目录
一、代码组织方式及执行顺序 3
二、问题描述 3
三、特征提取 4
(一)dat_risk 4
(二)dat_symbol 4
(三)dat_app 6
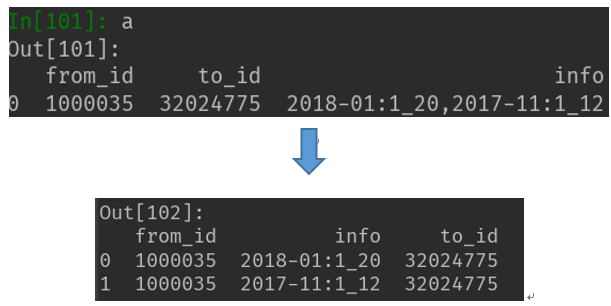
(四)dat_edge 7
四、用户关联图的特征提取 13
(一)中心度类特征 13
(二)Louvain 社区聚类 13
五、标签传播 14
(一)一度联系人 14
(二)二度联系人 15
(三)一度路由 17
六、特征传播 17
(一)特征概述 18
(二)数据描述 18
(三)特征提取 18
(四)特征评价 18
七、数据汇总及特征比较 18
八、特征排序与离散化 19
九、调参 19
十、测试集 AUC 下滑之谜 21
(一)用户 app 数据的缺失率差异 21
(二)用户关联数据的关联紧密程度 21
十一、改进空间 22
一、代码组织方式及执行顺序
二、问题描述
在这里说明是为了达成共识,同时也是为了统一符号表示,后面的讲解都以此为基础。 关于用户特征的数据分为四部分(按照处理的难易程度排序,从易到难):
•(1)dat_risk
•(2)dat_symbol
•(3)dat_app
•(4)dat_edge
关于用户标签和训练集、验证集、测试集的数据: (1)sample_train(两列: id、label) (2)valid_id(一列: id) (3)test_id(一列: id)
把 sample_train、valid_id、test_id 的 id 拼接起来,得到所有的 id,数据名称记为 all_id, 数据格式为一个 28959*1 的 DataFrame.
三、特征提取
(一)dat_risk
输出为 all_id_dat_risk
把 dat_risk 和 all_id 进行内连接:
all_id_dat_risk = pd.merge(all_id, dat_risk, on='id', how='inner')
目的是找出 all_id 中每一个 id 的特征,当然有些 id 可能没有这个特征,在最终的数据上表现为缺失值。