基于Python实现的GMM算法的语音数字识别
目录
1 任务描述 1
2 实验环境 1
3 实验方案 1
3.1 MFCC 特征提取 1
3.2 GMM 分类 2
3.3 GMM 实现 3
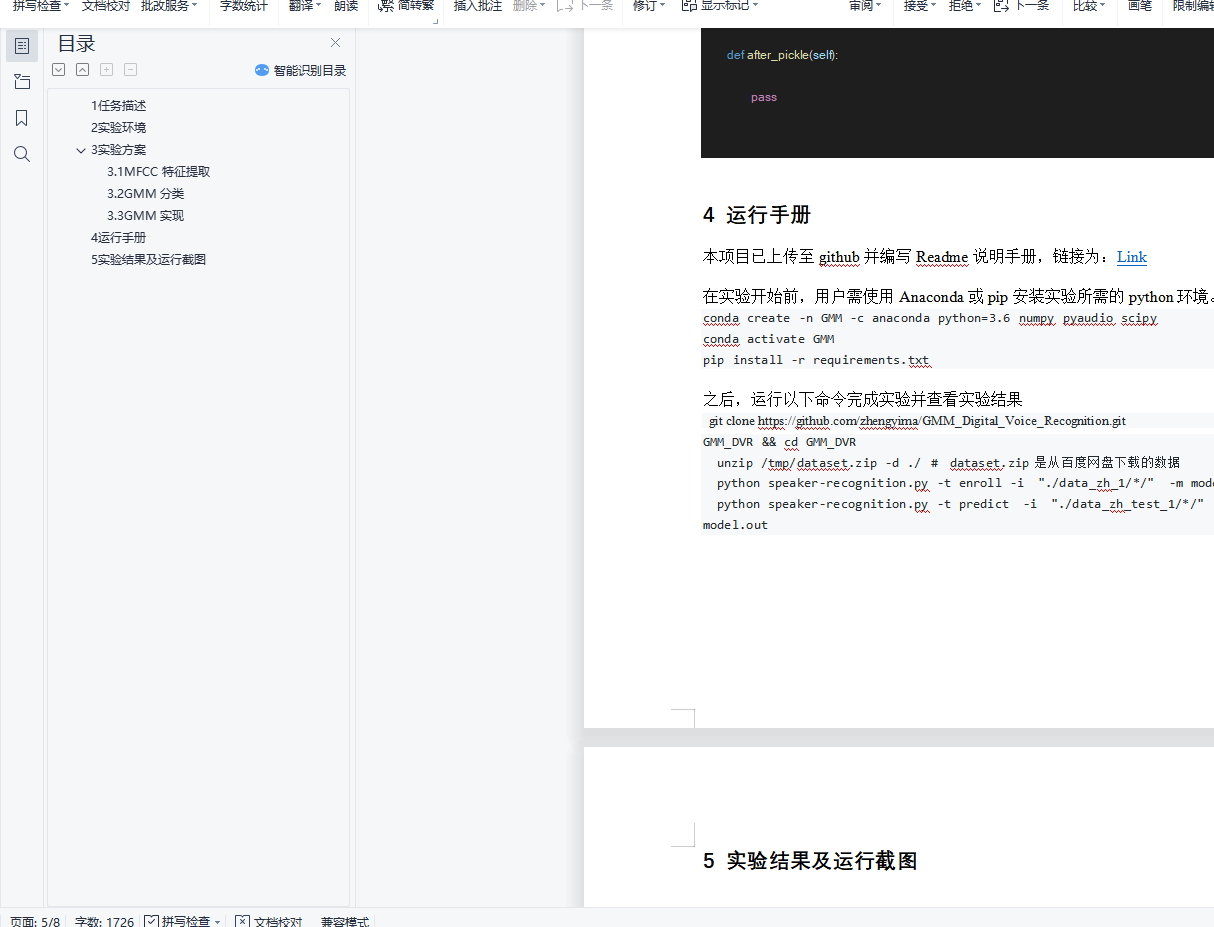
4 运行手册 5
5 实验结果及运行截图 6
1任务描述
基于数字语音数据集,编写代码,使用 GMM 算法完成语音识别,对输入的一段音频进行分类,输出语音中的数字,如“2”、“10”。
2实验环境
操作系统使用 MacOS,Python=3.6,python-speech-features=0.6,pyaudio, scikit-learn=0.18.1。
3实验方案
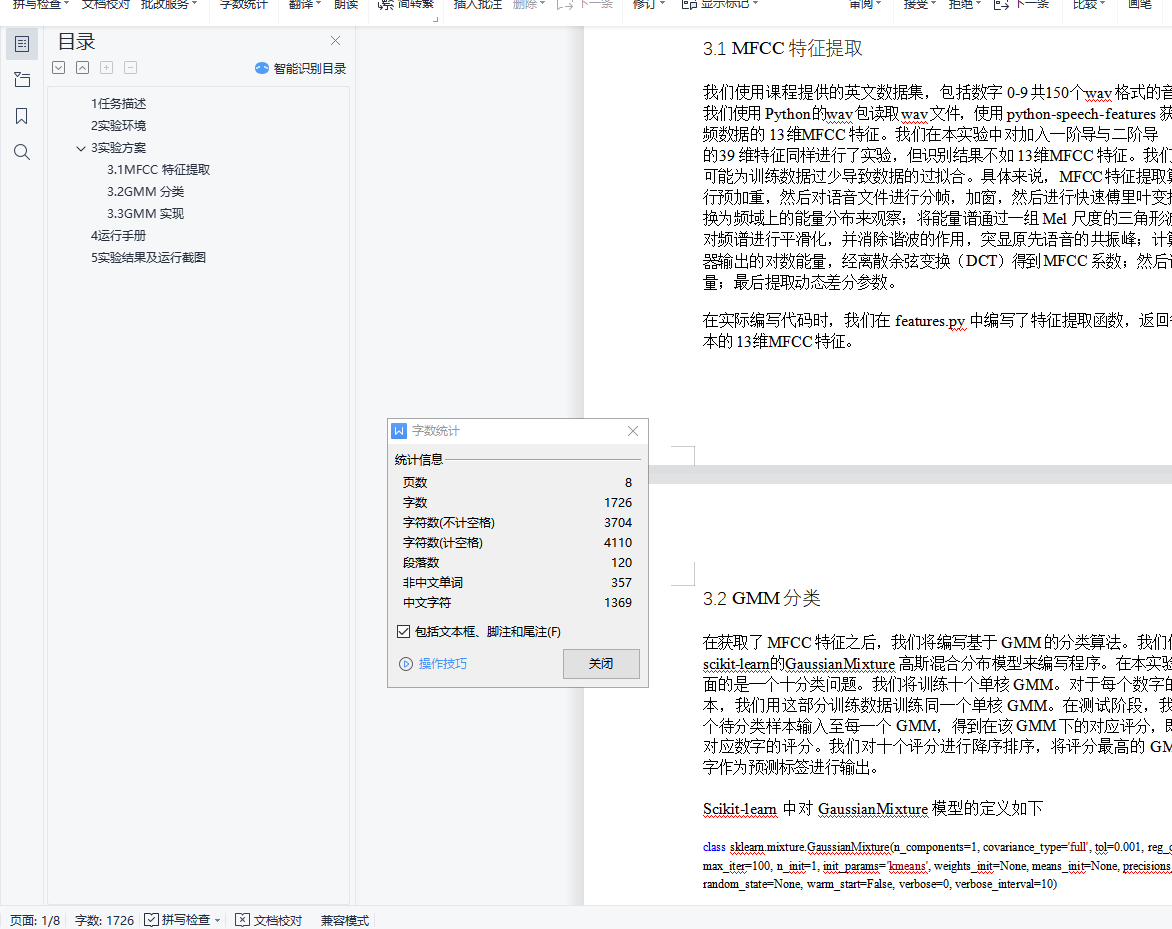
3.1MFCC 特征提取
我们使用课程提供的英文数据集,包括数字 0-9 共 150 个 wav 格式的音频文件。我们使用 Python 的 wav 包读取 wav 文件,使用 python-speech-features 获得每条音频数据的 13 维 MFCC 特征。我们在本实验中对加入一阶导与二阶导
的 39 维特征同样进行了实验,但识别结果不如 13 维 MFCC 特征。我们分析原因很可能为训练数据过少导致数据的过拟合。具体来说,MFCC 特征提取算法首先进行预加重,然后对语音文件进行分帧,加窗,然后进行快速傅里叶变换,将它转换为频域上的能量分布来观察;将能量谱通过一组 Mel 尺度的三角形滤波器组,对频谱进行平滑化,并消除谐波的作用,突显原先语音的共振峰;计算每个滤波器输出的对数能量,经离散余弦变换(DCT)得到 MFCC 系数;然后计算对数能量;最后提取动态差分参数。