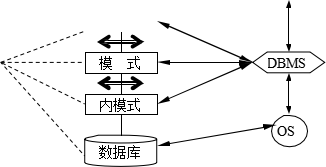
-top: 0px; margin-bottom: 0px; -ms-text-justify: inter-ideograph;">�� DBMS ���Ϸ��ԣ�������ģʽ����ȷ����Ӧ�Ĵ�ȡȨ�ޣ�
�� DBMS ������ģʽ/ģʽӳ��Ķ��壬ȷ��Ӧ�����ģʽ��¼��
�� DBMS ����ģʽ/��ģʽӳ��Ķ��壬ȷ��Ӧ�����������¼��
�� DBMS �� OS ���Ͷ�ȡ����������¼�����
�� OS ���� IO ����ִ�ж�������
�� OS �����ݴ����ݿ�Ĵ洢���͵�ϵͳ��������
�� DBMS ������ģʽ/ģʽӳ���壬�����û���Ҫ��ȡ�ļ�¼��ʽ��
�� DBMS �����ݼ�¼��ϵͳ���������͵�������û���������
�� DBMS ��Ӧ�ó�������ִ�������״̬��Ϣ��
1.4.3 ���ݿ����ϵͳ��ʵ�ַ���
1) N ����
⌦DBMS ģ����뵽�û����̣�DBMS ������ֶั�������ܴ���½���
2) 2N ����
⌦ÿ���û���һ�� DBMSshdow ���̺�һ����̨�����д����ֵ�Ľ��̡�
3) M��N ����
⌦2N �����ĸĽ�������N �û���M �� DBMS ���̣�M<N��
4) N��1 ����
⌦1 �� DBMS ����(����Ƴɶ��̵߳�)��N ���û����̣���Ϣ������
1.5 ���ݿ����Ӧ��
1.5.1 ���ݿ���Ƶ�Ŀ����ص�
➢ ���ݿ���Ƶ������ǣ��� DBMS ��֧���£�����Ӧ�õ�Ҫ��Ϊijһ���Ż���֯���һ���ṹ������ʹ�÷��㡢Ч�ʽϸߵ����ݿ⼰��Ӧ��ϵͳ��
➢ ���ݿ���ư������������ݣ��ṹ�����ݣ���ơ���Ϊ�����������
1.5.2 ���ݿ���Ʒ���
➢ �����ǣ�����ƺ��������
➢ ������Ʒ�����
• �°¶�����ƣ����������������ơ�����ơ��������
• S.B.Yao ��ƣ����������ģʽ���ɡ�ģʽ���ܡ�ģʽ�ع���ģʽ�������������
1.5.3 ���ݿ���Ʋ���
➢ ���裺�������������ṹ�����ṹ�������ṹ��ʵʩ������ά�� (P33 ͼ 1-36)
➢ ���ע������⣺
• ���û����룬�����û�������
• ��ֿ���ϵͳ�Ŀ������ԣ������������ȣ�
• �����ϵͳҪ���Ǿ�ϵͳ������ƽ��Ǩ�Ƶ���ϵͳ
1.5.4 ���ݿ�Ӧ��
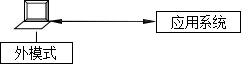
➢ �����û���������ͼ��
• �����û���Ӧ��ϵͳ
• ����Ա��DBMS ����ģʽ
• DBA/ϵͳ����Ա��DBMS ��ģʽ����ģʽ�����ݿ�
 �����û�
�����û�
 Ӧ�ó���Ա
Ӧ�ó���Ա
ϵͳ����Ա
��DBA��
ʹ�ö��� SPARC ����ṹ �������
➢ DBA ��ְ��
• ����붨�����ݿ�
• ���������û�ʹ�����ݿ�
• �ල�Ϳ������ݿ�����
• �Ľ����������ݿ�
• ת���ͻָ����ݿ�
• �ع����ݿ�
�ڶ��� ��ϵ���ݿ�
2.1 ��ϵ���ݿ����
➢ ��ϵ���ݿ�ϵͳ��֧�ֹ�ϵģ�͵����ݿ�ϵͳ
➢ ��ϵ�����ǽ����ڼ��ϴ������ۻ����ϵģ���ϵ�Ķ�����ֲ�����������ü��ϴ�������
➢ ��ϵģ�͵���Ҫ�أ�
• ��ϵ���ݽṹ����ά��
• ��ϵ������ѡ��ͶӰ�����ӡ���������������Ȳ�ѯ�Լ�����ɾ���ġ���ϵ�������ԣ�
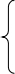 ��ϵ�������� ISBL
��ϵ�������� ISBL
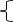 ��ϵ�������� Ԫ���ϵ�������� ALPHA��QUEL
��ϵ�������� Ԫ���ϵ�������� ALPHA��QUEL
���ϵ�������� QBE
���й�ϵ������ϵ����˫���ص������ SQL
• ������Լ����
1) �������ԣ�
2) ʵ�������ԣ�
3) ���������ԣ�
4) �Զ��������ԣ�
2.2 ��ϵ���ݽṹ
2.2.1 ��ϵ
1�� ������һ�������ͬ�������͵�ֵ�ļ��ϡ�ֵ�ĸ�����Ϊ��Ļ������磺�Ա�
��{�С�Ů}��������2
�·ݼ���{1��2��3��4��5��6��7��8��9��10��11��12}��������12 2�� �ѿ����˻�
• ���壺����һ����D1��D2������Dn���������ͬ������ D1D2����Dn �ĵѿ����˻�Ϊ��D1��D2��������Dn��{(d1��d2������dn)|di��Di��i��1��2������n} ���У�d1��d2������dn����Ϊһ��Ԫ�顣Ԫ���е�ÿ��ֵ di ��Ϊһ���������� Di��i��1��2������n��Ϊ�����������Ϊ mi��i��1��2������n�����ѿ����˻� D1��D2��������Dn �Ļ���Ϊ m����mi
• �� �� D1���������ϣ�{��һƽ��Ǯ�壬��Ӣ}
D2���Աϣ�{�У�Ů} D3�����伯�ϣ�{16��17��18} �� m��3��2��3��18
3�� ��ϵ(Relation)��
• ���壺�ѿ����˻� D1��D2��������Dn ����һ�Ӽ� D�������� D1��D2������Dn
�ϵĹ�ϵ���� R��D1��D2����Dn������ʾ��
���� R �ǹ�ϵ����n �ǹ�ϵ�ĶȻ�Ŀ��D���е�ÿ��Ԫ�أ�d1��d2������dn���ǹ�ϵ��һ��Ԫ�顣 n��1 �ǵ�Ԫ��ϵ��һԪ��ϵ��n��2 �Ƕ�Ԫ��ϵ
• ʵ��Ӧ���й�ϵ�����ǵѿ����˻�����������Ӽ����ɡ�
• ��ѡ�루candidade key������ϵ�е�ijһ�������ֵ��Ψһ�ر�ʶһ��Ԫ�飬�������Ӽ������ԣ���Ƹ�������Ϊ��ѡ�롣
• ���루primary key���������ѡ���У���ѡ������һ��Ϊ���롣
• �����ԣ�prime attribute������ѡ��ĸ������Զ���Ϊ�����ԡ�
• �������ԣ�none-key attribute�������������κκ�ѡ���е����ԡ�
• ȫ�루all-key������ϵģʽ���������Թ��������ϵģʽ�ĺ�ѡ�룬��Ϊȫ�롣
2.2.2 ��ϵģʽ
➢ ���壺��ϵ��������Ϊ��ϵģʽ��Relation schema��,һ���ʾΪ R(U,D,DOM,F) ���У�R �ǹ�ϵ����U ����ɸù�ϵ�����Լ��ϣ�D Ϊ������ U �����������Ե���DOM �����������ӳ�ϣ�F �����Լ����ݵ�������ϵ���ϡ�
2.2.3 ��ϵ���ݿ�
➢ ��һ����������ʵ�������������ʵ�弰ʵ������ϵ�Ĺ�ϵ�����ɵļ�����һ����ϵ���ݿ⣻
➢ ��ϵ���ݿ����ͺ�ֵ֮�֣���ϵ���ݿ����Ҳ�ƹ�ϵ���ݿ�ģʽ���ǶԹ�ϵ���ݿ������������������Ķ����Լ�����Щ���϶�������ɹ�ϵģʽ����ϵ���ݿ��ֵҲ��Ϊ��ϵ���ݿ⣬����Щ��ϵģʽ��ijһʱ�̶�Ӧ�Ĺ�ϵ�ļ��ϣ�
➢ ��ϵ���ݿ��ֵ���ϵ���ݿ�ģʽͨ��Ϊ��ϵ���ݿ⡣
2.3 ��ϵ��������
1. ��������
• ��ϵ�����Ե�ֵӦ�Ƕ�Ӧ���е�ֵ����������������Ƿ�Ϊ��ֵ��NULL����
2. ʵ��������
• ������ A �ǻ�����ϵ R �������ԣ��� A ����ȡ��ֵ
3. ����������
• ���루foreign key������ F �ǻ�����ϵ R ��һ����һ�����ԣ������� R ���루������ѡ�룩����� F �������ϵ S ������ Ks ���Ӧ����� F �ǻ�����ϵ R�����롣�� R �Dz��չ�ϵ��referencing relation����S �DZ����չ�ϵ��referenced
relation����
• �����ԣ��������飩F �ǻ�����ϵ R �����룬���������ϵ S ������ Ks ���Ӧ����ϵ R��S ��һ���Dz�ͬ�Ĺ�ϵ��������� R �е�ÿһ��Ԫ���� F �ϵ�ȡֵ���룺
1) ȡ��ֵ��F ��ÿ������ֵ��ȡ��ֵ�� 2) ���� S ��ij��Ԫ�������ֵ
4. �Զ���������
2.4 ��ϵ����
➢ ��ϵ������һ���ϵ������ɣ��Ƕ��ڹ�ϵ�IJ���������ϵ������һ��������ϵ��Ϊ�����Ķ�����������һ���µĹ�ϵ���ù�ϵ����ʵ�ֲ�ѯ��
➢ ��ϵ���������
• ��ͳ������������ȣ�����������ɣ����������ѿ�������
• ר�����������ѡ�� �� ͶӰ �� ���� �� ��
• �Ƚ�������� > �� < �� = ��
• ���������Ø �� ���� �Ż�
➢ ���õĹ�ϵ�����У�����������ѿ�������ͶӰ��ѡ�����ӡ���
➢ ������ϵ�����У�������ѿ�������ͶӰ��ѡ�������Ĺ�ϵ�������ͨ����������ʵ��
➢ ͬ���ϵ��������ͬ�Ķȣ���������ϵÿ������ȡֵ��ͬһ����
➢ Ϊ�˱���ķ��㣬�������¼Ǻţ�
1) ���ϵģʽ R��A1��A2������An��������һ����ϵΪ Rt��t��Rt ��ʾ t �� Rt��һ��Ԫ�顣t[Ai]���ʾԪ�� t ����Ӧ�� Ai ��һ������
2) �� A��{Ai1��Ai2������Aik}�� A1��A2������An ��һ���֣�k<=n���� A ��Ϊ�����У��飩�����С�t[A]=��t[Ai1]��t[Ai2]������t[Aik]����ʾԪ���������� A ��������ļ��ϡ�
3) R Ϊ n Ԫ��ϵ��S Ϊ m Ԫ��ϵ��tr��R��ts��S��tr �� ts ��ΪԪ�������
��Concatenation��������һ�� m��n �е�Ԫ�飬ǰ n ������Ϊ R �е�һ�� n Ԫ�飬�� m ������Ϊ S �е�һ�� m Ԫ�顣
4) ����һ����ϵ R��X��Z����X �� Z Ϊ�����飬���壺�� t[X]=x ʱ��x ��R �е���image set��Ϊ��
Zx��{t[Z]|t��R��t[X]=x}����ʾ R �������� X ��ֵΪ x ����Ԫ���� Z �������ϵķ����ļ��ϡ�
2.4.1 ��ͳ�ļ�������
➢ ���裺
R
|
Name
|
Sex
|
Age
|
|
Zhang
|
F
|
22
|
|
Wang
|
M
|
25
|
|
Lu
|
M
|
37
|
|
Chen
|
F
|
27
|
S
|
Name
|
Sex
|
Age
|
|
Zhang
|
F
|
22
|
|
Wang
|
M
|
25
|
|
Lu
|
F
|
30
|
➢ ����Union����ͬ���ϵ R �� S �IJ���Ϊ R��S���� R union S
���壺R��S={t|t��R �� t��S}ע��ȥ���ظ�Ԫ�顣R��S
|
Name
|
Sex
|
Age
|
|
Zhang
|
F
|
22
|
|
Wang
|
M
|
25
|
|
Lu
|
M
|
37
|
|
Chen
|
F
|
27
|
|
Lu
|
F
|
30
|
|
Sun
|
M
|
28
|
➢ ����Intersection����ͬ���ϵ R �� S �Ľ���Ϊ R��S���� R intersect S�� �� ��R��S��{ t|t��R �� t��S } ºR����R��S��ºS����S��R�� R��S
|
Name
|
Sex
|
Age
|
|
Zhang
|
F
|
22
|
|
Wang
|
M
|
25
|
➢ �Minus/Difference����ͬ���ϵ R ��S �IJ��Ϊ R��S �� R minus S
���壺R��S��{ t|t��R �� tÏS } R��S
|
Name
|
Sex
|
Age
|
|
Lu
|
M
|
37
|
|
Chen
|
F
|
27
|
➢ �ѿ�������Cartesian Product������ϵ R �� S �ĵѿ�������Ϊ R��S�����壺R��S��{ t��s|t��R�� s��S }
R:
S:
|
SNo
|
SN
|
Age
|
|
S-01
|
Huang
|
21
|
|
S-21
|
Lin
|
20
|
|
S-30
|
Shao
|
22
|
R��S:
|
CNo
|
CN
|
SNo
|
SN
|
Age
|
|
C-11
|
OS
|
S-01
|
Huang
|
21
|
|
C-11
|
OS
|
S-21
|
Lin
|
20
|
|
C-11
|
OS
|
S-30
|
Shao
|
22
|
|
C-21
|
DB
|
S-01
|
Huang
|
21
|
|
C-21
|
DB
|
S-21
|
Lin
|
20
|
|
C-21
|
DB
|
S-30
|
Shao
|
22
|
2.4.2 ר�ŵĹ�ϵ����
➢ ͶӰ��Projection����
��ϵ R �ϵ�ͶӰ�Ǵ� R ��ѡ����������ԣ�����ȥ���ظ�Ԫ�����һ���¹�ϵ�� ���ڵ�Ŀ���㡣������
ÕA(R)��{t[A]| t��R } A ΪR �е�����������
Student
|
SNo
|
SName
|
Sex
|
Age
|
|
S01
|
Wang
|
F
|
17
|
|
S02
|
Zhang
|
M
|
20
|
|
S03
|
Lin
|
M
|
18
|
|
S04
|
Sun
|
F
|
19
|
Sna=ÕSname��Age(Student)
|
SName
|
Age
|
|
Wang
|
17
|
|
Zhang
|
20
|
|
Lin
|
18
|
|
Sun
|
19
|
➢ ѡ��Selection����
�ֳ����ƣ�Restriction�����ڸ����Ĺ�ϵ R �У��������������Ԫ�飬���һ���¹�ϵ���¹�ϵ��ԭ��ϵͬ�࣬��ԭ��ϵһ���Ӽ���������
dF(R)={t| t��R �� F��t��=���桯 } F ��ʾ��������
Sa18��dage>=18��Student��
|
SNo
|
SName
|
Sex
|
Age
|
|
S02
|
Zhang
|
M
|
20
|
|
S03
|
Lin
|
M
|
18
|
|
S04
|
Sun
|
F
|
19
|
➢ ���ӣ�Jion����
��������ϵ�ĵѿ����˻���ѡȡ��������һ��������Ԫ�飬����µĹ�ϵ��������
R ¥ S ��{tr��ts| tr��R ��ts��S �� tr[A]qts[B]} º diq(r+j) (R��S) AqB
AqB ��ʾ R �ϵ����� A �� S �ϵ����� B ����q������q�DZȽ��������A��B �Ķ�������ҿɱȡ�������� AB �ֱ��� RS ��ϵ�ĵ� ij �У�R ��Ϊ r��
����
R
|
A
|
C
|
D
|
|
30
|
C1
|
D3
|
|
40
|
C2
|
D3
|
|
50
|
C3
|
D1
|
|
10
|
C4
|
D1
|
S
|
B
|
E
|
F
|
|
20
|
E1
|
F1
|
|
50
|
E2
|
F3
|
|
40
|
E3
|
F1
|
R ¥ S A>B
|
A
|
B
|
C
|
D
|
E
|
F
|
|
30
|
20
|
C1
|
D3
|
E1
|
F1
|
|
40
|
20
|
C2
|
D3
|
E1
|
F1
|
|
50
|
20
|
C3
|
D1
|
E1
|
F1
|
|
50
|
40
|
C3
|
D1
|
E3
|
F1
|
• ��ֵ���ӣ�equi��jion����qΪ������ʱ��Ϊ��ֵ���ӡ�
R ¥ S ��{tr��ts| tr��R ��ts��S �� tr[A]��ts[B]} AqB
• ��Ȼ���ӣ�Natioal Jion����������ϵ�о�����ͬ�����ԣ���������ͬ������������ֵ���ӡ���Ȼ������Ҫȡ���ظ��У�����ֵ���Ӳ���Ҫ��
R ¥ S ��{tr��ts| tr��R ��ts��S �� tr[A]��ts[A]}
➢ ������Division����
������ϵ R��X��Y���� S��Y��Z�������� X��Y��Z Ϊ�����飬R �е� Y ��S �е�
Y ���Բ�ͬ������������������ͬ���� R��S���� P��X����R��S���� P �� R ����������������Ԫ���� X �������ϵ�ͶӰ��Ԫ���� X �ϵķ���ֵ x ���� Yx ���� S �� Y ��ͶӰ�ļ��ϣ�������
R��S��{tr[X]|tr��R �� YxÊÕY��S��}
R��S º Õ1,2...r��s��R����Õ1,2...r��s����Õ1,2...r��s��R����S����R������
R
|
A
|
B
|
C
|
|
a1
|
b1
|
c2
|
|
a2
|
b3
|
c7
|
|
a3
|
b4
|
c6
|
|
a1
|
b2
|
c3
|
|
a4
|
b6
|
c6
|
|
a2
|
b2
|
c3
|
|
a1
|
b2
|
c1
|
S
 R��S��
R��S��
��Yx��a1={(b1,c2),(b2,c3),(b2,c1)} Yx��a2={(b3,c7),(b2,c3)} Yx��a3={(b4,c6)}
Yx��a4={(b6,c6)}
➢ �����ӣ�Outer Join����
��� R �� S ������Ȼ����ʱ���Ѹ�������Ԫ��Ҳ�������¹�ϵ�У��������ӵ����������ֵ��null�������ֲ�����Ϊ�������ӡ�������� R �и�������Ԫ�鱣�����¹�ϵ�г������ӣ��� S �и�������Ԫ�鱣�����¹�ϵ�г������ӡ�
➢ �ⲿ����Outer Union����
����ϵ R ��S ��ͬ�࣬���¹�ϵ�������� R �� S ��������ɣ���������ֻȡһ�Σ� �¹�ϵ��Ԫ�������� R �� S ��Ԫ�鹹�ɣ������������Ͼ���գ�null����
➢ �����ӣ�Semijoin����
��ϵ R �� S �İ����Ӷ���Ϊ R �� S ����Ȼ�����ڹ�ϵ R �����Լ��ϵ�ͶӰ������
R
S
|
B
|
C
|
D
|
|
b
|
c
|
d
|
|
b
|
c
|
e
|
|
a
|
d
|
b
|
|
e
|
f
|
g
|
R Outer Join S
|
A
|
B
|
C
|
D
|
|
a
|
b
|
c
|
d
|
|
a
|
b
|
c
|
e
|
|
c
|
a
|
d
|
b
|
|
b
|
b
|
f
|
null
|
|
null
|
e
|
f
|
g
|
R left Outer Join S
|
A
|
B
|
C
|
D
|
|
a
|
b
|
c
|
d
|
|
a
|
b
|
c
|
e
|
|
c
|
a
|
d
|
b
|
|
b
|
b
|
f
|
null
|
R right Outer Join S
|
A
|
B
|
C
|
D
|
|
a
|
b
|
c
|
d
|
|
a
|
b
|
c
|
e
|
|
c
|
a
|
d
|
b
|
|
null
|
e
|
f
|
g
|
R Outer Union S
|
A
|
B
|
C
|
D
|
|
a
|
b
|
c
|
null
|
|
b
|
b
|
f
|
null
|
|
c
|
a
|
d
|
null
|
|
null
|
b
|
c
|
d
|
|
null
|
b
|
c
|
e
|
|
null
|
a
|
d
|
b
|
|
null
|
e
|
f
|
g
|
R Semijoin S º ÕR��R ¥ S��
S Semijoin R º ÕS��R ¥ S��
2.4.3 *��ϵ��������Ӧ�þ���
➢ S��S����SN��SSEX��SAGE�� C��C����CN��TEACHER�� SC��S����C����GRADE��
➢ ����ѧϰ�γ̺�Ϊ C2 ��ѧ��ѧ����ɼ���
ÕS#��GRADE��d C#=��C2����SC������Õ1��3��d 2=��C2����SC����
➢ ����ѧϰ�γ̺�Ϊ C2 ��ѧ��ѧ����������
ÕS#��SN��d C#=��C2����S¥SC����
➢ ����ѡ�γ���Ϊ Maths ��ѧ��ѧ����������
ÕS#��SN��d CN=��Maths����S¥SC¥C����
➢ ����ѡ�γ�Ϊ C2 �� C4 ��ѧ��ѧ��
ÕS#��d C#=��C2�� �� C#=��C4����SC����
➢ ��������ѡ�γ�Ϊ C2 �� C4 ��ѧ��ѧ��
ÕS#��d 1��4 �� 2=��C2�� �� 5=��C4����SC��SC��
��d S#,C#��SC����d C#=��C2�� �� C#=��C4����C��
➢ ������ѡ�� C2 �γ̵�ѧ�����������䡣
ÕSN��SAGE ��S����ÕSN��SAGE��d C#=��C2����SC¥S����
➢ ����ѡ��ȫ���γ̵�ѧ��������
ÕSN��S ¥��ÕS#��C#��SC����Õ C#��C�� �� ��
➢ ������ѧ�γ̰���ѧ�� S3 ��ѧ�γ̵�ѧ��ѧ�š�
ÕS#��C#��SC����Õ C# ��d S#=��S3����SC����
2.5 ��ϵ����**
2.5.1 Ԫ���ϵ�������� ALPHA
2.5.2 ���ϵ�������� QBE
2.6 ��ϵ���ݿ����ϵͳ
➢ ��ϵ���ݿ����ϵͳ��ƹ�ϵϵͳ
➢ һ�����ݿ����ϵͳ�ɳ�Ϊ��ϵϵͳ����С����
• ��ϵ���ݿ⣨����ϵ���ݽṹ��
• ֧��ѡ��ͶӰ����������
➢ E.F.Codd ˼��Թ�ϵϵͳ�ķ��ࣺ��P63 ͼ 2-5��
• ��ʽϵͳ����ֻ�ǹ�ϵ���ݽṹ����֧�ּ��ϼ�����
• ��С��ϵϵͳ��֧�ֹ�ϵ�ṹ��ѡ��ͶӰ�����Ӽ��ϲ���
• ��ϵ�걸ϵͳ��֧�ֹ�ϵ�ṹ�����й�ϵ��������
• ȫ��ϵϵͳ��֧�ֹ�ϵģ�͵�����������
������ ��ϵ���ݿ����ѯ���� SQL
3.1 SQL ����
➢ SQL(Standard/Structured Query Language)�ǹ�ϵ���ݿ����
➢ 1974 �� Boyce �� Chamberlin �����
➢ 1986 �� 10 �£��������ұ��֣�American National Standard Institute ANSI��������һ���� ANSI X3.135-1986�����ʱ�����֯��International Organization for Standardization ISO��Ҳͨ����һ���� SQL��86��
➢ 1989 �� ANSI �ٴι����� ANSI X3.135-1989 ��ISO ��Ӧ SQL��89
➢ 1992 �� ANSI �ٴι����� ANSI X3.135-1992 ��ISO ��Ӧ SQL��92 (SQL 2)
➢ 1999 �꣬ISO ���� SQL-1999��SQL99��SQL3��
➢ 2003 �꣬ISO ���� SQL-2003
3.1.1 SQL ���Ե����
➢ ���ݶ��壨DDL Data Definition/Description Language ����
• �������ݿ�����ṹ����������������ͼ�������ȡ�
➢ ���ݲ��ݣ�DML Data Manipulation Language����
• ������ѯ���£������ְ������롢ɾ�����ġ�
➢ ���ݿ��ƣ�DCL Data Control Language ����
• ��Ȩ�������Թ���������������Ƶȡ�
➢ Ƕ��ʽ SQL��ESQL����������������ʹ�� SQL �Ĺ���
3.1.2 SQL ���Ե��ص�
➢ �ۺ�ͳһ���� DDL��DML��DCL ��һ�壬���Է��ͳһ
➢ �߶ȷǹ��̻���ֻ��Ҫ���Ŀ�꣬���������� DBMS ���
➢ ���ϵIJ�����ʽ����������ѯ�����������Ԫ��ļ���
➢ ��ͳһ����ṹ�ṩ����ʹ�÷�ʽ���Ժ�ʽ��Ƕ��ʽ
➢ ���Լ�࣬��ѧ���ã���ʹ�� 11 ���ؼ��ʣ�
• DDL��create drop alter
• DML��select insert delete update
• DCL��grant revoke commit rollback
3.2 ���ݶ������ԣ�DDL��
3.2.1 ���塢ɾ�����Ļ�����
➢ ������������
CREATE TABLE <����> ��<����><��������>[�м�Լ������] [,<����><��������>[�м�Լ������]... ...] [,<����������Լ������>]);
• CREATE TABLE S��
S�� CHAR��5�� NOT NULL UNIQUE�� SN CHAR��20����
SA INT��
SD CHAR��3��, PRIMARY KEY (S#)
����
➢ �ı����
ALTER TABLE <����>
[ADD <������><��������>[�м�Լ������]] [DROP <������Լ������>]
[MODIFY <����><��������>];
• �ڱ� S ��������ѧ����
ALTER TABLE S ADD SCome DATE��
• ALTER TABLE S MODIFY SA SMALLINT��
• ALTER TABLE S DROP UNIQUE(S#)��
➢ ɾ�������
DROP TABLE <����> ��
• DROP TABLE S��
3.2.2 ������ɾ������
➢ �����Ľ�����
• ���
CREATE [UNIQUE][CLUSTER] INDEX <������>
ON <����>��<���� 1>[<����>][��<���� 2><����>... ...]��
<����>������ ACS �� DESC
• CREATE UNIQUE INDEX S_S# ON S(S#) CREATE UNIQUE INDEX C_C# ON C(C#)
CREATE UNIQUE INDEX SC_S#_C# ON SC(S# ASC,C# DESC)
➢ ������ɾ����
• ���
DROP INDEX [<����>.]<������>
• DROP INDEX [S.]S_S#
3.3 SQL �����ݲ�ѯ��DML��
➢ ��ϵ��������ʽ��
ÕA1,A2,.....An��d F��R1��R2��... ...��Rn����
➢ SQL ��䣺
• SELECT A1��A2��......An FROM R1��R2��... ...Rm WHERE F
• ��ϸ���
SELECT [ALL|DISTINCT] {*|<Ŀ�����ʽ 1> [,<Ŀ�����ʽ 2> ... ...]}
FROM <��������ͼ�� 1> [��<��������ͼ�� 2>]... ... [WHERE <��������ʽ>]
[GROUP BY <��������ʽ 1>[��<��������ʽ 2>]] [HAVING <��������ʽ> ] [ORDER BY <��������ʽ 1> [ASC|DESC]], <��������ʽ 2> [ASC|DESC]]
• ִ�й��̣�
1) �Ȱ� WHERE �Ӿ������� FROM �Ӿ�ָ���ı�/��ͼ���ҳ�����������Ԫ�飨ѡ��;
2) �ٰ� SELECT �Ӿ��е�Ŀ�����ʽѡ���Ԫ���е����ԣ��γɽ������ͶӰ����
3) ���� GROUP �Ӿ䣬�����<��������ʽ>��ֵ���飬��<��������ʽ
>ֵ��ȵ�Ԫ��Ϊһ���飬ͨ������ÿ����ʹ�þۺϺ�����
4) ��� GROUP �Ӿ�� HAVING �Ӿ䣬�������ǣ������������������
5) ��� ORDER �Ӿ䣬�����<��������ʽ 1>��ֵ����������С�
3.3.1 ������ѯ��
���裺S��S#��SN��SS��SA��SD�� C��C#��CN��CP��CR�� SC��S#��C#��GR��
➢ ѡȡ���е�ijЩ�У���ͶӰ����
• ��ָ����
SELECT S#,SN FROM S
• ��ȫ����
SELECT * FROM STUDENT
• �龭���������
SELECT SN��2002-SA FROM S
➢ ѡ����е�����Ԫ�飬��ѡ������
• ����ȡֵ�ظ���
SELECT DISTINCT SD FROM S
• ��ѯ����������Ԫ��
1) �Ƚϴ�С��<��<= ��>��>=��=��<>
SELECT SN��SA FROM S WHERE SD����CS�� SELECT * FROM S WHERE SA<20
2) ȷ����Χ��BETWEEN... AND
SELECT * FROM S WHERE SA BETWEEN 20 AND 21
3) ȷ�����ϣ�IN
SELECT * FROM S WHERE SD IN (��CS��,��IS��,��MA��)
4) �ַ�ƥ�䣺LIKE��ת���ַ���\��
SELECT * FROM S WHERE S# LIKE ��TB%�� SELECT * FROM S WHERE SN LIKE ����_��
5) �漰��ֵ�IJ�ѯ��IS NULL
SELECT * FROM SC WHERE GR IS NULL
6) ����������ѯ��
SELECT * FROM S WHERE SD=��CS�� AND SA<20
➢ ��ѯ�������ORDER BY <�ֶα���ʽ> ASC|DESC
SELECT * FROM SC WHERE C#=��C3�� ORDER BY GR DESC
➢ ʹ�ü�(�ۺ�)������
��Ҫ�У�COUNT��[DISTINCT] *����COUNT��[DISTINCT] <�ֶ�>��
SUM��<�ֶ�>����AVG��<�ֶ�>����MAX��<�ֶ�>����MIN��<�ֶ�>�� SELECT COUNT(*) FROM S
SELECT COUNT(DISTINCT S#) FROM SC SELECT AVG(GR) FROM SC WHERE S#=��95001�� SELECT MAX(GR) FROM SC WHERE C#=��1��
➢ ��ѯ���飺GROUP BY
SELECT C#��COUNT(C#) FROM SC GROUP BY C#
SELECT S# FROM SC GROUP BY S# HAVING COUNT(*) >3 ����ѡ��>3 ��
�Ŀ�ѧ��ѧ�š�
3.3.2 ���Ӳ�ѯ��
➢ ��ֵ��ǵ�ֵ���Ӳ�ѯ����Ȼ����
SELECT S.*��SC.* FROM S��SC WHERE S.S# = SC.S#
➢ ���������� C
|
C��
|
CN
|
CP
|
CR
|
|
1
|
DB
|
5
|
4
|
|
2
|
MA
|
|
2
|
|
3
|
IS
|
1
|
4
|
|
4
|
OS
|
6
|
3
|
|
5
|
DataStruct
|
7
|
4
|
|
6
|
DataProcess
|
|
2
|
|
7
|
PASCAL
|
6
|
4
|
• ����ÿ�ſεļ��Ԥ�Ρ�
SELECT f.C#, s.CP FROM C f,C s WHERE f.CP=s.C#
➢ ������
• �г�����ѧ��������������û��ѡ��Ҳ�г��������Ϣ(��������)��
SELECT S����SN��SS��SA��SD��C����GR
FROM S��SC WHERE S.S# *=SC.S# (T-SQL � SYBASE)
SELECT S����SN��SS��SA��SD��C����GR
FROM S��SC WHERE S.S# =SC.S#������ ��PL/SQL � ORACLE��
SELECT S����SN��SS��SA��SD��C����GR
FROM S LEFT OUTER JION SC ON S.S#=SC.S# (MYSQL ��MSSQL)
➢ ������������
• ����ѡ�γ̺š�C2���ҳɼ��� 90 �����ϵ�����ѧ����
SELECT S.S# ,SN FROM S,SC
WHERE S.S# = SC.S# AND SC.C#=��C2�� AND SC.GR>=90
• ����ÿ��ѧ��ѡ�Ŀγ�������ɼ�SELECT S.S#,SN,C.CN,SC.GR from S,SC,C WHERE S.S# = SC.S# AND SC.C# = C.C#
3.3.3 Ƕ�ײ�ѯ��
➢ �� IN ν�ʵ��Ӳ�ѯ
• �����롰������ͬ��һϵ��ѧ����Ϣ��
SELECT S#��SN��SD FROM S
WHERE SD IN��SELECT SD FROM S WHERE SN������������
• ��������ͨ����������ʵ�֣�
SELECT s1.S#, s1.SN, s1.SD FROM S s1, S s2 WHERE s1.SD = s2.SD AND s2.SN=��������
• ����ѡ���˿γ�����Ϊ����Ϣϵͳ����ѧ��ѧ�ź�������
SELECT S#, SN FROM S WHERE S# IN ( SELECT S# FROM SC WHERE C# IN (SELECT C# FROM C WHERE CN=����Ϣϵͳ��) )
• ����ͬ��������������ʵ�֣�
SELECT S#, SN FROM S , SC ,C
WHERE S.S# = SC.S# AND SC.C# = C.C# AND C.CN=����Ϣϵͳ��
➢ ���Ƚ�������Ӳ�ѯ
��ȷ���Ӳ�ѯ�ķ���ֵ��Ψһʱ������ʹ�ñȽ������(ע���Ӳ�ѯ�ڱȽϷ���)��
SELECT S# , SN FROM S
WHERE SD=(SELECT SD FROM S WHERE CN=��������)
➢ �� ANY �� ALL ���Ӳ�ѯ���Ӳ�ѯ���ض�ֵʱ�ã�
• ��������ϵ�б� IS ϵ��һѧ������С��ѧ������SELECT S����SN FROM S WHERE SA < ANY �� SELECT SA FROM S WHERE SD����IS����
AND SD<>��IS�� ORDER BY SA DESC
�ȼ��ڣ�
SELECT S����SN FROM S WHERE SA < �� SELECT MAX��SA�� FROM S WHERE SD����IS���� AND SD <> ��IS��
ORDER BY SA DESC
• ��������ϵ�б� IS ϵ����ѧ�����䶼С��ѧ������SELECT S����SN FROM S WHERE SA < ALL �� SELECT SA FROM S WHERE SD����IS����
AND SD<>��IS�� ORDER BY SA DESC
�ȼ��ڣ�
SELECT S����SN FROM S WHERE SA < �� SELECT MIN��SA�� FROM S WHERE SD����IS���� AND SD <> ��IS��
ORDER BY SA DESC
➢ �� EXISTS ���Ӳ�ѯ���������κ����ݣ�ֻ���� Ture �� False��
• ��������ѡ���˿γ̺�Ϊ��C01����ѧ������
SELECT SN FROM S WHERE EXISTS��
SELECT * FROM SC WHERE S# = S.S# AND C# = ��C01����
ע�⣺�������Ӳ�ѯ�IJ�ѯ������������㸸��ѯ���ƴ����ѯΪ����Ӳ�ѯ
��corelated subquery�����ȼ�����ʵ�֣�
SELECT SN FROM S��SC WHERE S.S# = SC.S# AND C# = ��C01��
• SQL ��û��("x)p ����ת��Ϊ¬($x(¬p))�������ѡ����ȫ���γ̵�ѧ������û��һ�ſ�û��ѡ��ѧ����
SELECT SN FROM S WHERE NOT EXISTS�� SELECT * FROM C WHERE NOT EXISTS ��
SELECT * FROM SC WHERE C���� C.C# AND S# = S.S#����
• p->q Ӧ���ȼ�Ϊ¬p��q ���������ѡ����ѧ�� S001 ѡ��ȫ���γ̵�ѧ������ p=��ѧ�� S001 ѡ���� y�� q����ѧ�� x ѡ���� y��
("y)��p->q��=¬$y(¬(p->q))= ¬$y(¬(¬p��q))= ¬$y(p��¬q))����������ôһ�ſγ̣�ѧ�� S001 ѡ���˶� x û��ѡ��
SELECT SN FROM S WHERE NOT EXISTS(SELECT * FROM SC SC2 WHERE S# = ��S001�� AND NOT EXISTS ( SELECT * FROM SC WHERE C# = SC2.C# AND S# = S.S#) )
3.3.4 ���ϲ�ѯ��
➢ ʹ�ý���������ļ���������INTERSECT ��UNION��MINUS
• �����������ѧϵ�����䲻���� 19 ���ѧ��
SELECT * FROM S WHER SD=��CS�� UNION
SELECT * FROM S WHERE SA<��19
�ȼ��ڣ�
SELECT * FROM S WHERE SD����CS�� OR SA <=19
• ����ѡ���˿γ̺�Ϊ C01 �� C02 ��ѧ��ѧ��SELECT S# FROM SC WHERE C������C01�� UNION
SELECT S# FROM SC WHERE C������C02��
�ȼ��ڣ�
SELECT S# FROM SC WHERE C�� IN����C01������C02����
• ����ͬʱѡ���˿γ̺�Ϊ C01 �� C02 ��ѧ��ѧ��SELECT S# FROM SC WHERE C������C01�� INTERSECT
SELECT S# FROM SC WHERE C������C02��(�� ORACLE)
�ȼ��ڣ�
SELECT S# FROM SC WHERE C# = ��C01�� AND S# IN ( SELECT S# FROM SC WHE, RE C# = ��C02��)
• ����ѡ���˿γ̺�Ϊ C01 ��δѡ�� C02 ��ѧ��ѧ�š�SELECT S# FROM SC WHERE C������C01�� MINUS
SELECT S# FROM SC WHERE C������C02��(�� ORACLE)
�ȼ��ڣ�
SELECT S# FROM SC WHERE C������C01��AND S�� NOT IN�� SELECT S# FROM SC WHERE C������C02����
3.4 SQL �����ݸ��£�DML��
3.4.1 ���ݲ��룺
➢ ���뵥��Ԫ��
• ���
INSERT INTO <����>[ (<���� 1> [, <���� 2>]......)]
VALUES(<���� 1>[,<���� 2>]......)
• INSERT INTO S VALUES����S001�����������������С���18����IS����
➢ �����Ӳ�ѯ���
• ���
INSERT INTO <����> [ (<���� 1> [, <���� 2>]......)]
�Ӳ�ѯ
• Ϊ����ѧ������һ��ѡ�� C01 �γ̵ļ�¼
INSERT INTO SC SELECT S# , ��C01��,null FROM S
3.4.2 �����ģ�
➢ ���
UPDATE <����> SET <����>��<����ʽ>[, <����>��<����ʽ>]...... [WHERE <����>];
➢ ��ijһ��Ԫ���ֵ
• ��ѧ�� S001 �������Ϊ 22 ��
UPDATE S SET SA=22 WHERE S# =��S001��
➢ �Ķ��Ԫ���ֵ
• �����е�ѧ���������� 1 ��
UPDATE S SET SA��SA��1
➢ ���Ӳ�ѯ�������
• ���������ѧϵ���е�ѧ���ɼ�����
UPDATE SC set GR=0 where S# in (SELECT S# from S where SD=��CS��)
��ͬ�� DBMS ����ʹ�� join ������Ӳ�ѯʵ��ͬ�����ܣ� UPDATE SC SET GR=0 (����Ӳ�ѯ oracle ֧��) WHERE ��CS�� = (SELECT SD FROM S WHERE S# = SC.S#)
UPDATE a set GR=0 from S��SC a where S.S#=a.S# and S.SD=��CS��(SYBASE ��) UPDATE S,SC set SC.GR=0 where S.S#=SC.S# and S.SD=��CS�� (mysql ��)
➢ �IJ��������ݿ��һ����
• ijѧ������ѧҪ��ѧ��
UPDATE S SET S������S002�� WHERE S������S001�� UPDATE SC SET S������S002�� WHERE S������S001��
���뱣֤���ݿ��һ���ԣ�����������
3.4.3 ����ɾ����
➢ ���
DELETE FROM <����> [WHERE <����>];
➢ ɾ��ijһ��Ԫ���ֵ
• ɾ��ѧ��Ϊ S001 ��ѧ��
DELETE FROM S WHERE S������S001��
➢ ɾ�����Ԫ���ֵ
• ɾ������ѧ����ѡ�μ�¼
DELETE FROM SC
➢ ���Ӳ�ѯ��ɾ�����
• ɾ���������ѧϵ����ѧ����ѡ�μ�¼
DELETE FROM SC WHERE ��CS������
SELECT SD FROM S WHERE S����SC.S�� �� (����Ӳ�ѯ)
DELETE from SC where S# in (SELECT S# from S where SD=��CS��)
3.5 ��ͼ
➢ ��ͼֻ��һ�����ڣ������������ڻ�����
3.5.1 ������ͼ
1. ������ͼ
➢ ���
CREATE VIEW <��ͼ��> [(<���� 1>[��<���� 2>......])]
AS <�Ӳ�ѯ>
[WITH CHECK OPTION]
• ����������ֵ������
1) �Ӳ�ѯ��Ŀ�����Ǽ������ȣ����ǵ�������
2) �������ʱ����ͬ��������Ϊ��ͼ�ֶ�
3) ��Ҫ����ͼ�������µ�����
• WITH CHECK OPTION ��ʾ����ͼ����ʱ�Զ���֤�Ӳ�ѯ������
• ����ѧ����ͼ
CREATE VIEW IS_S AS SELECT S#, SN , SA FROM S WHERE SD=��IS��
• �����Ӽ���ͼ����һ����ͼ�Ǵӵ��������������ģ�����ֻ��ȥ���˻�������ijЩ�к�ijЩ�У����������룬�������Ӽ���ͼ��
• ������Ϣϵѡ���� C1 �ſγ̵�ѧ����ͼ��
CREATE VIEW IS_S1 (S#, SN ,GR) AS
SELECT S.S# ,SN ,GR FROM S, SC
WHERE S.S# = SC.S# AND S.SD=��IS�� AND SC.C# = ��C1��
➢ ��ͼ֮�Ͽ��Խ�����ͼ��
• ������Ϣϵѡ���� C1 �γ��ҳɼ��� 90 ���ϵ�ѧ����ͼ
CREATE VIEW IS_S2 AS
SELECT S#, SN, GR FROM IS_S1 WHERE GR>=90
➢ ��ͼ����������
• ����һ����ӳѧ���������µ���ͼCREATE VIEW BT_S��S����SN��SB�� AS
SELECT S#, SN,2003��SA FROM S
• ����һ��ѧ��ѧ�ź�ƽ���ɼ�����ͼCREATE VIEW S_G��S����AVG_GR�� AS
SELECT S#, AVG(GR) FROM SC GROUP BY S#
• ����һ��Ůѧ������ͼ
CREATE VIEW S_F��S����SN��SS��SA��SD�� AS
SELECT * FROM S WHERE SS=����
����ͼ�� S ���ṹ�ı�ʱ�����������취��ȥ����˵�����*Ϊ�б�
2. ɾ����ͼ
➢ ���
DROP VIEW <��ͼ��>
• ɾ����ͼ DROP VIEW IS_S;
3.5.2 ��ѯ��ͼ
➢ �Ѷ���ͼ�IJ�ѯת��Ϊ�Ի������IJ�ѯ��Ϊ��ͼ������(View Resolution)��
• SELECT S����SA FROM IS_S WHERE SA <20
������
SELECT S# ,SA FROM S WHERE SD=��IS�� AND SA <20
• SELECT * FROM S_G WHERE AVG_GR>90
������
����SELECT S#, AVG(GR) FROM SC WHERE AVG(GR)>90 GROUP BY S#
�ԣ�SELECT S#, AVG(GR) FROM SC GROUP BY S# HAVING AVG(GR)>90
3.5.3 ������ͼ
➢ ��ͼ���ģ�
• ����Ϣϵѧ����ͼ��ѧ��Ϊ S001 ��ѧ��������Ϊ�������� UPDATE IS_S SET SN=��������WHERE S������S001�� ��ͼ���⣺
UPDATE S SET SN=��������WHERE S������S001��AND SD����IS��
➢ ��ͼ�IJ��룺
• ����Ϣϵѧ����ͼ�в����¼
INSERT INTO IS_S VALUES����S001��������������20��
��ͼ���⣺
INSERT INTO S VALUES����S001��������������NULL��20����IS����
➢ ��ͼ��ɾ����
• ����Ϣϵѧ����ͼ�в����¼
DELETE FROM IS_S WHERE S������S001��
��ͼ���⣺
DELETE FROM S WHERE S������S001��AND SD����IS��
➢ ijЩ���ۺ�/����������ͼ�Dz����ĵģ���
����UPDATE S_G SET AVG_GR��80 WHERE S������S001��
➢ �����и��µ���ͼ����db2 �У���
1) ���������ϻ�������������ͼ
2) ��ͼ���ֶ����Գ��������ʽ��ֻ���� DELETE
3) ��ͼ���ֶ����Լ�����
4) ��ͼ�к��� GROUP BY �Ӿ�
5) ��ͼ�к��� DISTINCT ���
6) ��ͼ������Ƕ�ײ�ѯ�����ڲ��ѯ�漰����������ͼ�Ļ�����
7) ���������µ���ͼ�϶������ͼ
3.5.4 ��ͼ����;
➢ ��ͼ�ܼ��û��IJ���
➢ ��ͼ����ʹ�û���Ƕȿ���ͬһ����
➢ ��ͼ���ع����ݿ��ṩ��һ������������
• S��S����SN��SS��SA��SD����Ҫ���ΪSX��S����SN��SS��SA����SY��S���� SD�������ͨ����ͼ����֤Ӧ�ò���ı�
CREATE VIEW S AS SELECT SX.S����SN��SS��SA��SD FROM SX��SY WHERE SX.S����SY.S��
➢ ��ͼ�ܶ������ṩ��ȫ����
3.6 ���ݿ������ԣ�DCL��
3.6.1 ��Ȩ
➢ ���
GRANT {ALL PRIVILEGES|<Ȩ��>[,<Ȩ��>... ...]}
[ON <��������> <������>]
TO {PUBLIC|<�û�>[,<�û�>]... ...} [WITH GRANT OPTION];
• ʾ����
GRANT SELECT ON TABLE S TO USER1;
GRANT ALL Privileges ON TABLE S��C TO U2��U3; GRANT SELECT ON TABLE SC TO PUBLIC; GRANT UPDATE(SD),SELECT ON TABLE S TO U4;
GRANT INSERT ON TABLE SC TO U5 WITH GRANT OPTION; GRANT CREATETAB ON DATABASE S_C TO U8;
3.6.2 �ջ�Ȩ��
➢ ���
REVOKE {ALL PRIVILEGES|<Ȩ��>[,<Ȩ��>... ...]}
[ON <��������> <������>]
FROM {PUBLIC|<�û�>[,<�û�>]... ...}��
• ʾ����
REVOKE SELECT ON TABLE SC FROM PUBLIC; REVOKE UPDATE(SD),SELECT ON TABLE S FROM U4; REVOKE INSERT ON TABLE SC FROM U5;
3.7 Ƕ��ʽ SQL ����
➢ SQL �����Ƿǹ��̵ģ���Ӧ�ô���ǹ��̻��ģ���ͨ�����������ֲ� SQL ���̿��ƵIJ��㣬�� SQL Ƕ��(Embedded SQL )�����ԣ��������ԣ���ִ�С�
3.7.1 Ƕ��ʽ SQL ��һ����ʽ
➢ ����Ƕ��ʽ SQL �Ĵ�����DBMS һ�������ִ�����ʽ��
• Ԥ����
• �ĺ��������������Դ��� SQL
➢ һ����ʽ��EXEC SQL <SQL ���>��
➢ Ƕ��ʽ SQL ���������ò�ͬ��Ϊ���ࣺ��ִ������˵������䡣��ִ�������� DDL��DML��DCL������ SQL ���Ӧ����������������������ͬһ�ط���
3.7.2 Ƕ��ʽ SQL �����������֮���ͨ��
➢ ���ݿ����Ԫ�������Թ�����Ԫ֮���ͨ�Ű�����
• �������Դ��� SQL ����ִ��״̬
• �������� SQL ����ṩ����
• �� SQL ����ѯ���ݿ����������Խ�һ��������Ҫͨ�� SQLCA�����������α���ʵ�֡�
3.7.2.1 SQL ͨ����
➢ SQLCA��SQL Communication Area����һ�����ݽṹ��������䣺
• EXEC SQL INCLUDE SQLCA��
➢ SQLCODE ��ӳÿ��ִ�� SQL ���Ľ����
3.7.2.2 ������
➢ ��Ҫ���ܣ�Ƕ��ʽ SQL ����ʹ�������Եı�����������������
➢ ���ࣺ���롢�����������ָʾ����
➢ ʹ�÷�����
• ���������������ڶ��������壨BEGIN DECLARE SECTION��END DECLARE SECTION��
• ������ SQL ���������ʽ�ĶԷ�����
• �� SQL ����У�������ǰҪ�ӡ�����,�����������в��ؼӡ�
• ָʾ��������Ϊ�����������ֵ��ָʾ��������Ƿ��ֵ��
3.7.2.3 �α�
➢ ʹ��ԭ��SQL ��������ϵģ����������������¼��
➢ �����Ժ� SQL ���Եķֹ���
• SQL ���Ը���ֱ�������ݿ��
• �������������Ƴ��������Լ��� SQL ��ִ�н����һ������
• SQL �������������������Խ���ִ�в����������ݿ⣭>SQL ���Ե�ִ��״̬�� DBMS ���� SQLCA->�����Դ� SQLCA ȡ��״̬��Ϣ���ݴ˾�����һ��������
• SQL ��ִ�н��ͨ�����������α괫�������Դ�����
3.7.3 ��ʹ���α��SQL ���
➢ ��ʹ���α������У�
• ˵�������
• ���ݶ������
• ���ݿ������
• ��ѯ���Ϊ����¼�� SELECT ���
• �� CURRENT ��ʽ�� UPDATE ���
• �� CURRENT ��ʽ�� DELETE ���
• INSERT ���
3.7.3.1 ˵�������
➢ ������
• EXEC SQL INCLUDE SQLCA��
• EXEC SQL BEGIN DECALRE SECTION��
• EXEC SQL END DECALRE SECTION��
3.7.3.2 ���ݶ������
➢ ����
• EXEC SQL CREATE TABLE S
��S�� char��10���� SN char��10����
SS char��2����
SA int��
SD char��5������
• EXEC SQL DROP TABLE��
➢ ���ݶ�������в�����ʹ����������
• ��������EXEC SQL DROP TABLE :tablename��
3.7.3.3 ���ݿ������
➢ ����
• EXEC SQL GRANT SELECT ON TABLE S TO U1
3.7.3.4 ��ѯ���Ϊ������¼ SELECT ���
➢ ���
EXEC SQL SELECT [ALL|DISTINCT] {*|<Ŀ�����ʽ 1> [,<Ŀ�����ʽ
2> ... ...]} INTO <������ 1> [<ָʾ���� 1>][,<������ 1> [<ָʾ���� 1>]......]
FROM <��������ͼ�� 1> [��<��������ͼ�� 2>]... ... [WHERE <��������ʽ>]
[GROUP BY <��������ʽ 1>[��<��������ʽ 2>]] [HAVING <��������ʽ> ] [ORDER BY <��������ʽ 1> [ASC|DESC][, <��������ʽ 2> [ASC|DESC]]
➢ ����
EXEC SQL SELECT S#, SN INTO :sno, :sn FROM S WHERE S# =:GivenSno
➢ ע�⣺
• into��where �� having �Ӿ��о�����ʹ������������Ҫ����������
• ����ֵij��Ϊ NULL ʱ��ϵͳ�Ὣָʾ������ֵΪ��1�����������䡣
• ���ѯ���û�����������ļ�¼���� DBMS ��sqlcode ֵΪ 100�������н��Ϊ 0��
• ������ֹ���������������SQLCA �а���������Ϣ��
3.7.3.5 �� CURRENT ��ʽ�� UPDATE ���
➢ ����
• ���γ� C01 ȫ�����
EXEC SQL UPDATE SC SET GR=GR+:Raise WHERE C# =��C01��
• ��������ij��ѧ���ɼ�
EXEC SQL UPDATE SC SET GR=��newgr WHERE S# =��S001��
• �������ϵ����ͬѧ�ɼ��ÿ�
grid����1
EXEC SQL UPDATE SC SET GR=��newgr ��grid
WHERE S# IN ��SELECT S�� FROM S WHERE SD����CS����
�ȼۣ�
EXEC SQL UPDATE SC SET GR=NULL
WHERE S# IN ��SELECT S�� FROM S WHERE SD����CS����
3.7.3.6 �� CURRENT ��ʽ�� DELETE ���
➢ ����
• ɾ��ijѧ����ѡ�����
EXEC SQL DELETE FROM SC WHERE S��IN
��SELECT S�� FROM S WHERE SN����sname�� ���ߣ�
EXEC SQL DELETE FROM SC WHERE ��sname��
��SELECT SN FROM S WHERE S.S# = SC.S#��
3.7.3.7 INSERT ���
➢ ����ij��ѧ��ѡ����һ�ſγ�
grid����1��
EXEC SQL INSERT INTO SC VALUES ����sno����cno����gr ��grid�������ߣ�
EXEC SQL INSERT INTO SC ��S����C����VALUES ����sno����cno����
3.7.3 ʹ���α�� SQL ���
➢ ʹ���α������У�
• ��ѯ���Ϊ������¼�� SELECT ���
• CURRENT ��ʽ�� UPDATE ���
• CURRENT ��ʽ�� DELETE ���
3.7.3.1 ��ѯ���Ϊ������¼�� SELECT ���
➢ �α��� SELECT ���ļ��Ϻ������Ե�һ��ֻ�ܴ���һ����¼֮�����������
➢ �α경���У�
• ˵���α꣺�����Ƕ��壬����ִ�в�ѯ
EXEC SQL DECLARE <���> CURSOR FOR <SELECT ���>��
• ���α꣺ִ����Ӧ�IJ�ѯ���ѽ���Ž�������������ָ��ָ���һ����¼
EXEC SQL OPEN <���>
• ��ȡ��ǰ��¼���ƽ��α�ָ��
EXEC SQL FETCH <���>
INTO <������>[<ָʾ����>][,<������>[<ָʾ����>]......]
• �ر��α꣺�ͷŻ���������Դ
EXEC SQL CLOSE <���>��
➢ ������ѯij��ָ��ϵ������ѧ�������
... ...
EXEC SQL INCLEDE SQLCA�� //˵�������EXEC SQL BEGIN DECLARE SECTION��
VARCHAR depname[5]�� VARCHAR HSno[10]�� VARCHAR HSname[10]�� VARCHAR HSex[2]��
int HSage��
EXEC SQL END DECLARE SECTION��
.... ...
gets(depname)��
... ...
EXEC SQL DECLARE SX CURSOR FOR //˵���α�SELECT S# , SN ,SS , SA FROM S
WHERE SD = ��depname��
EXEC SQL OPEN SX�� //���α�WHILE ��1��
{
EXEC SQL FETCH SX INTO ��HSno����HSname����HSex����HSage��
//��ȡ��ǰ��¼���ƽ��α�ָ��if��sqlca.sqlcode!=SUCCESS��break��
printf(��%s,%s,%s,%d\n��, HSno�� HSname�� HSex�� HSage);
... ...
}
EXEC SQL CLOSE SX�� //�ر��α�
➢ :depname ֵ�ı��������´��α꣬��ò�ͬ�ļ��ϡ�
3.7.3.2 CURRENT ��ʽ�� UPDATE �� DELETE ���
➢ �������裺
1) ˵���α�
EXEC SQL DECLARE < �α���> CURSOR FOR <SELECT ��ѯ> FOR UPDATE [OF <����>]��
2) OPEN �α�
3) FETCH �α�
4) ����Ƿ�Ҫ�Ļ�ɾ��������ִ�� DELETE �� UPDATE������ʹ�� WHERE CURRENT OF <�α���>��
5) ������� CLOSE �α�
➢ ��������ijϵ��ѧ��������Ҫ��������
... ...
EXEC SQL INCLEDE SQLCA��
EXEC SQL BEGIN DECLARE SECTION��
VARCHAR depname[5]�� VARCHAR HSno[10]�� VARCHAR HSname[10]�� VARCHAR HSex[2]��
int HSage��
EXEC SQL END DECLARE SECTION��
.... ...
gets(depname)��
... ...
EXEC SQL DECLARE SX CURSOR FOR SELECT S# , SN ,SS , SA FROM S
WHERE SD = ��depname [FOR UPDATE OF SA]��
EXEC SQL OPEN SX�� WHILE ��1��
{
EXEC SQL FETCH SX INTO ��HSno����HSname����HSex����HSage��
if��sqlca.sqlcode!=SUCCESS��break�� printf(��%s,%s,%s,%d\n��, HSno�� HSname�� HSex�� HSage); printf(��UPDATE(U) or DELETE(D) or NO(N)?\n��);
scanf(��%c��,&op); if(op==��U��)
{
printf(��Input new age:��); scanf(��%d��,&newage);
EXEC SQL UPDATE S SET SA=:newage WHERE CURRENT OF SX;
}
else if(OP==��D��)
EXEC SQL DELETE FROM S WHERE CURRENT OF SX;
else continue;
... ...
}
EXEC SQL CLOSE SX��
3.7.5 ��̬SQL ��䣨�� SYBASE �� ESQL Ϊ����
➢ ��Ԥ����ʱ�����������Ϣ�ı���ʹ�ö�̬ SQL ������
• SQL �������
• ����������
• ��������������
• SQL ������õ����ݶ���
3.7.5.1 ��̬��������ʵ�ַ�ʽ
➢ ����һ��ʹ�� execute immediate
• �ص�
ִ����䲻�ܷ����κν����
• ���
EXEC SQL [at connection_name] EXECUTE IMMEDIATE
{: host_variable | string};
• ����
EXEC SQL BEGIN DECLARE SECTION;
CS_CHAR sqlstring[200];
EXEC SQL END DECLARE SECTION;
char cond[150];
strcpy(sqlstring,"update titles set price=price*1.10 where "); printf("Enter search condition:");
scanf("%s", cond); strcat(sqlstring, cond);
EXEC SQL EXECUTE IMMEDIATE :sqlstring;
➢ ��������ʹ�� prepare and execute
• �ص�
1) û�з���ֵ��Ҫ����ִ��
2) ���е������ؼ�¼
• ���
EXEC SQL [at connection] PREPARE statement_name FROM {: host_variable | string};
EXEC SQL [at connection] EXECUTE statement_name [INTO host_var_list] [USING host_var_list];
• ����
EXEC SQL BEGIN DECLARE SECTION;
CS_CHAR sqlstring[200]; CS_FLOAT multiplier;
EXEC SQL END DECLARE SECTION;
char cond[150];
printf(��Enter search condition:��); scanf(��%s��, cond);
printf(��Enter price multiplier: ��); scanf(��%f��, &multiplier);
strcpy(sqlstring,��update titles set price = price * ? where ��); strcat(sqlstring, cond);
EXEC SQL PREPARE update_statement FROM :sqlstring; EXEC SQL EXECUTE update_statement USING :multiplier;
➢ ��������ʹ�� prepare �� Cursor
• �ص�
1) SELECT �б��̶�
2) ���Է��ض�����¼
• ���
EXEC SQL [at connection_name] DECLARE cursor_name CURSOR FOR statement_name;
EXEC SQL [at connection_name] OPEN cursor_name [USING host_var_list];
EXEC SQL [at connection_name] FETCH cursor_name INTO :host_variable EXEC SQL [at connection_name] CLOSE cursor_name;
• ����
EXEC SQL BEGIN DECLARE SECTION;
CS_CHAR sqlstring[200]; CS_FLOAT bookprice,condprice; CS_CHAR booktitle[200];
EXEC SQL END DECLARE SECTION;
char orderby[150];
strcpy(sqlstring,"select title,price from titles where price>? order by "); printf("Enter the order by clause:");
scanf("%s", orderby); strcat(sqlstring, orderby);
EXEC SQL PREPARE select_state FROM :sqlstring;
EXEC SQL DECLARE select_cur CURSOR FOR select_state; condprice = 10;
EXEC SQL OPEN select_cur using :condprice;
EXEC SQL WHENEVER NOT FOUND GOTO END;
for (;;)
{
EXEC SQL FETCH select_cur INTO :booktitle,:bookprice; printf("%20s %bookprice=%6.2f\n",booktitle, bookprice);
}
end:
EXEC SQL CLOSE select_cur;
➢ �����ģ�ʹ�� prepare �� ��̬������Dynamic Descriptors
• �ص�
1) SELECT �б����Բ��̶�
2) ���Է��ض�����¼������Ҳ���̶�
• ��Ӧ���ݼ���زο���
3.8 �洢����*��T-SQL��
➢ ���
create procedure [owner.]procedure_name [(@parameter_name datatype [= default][output]
[, @parameter_name datatype [= default][output]]...)]
[with recompile] as SQL_statements
➢ ����Ҫ�أ�
• ����
begin
statement block
end
• ����
��@��ʼ��Ϊ�û���������@@��ʼ��Ϊȫ�ֱ������������DECLARE
@@rowcount ����Ӱ�������
@@sqlstatus �α� Fetch ��״̬
• ��������
if logical_expression statements
[else
[if logical_expression] statement]
• ѭ������
while boolean_expression statement
break
statement continue
• ˳�����label: goto label
• ����ֵ
return [integer_expression]
• ��ӡ��Ϣ
print {format_string | @local_variable | @@global_variable} [, arg_list] select @local_variable | @@global_variable
• ִ��
[execute] [@return_status =][[[server.]database.]owner.]procedure_name [[@parameter_name =] value | [@parameter_name =] @variable [output] [,[@parameter_name =] value|[@parameter_name = ] @variable [output]...]]
[with recompile]
• ��������ѧ�ţ���ø�ѧ���ɼ������� C01 �γ̣��ɼ��� 1������� 2 CREATE PROCEDURE get_gr @sno varchar(10), @GR OUTPUT int
AS
DECLARE @cno varchar(5) BEGIN
SELECT @cno=C#,@GR=GR FROM S WHERE S# = @sno IF (@cno =��C01��)THEN
select @GR=@GR+1
ELSE
select @GR=@GR+2 END��
ִ�У�
declare @gr int
execute get_gr ��s001��,@gr output select @gr �� print @gr
������ ���ݿ�ı���
4.1 ���ݿ�İ�ȫ��
➢ ���ݿ�İ�ȫ����ָ�������ݿ��Է�ֹ���Ϸ���ʹ�����й©�����Ļ��ƻ��ȡ����õķ����У��û���ʶ�ͼ��𡢴�ȡȨ���ơ�ʹ����ͼ����ơ����ݼ��ܵȡ�
➢

���ݿ�ϵͳ�İ�ȫģ�ͣ�
�û���ʶ ��ȡ���� ����ϵͳ���� ����洢
4.1.1 �û���ʶ�ͼ���
➢ һ����ϵͳ����Ա��DBA��Ϊÿ���û�����һ���û������û���ʶ/�ʺţ����û�����û�����ʹ�ô˱�ʶ���ɽ���ϵͳ��
➢ ���
CREATE USER <username> IDENTIFIED BY <password>
➢ ���ε�¼����
4.1.2 ��ȡ����
➢ ��ȡȨ����Ҫ�أ����ݶ���������
➢ ��Ȩ������ij�û�����Щ���ݶ��������Щ���͵IJ�����
➢ ���ݶ�������ȣ������С���(һ������ͼʵ��)������Խϸ����Ȩ��ϵͳԽ�� ��ȫ��Խ���ơ���ϵͳ����Խ�������ֵ��Ӵ�
4.1.2.1 Ȩ�����Ƶ�����
➢ ���û����п��ơ��û�ֻ���Է����Լ�����ģʽ
➢ �Բ������ͽ��п��ơ�����һ���������ѯ���ġ����롢ɾ���ȡ��û����Ա����費ͬ�IJ���Ȩ�ޡ�
➢ �����ݶ���Ŀ��ơ��û����Ա����Ʒ���ijЩ���������
4.1.2.2 Ȩ����(��ɫ)����
➢ ��ɫ�����ݿ�Ԥ�����õ�һϵ�о���ij�ֳ���Ȩ����ϡ�ij�û�����һ����ɫ��ӵ�иý�ɫ������Ȩ���ˡ�
➢ SYBASE ��һЩ��ɫ��
• sa_role
• sso_role
• sybase_ts_role
• navigator_role
➢ ORACLE �е������ɫ:
• Connect���������ݿ�¼����Ա��
1) ���Է��� ORACLE
2) ���������ı���������ѯ���²�����
3) ������ͼ��ͬ���
• Resource�����ڿ�����Ա��
1) ���� Connect ������Ȩ��
2) �������������۴ص�Ȩ��
3) �����Լ������Ķ�����Բ��������Ը����˸�Ȩ
4) ʹ���������
• DBA�����ڹ�����Ա��
1) ���� Resource ������Ȩ��
2) ���Է����κ��û�������
3) ������ջ��û�Ȩ��
4) ��������ͬ���
5) �������ķ���
6) ִ�����ݿ��ж��
7) ���
4.1.2.3 Oracle �д�ȡ���Ƶ��
➢ ��Ȩ���/�½��û���
GRANT [CONNECT | RESOURCE | DBA] TO <username>
[IDENTIFIED BY <password> ]
➢ �ջ�Ȩ��/ɾ���û���
REVOKE [CONNECT | RESOURCE | DBA] FROM <username>
➢ ����Ȩ���ƣ�
GRANT <����Ȩ> ON <����> TO <username|public> [WITH GRANT OPTION]
• ���С�����Ȩ��������SELECT��INSERT��DELETE��UPDATE��ALTER��INDEX��
ALL
• ����ӵ������Ȼ���ڶԶ���IJ���Ȩ��ֻ��ӵ���ߺ� DBA ���Խ�����IJ���Ȩ������ˡ�
4.1.3 ������ͼ
➢ ����ͨ��������ͼ�����û����ÿ������������ݣ�����ͼ����Ҫ������ʵ�����ݶ����ԣ��䰲ȫ�������ܲ�����ϸ��
4.1.4 ���
➢ ��ǿ����ȫ������ʩ���Զ���¼�����ݿ�ķ��ʴ�ȡ�ۼ���
➢ ��Ϊ�û�����ϵͳ�����û�����Ҫ�û����ã�����û��Լ������Ķ������ƣ���������Щ����ĸ��ַ��ʣ�ϵͳ������� DBA ���еģ�����û���¼�ijɹ�����Լ������ݿ⼶Ȩ�IJ�����
➢ ��Ƴ������Ĵ���ʱ��Ϳռ���Դ������һ����Ϊ��ѡ������رգ���ϵͳ�İ�ȫ��Ҫ�������
➢ ��ƽ������� SYS.AUDIT_TRAIL �У�ORACLE �У�
➢ ������ SC ���� ALTER �� UPDATE �������
AUDIT ALTER��UPDATE ON SC
➢ ����ȡ���� SC �����κ����
NOAUDIT ALL ON SC
4.1.5 ���ݼ���
➢ ORACLE �� SYBASE ���ݿⶼ�ṩ�Դ洢���̵ļ��ܣ��� SYBASE ��ʹ��
SP_HIDETEXT
4.2 ���ݿ��������
➢ ���ݿⰲȫ���Ƿ�ֹ�Ƿ��û��ķǷ������������������Ƿ�ֹ������������ݡ�
➢ ���ݿ������Ե�ʵ�ֻ��ƣ�
• DBMS ������ݿ��е������Ƿ���������涨����������Щ�������ݿ�����֮�ϵ�����Լ��������Ϊ���ݿ�������Լ��������
• �� DBMS �м�������Ƿ����������������Ļ��Ƴ������Լ�顣
4.2.1 ������Լ������
➢ ������Լ���������õĶ�����Է�Ϊ���м���Ԫ�鼶��ϵ���������ȡ�
• �м�Լ����ҪԼ���е�ȡֵ���͡���Χ����������ȣ�
• Ԫ�鼶Լ����ҪԼ����¼�и����ֶ�֮�����ϵ��
• ��ϵ��Լ����Ҫ��Լ�������¼���ϵ֮�����ϵ��
➢ ������Լ������״̬���Է�Ϊ��̬�Ͷ�̬�ġ�
• ��̬��Ҫ�Ƿ�ӳ���ݿ��״̬�Ǻ����ġ�
• ��̬��Ҫ�Ƿ�ӳ���ݿ��״̬��Ǩ�Ƿ������
4.2.1.1 ��̬�м�Լ��
➢ ���������͵�Լ�����������ݵ����͡����ȡ���λ�����ȵȣ��� char(10)��
➢ �����ݸ�ʽ��Լ���������� YY/MM/DD
➢ ��ȡֵ��Χ�ϵ�Լ����
➢ �Կ�ֵ��Լ��
➢ ����Լ����
4.2.1.2 ��̬Ԫ�鼶Լ��
➢ ��̬Ԫ��Լ��ֻ�����ڵ���Ԫ���ϣ���߿��ɼ���ij���ֶ�Ϊ�������ֶεĺ͡�
4.2.1.3 ��̬��ϵ��Լ��
➢ ��̬��ϵԼ�����������֣�
• ʵ��������Լ��
• ����������Լ��
• ��������Լ��
• ͳ��Լ��
4.2.1.4 ��̬�м�Լ��
➢ �Ķ���ʱ��Լ�������ɿո�Ϊ�ǿ�
➢ ����ֵʱ��Լ�������¾�ֵ֮����ij��Ҫ��
4.2.1.5 ��̬Ԫ�鼶Լ��
➢ �ĺ��ֵ��ԭ������ֶ����
4.2.1.6 ��̬��ϵ��Լ��
➢ ��ϵ�仯ǰ���״̬���ƣ���Ҫ�������һ���Ժ�ԭ���ԡ�
4.2.2 �����Կ���
➢ �����Կ��ƻ���Ӧ�þ��еĹ��ܣ�
• ���幦�ܣ�����Լ������
• ��鹦�ܣ�����û��IJ��������Ƿ�Υ����������Լ������
• ִ�ж������ڷ����û��IJ���Υ����������Լ���������ܲ�ȡһ���Ķ�������֤���ݵ������ԡ�
➢ ��鹦�ܷ����ࣺ
• ����ִ��Լ����immediate constraint��
• �ӳ�ִ��Լ����deferred constraint��:���ʺ�֮���ת���롰���ƽ��Լ������
➢ �����Թ������ʽ����ʾ��D��O��A��C��P����
• D��data�������ݶ���
• O��opration�������������Լ������ݿ����
• A��assertion�������ݶ���������������Լ��/���ԣ����������
• C��condition����ѡ�����ݶ�����������ɰ����� D ��
• P��procedure����Υ�������Թ����������IJ������̡��������ڹ��ʲ����� 1000 Ԫ
D��Լ�����ö��������ԡ����ʡ� O�����û�������ġ����ʡ�����ʱ���������Լ��A�������ʡ�����С�� 1000 C���������ڡ�ְ�ơ�����ֵΪ���ڵļ�¼ P���ܾ�ִ���û�����
➢ ����������Ӧ���ǵ����⣺
• ����Ƿ���Խ��ܿ�ֵ���� S.SD ���ԣ�SC.S��������
• ɾ�������չ�ϵ��Ԫ��ʱ�Ŀ���
1) ����ɾ����Cascade����ɾ�����չ�ϵ����Ӧ���ֵ��Ԫ��
2) ����ɾ����Restricted����ֻ�в��չ�ϵ��û����Ӧ���ֵ��Ԫ��ʱ������ɾ��
3) �ÿ�ֵɾ����nullified���������չ�ϵ����Ӧ����ÿա�
• �ı����չ�ϵ��Ԫ��ʱ�Ŀ���
1) �����ģ�Cascade�����IJ��չ�ϵ����ӦԪ������ֵ
2) �����ģ�Restricted����ֻ�в��չ�ϵ��û����Ӧ���ֵ��Ԫ��ʱ��������
3) �ÿ�ֵ�ģ�nullified���������չ�ϵ����Ӧ����ÿա�
4.2.3 Oracle �������Կ���
➢ Oracle �е�ʵ��������
CREATE TABLE S��
S�� char��10���� SN char��20���� SS char��2���� SA int��
SD char��5����
CONSTRAINT pk_1 PRIMARY KEY ��S#������
➢ Oracle �еIJ���������
CREATE TABLE SC��
S�� char��10���� C�� char��4���� GR int��
CONSTRAINT fk_1 FOREIGN KEY (C#) REFRENCES C��C������ CONSTRAINT fk_2 FOREIGN KEY (S#) REFRENCES S��S����
ON {DELETE CASCADE|SET NULL}����ȱʡ�� P ������ RESTRICT��
➢ Oracle �е��û��Զ���������
• �м�
CREATE TABLE S��
S�� char��10��
CONSTRAINT CHK1 CHECK ��substr (S#,3,8) BETWEEN ��00000001�� AND ��50999999������
SN char��20����
SS char��2�� CONSTRAINT CHK2 CHECK �� SS IN(���С�,��Ů��)���� SA int CONSTRAINT CHK3 CHECK ��SA<100����
SD char��5����
CONSTRAINT pk_1 PRIMARY KEY ��S#������
• Ԫ�鼶
CREATE TABLE EMP��
eno NUMBER��4�� ename VARCHAR��20���� sal number(7,2)�� deduct number��7,2����
CONSTRAINT CHK1 CHECK��sal+deduct<3000������
• ������
CREATE TRIGGER UPDATE_SAL:
BEFORE INSERT OR UPDATE OF sal, pos ON Teacher FOR EACH ROW
WHEN(:new.pos=�����ڡ�) BEGIN
IF :new.sal<800 THEN
:new.sal:=800; END IF
END
4.3 ���ݿ�IJ�������
4.3.1 ����
➢ ����Transaction�����Dz������Ƶĵ�λ�������ݿ����������λ�����û������һ��������У�����Ϊһ�� SQL ����һ����������������û���ʽָ���� ����ʽΪ���ݿ�ȱʡ����
➢ ��ʽ�������䣺
• BEGIN TRANSACTION [transaction name]
• COMMIT [TRANSACTION transaction name]
• ROLLBACK [TRANSACTION transaction name]
➢ ��������ԣ�ACID����
• ԭ���ԣ�Atomicity����һ����������ݿ������IJ����Dz��ɷָ�ģ�Ҫôȫ��
ִ�У�ҪôʲôҲ��������Ҫô�ύ��Ҫô�ع�����֤�����ԭ���������ݿ��ְ���� DBMS ���������ϵͳʵ�֡�
• һ���ԣ�Consistency���������ִ�н��������ݿ��һ���ԣ������ݲ����������ִ�ж����ƻ����������ɳ���Ա��ϵͳ������Լ�������ɡ�
• �����ԣ�Isolation�����������ʱ��Ӧ����Щ�����Ⱥ�ִ�еĽ��һ�����������ڲ��������ݶԲ�����������������Ǹ���ģ����ָ���ij̶ȱ�����Ϊ����ĸ��뼶�𡣸������� DBMS ����������ϵͳʵ�֡�
• �־��ԣ�Durability����һ������һ������ύ��������ݿ�ĸ��½����÷�ӳ�����ݿ��У�������Ϊϵͳ�Ĺ��϶���ʧ������Ҫ�����ݿ�Ļָ�������ϵͳ��ɡ�
4.3.2 ���ݿ�IJ��������������Ĵ�����
➢ �Ķ�ʧ���⣺���� 2 �� A ���� A��20 ��ʧ
|
ʱ��
|
t0
|
t1
|
t2
|
t3
|
t4
|
t5
|
|
���� 1
|
|
�� A
|
A=A+5
|
|
д A
|
|
|
���ݿ� A ֵ
|
5
|
|
|
20
|
10
|
|
|
���� 2
|
|
�� A
|
A=A+15
|
д A
|
|
|
➢ �ۣ��ࣩ�����⣺��ȷֵӦ���Ƕ��� A��5
|
ʱ��
|
t0
|
t1
|
t2
|
t3
|
t4
|
t5
|
|
���� 1
|
|
�� A
|
A=A+5
|
д A
|
|
�ع�
|
|
���ݿ� A ֵ
|
5
|
|
|
10
|
|
A=5
|
|
���� 2
|
|
|
|
|
�� A(10)
|
|
➢ �����ظ������⣺���ζ��� A ��һ��
|
ʱ��
|
t0
|
t1
|
t2
|
t3
|
t4
|
t5
|
|
���� 1
|
|
�� A
|
A=A+5
|
д A
|
|
|
|
���ݿ� A ֵ
|
5
|
|
|
10
|
|
|
|
���� 2
|
|
�� A(5)
|
|
|
�� A(10)
|
|
➢ ��Ӱ�����⣺ͬ������䷵�ؽ����һ��
|
ʱ��
|
t0
|
t1
|
t2
|
t3
|
|
���� 1
|
|
|
insert into t1
values(4,��Fl��)
|
|
|
���ݿ���
|
Col1
|
Col2
|
|
Col1
|
Col2
|
|
|
A��B ֵ
|
1
|
TX
|
1
|
TX
|
|
|
2
|
NY
|
2
|
NY
|
|
|
9
|
CO
|
4
|
FL
|
|
|
|
|
9
|
CO
|
|
���� 2
|
|
select * from t1 where
|
|
select * from t1 where
|
4.3.3 ���ݿ�IJ�����������
➢ �ɴ������Ǻ�������������ȷ�Ե�Ψһ�����������ʱ����ȷ�ģ����ҽ���������ijһ�ִ����е�ִ������ʱ�ؽ����ͬ�������ֵ��Ȳ���Ϊ�ɴ��л�
��Serializable���ĵ��ȡ�
➢ ���л�����ʾ����
���� 1���� B��A��B��1��� A
���� 2���� A��B��A��1��� B
• ���е��� 1��A��10��B��2���D�D>��A��3��B��4��
|
|
|
col1<5 (��� 2 ��)
|
|
col1<5 (��� 3 ��)
|
|
ʱ��
|
t0
|
t1
|
t2
|
t3
|
|
���� 1
|
�� B��2
|
A=B+1,д A
|
|
|
|
���� 2
|
|
|
�� A��3
|
B��A+1��д B
|
• ���е��� 2��A��10��B��2���D�D>��A��12��B��11��
|
ʱ��
|
t0
|
t1
|
t2
|
t3
|
|
���� 1
|
|
|
�� B��11
|
A=B+1,д A
|
|
���� 2
|
�� A��10
|
B��A+1��д B
|
|
|
• ���ɴ��л����� 3��A��10��B��2���D�D>��A��3��B��11��
|
ʱ��
|
t0
|
t1
|
t2
|
t3
|
|
���� 1
|
�� B��2
|
|
A=B+1,д A
|
|
|
���� 2
|
|
�� A��10
|
|
B��A+1��д B
|
• �ɴ��л����� 4��A��10��B��2���D�D>��A��3��B��4��
|
ʱ��
|
t0
|
t1
|
t2
|
t3
|
|
���� 1
|
�� B��2
|
A=B+1,д A
|
|
|
|
���� 2
|
��ʼ
|
�ȴ�
|
�� A��3
|
B��A+1��д B
|
4.3.3 ���ݿ�ķ�������
➢ �����ͣ�
• ����������ռ��:Exclusive Lock ��� X����������ʱ�� X ��
• ��������Share Lock ��� S������ѯʱһ��� S ��
• ������Update Lock������Ҫ�ĵ����ݼ� Update ������������ DBMS ���У�
• ���������ԣ�
|
|
X
|
S
|
-
|
|
X
|
N
|
N
|
Y
|
|
S
|
N
|
Y
|
Y
|
|
-
|
Y
|
Y
|
Y
|
➢ ��������(����)��
• DDL Lock
• Internal Lock
• Distribute Lock
• DML Lock��
• Table Lock��All pages��
• Page Lock��data Page��
• Row Lock��row Lock��
4.3.4 ���ݿ�ķ���Э��D�D������뼶��
➢ ������뼶�� 0��READ UNCOMMITTED������һ������Э�顣
• Э�������У�
1) ���� T ��������ǰ�����ȶ���� X ����ֱ������������ͷš������������������������Commit���������������Rollback����
2) ���� T �����ݲ�������
• ������
1) �������ֹ���Ķ�ʧ���⡣
2) ���ܷ�ֹ����ͱ�֤�ظ�����
➢ ������뼶�� 1��READ COMMITTED��������������Э�顣
• Э�������У�
1) ���� T ��������ǰ�����ȶ���� X ����ֱ������������ͷš�
2) ���� T ������ǰ�����ȶ���� S ����������ͷ� S ���������ǵ�����������ͷš�
• ������
1) �������ֹ��������⡣
2) ���ܱ�֤�ظ�����
➢ ������뼶�� 2��REPEATABLE READ��������������Э�顣
• Э�������У�
1) ���� T ��������ǰ�����ȶ���� X ����ֱ������������ͷš�
2) ���� T ������ǰ�����ȶ���� S ����ֱ������������ͷš�
• ������
1) ��֤�ظ�����
➢ ������뼶�� 3��SEARIALIZABLE���������η���Э�飬�ɴ����Է���Э�顣
• Э�������У��������У�
1) �ڶ��κ����ݶ�дǰ����Ҫ��ö����ݵ���������չ�Σ�����������������뼶�� 2 �����𣩡�
2) ���ͷ�һ�����Ժ��������κ������������Ρ�
• ������
1) ��֤����ɴ���ִ�С�
➢ ������뼶���������Ͷ��ձ�
|
������뼶��
|
0 (Read
Uncommited)
|
1 (Read
Committed)
|
2 (Repeatable
Read)
|
3 Serializable
|
|
X
��
|
���������ͷ�
|
|
|
|
|
|
��������ͷ�
|
��
|
��
|
��
|
��
|
|
S
��
|
���������ͷ�
|
|
��
|
|
|
|
��������ͷ�
|
|
|
��
|
��
|
|
һ���Ա�
֤
|
��ֹ��ʧ��
|
��
|
��
|
��
|
��
|
|
��ֹ���
|
|
��
|
��
|
��
|
|
���ظ���
|
|
|
��
|
��
|
|
��ֹ��Ӱ��
|
|
|
|
��
|
4.3.5 ���������
➢ ����������ϵͳ�����ǰ����������������Ⱥ��������ĸ���������Դ�����Ӷ�����ij�����������Զ����ȥ������ƻ�����
• ��������İ취��������Դ�ķ�������������ȷ���IJ���
➢ ���������� T1 ������ A������ T2 ������ B��Ȼ������ T1 ������� B�������� 2
������� A������ T1 �ȴ� T2 �� T2 �ֵȴ� T1 �ͷ���Դ�������������
• ��������ķ�����
1) һ�η���������һ�ν������õ�������ȫ������������ִ�С�
2) ˳�������������������ͬһ����ȥ����������Դ����ȻӦ����ʱ���밴��ij�ִ���ִ�У������Dz�ͬ�������в�ͬ�ķ��ʴ���
4.4 ���ݿ�Ļָ�
4.4.1 �ָ���ԭ��
➢ ���ݿ�Ļָ���ϵͳ����ʹ�������ϵ����ݿ�ָ���һ����״̬��
➢ ���ݿ�ϵͳ�������ϵ������У�������ϡ�ϵͳ���Ϻͽ��ʹ��ϡ�
4.4.1.1 �������
➢ ����ij��ԭ�������������Υ�����������ơ����������������ȵ�������û�������������쳣��ֹ����������ϡ�
➢ �ָ�����Ҫǿ�лع���Rollback��δ��ɵ������еIJ����ģ��ص���������ǰ��״̬�����ֻع�������Ϊ��������UNDO����
4.4.1.2 ϵͳ����
➢ ����ij��ԭ���� OS �� DBMS ����Ӳ������CPU ���ϣ���ͻȻ����ȵ���������û�������������쳣��ֹ����ʱ�����ϵ������������ڴ��е�����ȫ����ʧ�� ��ϵͳ���ϡ�
➢ �ָ�����Ҫǿ�лع���Rollback��δ��ɵ�����ص���������ǰ��״̬��UNDO����ͬʱ��Ҫ�����ύ�������ܴ����ڴ����δд���������������д�����裬������̳�Ϊ������REDO����
4.4.1.3 ���ʹ���
➢ ����ij��ԭ����Ӳ����ǿ�ų����ŵȵ��´洢�������ϵ����ݲ��ֻ�ȫ����ʧ���ƽ��ʹ��ϡ�
➢ �ָ�������Ҫװ�����ݿⷢ�����ʹ���ǰ��ij��ʱ�̵����ݿ⸱�����������Դ�ʱ�̿�ʼ�����гɹ�����ֱ����������ǰһʱ�̡�
4.4.2 �ָ���ʵ�ּ���
➢ �ָ��������ô洢��ϵͳ�����ط������������������ݿ��б��ƻ�����ȷ�����ݣ����Իָ��ĺ���������������
• ��ν�����������
• ���������������ʵʩ�ָ���
➢ ����������ת����������־����������ʹ�á�
4.4.2.1 ����ת��
➢ ����ת���������ݿ� DBA �����ݿ⸴�Ƶ��Ŵ�����̵������ط��Ĺ��̡���Щ���Ƶ����ݳ�Ϊ���ݿ�ĺ������Ԯ�����ݡ�
➢ ���ݵĺ����ڻָ���Ҫ����ת���Ժ����е����и�������
➢ ����ת����ת��ʱ���ݿ��״̬���֣���Ϊ��
• ��̬ת����ת��ʱ���ݿ���������е�����Ӱ�����ݿ������
• ��̬ת����ת����������Բ������У����ٶ�������Ӱ�죬��ת�����ݿ⸱����ͬʱ�����¼ת���ڼ������������־�ļ��������ſ����øú����ݿ⸱������־�ļ��������ݿ�ָ���
➢ ����ת���м��ַ�ʽ��
• ����ת������ȫת������ÿ�ζ���ȫ���ݵ����ݿ�����
• ����ת����ÿ�α�����ǰһ�λ��������ӵ�����
• ��ֵת����ÿ�α������ϴ���ȫת�����������ݿ����ӵ�����
4.4.2.2 ��־�ļ�
➢ ��־�ļ���������¼��������ݿ�ĸ��²������ļ���
➢ ��־�����֣�
• �Լ�¼Ϊ��λ
• �����ݿ�Ϊ��λ
4.4.3 �ָ��IJ���
4.4.3.1 ������ϵĻָ�
➢ ����ɨ����־�ļ������Ҹ�������²���
➢ �Ը�����ĸ��²���ִ���������UNDO��
4.4.3.2 ϵͳ���ϵĻָ�
➢ ����ɨ����־�ļ������Ҹ�������²���
➢ �Ը�����ĸ��²���ִ���������UNDO��
➢ ����ɨ����־�ļ��������������е��������������REDO��
4.4.3.3 ���ʹ��ϵĻָ�
➢ װ�����µ����ݿ⸱��
➢ װ����ص���־�ļ��������������
4.5 ���ݿ�ĸ����뾵��
4.5.1 ���ݿ�ĸ���
➢ �����֣�
• �Եȸ��ƣ��������ƽ�ȣ����Ի��ิ������
• ���Ӹ��ƣ�����ֻ��������ݿ⸴�Ƶ������ݿ�
• �������ƣ����ݴ������ݿ⸴�Ƶ������ݿ���ٴӴ����ݿ⸴�Ƶ��������ݿ�
4.5.2 ���ݿ�ľ���
➢ DBMS �����ṩ��־�ļ������ݿ�ľ����Է�ֹ���ʹ��Ϻ������ٻָ�Ӧ�á�
➢ ��ν���ݿ⾵����ָ���� DBA ��Ҫ��DBMS �Զ����������ݿ�����еĹؼ����ݸ��Ƶ���һ�������ϣ���֤����������������һ���ԡ�һ�����ʹ��ϳ��֣�DBMS���Զ����þ�����̽������ݿ�ָ�������Ҫ�ر�ϵͳ����װ���ݿ⸱����ͬʱ�������ݿ�������ڲ��Dz������������ݿ��� X �����û����Բ�ѯ�������ݿ⡣
➢ �������ݿ�ƽʱʼ�պ�Դ���ݿⱣ��ͬ������������Դ���ݿ�����IJ���ʱ�ṩ��ѯ������
������ ��ϵ���ݿ��������
5.1 ��������
➢ һ����ϵ���ݿ����һ���ϵ�����������ϵ�Ĺ�ϵģʽ��ȫ����������ݿ�ģʽ��
5.1.1 ��ϵģʽ�е���������
➢ �����Ĺ�ϵģʽ��������R��U��D��DOM��F����
• R ��ϵ��
• U ������
• D �� U ��ȡֵ��Χ������ļ��ϡ�
• DOM ����������ӳ��ļ��ϡ�
• F �����Լ����ݵ�������ϵ���ϡ�
➢ ��ϵģʽ�Ǿ�̬�ġ��ȶ��ģ���ϵ�Ƕ�̬�ģ���ͬʱ�̹�ϵģʽ�еĹ�ϵ���ܲ�ͬ�� ����ϵ�����������ϵģʽ������������ϵ���� F ָ����������Լ����
➢ Ӱ�����ݿ�ģʽ��Ƶ���Ҫ�� U �� F������һ���ϵģʽ��Ϊ��R��U�� F��
5.1.2 ���������Թ�ϵģʽ��Ӱ��
➢ ��������Ŀǰ�����¼��֣�������������ֵ��������������
➢ һ����ϵģʽʾ����
U��{Sno,Sdept,Mname,Cname,Grade}
F��{Sno->Sdept, Sdept->Sname, (Sno,Cname)->Grade}
�ù�ϵģʽ�����������⣺
• ��������̫��ϵ���������ظ����֣�������ѧ�������пγ̳ɼ�����һ��
• �����쳣������ϵ���α�����ÿһ��ѧ����Ϣ
• �����쳣���ճ�����ϵ�����û�����������洢ϵ������Ϣ
• ɾ���쳣��ij��ϵ��ѧ��ȫ����ҵɾ��ʱ�ᶪʧϵ������Ϣ
5.1.3 ��ظ���
➢ ����������R��U����һ����ϵģʽ��U �� R �����Լ��ϣ�X �� Y �� U ���Ӽ������� R��U��������һ�����ܵĹ�ϵ r����� r �в���������Ԫ�� w��v��ʹ�� w[X]=v[X] �� w[Y]<>v[Y]���� X �������� Y���� Y ���������� X���� X->Y��
➢ ƽ���ĺͷ�ƽ���ĺ�����������ϵģʽ R��U���� X �� Y �� U ���Ӽ������ X->Y���� YËX����� X->Y �Ƿ�ƽ���ĺ��������������ƽ���ĺ����������������۵Ķ��Ƿ�ƽ���ĺ���������
➢  ��ȫ���������Ͳ��ֺ�����������ϵģʽ R��U������� X��>Y���Ҷ�������� X�����Ӽ� X������ X�� \ >Y����� Y ��ȫ���������� X���� X f >Y���� Y ����ȫ������ X ��� Y ���������� X���� X P >Y��
��ȫ���������Ͳ��ֺ�����������ϵģʽ R��U������� X��>Y���Ҷ�������� X�����Ӽ� X������ X�� \ >Y����� Y ��ȫ���������� X���� X f >Y���� Y ����ȫ������ X ��� Y ���������� X���� X P >Y��
➢ ���ݺ�����������ϵģʽ R��U������� X��>Y��Y��>Z���� Y \ >X����� Z ���ݺ��������� X���� X t >Z��
➢  ������¶��壺��ϵģʽ R��U,F����K Ϊ������ϣ��� K f >U���� K ��һ����ѡ�롣
������¶��壺��ϵģʽ R��U,F����K Ϊ������ϣ��� K f >U���� K ��һ����ѡ�롣
5.2 ��ʽ
➢ ��ʽ��������������ij����������Ĺ�ϵģʽ�ļ��ϡ�
➢ Ŀǰ�� 6 �ַ�ʽ��1NFÉ2NFÉ3NFÉBCNFÉ4NFÉ5NF
5.2.1 ��һ��ʽ��1NF��
➢ ���壺���һ����ϵģʽ R ���������Զ���ԭ�ӵģ��������ٷֵĻ�������� �� RÎ1NF��
➢ ʾ����SCL��S����SN��SA��CLS��MON��C����CN��CRD��GR������ 1NF
�����������⣺
• ����������� MON��CRD ��
• �����쳣�����γ�ʱѧ����Ϣ������
• ɾ���쳣����ij��ѧ����ѡ����Ϣȫ��ɾ��ʱ������ѧ��������Ϣ��
➢ SCL ���ڵĺ���������ϵ��
• ��S����C���� f >GR
• 
 ��S����C���� P >SN S# f >SN
��S����C���� P >SN S# f >SN
•  ��S����C���� P >SA S# f >SA
��S����C���� P >SA S# f >SA
•  ��S����C���� P >CLS S# f >CLS
��S����C���� P >CLS S# f >CLS
• ��S����C���� P >CN C# f >CN
• ��S����C���� P >CRD C# f >CRD
•  CLS >MON S# t >MON
CLS >MON S# t >MON
5.2.2 �ڶ���ʽ��2NF��
➢ ���壺���һ����ϵģʽ RÎ1NF������ÿһ�������Զ���ȫ������ R ���룬��
RÎ2NF����Ȼ��ֻ����һ�����Ե� R ����� 1NF������� 2NF
➢ ʾ����S_L��S����SN��SA��CLS��MON�� C��C����CN��CRD�� S_C��S����C����GR�������� 2NF
�����������⣺
• ����������� MON
• �����쳣����ѧ����Ϣ��������Ϣ
• ɾ���쳣����ѧ������Ϣɾ����������
➢ ����������ϵ��
• S�� f >SA
• S�� f >CLS
• S�� f >SN
•  CLS >MON S# t >MON
CLS >MON S# t >MON
•  C�� f >CN
C�� f >CN
•  C�� f >CRD
C�� f >CRD
• ��S����C���� f >GR
5.2.3 ������ʽ��3NF��
➢ ���壺���һ����ϵģʽ R �в����ڷ������Զ���Ĵ����������� RÎ3NF��
➢ ʾ����S��S����SN��SA��CLS��
L��CLS��MON�� C��C����CN��CRD�� S_C��S����C����GR�������� 3NF
5.2.4 BC ��ʽ��BCNF��
➢ ���壺���һ����ϵģʽ R��U,F��Î1NF���� R �е�����һ����ƽ���ĺ�������
X��>Y��X �����к�ѡ�룬�� RÎBCNF��
➢ ʾ����STC��S��T��C����S ѧ����T ��ʦ��C �γ�
��S��C����>T
��S��T����>C T��>C
�ֽ�Ϊ��ST��S��T����TC��T��C�������� BCNF��
5.2.5 ���ķ�ʽ��4NF��
➢ ��ϵģʽ R��U�����Լ� U��X��Y �� Z �� U ���ཻ���Ӽ����� Z��U��X��Y������ϵģʽ R ����һ��ϵ r ���� X ��һ������ֵ������ Y ��һ��ֵ��֮��Ӧ���� Y ����һ��ֵ�� Z �أ��� Y ��ֵ������ X���� X��>��>Y���� Z �ǿ�ʱ�Ʒ�ƽ���Ķ�ֵ������
➢ ���壺���һ����ϵģʽ R��U,F��Î1NF���� R �е�����һ����ƽ���Ķ�ֵ����
X��>��>Y��X �����к�ѡ�룬�� RÎ4NF��
➢ ʾ����CTX��C��T��X�� C���γ̣�T����ʦ��X���ο����ѡ�룺��C��T��X��
C��>��>T��C��>��>X��C ���Ǻ�ѡ�룬�� CTX ������ 4NF
�ֽ�Ϊ CT��C��T����CX��C��X���������� 4NF
5.2.6 ���巶ʽ��5NF��
➢ ���壺��ϵģʽ R�������Լ� U��X1��X2......Xn �ֱ�Ϊ U ���Ӽ���ÈXi��U��������� R ��ÿһ����ϵ r ���� r��¥Xi���������������JD���ڹ�ϵģʽ R �ϳ����� ��Ϊ*��X1��X2��......Xn��,��ij�� Xi ���� R����ƽ��������������
➢ ʾ������ϵ AFP
|
A
|
F
|
P
|
|
a1
|
f1
|
p1
|
|
a1
|
f1
|
p2
|
|
a1
|
f2
|
p1
|
|
a2
|
f1
|
p2
|
|
a2
|
f3
|
p2
|
AF
|
A
|
F
|
|
a1
|
f1
|
|
a1
|
f2
|
|
a2
|
f1
|
|
a2
|
f3
|
FP
|
F
|
P
|
|
f1
|
p1
|
|
f1
|
p2
|
|
f2
|
p1
|
|
f3
|
p2
|
AP
AF¥FP
|
A
|
F
|
P
|
|
a1
|
f1
|
p1
|
|
a1
|
f1
|
p2
|
|
a1
|
f2
|
p1
|
|
a2
|
f1
|
p1
|
|
a2
|
f1
|
p2
|
|
a2
|
f3
|
p2
|
AF¥FP¥AP=AFP
|
a1
|
f1
|
p2
|
|
a1
|
f2
|
p1
|
|
a2
|
f3
|
p2
|
|
a2
|
f1
|
p1
|
���� AFP ���(a2,f2,p2)��
AFP
|
A
|
F
|
P
|
|
a1
|
f1
|
p1
|
|
a1
|
f1
|
p2
|
|
a1
|
f2
|
p1
|
|
a2
|
f1
|
p2
|
|
a2
|
f3
|
p2
|
|
a2
|
f2
|
p2
|
AF
|
A
|
F
|
|
a1
|
f1
|
|
a1
|
f2
|
|
a2
|
f1
|
|
a2
|
f3
|
|
a2
|
f2
|
FP
|
F
|
P
|
|
f1
|
p1
|
|
f1
|
p2
|
|
f2
|
p1
|
|
f3
|
p2
|
|
f2
|
p2
|
AP
AF¥FP
|
A
|
F
|
P
|
|
a1
|
f1
|
p1
|
|
a1
|
f1
|
p2
|
|
a1
|
f2
|
p1
|
|
a2
|
f1
|
p1
|
|
a2
|
f1
|
p2
|
|
a2
|
f3
|
p2
|
|
a1
|
f2
|
p2
|
|
a2
|
f2
|
p1
|
AF¥FP¥AP=AFP
|
A
|
F
|
P
|
|
a1
|
f1
|
p1
|
|
a1
|
f1
|
p2
|
|
a1
|
f2
|
p1
|
|
a2
|
f3
|
p2
|
|
a2
|
f1
|
p1
|
|
a1
|
f2
|
p2
|
|
a2
|
f2
|
p2
|
➢ ���壺���һ����ϵģʽ R��U,F��Î1NF���� R �е�����һ���������������ɺ�ѡ���̺����� RÎ5NF��
5.3 ��ϵģʽ�Ĺ淶��
5.3.1 ��ϵģʽ�Ĺ淶������
|
�����������Լ�����ķ�ƽ����������
|
��ʽ����
|
��������
|
|
1NF
|
|
|

|
�����������Զ���IJ��ֺ���������ϵ
|
|
2NF
|
|
|

|
�����������Զ���Ĵ��ݺ���������ϵ
|
|
3NF
|
|
|

|
���������Զ���IJ��ֺ���������ϵ
|
|
|
BCNF
|
|
|
|

|
�����������Եķ�ƽ���Ķ�ֵ����
|
|
|
4NF
|
|
|
|
|
�����Ǻ�ѡ���̺�����������
|
|
|
5NF
|
|
5.3.2 ��ϵģʽ�ķֽ�
➢ ��ϵģʽ�Ĺ淶����ͨ���Թ�ϵģʽ�ķֽ���ʵ�ֵġ����ѵͼ���Ĺ�ϵģʽ�ֽ�Ϊ����Ĺ�ϵģʽ���ֽⲻΨһ��ֻ�б�֤�ֽ��Ĺ�ϵģʽ��ԭ��ϵģʽ�ȼۣ� �������塣
➢ ʾ����
��ϵģʽ SL��Sno��Sdept��Sloc����Sno��>Sdept��Sdept��>Sloc, Snot >Sloc
��
�� SL �����¹�ϵ��
|
Sno
|
Sdept
|
Sloc
|
|
95001
|
CS
|
A
|
|
95002
|
IS
|
B
|
|
95003
|
MA
|
C
|
|
95004
|
IS
|
B
|
|
95005
|
PH
|
B
|
• �ֽⷽ��һ��
SN(Sno)��SD(Sdept)��SO(Sloc)
SN��SD��SO ���Ǻܸߵķ�ʽ������ 5NF�����ֽ��ʧ�ܶ���Ϣ��
|
SN
|
SD
|
SO
|
|
Sno
|
Sdept
|
Sloc
|
|
95001
|
CS
|
A
|
|
95002
|
IS
|
B
|
|
95003
|
MA
|
C
|
|
95004
|
|
|
|
95005
|
PH
|
|
• �ֽⷽ������
NL(Sno��Sloc)��DL(Sdept��Sloc)�ֽ���ϵΪ��
|
NL
|
DL
|
|
Sno
|
Sloc
|
Sdept
|
Sloc
|
|
95001
|
A
|
CS
|
A
|
|
95002
|
B
|
IS
|
B
|
|
95003
|
C
|
MA
|
C
|
|
95004
|
B
|
PH
|
B
|
|
95005
|
B
|
|
|
NL �� DL ����Ȼ���ӽ���ǣ�
|
Sno
|
Sdept
|
Sloc
|
|
95001
|
CS
|
A
|
|
95002
|
IS
|
B
|
|
95002
|
PH
|
B
|
|
95003
|
MA
|
C
|
|
95004
|
IS
|
B
|
|
95004
|
PH
|
B
|
|
95005
|
IS
|
B
|
|
95005
|
PH
|
B
|
�������Ԫ�飬��ʵ������ȷ���ĸ��Ƕ���ģ���˶�ʧ����Ϣ��
• ���壺�����ϵģʽ R��U��F���ڷֽ�Ϊ���ɸ���ϵģʽ Ri��Ui��Fi�� ������ U��ÈUi������ Ri ����Ȼ���Ӻ�ԭ��ϵ��ȣ���Ƹ÷ֽ�������������ԡ�
• �ֽⷽ������
ND(Sno��Sdept)��NL(Sno��Sloc)�ֽ���ϵΪ��
|
ND
|
NL
|
|
Sno
|
Sdept
|
Sno
|
Sloc
|
|
95001
|
CS
|
95001
|
A
|
|
95002
|
IS
|
95002
|
B
|
|
95003
|
MA
|
95003
|
C
|
|
95004
|
IS
|
95004
|
B
|
|
95005
|
PH
|
95005
|
B
|
NL �� DL ����Ȼ���ӽ���ǣ���ԭ��ϵ��ͬ������ij��ѧ��תϵ����Ҫ������������ 95005 תΪ CS ϵ���� PH��>CS��B��>A��ԭ���Ƿֽ�ʱ��ʧ�� Sdept��>Sloc�ĺ���������ϵ��
• ���壺����ڷֽ������ԭ�������� F ��ÿ���ֽ���ij����ϵ�������� Fi �����̺�����Ƹ÷ֽ��DZ��ֺ��������ġ�
• �ֽⷽ���ģ�
ND(Sno��Sdept)��DL(Sdept��Sloc)�ֽ���ϵΪ��
|
ND
|
DL
|
|
Sno
|
Sdept
|
Sdept
|
Sloc
|
|
95001
|
CS
|
CS
|
A
|
|
95002
|
IS
|
IS
|
B
|
|
95003
|
MA
|
MA
|
C
|
|
95004
|
IS
|
PH
|
B
|
|
95005
|
PH
|
|
|
NL �� DL ����Ȼ���ӽ���ǣ���ԭ��ϵ��ͬ���÷ֽ��DZ��ֺ��������ġ�
➢ ������ϵ�ֽ�����������
• �Ƿ��������������
• �Ƿ��˺�������
➢ ��ϵ�ֽ����۶�����
• ��Ҫ���ϵģʽ�ֽ�������������ԣ���ֽ�һ���ɴﵽ 4NF
• ��Ҫ���ϵģʽ�ֽⱣ�ֺ�����������ֽ�һ���ɴﵽ 3NF������һ���ﵽBCNF
• ��Ҫ���ϵģʽ�ֽ�Ⱦ������������ԣ��ֱ��ֺ�����������ֽ�һ���ɴﵽ
3NF������һ���ﵽ BCNF
������ ���ݿ����
6.1 ���ݿ����ݵIJ���
➢ �������
➢ ����ṹ���
• ��ƾֲ���ͼ
• ������ͼ
➢ ���ṹ���
• ������ṹ
• �Ż����ṹ
➢ ���ݿ��������
• ��������ṹ
• ���������ṹ
➢ ���ݿ�ʵʩ
• ���ݿ�ϵͳ������ʵ��
• ����������
➢ ���ݿ�����ά��
6.2 �������
6.2.1 �������������
➢ ���������������ͨ����ϸ������ʵ�����Ҫ�����Ķ�����֯�����š���ҵ�ȣ�������˽�ԭϵͳ�Ĺ����ſ�����ȷ�û��ĸ�������Ȼ���ڴ˻�����ȷ���µ�ϵͳ���ܡ���ϵͳӦ�ÿ��ǿ���չ�ԡ�
➢ ����������ص��ǣ����顢�ռ�������û������ݿ�����е���ϢҪ����Ҫ��ȫҪ���������Ҫ��
➢ ��������Ľ���ǣ�DD�������ֵ䣩��DFD��������ͼ����
6.2.2 ��������ķ���
➢ ��������������IJ��裺
• ������֯�������
• ���������ҵ�����
• ����Ϥҵ������ϣ�Э���û���ȷ����ϵͳ��Ҫ��
• �������������������ȷ����ϵͳ�ñ߽磬�����������ù����߽硣
➢ ���õĵ��鷽����
• ������ҵ
• �������
• ��רҵ��ʶ����
• ѯ��
• ��Ƶ�������û���д
• ���ļ�¼
➢ �����û�����ķ�����
• �Զ����£��ṹ����������(Structured Analysis����� SA)
• �Ե�����
6.2.3 �����ֵ�
➢ �����ֵ�����ϸ�����ռ������ݷ����Ľ���������������ݣ�
• ����������ٷֵ����ݵ�λ��
���������������������������������˵�����������������͡����ȡ�ȡֵ��Χ��ȡֵ���塢�����������������ϵ
• ���ݽṹ
���ݽṹ��ӳ������֮�����Ϲ�ϵ��
���ݽṹ���������������ݽṹ��,����˵��,���(��������ݽṹ)
• ������
�����������ݽṹ��ϵͳ�ڴ����·����
����������������������������˵������������Դ��������ȥ����ɣ����ݽṹ����ƽ���������߷���������
• ���ݴ洢
���ݴ洢�����ݽṹͣ����ĵط���Ҳ��������������Դ��ȥ��֮һ�����ݴ洢�����������ݴ洢����˵������š����������������������������
�����ݽṹ��������������ȡ��ʽ
• ��������
�������̵Ĵ�����һ�����ж������ж����������������ֵ�һ��ֻ������˵������Ϣ������������������������˵�������루��������������������������Ҫ˵����
6.3 ����ṹ���
6.3.1 ����ṹ����Ʒ����벽��
➢ �Զ����£��ȶ���ȫ�ָ���ṹ����ϸ��
➢ �Ե����ϣ��ȶ���ֲ�Ӧ�õĸ���ṹ���ټ����������õ�ȫ�ָ���ṹ
➢ �����ţ��ȶ�����ĸ���ṹ�������������䣬ֱ��ȫ�ָ���ṹ��
➢ ��ϲ��ԣ���ʹ���Զ����¡��Ե������༯��
6.3.2 ���ݳ�����ֲ���ͼ���
1. ѡ��ֲ�Ӧ��
2. ��һ��Ʒ� E��R ͼ
• ������ʵ������н�Ȼ���ֵĽ��ߣ�
1) ���Բ����پ�����Ҫ����������
2) ���Բ���������ʵ�������ϵ
6.3.3 ��ͼ�ļ���
1. �ϲ��� E��R ͼ���������� E��R ͼ���ϲ��� E��R ͼ�����д��ڵij�ͻ�У�
• ���Գ�ͻ���������ͻ�����Ե�λ��ͻ
• ������ͻ��ͬ�����壬����ͬ��
• �ṹ��ͻ��ͬһ�������ͬ��ͬһʵ�����Բ�ͬ����ϵ���Ͳ�ͬ��
2. �����ع������ɻ��� E��R ͼ
���� E��R ͼ��������Ҫ�����õ����� E��R ͼ����ͼ���ɺ��γ��������ṹ���������㣺
• �ṹ�ڲ��������һ���ԣ������л���ì�ܵı���
• ����ṹ�����ܷ�ӳԭ����ÿһ����ͼ�ṹ������ʵ�壬���Ժ���ϵ
• �ṹ��������������ε���������
6.4 ���ṹ���
➢ ���ṹ��Ƶ���������ṹת��Ϊijһ����ģ�͡�
➢ ���ṹ��ƵIJ��裺
• ������ģ��ת��Ϊһ��Ĺ�ϵ����Ρ���״ģ�͡�
• ��ת�����Ĺ�ϵ����κ���״ģ�����ض��� DBMS ֧���µ�����ģ��ת����
• ������ģ�ͽ����Ż���
6.4.1 E��R ͼ������ģ��ת��
➢ ת����ԭ��
• һ��ʵ����ת��Ϊһ����ϵģʽ��
• һ�� m��n ����ϵת��Ϊһ����ϵģʽ����Ϊ��ʵ������ϡ�
• һ�� 1��n ����ϵ ת��Ϊһ�������Ĺ�ϵģʽ����Ϊ n ��ʵ���룻Ҳ������ n �˹�ϵģʽ�ϲ���
• һ�� 1��1 ����ϵת��Ϊһ�������Ĺ�ϵģʽ��ÿ��ʵ�������Ǻ�ѡ�룻Ҳ��������һ�˹�ϵģʽ�ϲ���
• ��������������ʵ����һ����Ԫ��ϵת��Ϊһ����ϵģʽ��
• ͬһʵ�弯��ʵ������ϵ������ϵ��Ҳ�ɰ��������ϵ��ʽ������
• ������ͬ��ĸ�ģʽ���Ժϲ���
6.4.2 ����ģ�͵��Ż�
➢ ȷ����������
➢ �Ը�����ϵģʽ��������������м�С�������������������ϵ��
➢ ���������������۶Թ�ϵģʽ��һ���з��������Ƿ���ڲ��ֺ������������ݺ�����������ֵ�����ȣ�ȷ������ϵģʽ�ֱ����ڵڼ���ʽ��
➢ ������������εõ��ĸ���Ӧ�ö����ݴ�����Ҫ����������Ӧ�û�����Щ��ϵģʽ�Ƿ���ʣ�ȷ���Ƿ�Ҫ�����ǽ��кϲ��ͷֽ⡣
➢ �Թ�ϵģʽ���б�Ҫ�ķֽ�ͺϲ���
6.4.3 ����û���ģʽ
➢ ʹ�ø������û�ϰ�ߵı�����
➢ ��Բ�ͬ������û������岻ͬ����ģʽ��������ϵͳ��ȫ�Ե�Ҫ��
➢ ���û���ϵͳ��ʹ�á�
6.5 ���ݿ��������
6.5.1 ȷ�����ݿ�������ṹ
➢ ȷ�����ݵĴ洢�ṹ���ۺϿ��Ǵ�ȡʱ�䡢�洢�ռ������ʺ�ά�����ۡ��۴ص�ʹ��������
• ͨ���۴�����з����ǸĹ�ϵ����ҪӦ�á�
• ��Ӧ��ÿ���۴����ƽ��Ԫ�����Ȳ�̫�٣�Ҳ��̫�ࡣ
• �۴���ֵ����ȶ����Լ�������ֵ�����ά��������
➢ ������ݴ�ȡ·������Ҫ����ν���������
➢ ȷ�����ݴ��λ�á���Ҫ����־/���ݡ�����/���ݵĴ�ž����ֿ���
➢ ȷ��ϵͳ���á�����������������С��ʱ��Ƭ��С������Ŀ�ȡ�
6.5.2 ���������ṹ
➢ ��ҪȨ������أ�ʱ��Ч�ʡ��ռ�Ч�ʡ�ά�����ۡ��û�����
➢ �������ݿ�ķ�����ȫ������ѡ�õ� DMBS
6.6 ���ݿ�ʵʩ
���ݿ�ʵʩ����Ҫ����������
➢ �� DDL �������ݿ�ṹ
➢ ��֯�������
➢ ���Ƶ���Ӧ�ó���
➢ ���ݿ�������
6.6.1 �������ݿ�ṹ
6.6.2 ����װ��
➢ ����С��ϵͳ����װ�ز��裺
• ɸѡ����
• ת�����ݸ�ʽ
• ��������
• У������
➢ ���ڴ�����ϵͳ������װ�ز��裺
• ɸѡ����
• ��������
• У������
• ת������
• �ۺ�����
6.6.3 ���ƺ͵���Ӧ�ó���
6.6.4 ���ݿ�������
➢ �������ܲ��Ժ����ܲ��ԡ�
6.7 ���ݿ�����ά��
������Ҫ�� DBA �Ĺ�����������
6.7.1 ���ݿ��ת���ͻָ�
6.7.2 ���ݿ�İ�ȫ�������Կ���
6.7.3 ���ݿ����ܵļල�������Ľ�
6.7.4 ���ݿ������֯���ع���
➢ ���ݿ����飺����ı��������������ṹ��ֻ�����°��Ŵ洢�����������ȡ�
➢ ���ݿ��ع���Ӧ������ı䣬Ҫ��ı�����ƣ�����ṹ�ȣ������ع���
➢ ���ݿ�ϵͳ������ƣ����ݿ��ع��ij̶���ʮ�����ģ����ع��Ĵ���̫��ʱ���ͱ�ʾ���е����ݿ�ϵͳ�����������Ѿ�������Ӧ����������µ����ݿ�ϵͳ�ˡ�
������ ��ϵ���ݿ����ϵͳʵ��
7.1 ��ϵ���ݿ����ϵͳ��Ʒ����
RDBMS �ķ�չ�����
➢ �Թ�ϵ���ݿ�֧�ֵ�����
• 70 �����֧�����ݽṹ�ͻ������ݲ�����ѡ��ͶӰ�����ӵȣ���DBASE �ȡ�
• 80 �����֧�ֹ��ʱ� SQL������������TSQL��PL/SQL��,Oracle �ȡ�
• 90 �������ǿ��ȫ�Ժ������ԡ�
➢ ���л�����չ�����Σ�
• һ���Ϊ���û�ϵͳ�Ĵ���С�ͻ��������еĵ��� RDMBS�����ϵľ�Ϊ���û��ģ���Ϊ�� DOS �ǵ��û�����ϵͳ��
• ��������չ��һ�������ֲ�ԣ�ʹ֮�ڶ���Ӳ���Ͳ���ϵͳ�ϣ��������ݿ���������ֲ�ʽϵͳ��չ��֧�ֶ�����Э�顣
• �����绷���£��ֲ�ʽ���ݿ�Ϳͻ�/ �������ṹ���ݿ�ϵͳ���Ƴ��������ݿ�Ŀ����ԣ�����ֲ�� portability���������� connectivity����������
scalability����
➢ RDBMS ��ϵͳ���ɱ仯��
• ���ڵ� RDBMS ��Ҫʵ�� DDL��DML��DCL �Ȼ��������Լ����ݴ洢��֯���������ơ���ȫ�������Լ�顢ϵͳ�ָ������ݿ��������ع���
• ���ڵ� RDBMS �����ݹ����Ļ�������Ϊ���ģ�������Χ����ϵͳ������
FORMS��REPORT��GRAPHICS �ȡ�
➢ RDBMS ��Ӧ�õ�֧��
• ��һ����Ҫ��������Ϣ�������������ٶ�Ҫ�ߡ�
• �ڶ�����Ҫ���������������һ���������������������������Ӧʱ��
• RDBMS �ĸ��Ƽ�����Ҫ�У�
• ����
• �ɿ���
7.2 ORACLE ���ݿ�
7.2.1 Oracle ��˾���
➢ ������ 1977 ��
➢ 1979 �꣬Oracle ��һ������������������ RDBMS ֮һ��
➢ 1992 Oracle7��1997 �� Oracle8 ��Oracle 9i ��Oracle 10g
7.2.2 Oracle ��Ʒ����
➢ �����ԣ�compatibility���������������̵����ݿ���ݡ�
➢ ����ֲ�ԣ�portability��������װ 70 ���ֻ��������ֲ���ϵͳ��
➢ �������ԣ�connectability����֧�ֶ�������Э�飬�� TCP/IP��DECnet �ȡ�
➢ �������ʣ�high productivity�����ṩ PRO*C ��Forms �Ƚӿ��빤�ߡ�
➢ �����ԣ�ǰ�����Ա������俪���ԡ�
7.2.3 Oracle ���ݿ��������Ʒ
➢ ��������
• ����̡����߳���ϵ�ṹ
• Ϊ������ܸĽ����ļ������������м�����������ѯ�����߳�˳��Ų�����
• �߿�����
• SQL ��ʵ�֣����� ISO �� SQL ��
➢ ���з�����ѡ����Oracle Parallel Server���Ͳ��в�ѯ��Parallel query Option��
➢ �ֲ�ʽѡ����distributed Option��
➢ ���̻�ѡ����Procedural option�����ṩ�û��Զ������ݿ����
7.2.4 Oracle ����
➢ Developer/2000
• ORACLE Forms����Ļ����
• ORACLE Reports����������
• ORACLE Graphics��ͼ�ι��ߣ���ֱ��ͼ�ȡ�
• ORACLE Book ���������������ĵ���
➢ Designer/2000
• BPR �����ڹ��̽�ģ
• Modellers������ϵͳ����뽨ģ��
• Generators ��Ӧ����������
➢ Discoverer/2000��OLAP ���ߣ�Ӧ�������ݲֿ�ȡ�
➢ Oracle Office���칫�Զ�����
➢ SQL DBA���û���̬���ܼ�ء�
➢ ORACLE Ԥ������ Proc*C
➢ ORACLE ���ýӿ� OCI
7.2.5 Oracle ���Ӳ�Ʒ
➢ SQL *Net������ Client �� Server ��ͨѶ��
➢ Oracle ��Э��ת����
➢ Oracle ����ʽ���أ����������غ��̻����أ�����ʵ�ֶ��������ݿ��ֱ�ӷ��ʡ�
7.2.6 Oracle ���ݲֿ�������
➢ OracleOLAP
• Oracle Express Server
• Oracle Express Objects
• Oracle Express Analyzer
7.2.7 Oracle ��Internet �������
➢ Oracle WebServer 2.0
7.2 Sybase ���ݿ�
7.2.1 Sybase ��˾���
➢ 1984 �������INGRES ��ѧ�汾����Ҫ�����Ա֮һ Dr.Robert Epstein �� Sybase
�Ĵ�ʼ��֮һ��
➢ ������ C/S ���ݿ���ϵ�ṹ������ OLTP Ӧ��Ҫ��1987 ���Ƴ� SYBASE SQL
Server��
➢ Sybase 11.0��11.5��11.9��12.0��12.5 ���Ǻ�����İ汾��
7.2.2 Sybase ��ϵ���ݿ��Ʒ
➢ ���ݿ��������
• Sybase SQL Server
• Sybase MPP
• Sybase IQ
• Sybase Anywhere
➢ �м����
• Replication Server
• Open Client
• Open Server
• OmniCONNECT
• ObjectCONNECT for C++ Directconnect
➢ ���ߣ�
• PowerBuilder
• S��Designor
• Optima����
• NetImpact Studio
• Internet Developer Toolkit for PowerBuilder
7.2.3 Sybase ���ݿ������(Adaptive Server)
➢ SQL Server��RDBMS��������ټ��㡢���ݹ��������������
• �����̶��߳���ϵ�ṹ
• ������
• ���������Լ��Ϳ���
• ��ǿ��ȫ���ܹ��ܣ����ڽ�ɫ�������ṩ���
• ֧�ֲַ�ʽ��ѯ����
➢ ���ݷ�������backup server���������� SQL Server����ɶ����ݵı��ݹ�����
• ֧���������ݣ�����ʱ��Ӱ�� SQL Server ������
• ֧��ת���ֽ⣺����ʹ�ö�̨�������ת����
• ֧�����ת����DBA ���Թ������Զ�̷������ı��ݺ�װ�ء�
• ֧����ֵת������־ת����������ֵ�¼��������Զ���ɡ�
➢ SYBASE MPP���ദ�������з�������Ʒ
➢ SYBASE IQ�������ܾ���֧�ֺͽ���ʽ���ݼ��ɲ�Ʒ��
➢ SYBASE SQL Anywhere������ PC �ľ��� SQL ���ܵķֲ�ʽ���ݿ����ϵͳ��
7.2.4 Sybase ��������
➢ PowerBuilder������ͼ�ν���� C/S ǰ��Ӧ�ÿ������ߡ�
➢ PowerDesigner��һ����ܼ��ɵļ���������������̣�CASE�����ߣ��������ݿ�ķ��������ά���������ĵ��ʹ������ݿ�ȹ��ܡ�
➢ PowerJ���������� java Ӧ�õĿ��ٿ������ߡ�
➢ Power++��Optima++����RAD C++ C/S �� Internet �������Ŀ������ߡ�
➢ SQL Manager�����ӻ���ϵͳ�����ݿ�������ߡ�
7.2.5 Sybase ��
➢ Open Client/Open Server������ Sybase ����ʽ C/S ����������Open Client ���ڽ�����Ч��ǰ��Ӧ�ã�Open Server ��һ�������칤�ߣ����ڼ�����ҵ����Դ�����
➢ Jaguar CTS���� jaguar ��������������component transaction server����ƣ�ר��Ϊ NetOLTP Ӧ����Ƶ������������
➢ Replication Server�����Ʒ�������
➢ OmniCONNECT����ͬ���ݿ����ϵͳ������ sybase��֮����ȫ�������ݼ��ɡ�
➢ DirectConnect������ͬ�� Sybase ����Դ������ϵ�ķ��ʷ�������
7.2.6 Sybase ���ݲֿ�������
➢ Sybase Web. Works
7.4 INFORMIX ���ݿ�
➢ 1988 �� Infomix �Ƴ���һ�����ݿ������ INFORMIX��TURBO ������ IBM �չ���
7.5 DB2 ���ݿ�
➢ DB2 �� IBM �����ݿ����ϵͳ����Դ�� System R �� System R*��
7.6 INGRES ���ݿ�
➢ INGRES ��˾������ 1980���似��Դ�ڼ��ݲ�������ѧ��PostgreSQL ��ǰ����
➢ PostgreSQL ����˵�����ɫ���������ݿ����ϵͳ������ѧԺζ����Ϊ��������Ŀ�������ݿ��о�����˲������ȶ��ԣ����ܻ���ʹ�÷��㷽�涼���������ݿ�Ƿȱ��
7.7 * ���㼰���Ӧ��ϵͳ��ϵ�ܹ�
�ڰ��� ���ݿ⼼���½�չ
8.1 ���ݿⷢչ����
➢ ���ݹ�����չ����
• �˹���
• �ļ�������
• ���ݿ��
➢ ���ݿ�����ģ�ͷ�չ�����Σ�
• ��ʽ������ģ�ͣ���Ρ���״��
• ��ϵģ��
• �ḻ������ģ�ͣ��������壩
➢ ��ϵ���ݿⷢչ������
• ֧�����ݽṹ�ͻ������ݲ�����ѡ��ͶӰ�����ӵȣ���DBASE ��
• ֧�ֹ��ʱ� SQL������������TSQL��PL/SQL��Oracle ��
• ��ǿ��ȫ�Ժ�������
8.2 ���ݿ⼼�������������Ľ��
8.2.1 �ֲ�ʽ���ݿ�
➢ �ֲ�ʽ���ݿ��ص㣺
• ���ݵ������ֲ���
• ���ݵ���������
• ���ݵķֲ������ԣ����ԣ����������������ԡ��������ԣ��û����ع������ݵķֲ�ϸ�ڡ�
• ����������Э�����������ִ�оֲ�Ӧ������Ҳ��ͨ�����紦��ȫ������
• ���ݵ����༰�������ԣ��ʵ��������ϵͳЧ�ʺͿɿ��ԣ�������û�����
➢ �ֲ�ʽ���ݿ��ŵ㣺
• �ֲ�ʽ���ƣ�����ͨ�ſ���
• ���ݹ�����ȫ�ֺ;ֲ�
• �ɿ��ԺͿ����Լ�ǿ�����Ը����������ݻָ�ijһ��������
• ���ܸ��ƣ����ݷ�Ƭ��������Դ����
• �������Ժã���ֲ������ԣ�����Ӱ���û�����
➢ �ֲ�ʽ���ݿ�ȱ�㣺
• ���ӣ���Ҫ��������Э����
• ������Ӳ����ͨ�š����������ȫ�ԡ������ԺͲ������ƿ�����
➢ �ֲ�ʽ���ݿ���ϵ�ṹ�������ɾֲ�����ģʽ��һ��ȫ������ģʽ��
• ȫ������ģʽ
• ȫ����ģʽ
• ȫ�ָ���ģʽ
• ��Ƭģʽ��ˮƽ����ֱ����Ϸ�Ƭ����ȫ�ԡ����ع��ԡ����ཻ�ԡ�
• �ֲ�ģʽ
• �ֲ�����ģʽ
• �ֲ���ģʽ
• �ֲ�����ģʽ
• �ֲ���ģʽ
• �ļ�ӳ��
• ȫ����ģʽ��ȫ�ָ���ģʽ֮���Ӧ��ϵ��
• ȫ�ָ���ģʽ����ϵ����ȫ�ַ�Ƭģʽ��Ƭ�ϣ�֮���Ӧ��ϵ��
• ȫ�ַ�Ƭģʽ��Ƭ�ϣ���ȫ�ֲַ�ģʽ�������㣩֮��Ķ�Ӧ��ϵ��
• ȫ�ֲַ�ģʽ��ֲ�����ģʽ֮���ӳ�䡣
8.2.2 �������ݿ�
➢ ���м������ϵ���ͣ�
• �����ȫ�Գƶദ������SMP������ CPU �����ڴ�����̣�share memory����
• �����Ⱥ����ϵͳ������ CPU �������̣�share disk��
• ���ģ���д�����MPP�������� CPU ���Լ��ڴ�ʹ���������Դ��share nothing��
➢ ��Ӧ�������ݿ����ϵ�ṹ��
• �����ڴ棨share memory����SMP��
• �������̣�share disk��
• ������Դ��share nothing��
➢ �������ݿ�����ȣ�
• ��ͬ����䲢��
• ͬһ����ͬ��ѯ�䲢��
• ͬһ��ѯ��ͬ�����䲢��
• ͬһ�����ڲ���
8.2.3 ��ý�����ݿ�
➢ ��Ҫ������
• �ܹ���ʾ����ý�����ݡ�
• �ܹ�Э����������ý�����ݡ�
• Ӧ�ṩ�ȴ�ͳ���ݹ���ϵͳ��ǿ���ʺϷǸ�ʽ�����ݲ�ѯ���������ܡ�
• Ӧ�ṩ������������汾����������
8.2.4 �������ݿ�
➢ Ŀ�����ṩ���������ʱ��Ӧ������ͬʱ������ݿ�ģ�黯�̶ȡ�
➢ ͨ�����÷������ڴ�ͳ���ݿ���Ƕ�� ECA���¼�������������������
➢ Ҫ��������⣺
• ����ģ�ͺ�֪ʶģ��
• ִ��ģ��
• �������
• �������
• ��ϵ�ṹ
• ϵͳЧ��
8.2.5 ����ϵ���ݿ�
➢ ����ϵ���ݿ���й�ϵ���ݿ������������ݿ�����������������ڹ�ϵ���ݿ�������ṩһ�¹��ܣ�
• ���������������ģ��
• SQL ��֧�ָ������
• ֧������Գ�������Լ̳�
• �ṩͨ�ù���ϵͳ
8.3 ����Ӧ�õ����ݿ��¼���
8.3.1 ���ݲֿ�
➢ ���ݿ⼼����չ���������������߷�����
➢ ���ݿ�������ࣺ�����ͣ����������ͷ����ͣ����߷�������
➢ ���ݲֿ�����ϵ�������ĺ��ģ��ǽ�������֧��ϵͳ��DSS���Ļ�����
➢ �����ݿ���ݲֿ⣬���ݿⲻ�ʺϷ����ʹ�����
• ����������������������Բ�ͬ��
• ���ݼ�������
• ���ݶ�̬����
• ��ʷ����
• �����ۺ�����
8.3.2 �������ݿ�
➢ �������ݿ���һ���ܴ洢�������ֹ���ͼ�Σ�����Ϊ��������ṩ���ַ�������ݿ⡣������ CAD��CIM �ȡ�
8.3.3 ͳ�����ݿ�
➢ ͳ�����ݿ���һ��������ͳ�����ݽ��д洢��ͳ�ơ����������ݿ�ϵͳ��
8.3.4 �ռ����ݿ�
➢ �ռ����ݿ����������ռ�λ�ú͵㡢�ߡ��桢�����������˽ṹ��λ���Լ�������Щ�������ܵ���������Ϊ��������ݿ⡣
,
��һ�� ����
1.1 ����
1.1.1 ���ݡ����ݿ⡢���ݿ�ϵͳ�����ݿ����ϵͳ
➢ ���ݿ⼼�������� 20 ���� 60 �������
➢ �����ݹ��������¼���
➢ �������ѧ����Ҫ��֧
⌦�����Ӧ�õ��������棺��ѧ���㡢���ݹ��������̿���
➢ ���ݡ����ݿ⡢���ݿ����ϵͳ�����ݿ�ϵͳ�Ĺ�ϵ
1) ���ݣ�Data��
��������Ϣ�ķ��ż�¼�����������ݿ�����о��Ķ���
⌦���֡�ͼ�Ρ�ͼ��������ѧ����������������ȡ�
2) ���ݿ⣨Database��
⌦���ݱ��淽�����˹����ļ������ݿ�
���ڴ洢�ڼ�����ڣ�����֯�ġ��ɹ�����������ݵļ��ϡ����ݰ�һ��������ģ����֯�������ʹ�����������С����ȡ��ϸߵ����ݶ����ԡ�����չ�ԡ����û��������ص㡣
3) ���ݿ����ϵͳ��DBMS��
Database Management System��λ���û��Ͳ���ϵͳ֮���һ�����ݹ���������
⌦���ݿ�Ľ��������к�ά���� DBMS ͳһ������ͳһ���ơ��ܷ����û����ݶ�������ݲ��ݡ����ݿⱣ���ȹ��ܡ�
4) ���ݿ�ϵͳ��DBS��
�����Ӳ��Ϊ�����ļ�¼����ϵͳ���������ݿ⡢���ݿ����ϵͳ��Ӧ��ϵͳ������Ա���û�����ʱ�����������Ӳ����
1.1.2 ���ݹ��������ķ�չ
➢ ���ݹ�����ָ�����ݽ��з��ࡢ��֯�����롢�洢��������ά���������ݴ����ĺ������⡣��Ϊ������
1) �˹�������
⌦�ص㣺1)���ݲ����� 2)�������˹��� 3)���ݲ����� 4)����������
2) �ļ�ϵͳ��
⌦�ص㣺1)���ݳ��ڱ��� 2)�ļ�ϵͳ�������� 3)�����Բ� 4�������Ե�
3) ���ݿ�ϵͳ�μ� 1.1.4
|
|
��
|
�˹�
|
�ļ�ϵͳ
|
���ݿ�ϵͳ
|
|
����
|
ʱ��
|
20 ���� 50 ���ĩ
|
60 �������
|
60 ���ĩ
|
|
Ӧ�ñ���
|
��ѧ����
|
��ѧ���㡢����
|
���ģ����
|
|
Ӳ������
|
��ֱ�Ӵ洢�豸
|
���̡��Ź�
|
����������
|
|
��������
|
�� OS
|
���ļ�ϵͳ
|
�� DBMS
|
|
������ʽ
|
������
|
������������
|
������������
|
|
�ص�
|
���ݹ�����
|
��
|
�ļ�ϵͳ
|
DBMS
|
|
�����������
|
ijһӦ�ó���
|
ijһӦ�ó���
|
��ʵ����
|
|
���ݹ����̶�
|
�ޣ������
|
�����Բ����ϴ�
|
�����Ը�����С
|
|
���ݶ�����
|
��
|
�����Բ�(����)
|
�и߶ȶ�����
|
|
���ݽṹ��
|
��
|
��¼�нṹ��������
|
����ģ������
|
|
���ݿ�������
|
Ӧ�ó������
|
Ӧ�ó������
|
DBMS ����:
��ȫ�ԡ������ԡ��������ơ����ݻָ�
|
1.1.3 ���ݿ�ϵͳ���ص�
➢ ���ݵĽṹ��
➢ ���ݵĹ����Ժá�����ȵ�
➢ ���ݵĶ����Ըߣ���������
➢ ������ DBMS ͳһ����
1) ���ݵİ�ȫ�ԣ�Security��
2) ���ݵ������ԣ�Integrity��
3) �������ƣ�Concuurency��
4) ���ݿ�ָ���Recovery��
➢ ���õ��û��ӿ�
1.1.4 *���ݿ⼼�����о�����
1. ���ݿ����ϵͳ���������ƣ��������ý�����ݿ�ȣ�
2. ���ݿ���ƣ���Ʒ���ѧ����ƹ��ߡ�����ģ���뽨ģ����ƹ淶�����
3. ���ݿ����ۣ��淶�����ۣ�
1.1.5 *���ݿ�����Ϣ��ѧ�е�Ӧ��
➢ �������磺��ʵ���硢��Ϣ���硢���������
• ��ʵ����Ķ����ǿ۴��ڵĸ���ʵ�ÿ�������ʵ�塣ʵ������������ɫ�������ȡ�
ʵ�壨entity��
ʵ�弯��entity set�� ���� ��feature��
• �������������еķ�ӳ������Ϣ���ü�¼��ʾʵ��ʵ���¼��record��
��¼����record set�� ���ԣ�attribute��
• ���������ֻ�ܹ�������ĸ�����Ź��ɵ����ֻ���Ϣ�����ֻ������Ϣ�����ݡ���������Ϣ�ķ��Ż���
���ݣ�Data����Ԫ��(Tuple)��
���ݼ���dataset�����ļ�/��(File/Table)������ֶΣ�Field��
1.2 ����ģ��
1.2.1 ����
➢ ���ݵ���֯�����ݿ⼼���ĺ�������
➢ ���ݿ��������֯��ͨ������ģ����ʵ�ֵ�
➢ ����ģ���Ǵ������ݿ�ά�����ݿ�ķ�ʽ�������ݿ�ϵͳ�����������ݺ����ݼ���ϵ�ķ�����
➢ ����ģ�͵Ķ��壺��ʾʵ�����ͺ�ʵ�����ϵ��ģ�ͳ�����ģ�ͣ��Ƕ���ʵ����ij���
➢ ����ģ�ͷ�������Σ�
• ������ݣ�ģ�ͣ�Ҳ����Ϣģ�͡�����������Ϣ�ṹ���ֳ�ʵ����ϵģ��
��ER��;�����û��۵����Ϣ��ģ��
• ���ṹ������ģ�ͣ��������ݿ�����ṹ��ֱ���漰�������ϵͳ�� DBMS�� �ֳ�Ϊ������ģ�ͣ��������ģ�ͣ����ռ����ϵͳ�Ĺ۵�����ݽ�ģ��
➢ ����ģ�͵���������Ҫ��
1) �Ƚ���ʵģ����ʵ����
2) ������������
3) ���ڼ����ʵ��
1.2.2 ����ģ��

 ��ʵ����D(��ʶ����)�D>��Ϣ���磬����ģ�ͨD(ת��)�D>�������磬����ģ��
��ʵ����D(��ʶ����)�D>��Ϣ���磬����ģ�ͨD(ת��)�D>�������磬����ģ��

1. ��Ϣ�����漰�Ļ�������
• ʵ�壨entity��
• ���ԣ�attribute��
• �루key��
• ��domain��
• ʵ���ͣ�entity type��
• ʵ�弯��entity set��
• ��ϵ��relationship����һ��һ(1:1) һ�Զ�(1:n) ��Զ�(m:n)
2. ����ģ�͵ı�ʾ�����D�Dʵ����ϵģ��
➢ ʵ����ϵģ�ͣ�Entity Relationship Model����� ER ģ�ͣ����� P.P.S Chen 1976 ������ġ�ֱ�Ӵ���ʵ�����г����ʵ���ʵ�����ϵ��Ȼ����ʵ����ϵͼ��ER ͼ�� ��ʾ��Ϣģ�ͣ����ַ����� ER ������ER ģ��ʵ������Ϣ�����ģ�͡�
➢ ER ͼ���ĸ���ɲ��֣�
• ���ο�ʵ����
• ���ο���ϵ
• ��Բ��ʵ���ͺ���ϵ������
• ֱ�ߣ�����ʵ�����ͺ���ϵ���ͣ�����ʾ��ϵ������
➢ ����˵����
1.2.3 ���ṹ������ģ��
➢ ����ģ����Ҫ�أ�
1. ���ݽṹ��
a) ��������ϵͳ�ľ�̬������
b) �Ƕ�ʵ�����ͺ�ʵ�����ϵ�ı����ʵ�֣��������͵��������ݡ�
2. ���ݲ�����
a) ����������ϵͳ�Ķ�̬������
b) �Ƕ����ݿ�������£����롢�ġ�ɾ�����������
3. ���ݵ�Լ��������
a) һ�������Թ���ļ��ϡ�
b) �������ݼ�����ϵ�����е���Լ������ԭ��
➢ �ṹ����ģ����Ҫ�����֣����ģ�͡���״ģ�͡���ϵģ�ͣ�δ���ķ�չ�У�����ģ�͡�����ģ�ͣ�
➢ �ǹ�ϵģ���е����ݽṹ�ĵ�λ�ǻ��������ϵ����ν���������ϵ��ָ��������¼�Լ�����֮���һ�Զࣨ����һ�Զࣩ����ϵ��
1.2.3.1 ���ģ��
➢ ���ʹ�����IBM1968 ��� IMS��Information Management System��
➢ ���ģ�Ͷ��壺�����ͣ���Σ��ṹ��ʾʵ�����ͼ�ʵ�����ϵ������ģ��
1. ���ģ�͵����ݽṹ�ص㣺
• ���ҽ���һ�������˫�ף��ý���Ǹ����
• ����������ҽ���һ��˫�ס�
• ���ģ����ÿ����㣨Ƭ�ϣ���ʾһ����¼����
• ÿ����¼���Ͱ������ɸ��ֶΣ��ֶ����ֶ������������ͺͳ��ȵ�
• IMS �У�һ����Ƭ���ͼ������д���Ƭ������ɵĵ�һ�����ģ�ͳ�Ϊһ���������ݿ��¼�� PDBRT��Physical DataBase Record Type����
• IMS �У���Ƭ�ϵ�һ��ֵ�������д���Ƭ��ֵ���������һ���������ݿ�ļ�¼ֵ����Ϊ�������ݿ��¼���� PDBR��Physical DataBase Record����
2. ���ģ�͵����ݲ�����������Լ����
• ����ʱ��û��˫��㲻�ܲ�����Ů��㣻
• ɾ��ʱ��ɾ��˫���Ҫͬʱɾ����Ů��㣻
• ����ʱ��Ҫ����������Ӧ�ļ�¼��
3. ���ģ�͵Ĵ洢�ṹ��
• �ڽӷ�
• ���ӷ�
4. ���ģ�͵���ȱ�㣺
• �ŵ㣺
1) ģ�ͱ�����
2) ʵ�����ϵ�ǹ̶��ģ�Ԥ����ƺõ�Ӧ��ϵͳ���������ڹ�ϵ�ͣ���������״ģ��
3) ���ģ���ṩ�����õ�������֧�֡�
• ȱ�㣺
1) ʵ�ֶ�Զ��ϵʱ����Ҫ������������㷽ʽ�����γɲ�һ����
2) �Բ����ɾ���������ƽ϶ࡣ
3) ��ѯ�ӽ����ͨ��˫��㡣
4) �ṹ�Ͻ�������������ڳ���
1.2.3.2 ��״ģ��
➢ ���ʹ�����
• 20 ���� 70 ��� CODASYL��Conference OnData System Language���� DBTG
��DataBase Task Group ���ݿ������飩����ϵͳ��
• HP ��˾�� IMAGE/3000��
• Honeywll ��˾�� IDS/II��
• Burroughs ��˾�� DMSII
• Univac ��˾�� DMS1100
• CwllinetI ��˾�� DMS
• CINCOM ��˾�� TOTAL
➢ ���壺������ͼ�����磩�ṹ��ʾʵ�����ͼ�ʵ�����ϵ������ģ�͡���network model��
1. ��״����ģ�͵����ݽṹ�ص㣺
• ����һ�����ϵĽ����˫��
• ����һ����㲻ֹһ��˫��
2. ��״����ģ�͵����ݲ�����������Լ����
• ����ʱ����������δȷ��˫������Ů���ֵ��
• ɾ��ʱ������ֻɾ��˫���ֵ��
• ����ʱ��ֻ�����ָ����¼��
3. ��״ģ�͵Ĵ洢�ṹ��
• �������ӷ�
• ��������Ԫ���з������������з�����������
4. ��״ģ�͵���ȱ�㣺
• �ŵ㣺
1) ����ֱ��������ʵ����
2) ��ȡЧ�ʸߣ����ܺ�
• ȱ�㣺
1) �ṹ���ӣ��������û����գ�DDL��DML ���Ը���
2) ���ݶ����Բ�
1.2.3.3 ��ϵģ��
➢ ���ʹ�����1970 �꣬���� IBM ��˾ E.F.Colld �����ϵģ�ͣ�Ŀǰ�����ݿ⣺DB2��
Oracle��Sybase��Infomix��SQL Server��Foxpro��Access �ȡ�
➢ ���壺��Relation model���ñ����ʾʵ�弯��ʵ�����ϵ���������ʵ�ֹ�ϵ�����ϵ��
1. ��ϵ����ģ�͵����ݽṹ������
• ���û�������һ����ϵģ�͵����ṹ����һ�Ŷ�ά����
• ����ʹ�ù淶���Ĺ�ϵ���������ԭ�ӵģ�
• ����ʵ���ù�ϵ��ʾ��ʵ������ϵҲ�ù�ϵ��ʾ��
➢ ���
• ��ϵ��relation����һ����ϵ��Ӧͨ��һ�ű� ����R
• Ԫ�飨Tuple�������е�һ�� ��V1��V2����Vn��
• ���ԣ�Attribute��/�ֶΣ�field�������е�һ�У�A1��A2����An��
• ��Domain�������Ե�ȡֵ��Χ�����Ա��� DOM���Ա𣩣����С�Ů��
• ������Ԫ���е�һ������
• ��ϵģʽ���Ǽ�¼�͡��Թ�ϵ����������ϵ�������� 1������ 2�������� n�� �� R��A1��A2���� ��An������ϵģʽ��ʵ����һ����ϵ����ϵʵ�ʾ���һ�ű�����ϵģʽ��������������ϵ�������������������͡����Գ��ȡ��������������Եȣ�������R��U��D��DOM��F��
• ��ϵ���ݿ�ģʽ��һ���ϵģʽ���ܳƼ���ϵ���ݿ�ģʽ�����ģʽ��
• ��ѡ����Condidate Key�����ڸ����Ĺ�ϵ�У������������Ի���С�����飬���ڲ�ͬ��Ԫ���е�ֵ�Dz�ͬ�ģ����������Щ��ֵ����Ψһ�ر�ʾ��ϵ�е�Ԫ�飬��Ƹ����ԣ��飩Ϊ��ѡ����
• ���루������Primary key������ѡ�����ܲ�ֹһ������ָ������ʹ�õغ�ѡ����������
• ������Super Key������Ψһ��ʶԪ������Լ������к�ѡ�����dz�����������С���Լ��������ж������ԡ�
• ��ϼ���ȫ�������������ǵ�һ������ʱ����ϼ�����ϼ�������������ʱ��ȫ����
• �ⲿ����Foreign Key������ϵģʽ R �е����Լ���������ϵģʽ����������ô�����Լ��Թ�ϵģʽ R �����������
• �����Ժͷ������ԣ���������һ��ѡ���е����Խ������ԣ�����Ʒ������ԡ�
2. ��ϵ����ģ�͵IJ�����������Լ����
• ���롢ɾ�����²������������ϵ��������Լ����
• ��ϵ��������Լ��������ʵ�������ԡ����������Ժ��Զ���������
3. ��ϵģ�͵Ĵ洢�ṹ��
• ʵ���ʵ������ϵ���ñ�����ʾ
4. ��ϵ����ģ�͵���ȱ�㣺
• �ŵ㣺
1) �������ϸ����ѧ���������
2) ���һ��ʵ�塢��ϵ���ù�ϵ����ʾ
3) ��ȡ·�����û��������ݶ����Ը��ߣ������Ը��á�����Ա���������ݿ������������
• ȱ�㣺
1) ��ȡ·�����û�������ѯЧ�ʲ���
2) ���ȡ·�����û�����������û���ѯ�����Ż��������˿��� DBMS
���Ѷȡ�
1.3 ���ݿ�ϵͳ�Ľṹ������
1.3.1 ���ݿ�ϵͳ��ģʽ�ṹ(�ӹ���ϵͳ�Ƕȿ�)
➢ �ͣ�type����ֵ��value�����������ݽṹ�����Ե�˵����ֵ���͵ľ��帳ֵ��
➢ 1975,�������ұ�ѧ�ᣨANSI���ı��ƻ���Ҫ��ίԱ�ᣨSPARC:Standard Plan And Request Committee����������ݿ��������ͨ���� SPARC �ּ��ṹ��
1. SPARC �ӿڷ������ṹ������ӳ��
1) �ڲ������ڲ���ͼ���洢��������������ģʽ���洢ģʽ
���д洢�ڼ��������ϵ������ļ���һ�����ݿ�ֻ��һ����ģʽ��
2) �����������ͼ��ȫ��������ģʽ������ģʽ
�����������ݿ���������ṹ��һ�����ݿ�ֻ��һ��ģʽ��
3) �ⲿ�����û���ͼ���ֲ���������ģʽ����ģʽ��
�����ݿ����û��Ľӿڣ����û��ֲ�����������һ�����ݿ�����ж����
|
|
schema
|
view
|
level
|
|
External
|
��ģʽ����ģʽ
|
�û���ͼ������ͼ
|
�ⲿ�����ֲ�����
|
|
conceptual
|
ģʽ������ģʽ
|
������ͼ��DBA ��ͼ
|
�����ȫ������
|
|
internal
|
��ģʽ���洢ģʽ
|
�ڲ���ͼ
|
�ڲ��������������洢��
|
2. ���ݿ�Ķ���ӳ���������ݶ�����
• ����ģʽ/��ģʽ��ӳ��
• ����ģʽ/��ģʽ��ӳ��
• ���������ԣ����洢�ṹ�ı�ʱ������ͨ���ĸ���ģʽ/��ģʽ��ӳ��ʹ������ֲ��㣬�����ⲿ����Ӧ�ó���Ҳ����ı䡣
• �������ԣ�����������ı�ʱ������ͨ���ĸ���ģʽ/��ģʽ��ӳ��ʹ�ⲿ���������ֲ��䣬Ӧ��Ҳ�Ͳ���ı䡣
1.3.2 ���ݿ�ϵͳ����ϵ�ṹ���������û��Ƕ���������
➢ ���ݿ�Ӧ�õ�������Σ��洢�㡢ҵ�����㡢�����ʾ��
➢ ��ϵ�ṹ��
1. ���û� DBS
2. ����ʽ�ṹ DBS���ն˷�ʽ��
3. �ͻ�/�������ṹ DBS ��BS ���� DBS
4. �ֲ�ʽ�ṹ DBS
1.3.3 *���ݿ�ϵͳ�����
➢ ��ɣ�
• �����Ӳ�� CPU���ڴ桢Ӳ��
• ��������� OS��DBMS��Ӧ����������Ӧ�ó���
• ���ݣ��⣩
• ����Ա���û�
1.4 ���ݿ����ϵͳ
1.4.1 ���ݿ����ϵͳ�Ĺ��������
➢ DBMS ����
1) ���ݶ��� ��DDL ʵ�֣�
2) ���ݲ��� ��DML �� DCL ʵ�֣�
3) ���ݿ����й���
• ��ȫ�Լ��
• �����Լ��
• ��������
• �����������ֵ���ڲ�ά��
4) ������֯���洢������
• �������ֵ䡢�û����ݡ���ȡ·���ȵ���֯���洢����
5) ���ݿ⽨����ά������
• ���ݿ����ݵ����롢����ת��
• ���ݿ��ת����ָ�
• ���ݿ���������ع�
• ���ܼ��������
6) ����ͨ�Žӿڹ���
➢ DBMS ���
1) ���ݶ�������(DDL Data Definition/Description Language )
2) ���ݲ�������(DML Data Manipulation Language )
3) ���ݿ����п�������(DCL Data Control Language )
4) ʵ�ó���
1.4.2 ���ݿ����ϵͳ�Ĺ�������
➢ �û���ȡ���ݿ����ݵĹ��̣�
�� �û��ڳ�����Ƕ�� DML ��һ������¼��䡣����ת�� DBMS��
ȫ�ױ�ҵ��������ֳɳ�Ʒ��������ѯ�źţ�biyezuopinvvp QQ��1015083682
������ҳ
�������ش����ϣ����ѣ�
��ת����ע����Դ��www.biyezuopin.vip
