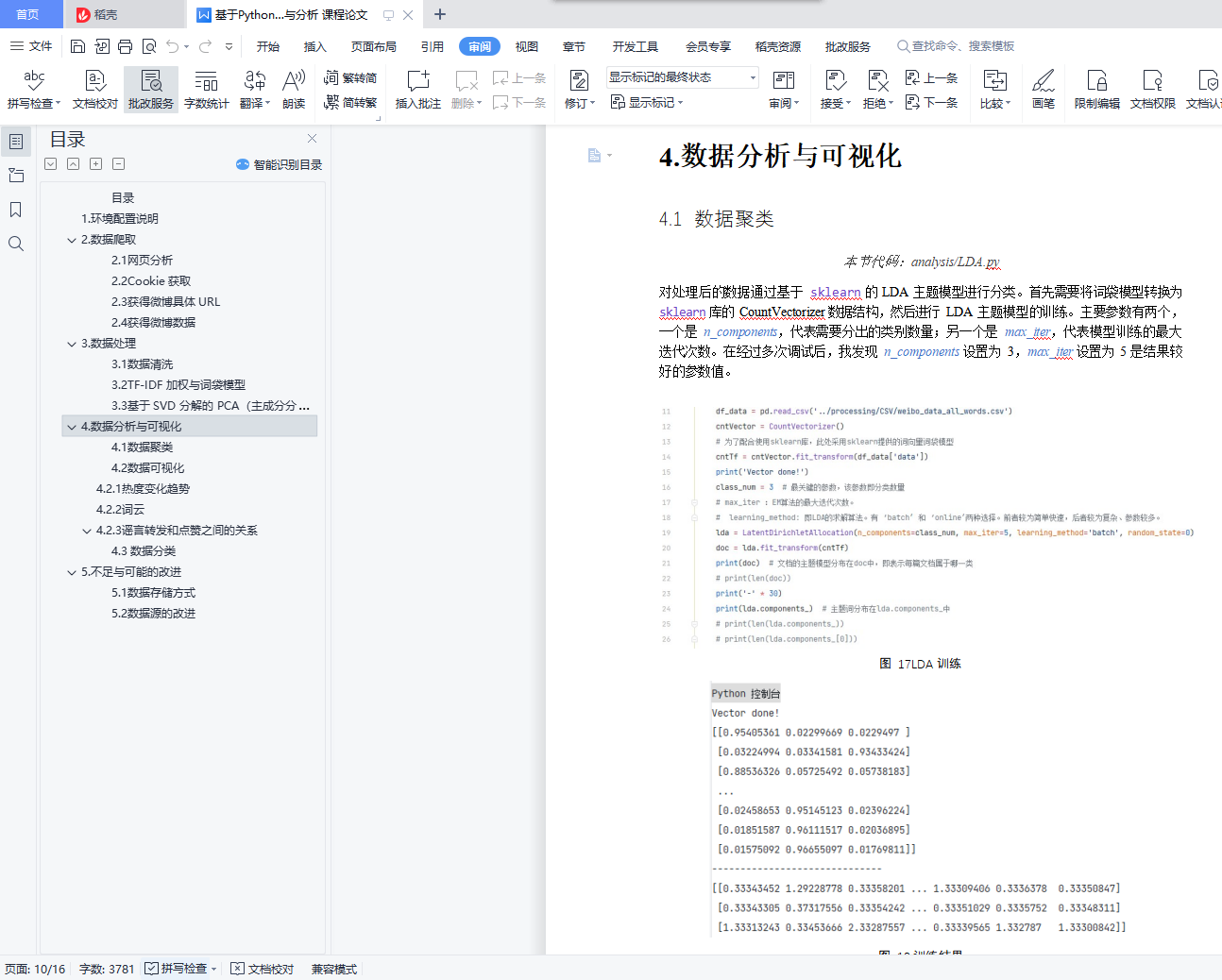
1.环境配置说明
• Python 解释器版本:Python 3.9 Anaconda
• 操作系统:Windows 10
• IDE:PyCharm 2021.3 (Professional Edition)
• 第 三 方 Python Packages: selenium, BeautifulSoup(bs4), pandas, jieba, numpy, sklearn, matplotlib, wordcloud
Python 额外程序包可以使用 pip/conda install 在 IDE 终端直接安装。或者也可以使用
PyCharm 的包安装程序(见图 1)。
图 1PyCharm 的包安装程序
注:本项目数据处理的最终结果是文件 analysis/CSV/weibo_data_classified.csv
2.数据爬取
2.1 网页分析
微博的所有网页均采用了 js 动态渲染技术,即使采用正确的 Cookie,利用 requests 等处理静态网页的库爬取网页仅能得到一大串无法使用的 Java Script 脚本。因此我最终决定采用selenium 库,配合 BeautifulSoup,利用浏览器驱动模拟真实浏览器获得 Cookie、发出请求。
2.2 Cookie 获取
本节代码:spider/GetCookie.py
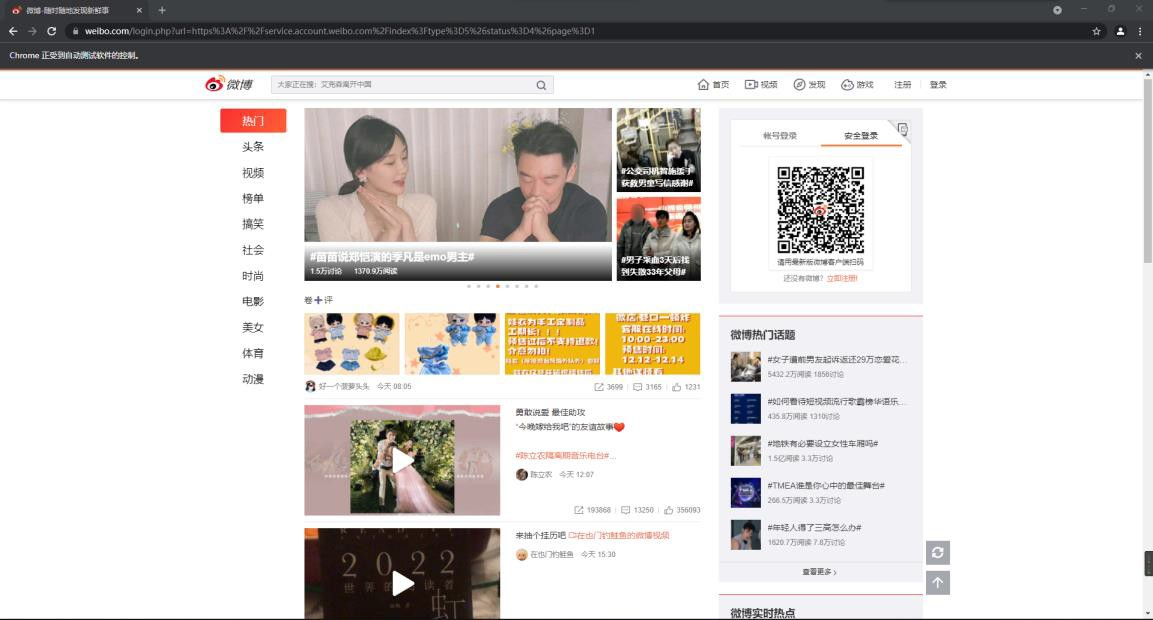
通过多次尝试,我发现,微博网页的 Cookie 获取无论是通过账号密码或是邮箱方式,最后都必须通过手机短信或者手机扫码才能成功,即完全自动化的 Cookie 获取是比较困难的。因此我利用 selenium 来自动跳转至扫码界面(图 2):