交互式视频检索系统的设计与实现

摘要
在本文中,我们介绍并讨论了我们为TRECVID 2002的搜索任务开发的系统及其在交互式搜索任务中的评估。要做到这一点,我们将看看我们在设计系统时使用的策略,并且我们讨论和评估用于确定一个系统的价值和有效性的实验,该系统结合了特征证据和抄录检索,而不是仅有抄本的检索系统。测试过的两个系统都建立在Físchlár系统的基础上,并在CDVP上运行多年。该系统完全兼容MPEG-7,并使用XML在整体内交换信息建筑。
类别和主题描述
H.3.3 [ 信息存储与检索 ]信息检索与检索 - 检索过程,查询公式。
一般条款
算法, 测量,性能,设计,实验,人类 因素。
关键词:视频检索,视频分析,视频浏览,系统评估,可用性测试,界面设计。
1.介绍
近年来随着许多数字图书馆和WWW的发展,多媒体信息检索已经显着发展,允许浏览和检索多媒体内容。每年来自世界各地的研究团队都有机会使用TREC(文本检索会议)指南和通用评估程序来评估他们在开发和加强信息检索系统方面的进展。作为TREC背后的组织机构,NIST(国家标准与技术研究院)以电子形式向所有参与团体提供一套文件和一组搜索主题。然后,组使用所提供的主题来运行他们自己的信息检索应用程序语料库,Permission使所有或本作品的个人或教室使用的部分数字或硬拷贝是不收取费用理所当然前提是副本没有制作或分发利润或商业利益和副本承担此通知,并在全CITA重刑第一页。要复制或重新发布,在服务器上发布或重新发布到列表,需要事先具体的许可和/或a费用。
MIR'03,2003年11月7日,美国加利福尼亚州伯克利。 版权2003 ACM 1-58113-778-8 / 03/00011 ... $ 5.00。并将结果发送回NIST。 手动评估返回的结果的相关性,从而创建一个基本事实并在所有提交的结果中进行比较评估。 使用单一通用语料库和单一评估策略 为基准测试不同系统的性能创造了一致的基础 。 TREC支持实验与自1992年成立TREC EG的互动轨迹推出了 不同 的轨道 信息检索的不同方面 不及物动词 oduced在1997年评估IR系统的互动元素,并在1999年推出的评估从超链接的网页语料检索表演的Web轨道。都柏林城市大学的数字视频处理中心(CDVP) 于2002年 参加了 名为TRECVID [1] 的 视频轨道 ,同时执行特征检测和搜索任务。 TRECVID于2001年首次推出 ,其总体TREC活动的 基本 目标 相同 ,但侧重于基于内容的数字视频信息检索。全球有超过20个团体,从大学研究团体到行业研究团体参加了2002年视频轨道的第二年,而2003年又有35人参与。与TREC的所有其他轨道一样,NIST为参与团体提供了一个语料库 - 一个总共约70小时的MPEG-1格式的数字化视频文件。 这个语料库被分成三个子集,用于TRECVID内的三个不同任务 :
• 镜头边界检测(SBD)的任务是评估如何准确的系统可以自动检测视频内容的相机镜头边界的练习。
• 特征检测任务,介绍了一种在2002视频轨中尚属首次 。 该轨道的目的是评估系统有效性,识别视频内容中简单的语义特征。
•搜索 任务被引入到评价检索系统的性能,通过分析,以 沉着应对 EFFE 并通过大型视频全集有效地搜索 用户的能力。
每个参与小组开发了一个交互式或自动视频检索系统,其前端界面允许访问视频语料库。然后,每个组中的用户使用NIST提供 的二十五个 主题 或查询来搜索视频采集。2003年,在广播电视新闻中增加了故事边界检测的后续任务。对于搜索任务,我们开发了一个交互式视频搜索/浏览系统,并在真实测试用户的实验室环境中使用TREC主题对其进行评估。该系统是Físchlár数字视频系统[2]的一个变体,专门用于在视频trac k in TRECVID2002 [2]。 Fischlár系统是一个基于网络的视频录制/索引系统,允许校园用户浏览在线电视节目并请求录制特定的电视节目。然后,用户可以浏览并选择 她或某个其他用户已录制的节目,以从视频中的任意点接收流式播放。该系统非常受欢迎,并于2003年初在网上提供超过300小时的在线内容和大学内2500名注册用户,访问学习,教学和研究系统目的。
2. 系统描述
为了进行评估和系统变型比较,我们为TRECVID 2002开发了两个几乎完全相同的系统,它们具有以前Físchlár系统的通用底层架构(图 1)。吨他二变种是简称至如'系统一个'(数字2)其中包含了ASR转录本检索(本节后面介绍)和仅包含ASR转录本检索的'系统B'。'系统B'具有与系统A类似的接口,但是我们通过文本搜索框取代了功能面板,允许用户使用ASR转录本搜索相关镜头。
2.1系统架构
该系统具有基于XML的架构,其内部视频描述符合MPEG-7标准。图1显示了具有内部XML描述的系统的整体架构。当用户通过基于Web的界面提交查询时,Web应用程序对其进行处理并将查询发送到搜索引擎。搜索引擎的更多细节可以在第3节中找到。搜索引擎将检索到的单独和组合评分结果发送回XML生成器,以便动态生成必要的XML描述,以供适当的XSL(可扩展样式表语言)样式表,以便呈现HTML和SVG(可缩放矢量图形)以便在用户的网页上显示浏览器。
2.2 用户界面
设计用户界面的任何系统的目标ØNE应该是简单,直接,方便的互动,不迷惑用户提供。 然而,诸如视频搜索系统的复杂多媒体系统需要复杂的 界面元素来搜索和显示结果。 拥有内部基于XML的体系结构使我们能够清楚地将接口中的数据表示与系统内部操作方式分开,从而显着帮助系统开发 流程 软件工程和界面设计可以分开进行。 为了便于在基于Web的界面上显示搜索系统,XSL和SVG已广泛地与XML描述一起使用。
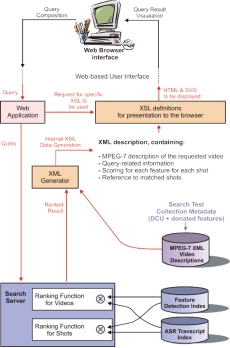
图1.Fschlár-TREC2002的体系结构
2.2.1设计
我们设计了接口来容纳捐赠给TRECVID参与者的所有十个功能(见图2),因为这对于所提出的假设是至关重要的。如表1所示,我们将这10个单独的功能分组为四个概念性更高级功能组。
表1.所用功能的分组
|
人:
|
面对,一群人
|
|
位置:
|
户外,室内,城市景观,景观
|
|
音频:
|
Speech,Instrumental Sound,Monologue,ASR transcript search
|
|
文本:
|
文本覆盖
|
每个组在面板上都有一个独特的选项卡,以节省屏幕空间,同时允许逐渐暴露给用户,从而防止“太多”效果(图2左上)。一旦这些分组建立起来,我们就在整个可视化和交互过程中使用它们,而不是单独使用十个单独的特征。四个组中的每一组都具有始终贯穿始终的独特颜色该相互作用阶段。小图标是设计对于每一个使用根据他们所属的组指定的四种颜色之一,提供的那种功能的用户有兴趣的低,但独特的和一致的线索十大功能。这些图标被连接到视频截图塔T中这些功能具有很高的置信度。

图2.查询和浏览的用户界面
2.2.2.查询
在查询期间,用户最初会在其屏幕左上角显示查询面板(请参见左上图2)。查询面板显示标签排列中的四个要素组之一,图2显示了包含两个要素(人脸,人员组)的人员组。用户通过选择相关要素的无线电来指定查询。所有功能都有标有“不重要”的默认单选按钮。 要选择面部或“人群”以外的其他功能,用户必须从查询面板顶部的其他选项卡中 选择一个, 例如输入文本查询,用户必须选择包含搜索框的“音频”选项卡。 当查询被构建时,检索工具被激活回国直观的方式。 当从搜索结果显示中选择视频节目时, 用户 选择 的初始屏幕是 具有主题描述的所选视频的概述,以及关于 从整个视频中自动选择30个小关键帧。 在内容浏览器的顶部,我们 有五个选项来查看相关视频的镜头列表(请参见图2)。这些包括: - “组合”,“人物”,“地点”,“文本”和“按时间顺序排列”。 这些按钮中的每一个都分别按照总体特征评分,人员评分,位置评分和文本重叠评分返回该视频中的评分列表。“按时间顺序排列”按钮显示镜头列表,但另外还有一个时间线显示在列表顶部,可视化视频中用户查询匹配的状态(参见 图 3)。

图3.视频中搜索结果的时间轴可视化
时间线的上半部分显示了每个镜头的组合分数和较浅的灰色条的相对高度,而下半部分显示了单个4个特征组 匹配状态,突出显示了查询与阈值匹配的位置。在时间线下方是与时间线的水平进度相对应的按时间顺序排列的镜头列表。点击时间线的任何部分,都可以在下面的镜头列表中看到镜头内容的部分。如图4所示,镜头列表中的每个镜头条目都提供了有关镜头的以下信息。排名的相关视频列表。
2.2.3 查看搜索结果
初始搜索结果以视频节目的形式呈现,按照聚合得分顺序排列,恰好位于查询面板下面的用户查询中(见图2)。个人特征检测分数结合起来形成每个视频的单个值(在第3节中解释),从而允许我们呈现一个排名视频列表,而不是来自不同视频的单独排名镜头列表。与每个视频相邻显示的是条形式的四个特征组的视觉分数,表示每个特征组的各个权重,以及哪些特征对视频的排序影响更大。显示在每个排名视频左侧的数字表示该用户在该特定视频节目中定义的相关数量。
2.2.4 浏览视频内容
当用户选择排名视频列表中的一个视频节目时,屏幕右侧的内容浏览器(见图2右侧)支持浏览视频内容。屏幕左侧的视频列表 用于视频节目中的查询结果分数的可视化,但是一旦用户移动到一个特定的视频节目中,问题就变成可视化该视频内的镜头之间的查询结果分数,并呈现个人的s热“内容的有效性和有效性。
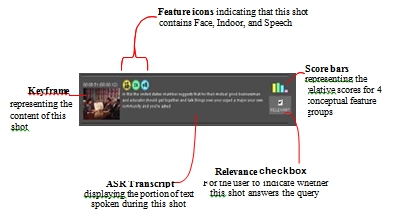
图4.视频浏览器中的镜头信息
2.3 TREC视频语料库
视频语料库是一个封闭的集合,因此所有基于内容的分析和索引都是离线完成的。假定Through NIST和供系统使用的数据是:
•176个视频节目文件,总共约40小时(MPEG-1格式),从1到28分钟不等 每。
•为所有视频标记预定和同意拍摄边界的数据(采用XML格式)。
•十个功能在视频节目每次拍摄 三月 K-了数据(XML 格式)。
•自动语音识别(ASR)成绩单所有视频。
该视频节目主要是1940 - 1970年代的美国政府广告,宣传活动以及关于自然,历史和社会的各种纪录片。 尽管所有的视频都具有足够的质量,可以被人眼认出并舒适地观看,但一些素材(40-70秒)的相关来源意味着视频的视觉和音频质量低于Fschl'lr系统已经被调整来处理,因此我们必须对这个特定视频集合的每个系统索引模块进行一系列参数调整 。
每个视频还有内容提供商提供的一段文字说明,互联网档案和开放视频项目。 除了视频语料库之外, 所有TREC参与者都可以使用 常见的镜头边界 检测数据,理论上可以在比较交叉参与者系统结果时更容易地参考视频片段。 常见的SBD数据也被用在特征 检测任务中,作为检测特定特征的视频段的单位。 参与组在搜索任务中使用的 交互式系统 使用此常见SBD结果定义的镜头单元作为搜索,浏览,向用户显示检索结果,选择回答主题的片段以及最终提交给NIST的基础。搜索任务中还使用了特征检测数据,由三个参与组(由DCU 提供 Face,Music and Speech和 Microsoft Research Asia和IBM的其他功能)以XML形式提供,总共提供了10个特征。此功能数据包含有关视频收藏中特定功能(例如镜头内的脸部)外观的信息。 对于每个镜头,我们在[0..1]范围内评分的十个特征中的每一个。参与小组能够将这些“捐赠”的特征检测输出整合到他们的搜索中系统。每个参与团队也可以获得语料库中所有视频的成绩单,这些成绩单由一些参与团体(微软亚洲研究院,卡内基梅隆大学和LIMSI法国)开发的自动语音识别(ASR)技术生成并提供,他们应用他们的ASR引擎可用于语料库中的所有视频节目。成绩单也用XML格式标记。MPEG-1格式的视频节目在Fischlár系统中通过离线处理,以便与上述特征检测数据和ASR转录本文本,所有文件先前都是由普通SBD定义的镜头级单元分割的。
3.支持搜索与恢复
在我们的F'schlár-TRECVID2002系统中,用户组成一个查询,其中包含零个或多个必需的功能以及(如果需要)用于匹配ASR转录本的文本查询。 再次 提醒用户的搜索会话本质上是一个两阶段的过程,第一阶段会生成一个排名的视频列表,其中176个视频中的每个视频在按降序排列返回给用户之前进行评分和排名。 在第二阶段中 ,用户可以选择其中一个视频(通常是排名最高的)进行镜头级考试。 拍摄级别的检查会在检索工具中生成与所选用户的查询相匹配的所选视频中的镜头列表。
我们的实验假设中回顾一下,我们要求用户使用仅限ASR进行搜索,并使用ASR和功能的组合。因此,我们开发了专门的检索工具,该工具旨在支持所有需要的搜索任务:
•ASR只需查询176个完整视频ASR描述;
•ASR只查询来自任何一个视频的镜头ASR描述符;
•ASR 功能查询176个完整视频ASR描述符和功能列表
•ASR +特征查询任何一个ASR描述符和特征列表视频。
对于系统B(仅限ASR),检索过程仅需要处理文本查询,但对于系统A,用户可以搜索十个自动生成的特征证据索引,并搜索ASR成绩单。我们分别检查每个检索方法。
3.1仅ASR搜索(系统B)
系统B的搜索和检索功能仅仅基于传统的 文本检索引擎。 每个视频由与所有包含该特定视频的镜头相关联的ASR转录表示,并且每个镜头由与该镜头相关联的ASR转录部分表示。 这导致了176 件用于视频检索的数据和14,524件用于镜头检索的文件。这需要使用两个传统(纯文本)搜索引擎,一个用于176个视频描述符,另一个用于镜头描述符,它们必须支持索引分区。 Th 比排列所有镜头和后处理排列的输出效果更有效,可以删除所有镜头,而不是从特定视频中删除。在编制索引之前,每个镜头的ASR脚本都经过了预处理,以去除停用词(词频过于频繁,无法帮助搜索过程,“”,“”,“和”等),然后使用Porter算法进行阻止。 排名算法 我们选择 搜索ASR转录本是流行的BM25算法,该算法已经在多年的TREC实验中证明了它的价值。 我们的BM25排名基于以下参数值,这些参数根据 TREC-8 [7]的WT2g集合得出 的最佳性能设定, 其中 adv1 = 900, b = 0.75, k1 = 1.2和 k3 =1000.我们注意到,额外的实验将有利于调整这些参数以最适合ASR 内容。
3.2ASR和特征搜索(系统一个)
系统A的搜索和检索功能基于传统的文本检索引擎(如3.1节所述),但必须将TRECVID 2002中可用的所有10种特征检测器合并到检索过程中。 CL 早其中排名拍摄和视频排名的顺序呈现给用户都会对用户是否会找到相关的镜头有很大的影响。 为了尽可能准确地提供视频和镜头的排名,我们以不同的方式处理了 镜头和视频 的排名 ,如图1的底部所示。 现在我们将检查我们的视频和镜头的搜索和检索方法。 我们的算法是在没有使用TREC主题的情况下开发的,因此没有专门开发算法 以在这个特定的语料库上提供高检索性能 查询。
3.2.1 视频搜索和检索单位
176视频中的每一个视频均由该视频中所有镜头计算出的十个特征中的每一个的总体特征权重表示,然后将这些总计分数除以视频中的镜头总数。 通过这种方式,我们 为视频排名过程中使用的每个视频中的十个功能中的每一个都获得了一个权重。如果没有对我们使用的特征检测的准确性进行彻底抽样, 并且我们的特征源自三个独立的参与 组,我们认为最好是对每个特征的权重进行归一化,以便没有任何特征会因为差异而超过任何其他特征仅在信心水平。如果我们忽略这些差异,最高加权特征实际上将 高于低加权特征的5倍,这显然会影响检索性能。此外,我们根据每个功能的实用性为每个功能的影响添加了一个最终权重,作为区分不同视频的辅助工具。为此,我们调整了传统的文本排序技术,称为idf(反向文档频率,它允许我们增加特征的权重,以更好地区分相关和不相关的视频。 Letti NG FWT VF 是 视频 v中 的特征 f 的特征权重,N是系统中视频的数量,以及 vf f 作为特征 f 的视频 ,我们的idf计算基于以下公式:


3.2.2 搜索和检索镜头单位
当用户从第一阶段选择排名视频时,初始查询(已生成视频列表)将被发送到检索工具,以便对该视频中的镜头进行排名。 用于对选定 视频 内的镜头排名的排名算法 类似于用于对视频 进行排名的排名算法 ,不同之处在于针对镜头的特征权重的归一化是在镜头级别计算的,而不是视频级别和特征影响的调节(基于在 idf上 )也是在 相对于视频水平的情况下计算的。 这导致我们加权某些特征,如脸部和独白,比其他人更高,因为他们更好地区分了镜头。 此外,我们对ASR成绩单分数的权重小于视频排名(两倍于任何一项功能)的权重,因为我们认为考虑到正在审查的视频已被认为是相关的。
4.系统实验
这个实验的目的是评估和分析'系统A'对'系统B'的有效性。 我们按照TREC指导原则进行了正式的实验,使我们能够比较两种系统搜索视频集合的有效性。 这些实验 使我们能够评估是否将特征证据(系统A)并入搜索过程中,以改善纯文本搜索(系统B)的检索性能。
4.1实验程序
总共有12人参加 了大学计算机学院的 测试用户,10名研究生硕士 和2名暑期实习生,总体目标是用户之间的个体差异相对较小,使我们能够比较'系统A'和'系统B'更有效地,即用更少的 可变性。 所有用户都具有先进的计算机知识水平,并熟悉基于网络的搜索,每种搜索都会每天进行某种形式的在线搜索 。 NIST在我们的系统开发完成后提供了二十五个查询主题。 对于 用户实验,我们将12个用户分为两组, 使用系统A(功能+ ASR转录本)的组A和使用系统B(仅ASR转录记录搜索)的组B具有六个用户。 为了避免用户a 的 学习效果, 他们通过了25个主题,对于A组和B组,三个用户以前向顺序进行了25个主题,而另外三个用户使用了相同的主题,但是以相反的顺序。 每个用户都有4分钟的时间来搜索 主题(包括阅读主题和准备初始查询)。 当用户完成了十二个主题后,他们在进入下一组主题之前先休息一会儿。
每个用户都需要完成TREC调查问卷,这些调查问卷 在过去几年中由TREC交互式跟踪分为预测试,后测和二十五个后题。 在简短的介绍之后,每个测试用户都会 看到 一系列的网页 ,其中包含了构成主题描述一部分的音频/图像/视频/文本示例。一个典型的TRECVID2002查询是主题18.该查询包含文本描述“用一个或多个帆船,帆船 ,帆船或高船 - 查找 带有一些帆展开的照片”,三幅帆船图片和两个视频剪辑。 用户使用他们感兴趣的TREC主题的任何方面准备了初始查询并继续进行搜索。 当用户认为回答了主题查询时,他们通过检查紧挨着镜头旁边的一个小方框来指出这一点(见图4)。 在四分钟结束时,用户填写了一个简短的专题问卷。 完成 用户填写测试后调查问卷 后的所有 主题。 所有个人用户交互都记录在系统的服务器上,并将结果收集,处理并提交给NIST 评价。
4.2实验结果
我们对每个视频检索工具的所有六位用户的综合结果进行 了比较 ,以解决用户可变性问题。 下面的每个结果表示由六个用户针对每个系统变化识别的镜头的交错结合。在比较所有六个用户的精确度和召回率图表时,我们可以看到系统性能大致相等,如图所示5。
在图6中,我们对每个系统的所有六个用户的结果进行了检查,其中显示了每个(六个)用户针对两个系统变体中的每一个提交的相关和不相关镜头的数量。该图显示系统A的用户之间的差异比系统B高得多(见图6)。
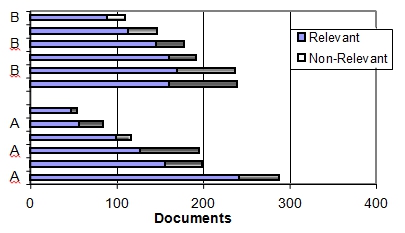
更详细地检查提交的结果表明,系统A的用户在所有25个查询中发现了382个相关镜头,而系统B的用户发现了388个镜头镜头。系统A的总体用户的平均精度为0.3164,而系统B的平均精度为0.3105。 这表明两个系统都具有相当的可比性,基于所有六个用户的总体结果的平均精度,结果没有显着的统计差异。鉴于这是一个交互式实验,涉及用户主动作出与哪些镜头相关并应提交评估的判断,这意味着 在提交结果之前,我们 已经将镜头判断为相关,并且这解释了人为的高精度人物。这些结果有些误导的另一个原因是,它们代表了一个由6个用户组成的小组的人工场景,他们共同致力于单个搜索任务,但他们允许我们符合我们提交的TRECVID准则,并且意味着我们所有的结果 已提交已被评估。 这又意味着在我们的TRECVID分析后,我们可以“解开”我们的官方提交的结果,并根据每个用户检查两个系统的性能,以呈现一组新的性能结果和一个新的分析结果。
Table 2. Average Precision of the featu res used
|
特征
|
Average Precision
|
|
Monologue
|
0.0086
|
|
言语
|
0.7103
|
|
Music
|
0.2221
|
|
Indoor
|
0.3348
|
|
Outdoor
|
0.6091
|
|
Landscape
|
0.1337
|
|
Cityscape
|
0.3479
|
|
人
|
0.1543
|
|
Face
|
0.2707
|
|
Text Overlay
|
0.4181
|
4.2.2用户问题
图6表明,'系统A'有六个样本中的两个用户,与其他用户相比,搜索能力非常不同。 在构建视频导航系统时必须考虑到用户的能力。 我们进一步评估了每个e用户的日志,并注意到用户返回最相关的文档并未在其原始查询中使用功能,而其他用户对功能的评价更高。 这给我们带来了这样的问题:功能是否有益于用户制定查询。 它还表明,考虑到使用功能的功能以及仅使用ASR或ASR和功能的选项,用户在75%的时间内使用ASR和功能来生成查询。让我们再考虑一下(主题18): “找到一艘或多艘帆船,帆船,帆船或高大船只,并展开一些风帆”。 为此主题生成的典型查询是:
Text= sailing ship boat
Location= OUTDOOR
Location Scape = LANDSCAPE.
当用户点击排名视频列表中的视频标题时,呈现给用户的第一个浏览屏幕就是该视频的概览,其中有简短的文字描述和30个关键帧。这30个关键帧是在整个视频内容中以特定时间间隔选出的,旨在提供视频内容的一瞥视图。在实验过程中观察到的用户行为表明,用户通常会根据概览的关键帧丢弃视频,而无需实际检查该视频中的镜头。尽管视频的这个关键帧概述可以很好地显示视频的粗略内容,但如果与用户查询相关的关键帧没有出现在概览中,则可能会误导用户,从而导致用户错过相关镜头。我们注意到,当用户搜索主题#4(“以亚伯拉罕林肯的描绘查找镜头”)时,相关视频将亚伯拉罕林肯的脸部显示为三十个关键帧之一,用户单击此处即可看到该镜头。但是,如果在30个关键帧中未选择该关键帧,则用户可能只是转向下一个视频节目,完全错过了相关镜头。这个例子在其他话题中也是如此。我们认为视频概览应该显示更多的基于查询的概述[16],而不是目前的总体概述,也就是说,我们应该根据镜头分数选择30个关键帧,而不仅仅是时间长度如同一般。
5.结论
在本文中,我们考察了两个系统之间在性质和设计上几乎相同的视频信息检索系统之间的差异,不同之处在于它包含了基于特征的搜索和基于ASR的搜索。系统已经在实验室环境中进行了测试,有12个用户在TRECVID主题上进行搜索任务。我们感兴趣的是在搜索视频集合中的特定主题时系统为用户提供的有效程度。我们从测试用户那里获得了实时和用户评论作为实验室测试会话的一部分,以分析用户对系统及其各种功能的意见和想法。我们的用户交互日志表明,鉴于有机会使用功能,“系统A”(基于功能)的用户将其功能纳入其查询的75%。然而,尽管特征是查询制定的一个重要方面,但包含这些特征并没有显着提高检索性能。
由于我们使用的特征报告的准确性存在大量的变化,并且由于用户之间存在很大的差异,因此有必要设计一种评估策略,以减少用户变量并促进系统间的比较。这种评估策略将衡量和比较两种系统变体(A和B)的有效性,它允许一个用户同时使用这两个系统,同时永不让用户看到一个特定的主题。为了做到这一点,用户必须在两个系统之间进行切换,逐步完成主题。对于未来的实验,我们强烈认为,即使认知用户差异被认为是次要的,两个系统变体的主题内测试应优先于两个系统变体的主题间测试来执行。如果没有别的,我们的结果表明,在同一个系统上,同一主题上,具有相似背景和年龄分布的用户组之间存在很高的主题差异。
我们的Fischlár系统的整个评估为我们提供了一个定性和基于查询的概述,从中我们可以发现我们的数字视频检索系统的优势,问题和评估问题。评估还使我们能够对我们自己的系统进行比较,但与其他站点的其他系统进行比较。虽然这是TRECVID的一个明确目标,但在2002年TRECVI D中这是不可能的事实,是因为赛道的活动尚未成熟到该州。 TRECVID尚未建立可跨站点使用的基准,以支持跨站点系统比较。此时,TRECVID活动具有必要的数据,了解视频红外线在交互式搜索时进行的跨站点比较中涉及的问题,并有在这一领域取得进展的势头。交互式视频导航的许多方面,如本文中报道的文本和基于特征的搜索相结合,单个视频中时间近距离拍摄中的本地浏览以及跨越视频的以下信息链接,这些是TRECVID所关注的方面还不够成熟,无法在现场或交叉比较中促进。这一进展可以预见在未来几年。
6.鸣谢:
部分材料基于欧盟IST计划IST- 2000-32795 SCHEMA支持的工作。 作者要感谢爱尔兰企业信息研究倡议组织和爱尔兰科学,工程和技术研究委员会的支持。 我们也感谢MSR Asia和IBM为DCU和所有TRECVID参与者提供特征检测输出。
7. 参考文献
[1] TREC2002 Video track. Available online at URL: http://www-nlpir.nist.gov/projects/t01v/t01v.html (last visited May 2003)
[2] Lee, H. and Smeaton, A.F. Designing the user interface for the Físchlár Digital Video Library. Journal of Digital
Information, Special issue on Interactivity in Digital Libraries, 2(4), 2002.
[3] Lee, H. and Smeaton, A.F. Searching the Físchlár-NEWS Archive on a mobile device. Proc. 25th International ACM Conference on R&D in Information Retrieval, Workshop on Mobile Personal Information Retrieval (SIGIR 2002), Tampere, Finland, 11-15 August, 2002.
[4] The Internet Archive. Available online at URL: http://www.archive.org/movies/ (last visited June 2003)
[5] The Open Video Project. Available online at URL: http://www.open-video.org/ (last visited July 2003)
[6] McDonald, K., Smeaton, A.F., Marlow, S., Murphy, N. and O’Connor, N. Online television library: organisation and content browsing for general users. Proc. of the SPIE Electronic Imaging – Storage and Retrieval for Media Databases, San Jose, CA, 24-26 January, 2001.
[7] Savoy, J. and Picard, J. Report on the TREC-8 experiment: searching on the Web and in distributed collections. The 8th Text Retrieval Conference (TREC-8), Gaithersburg, MD, 1999.
[8] Dimitrova, N., McGee, T. and Elenbaas H. Video keyframe extraction and filtering: a keyframe is not a keyframe to everyone. Proc. of the 6th ACM International Conference on Information and Knowledge Management (CIKM '97), Las Vegas, NV, 10-14 November, 1997.
[9] Wactlar, H., Kanade, T., Smith, M. and Stevens, S. Intelligent access to digital video: Informedia project. Computer, 29(5), 1996.
[10] Smith, J.F. Searching for images and videos on the World- Wide Web. Technical report #459-96-25, Center for Telecommunications Research, Columbia University, 1996.
[11] Zhang, H., Low, C., Smoliar, S. and Wu, J. Video parsing, retrieval and browsing: an integrated and content-based solution. Proc. of 3rd ACM International Conference on Multimedia (MM ’95), San Francisco, CA, 5-9 Nov, 1995.
[12] Wolf, W. Keyframe selection by motion analysis. Proc. of the International Conference on Acoustics, Speech, and Signal Processing (ICASSP '96), Atlanta, GA, 7-10 May, 1996.
[13] Aoki, H., Shimotsuji, S. and Hori, O. A shot classification method of selecting effective key-frames for video browsing. Proc. of the 4nd ACM International Conference on Multimedia (MM '96), Boston, MA, 18-22 November, 1996.
[14] Uchihashi, S., Foote, J., Girgensohn, A. and Boreczky, J. Video Manga: generating semantically meaningful video summaries. Proc. of the 7th ACM International Conference on Multimedia (MM '99), Orlando, FL, 30 Oct - 5 Nov, 1999.
[15] TREC Interactive track. Available online at URL: http://www-nlpir.nist.gov/projects/t11i/t11i.html (last visited July 2003)
[16] Christel, M., Winkler, D. and Taylor, R. Improving access to a digital video library. Proc. of the 6th IFIP Conference on Human Computer Interaction, Sydney, Australia, 14-18 July, 1997.

