摘要
随着医疗卫生事业的发展,以及治疗技术的进步,在社会上有更多的健康需求。对医疗保险基金支出的绝对值的快速增长已经提上了国家卫生保健系统的压力,很多。然而,医疗保险基金是卫生保健系统的直接键。基金支出的增加可能会导致一个相对资金不足和施加压力的可持续健康发展。为了应对这些问题,本文分析了医疗保险的医疗保险基金支出指标的影响,并预测了基于时间序列预测的方法,医保基金的每月开支,基于大连市近5年医疗保险基金的历史数据,为了准备政策调整和预警。最后,它表明,医保基金结余存在不同的医疗指标组之间存在显著的平均差异。预测误差为6.72%,满足实际需求。
随着基于关系结构的传统数据库技术广泛地应用于信息化时代的各个领域,各种复杂的数据库系统纷纷被建立,由计算机代替了手工操作,极大提高了人们的工作效率。随着关系数据库和各类信息系统应用的年深日久,在数据库系统中积累了大量的业务数据,并且由于业务应用的深入数据量还在日益增加。当前社会的市场竞争日趋激烈,使得医疗行业对于数据库的要求不仅仅停留于数据处理层面,而逐渐向数据的深层次分析与利用的方向转变。但如果没有强大的数据分析工具对现有数据库中的数据进行挖掘分析,而单凭目前数据库的分析查询功能以及各业务系统的的能力,是无法发现并提取这些海量数据中所蕴含的知识与规律的。因此为了满足日益增长的对数据进行深层次利用的需要,数据挖掘与数据仓库技术应运而生,它们能够对现有的海量数据进行深层次的知识提取和经验总结,并获取对管理决策有用的信息。目前这些技术广泛的运用于金融业(如银行、保险)、零售业(超级市场)以及电信业等商业领域,但是在医疗卫生领域还处予摸索阶段,对此我们进行了大胆的尝试,对这一领域进行研究,在医院医保费用分析中采用了数据挖掘技术来产生对医保费用管理工作有意义的规则集。
关键词:医疗保险基金支出,医保基金结余,方差分析,时间序列预测。
1 引言
随着中国经济的快速增长,中国健康保险事业取得了巨大的成就。在2010年,城镇职工基本医疗保险制度已普遍成立了全国2370万人参保。2011年,随着新型农村合作医疗制度的建立,在合作医疗的832002万人,占整个农业人口97.5%[1,2]。在2012,中国基本医疗保险已覆盖超过95%的人口,这意味着中国已初步建成了世界上最大的医疗保健网络。
随着一些优惠的医疗保险政策的出台,医疗保险基金支出增加。2010年,城镇职工基本医疗保险的一般基金支出达到32716亿元,与2008年相比增加57%。同时,新型农村合作医疗的一般基金支出达到11878亿元,与2008年相比增加79.4%。然而,在2010的国内生产总值增长仅为2008年的21.1%,这意味着医疗费用的增长速度远远超过了GDP的增长。医疗费用的快速增长已成为中国在医疗服务领域的一个重要问题[3,4]。
近年来,医疗保险基金平衡问题逐渐出现在各个地区,个别地区入不敷出。以城镇职工基本医疗保险基金为例,医保基金股票增长率逐年下降,从2005开始,从91%下降到10.9%,2010,甚至负增长发生在一些地区[5,6]。它带来的医疗保险系统,财务根据工资总额的一定比例很大的风险。因此,基金支出的预测是维护基金收益相对不变的前提下的医疗保险制度的重要举措。
为了保证医疗保险制度的顺利运行,有必要对医保基金的股票和支出趋势的影响因素,预测医疗保险基金支出和医疗保险政策的调整。这已经引起了国内外学者的关注。在国际上,医保基金支出的研究已成为一个热门话题。例如,在1992和gerdtham纽豪斯,奥康在1996和getzen 2000分析数据用时间序列方法确保支出总额的趋势不同的国家[7]。同时,在2000年时,为了分析医疗指标的影响,乔治和Karatzas 利用从1962至今美国的医保基金支出数据用时间序列方法进行分析[8]。
2 改变医疗保险基金平衡不同医疗分析指标
医疗保险的指标,也被称为平均支付标准,是费用,医疗保险基金管理机构支付治疗一个病人的医疗机构。确切的数额是由于不同地区、不同年不同,但一般逐渐增加。如表1和图1所示,它显示了医疗保险基金平衡不同医疗指标从2008到2010的变化。
在分析医疗保险基金平衡医疗指标基于方差分析的方法[9],通过SPSS不同的差异,这表明,医保基金结余存在4760和5610组之间的平均差异显著,与相对较低的医疗保险基金平衡指标相对较高。这种现象也发生在4760组6060之间。
事实上,医保指标的调整是医疗保险基金有轻微的剩余的前提下提高医疗机构支付标准。它的目的是减少医疗机构的工作压力。但在实践中,提高医疗机构的诊断标准,旨在提高医疗收入。同时,医疗机构扩大经营面积,增加开放床位与住院的病人,受利益。所有这些行为将导致医疗保险基金支出的增加。
表1.2008到2011年医疗保险基金平衡不同医疗指标数据
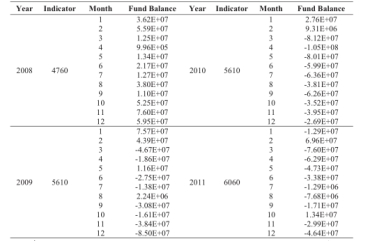
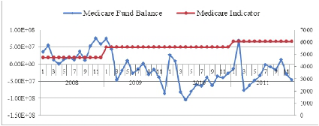
图1.2008到2011年的医疗保险基金平衡不同医疗指标趋势
3 医疗保险基金支出的时间序列预测
随着医疗技术的进步,人们的社会医疗保险和优惠政策的影响的认识的变化,社会医疗保险基金支出增加。收入和支出的医疗基金失衡。以大连为例,如图2所示,近年来医疗保险基金平衡显著下降(假设医保基金的平衡是零前2008)。因此有必要对医疗保险基金支出的预测基于历史数据的预警。

图2. 2008到2011年的医疗保险基金收支平衡的趋势
时间序列预测和因果预测广泛用于描述变量随时间的变化规律。不同的是,时间序列预测是基于目标变量与时间不同历史的大量数据,和因果关系的基础上,预测变量与目标变量的因果关系[10]。
由于只有医疗指标可以在医疗保险基金支出的影响因素量化,这意味着在过去的五年里,只有5个变量的医疗指标值。数据规模太小,基于因果预测准确的预测。同时,在医疗保险基金支出随时间变化的必然趋势。所以,时间序列预测是选择医疗保险基金支出预测。
预测从一个数据流,利用时间序列建立节点通过Clementine。下一步是选择预测模型的节点集[11]。如图3所示,它显示的数据流。

图3. 通过Clementine时间序列预测模型的数据流
表2. 每月医疗保险基金支出的数据拟合
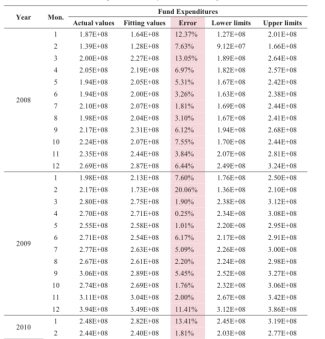
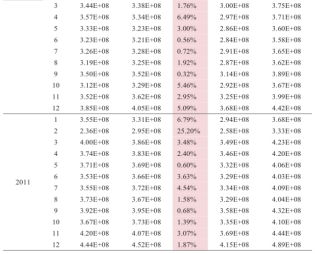
表3. 每月医保基金支出的数据预测
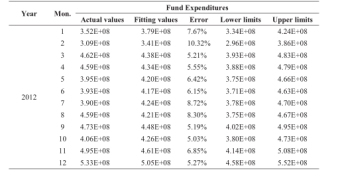

图4. 每月医保基金支出曲线的拟合和预测
如上图所示,表2显示了拟合值。它提供了样本数据建立的模型拟合结果,每月医保基金的支出从2008到2011。列1和2表示从2008到2011的时间段。列3提供每月医疗保险基金支出的实际值。这三列提供样本数据。然后拟合结果在列4表示。列4提供每月医疗保险基金支出的拟合值。列5提供的拟合结果列3和4的相对误差。列6和7提供的拟合值的置信区间。和置信水平为95%,这意味着拟合值发生在这个区间的概率为95%。表3显示了预测值。它提供的检验数据,文本的模型和预测结果。和柱的意思类似于表2。图4显示的拟合和预测曲线。
在拟合结果,拟合优度0.772。和残差序列的随机性测试表明没有结构的观测序列中无法解释的,这意味着该模型是理想的。此外,平均误差为5.05%,误差的方差为0.25%,这意味着该模型提供了小的波动,更适合和可以用来预测就像表3那种。
从表3中列出的结果预测,预测误差为6.72%,这意味着预测精度满足实际需求。
如图4所示,可以直观地观察出拟合及预测效果。
从以上的分析,它是适用于预测医疗保险基金支出的时间序列预测方法的合理性和有效性。这是必要的。
4 结论
通过本课题的研究发现将数据挖掘工具运用到医保定额结算的工作中去,将既能帮助管理部门方便灵活地制定定额标准,又能加快分析反馈的速度;最重要的是它还能在出现问题时帮助找出发生问题的可能原因。有了这样一种分析展示工具,不但能够极大地提高医保工作的效率和准确性,也为医保管理工作提供了一种有效地手段,同时对于医保数据做进一步深入的分析提供了一种有益的尝试,为管理部门提供了灵活的分析方式。
总之,医疗指标调整生产医疗保险基金支出一定的放大效应,和相对较低的医疗保险基金平衡指标相对较高。这样的优惠政策可以更多或更少的刺激医保基金支出的增长。因为有大量的前几年基金结余,医疗机构很少关注医疗保险基金结余。近年来,基金会和基金股票减少赤字。它影响了医疗保险的可持续发展。所以预测医疗保险基金有助于早期预警与政策调整。
参考文献
[1] Xu W B. Flourishing Health Work in China [J]. Social Science and Medicine, 1995, 41(8):1043-1045.
[2] 2012 China Health Statistical Yearbook.
[3] Tu Tingyong. Development Research of Chinese MedicalInsurance System[D]. Dalian: Dongbei University of Finance and Economics, 2012.
[4] Wang K M. Health care expenditure and economic growth: Quantile panel-type analysis[J]. Economic Modelling, 2011,28(4): 1536-1549.
[5] Zheng Xiaoyu. Brief Analysis of Causes and Countermeasuresabout Medicare fund loss[J]. China Collective Economy.2011(2):126-127.
[6] Shen Shuguang, Wu yubin. The Critical Issues of theIntegration of Urban and Rural Medical Insurance in China[J]. China Health Insurance, 2013(6): 33-35.
[7] Meijer C, O’Donnell O and Koopmanschap M. Health expenditure growth:
Looking beyond the average through decomposition of the full distribution [J].
Journal of Health Economics, 2013,32(1):88-105.
[8] GEORGE KARATZAS.On The Determination of The US Aggregate Health
Care Expenditure[J]. Applied Economics 2000, 32, 1085-1089.
[9] Wu Minglong, Statistical analysis of the questionnaire practice-SPSS operation and applications. Chongqing: Chongqing University Press,2010.
[10] Zhang Meiying, He Jie. Summary on Time Series Forecasting Model[J].
Mathematics in Practice and Theory,2011, 41(18), 189-195.
[11] Xiong Pin. Data mining algorithms and Clementin practice[M]. Beijing: Tsinghua University Press, 2011
[12]M.J.Zaki,N.Lesh,and M.Ogihara,andW.Li.Parallel algorithm
for discovery of association rules.Data Mining and Knowledge Discovery,1 997
[13]Randy Crane, A Simplified Approach to Image Processsing , Prentice
Hall, 1997.
