摘 要
随着当前信息时代的日益发展,数据量的逐渐增大,大规模图数据的处理在网页搜索应用,社交网络和交通网络等场景中作用也愈发明显。因此,大规模图着色的研究也开始成为高性能计算领域的热点。而通用GPU(Graphics Processing Unit)的发展使其作用逐渐广泛,用于图着色的加速也成了一种研究的趋势。但调研后,现有的较广泛的并行图着色均存在以下问题中的部分或全部:反复着色,在着色时,后续迭代轮次中顶点颜色会导致已着色顶点颜色出错,需要重新修改;并行度不够,每轮着色中,正确的着色顶点比例稀少;长尾问题,在着色最后,每轮着色顶点数大幅度减少;负载不均衡,每个线程运行时间开销相差过大,导致整体性能较差。
设计的新的基于并行架构的图着色算法,解决了反复着色,并行度不够以及长尾的问题。首先,预处理图数据,将其变成只有小编号顶点指向大编号顶点的有向图,避免了反复着色,也确保了算法能在有限轮次后终止。此外,配合使用CSR和CSC的存储格式保存图数据,可以做到一定程度的连续访存,并减少修正工作一半的工作量。其次,着色过程采用无冲突的并行着色思路,每一轮分为着色和修正两个步骤,提高了并行度,并可以避免原子操作。最后,在未着色顶点数剩余极少时,避免多次迭代,将着色策略变成串行,解决长尾问题。
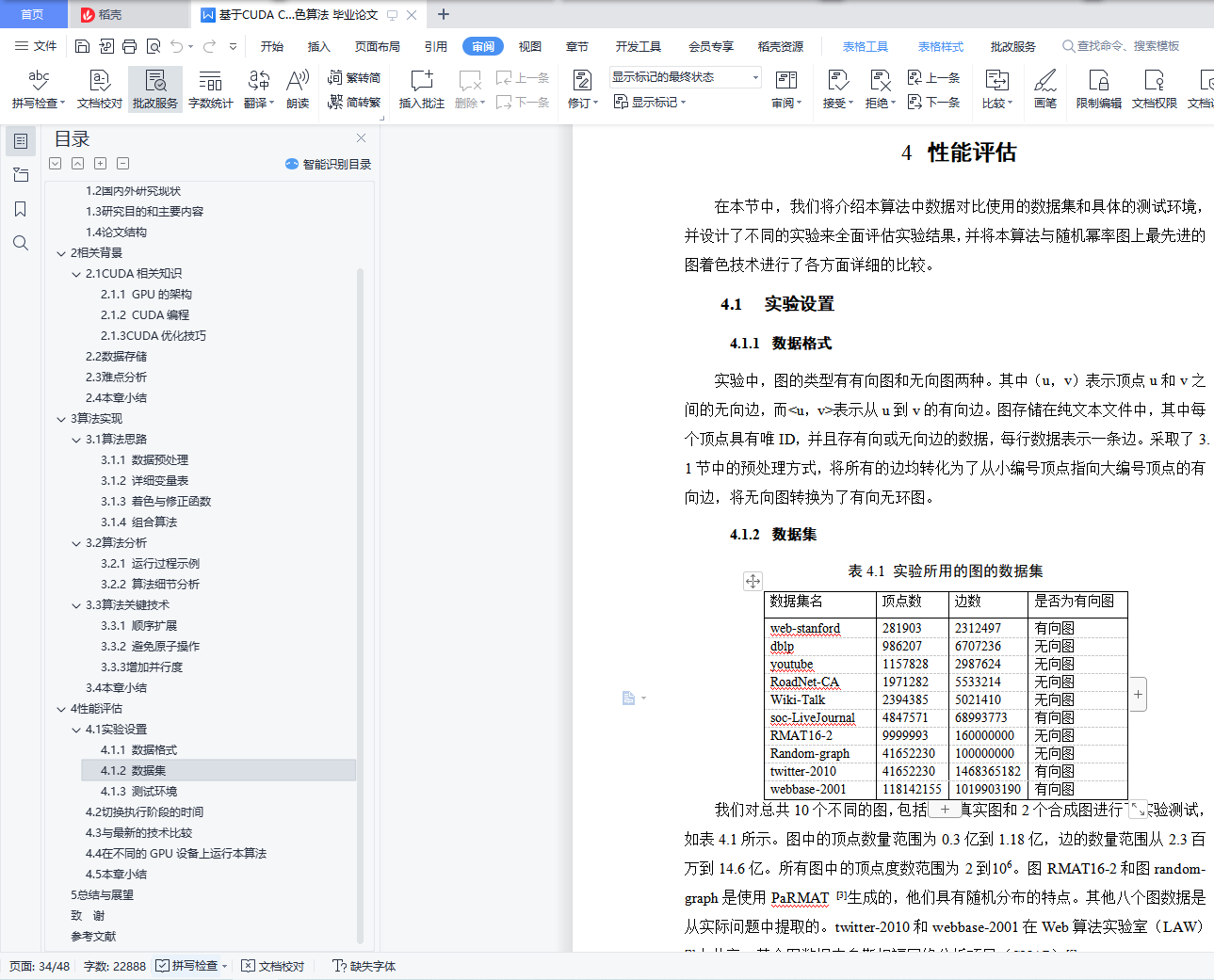
本算法使用CUDA C语言编程设计完成,提供了针对不同的图数据的接口参数。通过在相同环境下针对普遍的大规模图数据进行的实验,结果表明,该算法相较于CPU下的贪心着色算法有1.51-125.81倍的性能提升,相较于JPL(Jones-Plassman-Luby)有8.37-71.07倍的性能提升。
关键词:图着色;图形处理器;并行运算技术;两阶段
Abstract
With the increasing amount of data in the current information age, the processing of large-scale map data has become more and more obvious in the fields of web search applications, social networks and traffic networks. Therefore, the study of large-scale graph coloring has also become a hot spot in the field of high-performance computing. The development of general-purpose GPUs has gradually become more and more effective, and the acceleration for graph coloring has become a research trend. However, after the investigation, the existing parallel graph coloring has the following problems: repeated coloring. When coloring, the color of the vertex in the subsequent iteration round will cause the color of the shaded vertex to be wrong and needs to be re-modified; the degree of parallelism is not enough, in each round of coloring, The correct coloring vertex ratio is sparse; the long tail problem, at the end of the coloring, the number of colored vertices per round is greatly reduced; the load is unbalanced, and the running time overhead of each thread is too large, resulting in poor overall performance.
The parallel graph coloring algorithm designed solves the problem of repeated coloring, insufficient parallelism and long tail. First, the map data is preprocessed, turning it into a directed graph with only small numbered vertices pointing to the large numbered vertices, avoiding repeated coloring and ensuring that the algorithm can terminate after a finite number of rounds. In addition, in conjunction with the use of CSR and CSC amount storage format to save map data, a certain degree of continuous memory access can be achieved, and the workload of partial correction can be reduced. Secondly, the coloring process adopts a collision-free parallel coloring idea. Each round is divided into two steps of coloring and correction, which improves the degree of parallelism and avoids atomic operations. Finally, when the number of vertices remains very small, the coloring strategy is changed to serial to solve the long tail problem.
The algorithm is designed using CUDA C language programming and provides interface parameters for different graph data. Experiments on general large-scale graph data in the same environment show that the algorithm has a performance improvement of 1.51-125.81 times compared with the greedy coloring algorithm, and has a performance improvement of 8.37-71.07 times compared with JPL.
Keywords:Graph Coloring, GPU,CUDA,Two stages
目 录
摘 要 I
Abstract II
1 绪 论 1
1.1 课题背景 1
1.2 国内外研究现状 1
1.3 研究目的和主要内容 4
1.4 论文结构 6
2 相关背景 7
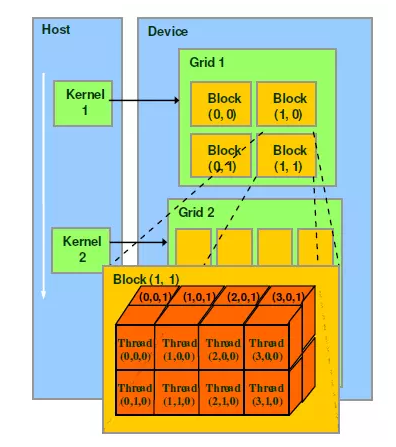
2.1 CUDA相关知识 7
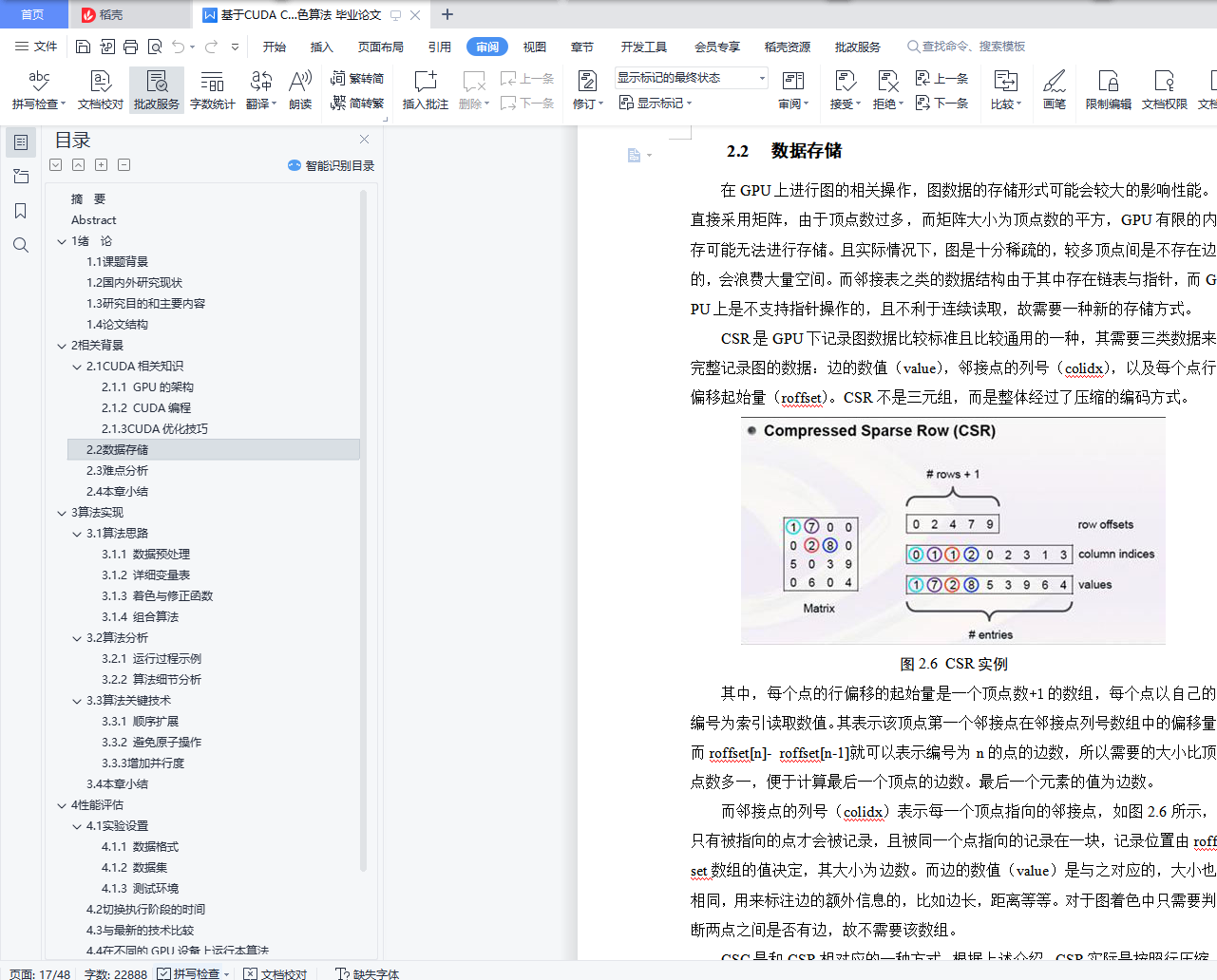
2.2 数据存储 13
2.3 难点分析 14
2.4 本章小结 16
3 算法实现 17
3.1 算法思路 17
3.2 算法分析 22
3.3 算法关键技术 24
3.4 本章小结 29
4 性能评估 30
4.1 实验设置 30
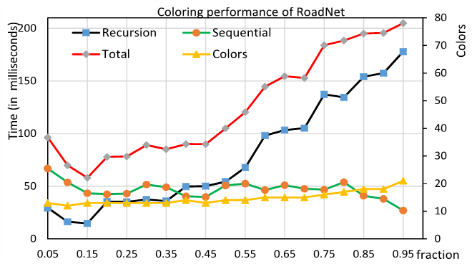
4.2 切换执行阶段的时间 31
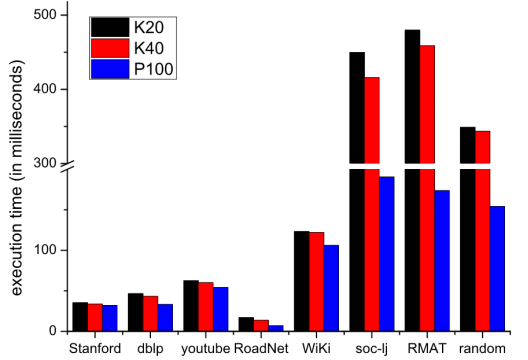
4.3 与最新的技术比较 34
4.4 在不同的GPU设备上运行本算法 35
4.5 本章小结 36
5 总结与展望 37
致 谢 39
参考文献 40