|
"Times New Roman"; font-size: 12pt;'>��ǿͼ��G3�ĶԱȶȣ�����ÿ�����ض��Ǵ��ڵ����ģ���������ֲ���ƫ���������17������������ͼ���С��ͬ�ı�ƫ��ͼ��SD���������ٴ�ʹ����һ����СΪS��S�Ĵ�����ǿͼ��G3�ĶԱȶȣ���������ֲ���ֵ��������һ��ƽ��ͼ��M�����������ʹ������֮���ƽ��ͼ��M�ͱ�ƫ��ͼ��SD���бȽ�������һ��������ͼ��B1��������������
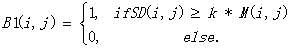 ��4�� ��4��
���У�i,j�������ص�λ�ã�k��ʵ��ȷ���IJ�������Χ��0-1����ĿǰΪֹ���������ڡ����������������ͼ����k��ѵ�ֵ��0.3������������ģ����ͼ����k��ѵ�ֵ��0.2������ҹ��ͼ����k��ѵ�ֵ��0.075�����ÿ��ͼ����ȷ�����������������ʡ�ͼ9��ʾ������ƽ��ͼ��M����ƫ��ͼ��SD��������ͼ��B1��Ϊ����ͼ������������ʽ��4�������DZȽϵı�ƫ��ڶ��ף���ƽ��ֵ����һ�ף�����ԭ��������Ҫ����ֲ��ı�ƫ��ı�ǿ�ȣ��ߣ����ֲ���ƽ��ֵ��ƽ��ǿ�ȣ��͡���ˣ���ͼ��B1���ж�ֵ������ʱ����ʹ������ǿ��ֵ�ͣ�������������ɼ�����ǿ�ȵı仯�ڻҶ�ͼ���G3�Ǹ�����ͬʱ�������������������ǿ��ֵ�ܸߣ������������������Լ��ٶ�ֵ��ͼ���еİ�ɫ���÷���ͬ�������ںڵװ��ֵij��ƣ���Ϊ�ں�ɫ��ӽ���ɫ�ı����ϵ�ƽ��ֵ���͡����ͼ���а��������ij�������ô������Ҫ������ֵȡ������Ϊ��ֵ���롣��ʽ��4��������Ҳ��ƽ��ֵ��ϵ��k�����k��ȡֵ��Χ��0-1���ڶ�ֵ�����������У���С��kֵ���Сƽ��ֵ������ζ�������������������е��ͱ�ƫ��ֵ����һ���棬�ϴ��kֵ������ƽ��ֵ������ζ�������������������е��߱�ƫ��ֵ����ˣ����ڵͶԱȶ���ͼ��������Ҫʹ����С��kֵ�������߶Աȶ���ͼ��������Ҫʹ�ý�����kֵ��
���������ϸ�۲������ͼ��B1�����ǿ��������ݾֲ�����������ǿ��ת������ѡ���ɫ���ء�������������ǿ��ת�������ܸߣ����Զ�ֵ�����̻��������������һ�����ܶȵİ�ɫ����������ʵ�ϣ����ֶ�ֵ�����̽��������ɫ�ı�ʱ���߽磬�����ӱ���ǿ�������Χ����ǿ������߽�Ŀ��ȡ�Ϊ��������ֵ�����������̣�����ͨ������һ����ͼ��������չʾ��ͼ10չʾ������ֵ������ǰ���ͼ�����������ϸ�۲죬�ͻ�������������ֵ��������������߽粢����߽������ȡ�����ı߽����ȡ���ڴ��ڵĴ�С���������������ַ������߽磬������ֵ������������Ķ�ֵ��ͼ��B1�г��������ܶȵİ�ɫ�����������ϼ������Ĵ����������˫�еģ����ǵ�ͼ�����ݼ�����������֮���ƽ�����ؾ���Ϊ7��ͼ����ˣ�Ϊ���ڶ�ֵ��������������������һ��������ʹ����СΪs��7�Ĵ��ڡ�
������ij����Զ�ʶ�������ڶ��ν�������еĵͶԱȶ����⣬��ģ�������졢���Ϻ������Ļ���������ͼ11��ʾȥ��ͼ��G2���������ӣ������Ķ����ư汾�����ڶ���֮���õ�������һ��������ʹ�ö�����ͼ��B1��Ϊ����ͼ������λ��ѡ��������
3.3.�ֲ������˲�����CCC
3.3.1.�ֲ������˲���
�ڵ����εĿ�ʼ�����ǽ��ֲ������˲���Ӧ���ڶ�����ͼ��B1�е����ܼ���ɫ������С�Ŀհ㡣�ڴ�СΪS��S�Ĵ����п��Կ���������ͼ��B1�ľ����Ͱ�ɫ���ص�����������ֲ������еĴ���50%�����ص�������ɫ���أ�������������λ������Ϊ1��������0���������������dzɹ��õ��ı����������ͼ��B2������ʹ�ü����˲���ʱ���ô��ڵĴ�С����ͨ������һ��߶ȣ���Ϊ������ͼ��B2�ij��ƺ�ѡ���������ܼ��İ�ɫ�������ǵ�ͼ����ƽ���߶���40���أ���˴��ڴ�СS��20��ͼ12�����������������˲���Ķ�����ͼ��
3.3.2. ��̬ѧ�����㷨
��ʹ�ü������������CCC��֮ǰ��������Ҫȥ��С�İ�ɫ��������������ĵ�����������ɫ����֮�����ͨ��������ʹ��CCC����ʴ�����ͣ���������ͼ��B2�����˲���ͬʱʹ��Բ����Ϊ�ṹԪ�ء�Բ�̵İ뾶ȡ���ڳ�������Ĵ�С��Ȼ����ʵ���У�����ʹ��һ��Բ�̰뾶Ϊ20���أ����Ƹ߶ȵ�һ������������������ͼ12��c���и����˶�����ͼ��B3����CCC����������ӡ�
3.3.3.�������ӵ����
�ڶ�����ͼ��B3���������������������8-neighboring����������������Ҫ����������ͼ��B3�����˴������ӵ�Ҫ����ͼ13��a����ʾ��һ������Ҫ�����ΪC1��C2��C3��C4��C5�Ķ�����ͼ��B3�����ӡ�����������������Dz��þ��βü�����ǿͼ��G3�ĶԱȶ����ڲü�ͼ��G3�ľ���ʱ�����ǿ��ǵ���С�����е�ֵ����ͼ��B3������ε����Ͻǵ㣬����к��е�ֵ����ͼ��G3������������½������ڲü�֮������������ƺ�ѡ������ͼ13��b����ʾ���еľֲ���������ɫ�����ΪLP1��LP2��LP3��LP4��LP5������Щ���ƺ�ѡ�����У�����һ����ʵ�ʵij�����������һ����Ҫһ�������õ��˲�������������ҵ������ij�������
3.4.��Ǽ����У��
������ij����Զ�ʶ������������Ϊ������бͬ�������д��ڵ�����֮һ�����ǽ������бУ�������������ˮƽ��б�Ƕ���0 - 30����Χ�ڵ���б���Լ���бУ����֮����������б�Ƕ�Ҳ�����������������˲���
3.4.1.Bernsen�Ķ�ֵ���ͺ�ѡ���Ƶ��ܳ�
Ϊ�˼����б�Ƕȣ���������ʹ�ö������ܳ��Ժ�ѡ�ij�����������ü������ڼ��Ҷ���Ϣ����б�Ƕ���û�б�Ҫ�ģ�ֻ�б߽���Ե�����Ƹ�ʽ����Ϣ����Ч�����������������Bernsen�Ķ�ֵ��������15��15�����ڣ�����ֵ���ԻҶ�ͼ����ѡ����������LP1��2��3��LP4�ȵȣ����д�����Ȼ�����������ͼ��������Bernsen��Ϊ�м����������Ϊ�����ڹ��ղ����ȵ�ͼ���������������籩¶����Ӱ��ͼ14չʾ��һЩ��ѡ�ij��������ͼ��ͬʱ���о���Bernsen��ֵ�����ܳ��������ͼ���� , ���ӻ����µij����Զ����
����Samiul Azam, Md Monirul Islam
Samiul Azam:
���ô�����ʡ�Ŀ��������ѧ�������ѧϵ.
Md Monirul Islam:
�ϼ������│���ϼ������̼�����ѧ������������ѧϵ
�ؼ��ʣ�
�����Զ���⡢���ӻ��������ꡢ���졢ˮƽ��б���ͶԱȶ�ͼ����Ҷ�任
ժҪ��
�����Զ������ָ��û���˲���������ʵ�ֶ�ͼ���г�����������Ķ�λ��������ĿǰΪֹ���Ѿ��кܶ���������Զ����ƣ����Ǵ������û�п�����ʵ�ʼ�ʻ�д��ڵĸ��ֲ������ء�������ͼ��������ζ��ͼƬ�п��������ꡢ�������ͶԱȶ��Լ������ͳ������ƻ���ˮƽ��б�ij���������Щ�������չ��Ч�ij����Զ�����ֶδ����˺ܴ����ս���ڱ����У����������һ���µ��Զ����Ƶķ��������ܹ��ں��и���״����ͼƬ����Ч�ض�λ���Ƶ������������Ӱ�죬���Dz���Ƶ����ģ�ķ���������ͼ������������ɵ����ơ����ڵͶԱȶȵ����ڡ����ϡ���������Σ��Զ����Ƽ���в�����һ��ͨ��ͳ�ƵĶ�ֵ����������ǿ�Աȶȡ�������б�ij�����������Ӧ�û���Radon�任��ʵ����бУ�������⣬Ϊ������ȥ����LP���������һ�ֻ���ͼ���ص���������������������ķ�����850�������ڸ��ӻ����µ�ͼƬ�����˲��ԣ��������˷dz����⡣
1������
�����Զ������ָ��û���˽���������ʵ�ִ�ͼƬ�жԳ�����������Ļ�ȡ������ڳ����Զ�ʶ��ϵͳ��˵�Ƿdz���Ҫ��һ���֡�������˵�������Զ�ʶ��ϵͳ��Ҫ��Ϊ���������Σ�(1)ʹ��ͼ��ɼ��豸��ȡ������ͼƬ��(2)��ͼ���ж�λ���Ƶ�ȷ����(3)�ӳ���������ȡ��ʶ��������Ϣ��ͼ1չʾ���dz����Զ�ʶ��ϵͳ�Ļ�����ܡ���ϵͳ��Ŀ����ͨ��ͼ�����Ƶ�а����ij�����Ϣ���Զ�ʶ�������ڳ����Զ�ʶ��ϵͳ�У����������������װ��·�ꡢ·�ơ�����������ŵȵط����Դ��������йس�����ͼ��Ȼ��ͼ����Ϣ�����������������ͨ������������λ������ͼ���е�λ����Ϣ����Щ������Ϣ���ܹ�����ʹ��Ҳ���Դ洢����ʹ�á������Զ�ʶ��ϵͳ��������ʵ�����������Ź㷺��Ӧ�ã��磺��ͨ����������ʶ�𡢽�ͨģʽ�������Զ��շѡ�ͣ�������ȵȡ�
�ڳ����Զ�ʶ��ϵͳ�У����Ƽ�ⶨλ��Ϊ�ؼ�������ֱ��Ӱ������ϵͳ�����ܡ��ڼ��Σ�������Ҫ���һϵ�е����⣬���磺(1)���ӵ��������������ꡢ��������(2)���ӵ�ͼ�������ڷdz��ƵĶ���(3)�ͶԱȶȵĻ��������ڡ�ҹ����ģ�������ղ����ȣ���(4)���������λ�õ��³���ͼ���ˮƽ��б����Щ���ⶼ�����ڸ��ӵĻ��������³��֡�ͼ2չʾ���ڸ��ӻ����µ�����ͼ������ӡ���˳����Զ�ʶ����һ��������ս�Ե��о����⡣��ǰ���ܶ�����Ŭ������һ�������ij����Զ�ʶ��ϵͳ����������ȴ�ر��˳��Ƽ���д��ڵĴ����⣬��ʹ�ø�ϵͳ�ڳ��Ƽ�ⷽ���ܵ��ܴ�����ơ���ˣ�һ������ȫ��ij��Ƽ�ⷽ�����ڳ����Զ�ʶ��ϵͳ��˵�Ǻ��б�Ҫ�ġ��ڱ����У�����ֻ��ע��δ�����ͼƬ���Զ�ʶ���Ƶ����������dz����Զ�ʶ��ϵͳ��ͼ��IJɼ���ʶ���衣���У�����ͼ��ĸ��ӻ������������ǹ�ע�����ġ����ǵ�Ŀ�������һ�������Զ����ķ����������ڼ��ӵ�ͼ�����붼���кܺõı��֡�
���ĵĽṹ������ʾ����2�ڣ���Ҫ���������еļ��ֳ����Զ���ⷽ���ľ����ԣ���3�ڣ���������Ƶij����Զ���ⷽ������4�ڣ�չʾ������ij����Զ���ⷽ����ʵ���еı��ֺͽ������5�ڣ����������Ĺ��������ܽᣬ�����һЩ����ͽ��顣
2�����ع�
�ڹ�ȥ��ʮ���У����������ڴ�ͼ�����Ƶ�м��DZ�ڵ���������ͬ���ҵ����Ƚ��ķ��������ڲ�ͬ��ͼ�����������������㷨���Ӷ����������Լ��������Զ�ʶ��������Ϊ�˴�ͼ���м������Ƶ�������Ҫ���ݳ��Ƶļ��Ρ���������ɫ�����������ۺϷ�����ֵ��ע����ǣ����ӵ�������Ӱ�쳵�Ƶ����������³��Ƽ�������������У�ͼ���е������ƻ���ɲ���Ҫ�IJ�����ͱ�Ե�ܶȡ��ͶԱȶȻ�����ҹ�䡢���ڡ����졢ģ���������˳����ַ������Ʊ߽�Ŀɼ��ԣ���ʹ�ó��Ƶ�ǰ����ɫ�����˱仯������ζ����Ӱ���˳��Ƶļ��Ρ���������ɫ�����������������λ�úͽǶȣ�����ͼ���е���������������ˮƽ��б�������Ӱ�쵽��������ļ�����������ˣ����ڼ��������������������dz����ѡ��ڲ����ͼ���г����������������壬�磺ǰ�յơ����ոܡ�������logo�ȡ����ӵı��������ڳ����Զ�ʶ����ѡ��ԭʼ��������ʱ����ģ�����ɵ������������飬���Ƿ������е����Ƚ��ij����Զ�ʶ��û��ȫ��ؿ������еĸ����������ڱ�1���ܽ��˼������Ƚ��ij����Զ�ʶ�����������ļ����Լ��ڸ��������µľ����ԡ����⣬����һЩ���ڵ���ҵ��;�ij����Զ�ʶ��ϵͳ�������ϸ��ܵ�����������ȡ�似����������Ϣ��
�ӱ�1�����ǿ������еij����Զ�ʶ�������ܽ���������������⡣������һ�ַ��������˳��Ƶ���б���⣬������������Ӱ�����ַ�����ͨ�Ժ��������ܶ������о������Զ�ʶ��������п��dz��Ƶ���б���⣬����������Ϊ��б���ƵĶ�λ��У��������û�б����֡��������������������˳�������б������б���������û�о���ķ���ȥ������б�ij��ơ������еij����Զ�ʶ��[10,12�C14,20�C22,25�C27]��Ϊ�����ͼ�����߱����õĶԱȶȺ����ȡ���������û�в�ȡ�κ���ǿ�ԱȶȵĴ�ʩ��ֻ�з���[16,18]ʹ����ǿ�Աȶȵķ����������ͼ��ĶԱȶȣ�����ڵͶԱȶȣ�ҹ�䡢ģ�����ij�����������Ч�ġ�����[9,11,15,19,23,24,28�C30]����������ͼ����ղ����ȡ��ͶԱȶȵ����⣬��û��ȫ�濼�Ǹ��ӵ��������ӱ�����ȥ���dz�������ʱ��������ִ�ķ����Ǹ��ݳ��ƵĴ�С���ݺ���Լ�������Ϊ���˵�����������[10]����ŷ������Ϊȥ���dz�������������������������������������ӻ��С������İ㡣����[11,13�C15,19,26]ʹ��ˮƽǿ��ת���������Ե�ܶ���Ϊ����������������û��ʹ���κ������˲��ͶԱȶ���ǿ�������ڷ���[9,23]��ͨ��ģ��ƥ����������ͼ��ij��������ͷ������������ⲻ�����˷�ʱ��ͬʱ�Բɼ�����ͼ���нϸߵ�Ҫ���ַ�����������Ӧ����[27]�У���ͬ�������ʱ����˷ѡ����Ƶ���ɫ������Ϊʶ���������һ�����ݣ������Թ⡢ǿ�⡢��Ӱ�dz����С�������Ч�˲���Ȼ��Ҫ������˲������ܵ���˵�����еij����Զ�ʶ�����жϸ��������µ�ͼ��ʱ�кܴ�ľ����ԡ�����ʵ����������������һ�����ڸ��ӻ�������Ч����������·��������ֳ����Զ�ʶ��ϵͳ�ǻ��ڳ��Ƶ���ɫ��λ�ú������Dz���仯�ġ������������κ����еij����Զ�ʶ��ϵͳ�����ĵĴ��¹������£���1����ͼ����������ȥ������������2������Tamura�Ľ��Աȶ�����Ӧֱ��ͼ���⻯��CLAHE������3���ͶԱȶ�ͼ������һ���µ�ͳ�ƵĶ�ֵ����������4������Radon�任�Գ��Ƶ���б�Ƕ���������У�����������ַ�����ͨ�Բ������У���5�����ݷdz�����������ļ����Ϊ�µĹ���������������½ڽ�����ϸ����������ij����Զ���ⷽ����
3������ķ���
�����Զ�ʶ��ķ�����Ҫ��������Σ�
1��ͼ��ĻҶȱ任��������������ȥ����
2����ǿͼ��ĶԱȶȣ������ж�ֵ��������
3��ͨ�����ؼ����˲����������������
4�����Ƶ���Ǽ���У����
5�����˷dz��Ƶ�����
�ڴֽΣ����Ƕ��������µķ���ʹ������ij����Զ�ʶ��ϵͳ���Ѿ����ڵĽ�������������IJ��졣ͼƬ3���ݽε�˳��չʾ��������ij����Զ�ʶ����
3.1. ͼ��ĻҶȱ任��������������ȥ��
3.1.1. RGB��ɫͼ�Ҷ�ת��
����ʹ����������ػ�ȡ������ͼ������RGB��ɫͼ����Ϊ�����Զ�ʶ��ϵͳ�����롣ͨ������£������Ǻڵװ��ֻ��߰��֡����ϼ����������˽�������ij��Ʒ�����Щ��ɫ��ʽ������һЩ�����Ǻڵ����������⣬���ص�һЩ��ҵ���������䳵�����̵��ֻ�Ƶ��ֵij��ơ�Ȼ������Щ��ɫ�IJ�����ڳ����Զ�ʶ����Ҫ����Ϊû���κ���ɫ��Ϣ��������Ϊ�������������������ԭ���Dz����ȵĹ��ջ����ɫ��Ϣ�����ܴ��Ӱ�졣�����ڳ����Զ�ʶ���ÿ���ζ�����ʹ�ûҶȻ��ֵͼ��RGB��ɫͼ��ת��Ϊ�Ҷ�ͼ����Ҫ�������²�����
 (1) (1)
��i��j�������ص�λ�ã�G1�ǻҶ�ͼ���ֵ��R��G��B�Dz�ɫͼ������ͨ������Ӧ��ֵ��
3.1.2.ȥ�������Ӱ��
�ڳ����Զ�ʶ������У������������Ƶ�ͼ����Ϊ����ή��ϵͳ�����ܡ�ͼ���е������Ʋ�����һЩ�������������һ�������Ϊ��ѡ���������������Ϊ����߳����Զ�ʶ��ϵͳ�����ܣ���Ҫȥ������ٻҶ�ͼ��G1�������Ƶ�Ӱ�졣��ȥ��ͼƬ�е����ʱ�����ǿ�������Ϊ�����Ե������������Ե�����������Ƶ����з������˲��������˼�����������������ڸ���Ҷ�任���ͼ���г��ֳ����б�����״̬��������һ����˼�룬���ǿ�����һ���Զ�ȥ��ͼ�������ļ�����������Ч��ȥ��ͼ���еĽ������ơ����ȣ�����ʹ����ɢ����Ҷ�任��DFT�����ܽ���Ӱ��ĻҶ�ͼ��G1ת��Ϊ����Ҷͼ��F1�����ڸ���Ҷͼ��F1�У������Է�Χ0-1�������е�ϵ��ֵ��������0.5��Ϊ��ֵ���Ӷ�������Щ��Ҫ��ϵ��ֵ��������ֵ���������Ҷͼ���д���ϵ��ֵС��0.5������ֵ��Ϊ0����ͼƬ4�У�����չʾ��һ�����ڸ���Ҷͼ��Ͷ�Ӧ����ֵͼ������Ĵ���Ч�����ڸ���Ҷ��ֵͼ��F2�У�����Χ�������������������Ӱ���������������������G1ͼ���У����������ķ���ֱ�������Ƶķ�����Ϊ�������������ٶ���Ϊ�����������ķ���Ҳ����ֱ�������Ƶķ���ͼ4��a���ͣ�b������Ϊ��ȷ������Ҷ��ֵͼ������������ķ������ǽ�ÿ���������������һ��ֱ��ͼ����ֱ��ͼ�����У�����ͨ����-45�㵽45����Ϊ����ķ�Χ����ΪͼƬ��G1����������Ƶķ�����-45�㵽45�������Χ����ͼ5�У�ͼ��a������������ֱ��ͼ�����������ǵ����з���91�����ߣ�������֪������Ҷͼ��F2�����Ĵ�ֱ��Գƣ��������ֻ����������Ҷ��ֵͼ��F2��һ�������ֱ��ͼ��������ͼ5�У�����Ҷ��ֵͼ��F2��ͼ��b�����������ķ�����23����ͼ��C����������- 45��+ 45����������ֱ��ͼ�У�ʰȡ��չʾ������ͻ��ķ�����Ϣ��ͼ5��c����ʾ����ֱ��ͼ�ķ�ֵָ��23�������ǵõ���������ķ�����Զ�ȥ���÷������������Ӧ���ڸ���Ҷͼ��F1�ϡ������Ҷͼ��F1����DFT�任�õ�ȥ�������ͼ��G1����ͼ4��չʾ���Զ�ȥ���������ӡ�
3.1.3.ȥ��������������
��������ij����Զ�ʶ�������þֲ��������ͼ����Ϊ��ʼ�����ı����������������ַ��Ĵ��ڣ����������ڲ��Dz���������������������������۹����ҳ�������������������ͼ��IJ������ԣ�������ӱ����зdz����������������ˣ�Ϊ�����������������������������ڴ�СΪ3��3�ľֲ�Wiener�����˲��������Ҷ�ͼ��G1��G10�����Ӷ��õ�ȥ���������ͼ��G2��������û��ֱ�Ӷ�105ͼ�����������������ں������ͼ�����д���ʱ���ҵ�472����ѡ�ij���������105�������� + 367������������������Ӧ��ά���˲����������õ�329����ѡ����������105�������� + 224������������������ζ�������˲�������������Ҫ�ı���Ԫ�������������������Զ�ʶ��������Ρ����⣬����ǿͼ�ζԱȶȵij��϶���Ҫʹ�������˲�������Ϊ����ǿͼ��Աȶȵ�ͬʱҲ��������������ˣ�������Wiener�˲������������������Զ�ʶ����ڶ�����Wiener�˲�����ʹ��������ʶ��ϵͳ�����˺ܶ�ô������������Ĵ��ڣ����������Χʱ�����ᷢ��һЩ�����ı߽�����ͨ��ʹ��Wiener�����˲������õ��ɽ��ܵ���С�ij��������߽硣ͼ6������һЩ�Ƚ�ͼ������ӡ��ڳ����Զ�ʶ��ĵ����Σ����Dz��õ��Ƕ��������е�Bernsen�Ķ�ֵ������������ζ����Bernsen��ֵ���������������������ԡ���Щ������������ɫ�ߵ㲻�dz������������֣����˲��������˺ܴ����������ͼ7�У�����չʾ��һЩ�����Զ�ֵ������Ӱ���ͼ���������Dz�ʹ��Wiener�����˲�������ʱ�۲���ܵĺ�Ȧ�������ǿ��Կ���һЩ���������ڳ������������С�㡣
3.2.��ǿ�ԱȶȺͶ�ֵ������
3.2.1. Tamura-CLAHE�Աȶ���ǿ
���ڸ��ӵĻ�����������ҹ�������ڡ�ģ����������ͼ����ܴ��ڶԱȶȵ͵����⡣��ή�ͳ����Զ�ʶ���ں����������ܡ�ͬʱ�����Ӱ��Ҳ�ή������ͼ����ܼ��Ȼ�Աȶȡ�������Ϊ�����������ǿ�Աȶȵ��������ơ����ԣ�Ϊ�˳ɹ����Ƶ�����������Ҫ��ǿȥ���������ͼ��G2�ĶԱȶȡ����������Ƶ���߶ԱȶȻ��߲�֪����ǰͼ��ĶԱȶ�ֵ�ܿ��ܻᵼ���������⣬���������������Ӻ�ѡ����������������������ֳ��Ƶ��߽��������ˣ����Dz���Tamura-CLAHE�ķ�ʽ�����������ͼ��ĶԱȶȡ�Tamura�Աȶ�ֵ��һ��������֪�IJ���ͼ��Աȶ��ķ�����Tamura�ԱȲ������̣�Fcon��:
 ��2�� ��2��
Fcon��Tamura���Աȶ�ֵ��������ͼ��ǿ�ȵIJ��죬��Լ��ƽ�����ĵ�ʱ�̣�n = 0.25������������0 - 1��Χ�ڵĶԱȶ�ֵ����һ���棬CLAHE��һ�����еĶԱȶ���ǿ���������ǿ���ͨ��ֱ��ͼ��Ԥ��������任����֮ǰ������ǿ�Աȶȵ����ơ�Ϊ�����Ƽ���CLAHE������ʹ������Ĺ�ʽ��
 ��3�� ��3��
��1��ȥTamura��ֵ��������һ������div������div��һ���ij�������������Climitֵ�ķ�Χ��ʵ���������������������ʱ��div�����ֵ��200��������̻�������һ�ַ�ʽ�����ͼ��ĶԱȶȵͣ�����ǿ�Աȶȵ�ֵ�ļ���ܴ�֮���ͼ��ĶԱȶȸߣ�����ǿ�Աȶȵ�ֵ�ļ����С��������ʹ�öԱȶ�����CLAHE������ǿ��ȥ���������ͼ��G2�ĶԱȶȣ��Ӷ��õ�ϣ����ͼ��G3����
ͼ8��������ʹ��Tamura-CLAHE��������ͼ���һЩ���ӡ�
3.2.2.����ͻ��ھ�ֵ�Ķ�ֵ��
�ڻҶ�ͼ���У������ַ����ܶȺͱ����������������������ֲ�������������ζ�������ı��ͱ���֮��ĶԱȣ���������������ǿ��Ҳ��������ı仯��������ij����Զ�ʶ���У����Dz���һ���µĶ�ֵ���Ĺ��̣����þֲ���������Ϊ��ʼ�����������������ֵ�����ֻҶ�ͼ������оֲ����������ı�ǿ�ȣ��ڸ߶��ܼ��İ�ɫ���������ڶ�ֵ������ʱ������ʹ��һ����СΪS��S�Ĵ���
|
