摘 要
数据挖掘,就是从存放在数据库,数据仓库或其他信息库中的大量的数据中获取有效的、新颖的、潜在有用的、最终可理解的模式的非平凡过程。其在商业领域具有广泛的使用,透过数理模式来分析企业内储存的大量资料,以找出不同的客户或市场划分,分析出消费者喜好和行为,为管理者提供决策支持。数据挖掘,简单说,就是从大量的数据中,抽取出潜在的、有价值的知识、模型或规则的过程。本文将数据分析过程分为确定数据分析目标、研究设计、数据预处理、整理与数据挖掘、解释和分析计算结果 5 个阶段。利用 MATLAB 软件的聚类分析和判别分析功能对某高校某一段时期内的用户上网日志的分析,挖掘出在抽样时间段内用户上网的行为模式,为科学的进行网络管理提供依据。实践表明,该方法具有简便易用,有着广泛的应用价值。
关键词:用户行为模式;数据挖掘;apriori算法;判别分析;MATLAB
Abstract
Data mining is to extract effective, novel, potentially useful data from a large amount of data stored in databases, data warehouses, or other repositories. A nontrivial process that is ultimately understandable. It is widely used in the business world. It uses mathematical models to analyze a large amount of data stored in an enterprise, to identify different customer or market segments, and to analyze consumer preferences and behaviors. Data mining, in short, is the process of extracting potential, valuable knowledge, models or rules from a large amount of data. Data preprocessing, data processing and data mining, interpretation and analysis of the results of calculation are five stages. The function of clustering analysis and discriminant analysis of MATLAB software is used to analyze the users' online logs in a certain period of time in a certain university. In order to provide scientific basis for network management, this method is easy to use and has wide application value.
Keywords: user behavior pattern; data mining apriori algorithm; discriminant analysis; MATLAB
目录
摘 要 1
Abstract 2
1 引言 4
1.1 课题背景及研究意义 5
1.2 研究现状及分析 5
1.3 论文组织结构 8
2 基于蚁群算法的Web日志挖掘概念 10
2.1 Web日志挖掘 10
2.1.1 Web日志挖掘分类及架构模型 11
2.1.2 Web日志挖掘过程 11
2.1.3 Web日志挖掘技术 14
2.1.4 Web日志挖掘算法的关键问题 17
2.2 蚁群算法 18
2.2.1 蚁群算法分析 18
2.2.2 蚁群算法的关键问题 19
2.3 本章小结 20
3 Web日志挖掘的预处理技术 21
3.1 聚类模型分析 21
3.2 聚类模型设计 22
3.3 Web日志预处理相关技术 24
3.4 Web日志数据预处理的过程 25
3.4.1 数据清理 26
3.4.2 用户识别 28
3.4.3 会话识别 30
3.4.4 路径补充 31
3.4.5 事务识别 33
3.5 本章小结 34
4 应用于Web日志挖掘的改进蚁群算法设计 35
4.1 蚁群算法在Web日志挖掘中的应用分析 35
4.2 传统日志数据挖掘算法 36
4.2.1 Apriori算法 36
4.2.2 蚁群系统算法 37
4.3 一种改进的适用于Web日志挖掘的蚁群算 38
4.3.1 改进后蚁群聚类算法流程 41
4.4 仿真实验对比分析 42
4.4.1 仿真环境与数据 43
4.4.2 对比实验 43
4.5 改进后的蚁群聚类算法应用场景实验 45
4.6 本章小结 47
5 Web日志数据挖掘系统的实现 48
5.1 系统的设计 48
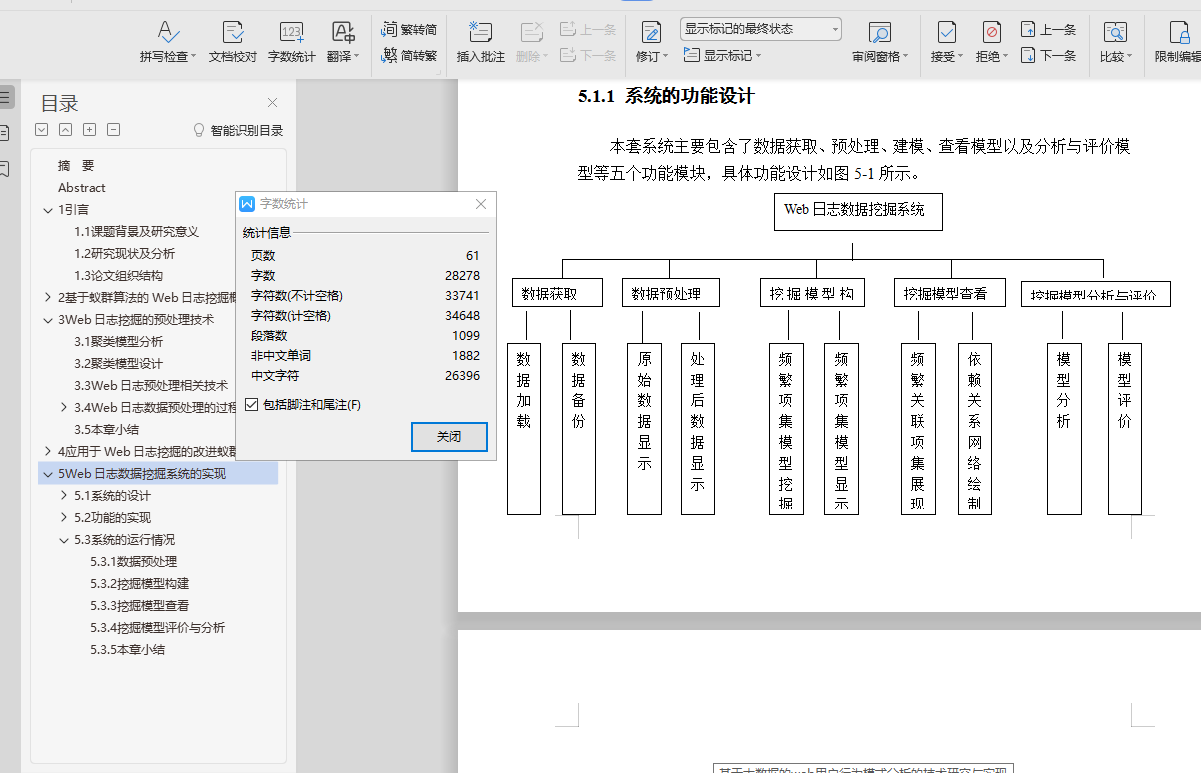
5.1.1 系统的功能设计 48
5.1.2 系统的类设计 49
5.2 功能的实现 50
5.2.1 数据获取模块以及预处理模块的实现 50
5.2.2 数据挖掘构建模块的实现 51
5.2.3 数据挖掘模型查看模块的实现 52
5.2.4 挖掘模型分析与评价模块的实现 55
5.3 系统的运行情况 56
5.3.1 数据预处理 56
5.3.2 挖掘模型构建 58
5.3.3 挖掘模型查看 59
5.3.4 挖掘模型评价与分析 60
5.3.5 本章小结 61