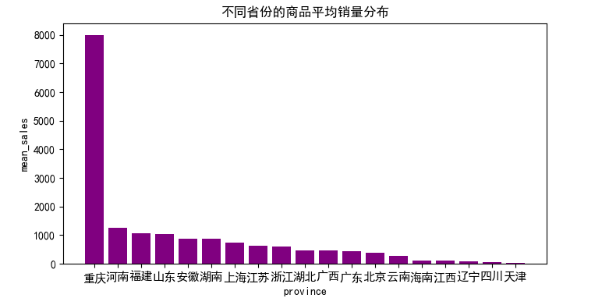
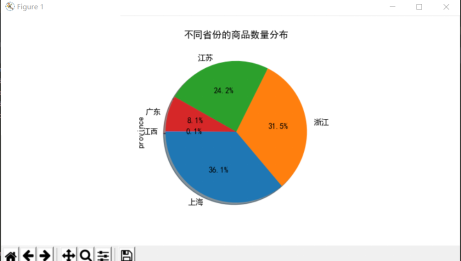
5.4产地对商品的影响 - 23 -
5.5总体设计 - 24 -
5.6 本章总结 - 25 -
第六章 总结与展望 - 26 -
致谢 - 27 -
参考文献: - 28 -
第一章 前言
1.1课题背景
信息是维持人类生存交流的根本,是人类在世界上无时无刻都在接触的因素。信息是丰富的,繁杂的,我们平时接触到的信息非常多,但是我们无法知晓我们获取了怎么样的信息,我们又传递了哪些信息,互联网给予了我们解决这个问题的可能[[[]]]。
现如今4G技术已基本普及在各大地区,应用但不仅限于生活、教育、科技等领域,可以说国内目前在世界上已经走到了互联网生活的前沿[[]]。不仅如此,在4G之外,5G技术也在蓬勃发展中,可以说在未来人们所接收到的信息会更加迅速、丰富和快捷,人们可以尽情地在互联网上使用各种搜索引擎去查找自己感兴趣的内容;可以在各大视频网站上去观看,浏览他人对其的评价;可以在购物网站上去购买自己喜爱但又出于种种原因无法在线下购买的物品等等,因此人们生活于一个互联网串通彼此,信息大爆炸的时代。
但是信息爆炸会带来一连串的问题,人们经常会在使用互联网的时候遇到这些问题并因此而感到困扰,其中最引人注目的便是:如果我想要批量获取信息,该如何去做[[]]。互联网会提供给人们各种各样的web页面,其中以文本、图像、音频和视频的形式存储的信息是最常见的,从像互联网这样的大型存储库中检索正确的图像是困难的。为了支持检索正确的信息,人们使用到了搜索引擎,最受欢迎的是谷歌,百度,Bing,Yahoo等。这些搜索引擎使用浏览整个互联网的web爬虫程序从相应的URL收集相关信息并将其存储在数据库中,网络爬虫增强了快速搜索终端用户的范围[[]]。
基于内容的图像检索系统是需要从大型数据集或互联网检索图像的领域之一。对该系统来说,正确的图像检索是一个重要的挑战。在网络爬虫中,程序可以递归地检索由这些链接在提供的URL下标识的所有web页面[[]];网络爬虫程序搜索也是基于一个关键字,关键字可以与作为文件名称或网页中文件的标题或描述中检索到的图像相关联。这些可以在爬虫下载的网页链接中找到。爬虫的设计必须包含一些社会责任,如道德,在爬行网站经常有网站警告机器人不要爬进它们,这样的服务器将在一个名为Robots .txt的文件中实现机器人排除协议(当人们使用部分爬虫框架时可以更改该文件)[[]]。因此爬虫需要尊重web上采用的爬虫规则标准所设定的协议,允许最小的爬虫伦理性,从而避免网络流量到这样的服务器。
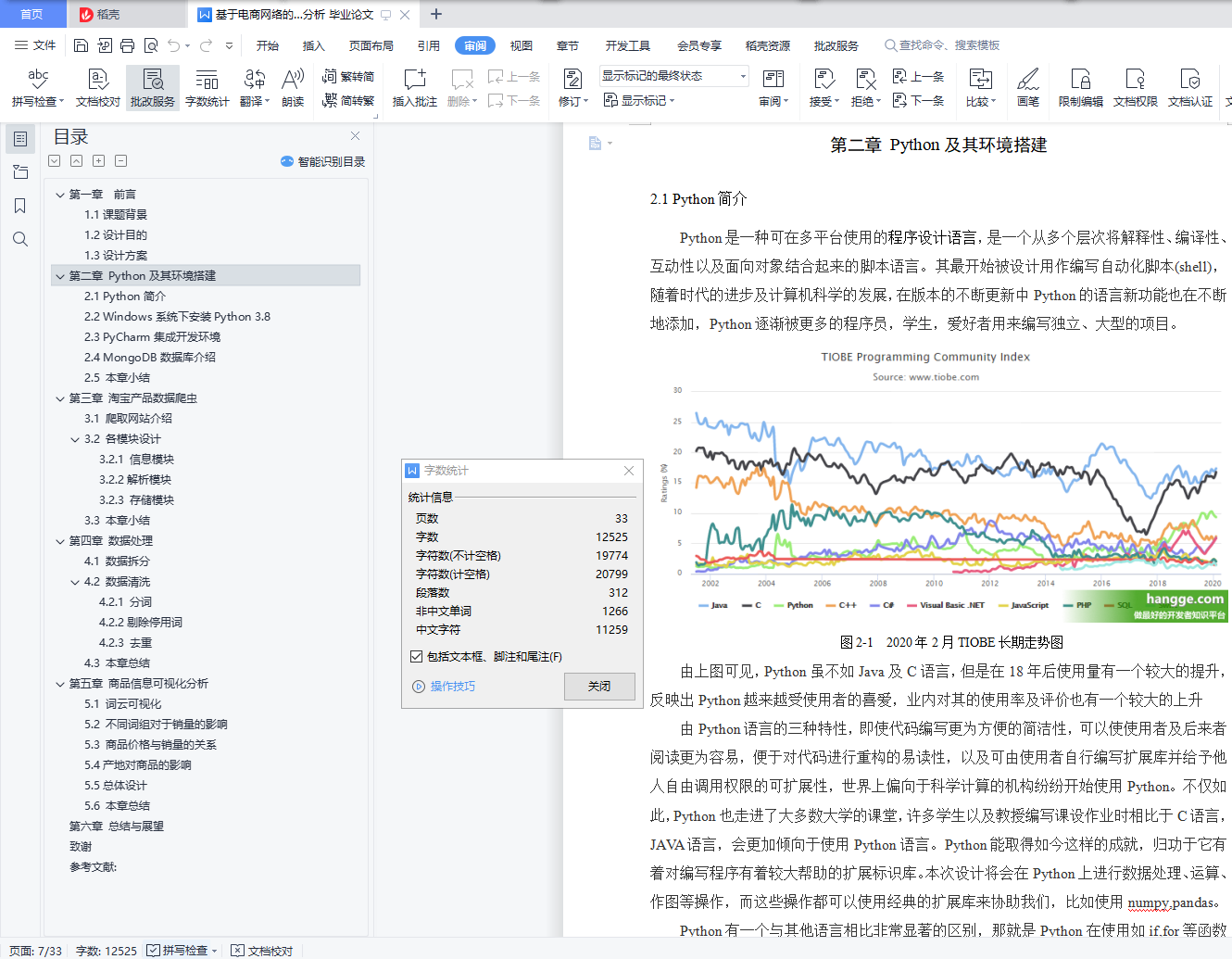
现如今大多数的网络爬虫都会使用Python语言来编写,这是因为相比与其他静态编程语言,如java,c#,C++,对于获取所爬取的网页的文档接口,Python更简单清晰[[]];相比其他动态脚本语言,在给予用户用于访问网页文档的API方面上,Python的urllib3包相比于perl,shell等动态脚本语言,有着更为显著的优势,比如提供的API就更加完整。
1.2设计目的
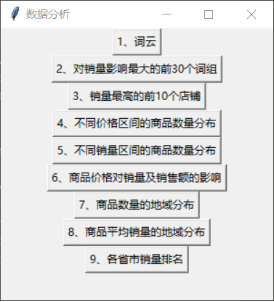
通过Python编写爬虫程序从淘宝网站上循环抓取产品的各项数据,并对数据进行存储与提取,然后用图表对其进行展示,直观了解产品价格,销量,产地等详细情况,并对这些数据进行分析与可视化。
1.3设计方案
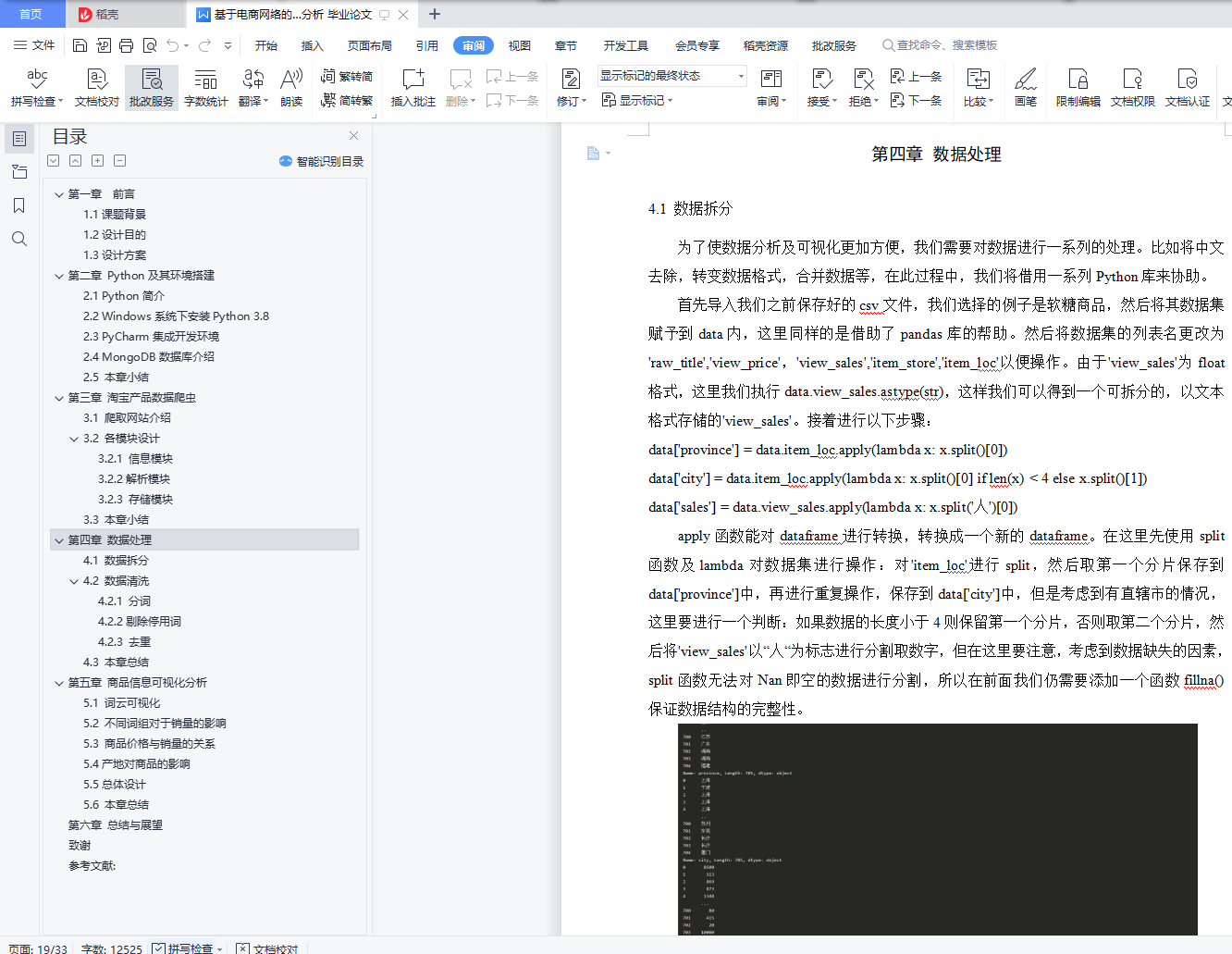
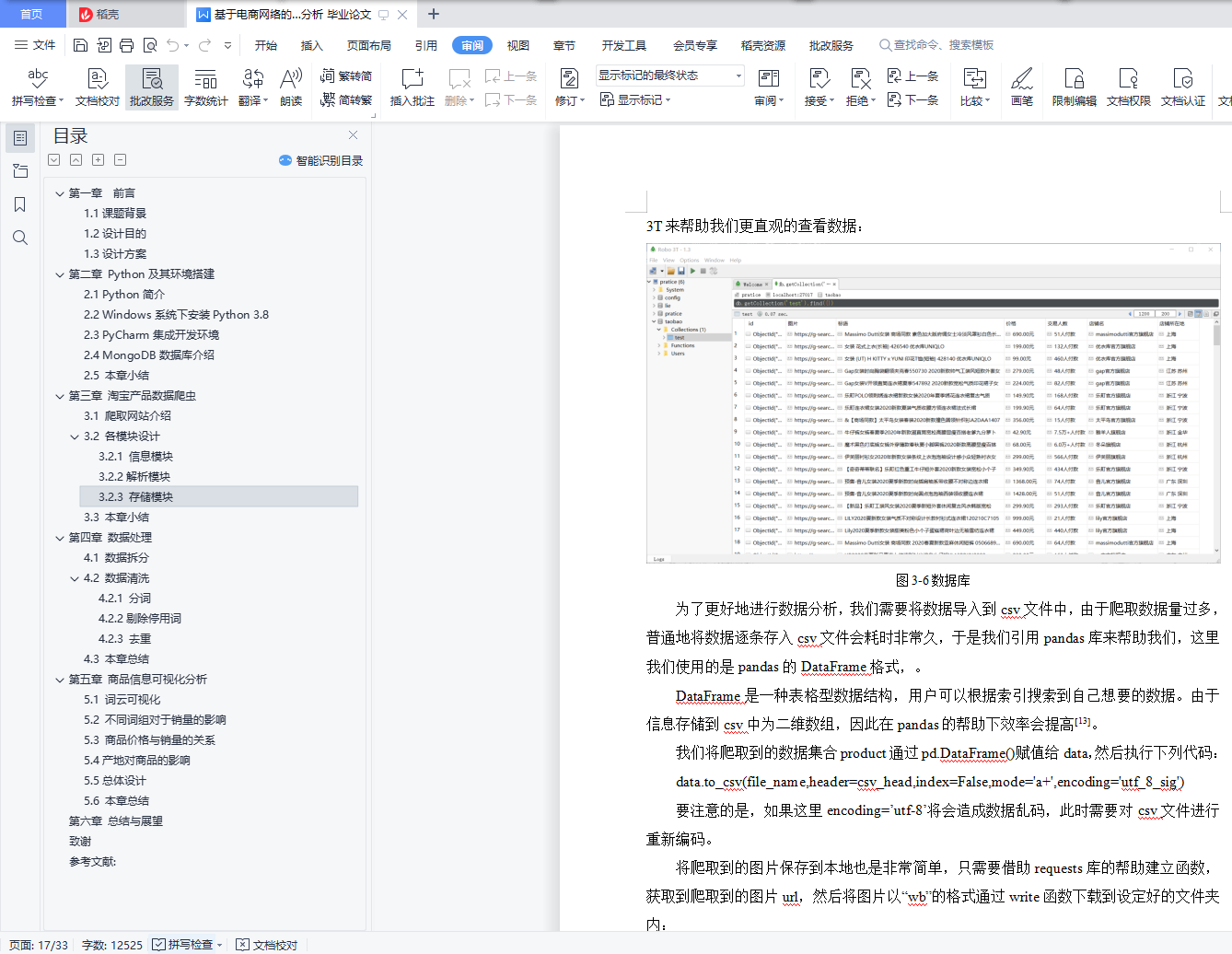
本论文将使用Python语言,在PyCharm开发环境中去编写爬虫程序,通过selenium启动代理浏览器,在搜索文本框中输入搜索关键字,从Web服务器调用Web爬虫模块,接着爬虫模块检查Internet连接,如果网络连接成功,就处理文本搜索引擎的关键字,然后将搜索引擎结果发送给解析器,直到所有链接都被处理。通过requests库来提交网络请求,爬取HTML页面,获得网页源码。通过正则表达式解析源码,即解析页面,然后提取相关数据。最后使用pymongo库连接MongoDB数据库和Python将爬取的数据存入该数据库。通过这几个步骤我们就能实现基本的爬虫功能并将数据保存。
爬取完成产品信息后,我们就能使用numpy、pandas、matplotlib三个库对数据进行填补缺失值,去重,清洗,分类等操作,然后进行数据分析,最后实现数据可视化。