面向目标探测与跟踪的相控阵雷达波束调度策略研究
1、背景说明
1.1、研究对象的应用意义
相控阵雷达在军事和民事领域都占据着举足轻重的地位。军事上,它是防空反导系统的核心感知部件,可远距离探测敌机、导弹等目标,为军事决策提供精准情报,助力掌握制空权;在民事领域,于航空管制中能严密监控航班飞行轨迹,保障空中交通顺畅,在气象监测方面可细致分析云层结构与降水分布,提升气象预报的准确性。
相控阵雷达可以利用波束形成技术发射波束,该波束具备指向性且角度、宽度可控,通过扫描监测区域达成目标探测、定位与跟踪等任务。在探测时,依据波束反射回波判断目标存在;定位则依靠计算波束发射角度和回波时间来确定目标坐标;跟踪时持续接收回波更新目标位置信息。
1.2、国内外研究现状
国外相控阵雷达波束调度研究起步较早,已形成较为完善的理论体系。其中Blair等学者提出了基于任务优先级的调度方法,美国研究人员将智能优化算法应用于波束时间分配,英国学者则着重研究了自适应波束调度技术。研究趋势主要表现为向智能化发展,更加注重多任务协同和自适应性增强。
我国在该领域虽起步较晚但发展迅速,国防科技大学深入研究了时间资源管理理论,哈尔滨工业大学开展了多目标跟踪场景下的调度优化,西安电子科技大学在深度强化学习应用方面取得进展。目前该领域面临实时性要求高、算法鲁棒性不足等挑战,未来研究重点将集中在提升系统性能、完善理论体系等方面。
1.3、亟需解决的问题
然而在监测任务里,发现新目标与跟踪已有目标相互矛盾。跟踪已有目标时,需集中波束于目标以获取精确信息,如此一来,用于扫描其他区域以发现新目标的波束资源就会减少,新目标被发现的几率随之降低;而若侧重扫描未知区域寻找新目标,分配给已有目标跟踪的波束能量和时间减少,跟踪精度必然下降,这对相控阵雷达的综合性能提升构成了重大挑战。
2、 主要内容
主要内容
2.1、课题期望
本课题研究波束资源调度策略,保证雷达在精确跟踪已有目标的同时,还能及时地发现新目标。具体而言,本课题研究在各种不同的情况下,相控阵雷达应该选取什么样的发射波束照射监测区域,从而能达到精确的目标跟踪和及时的目标探测等目的。、
2.2、项目研究关键点
1、相控阵雷达及其工作环境的仿真问题研究
2、相控阵雷达的波束资源调度分配研究
3、通过机器学习算法对雷达获取信息的处理
4、通过强化学习方法构建雷达智能体
5、采取何种环境数据和何种Q - Function训练智能体的波束调度策略
3、 工作方案
工作方案
3.1、学习相控阵雷达波束调度的基本工作原理
通过学习基本工作原理,从而理解何种波束更适合探测目标,何种波形能更精准的跟踪目标,以此来决定如何控制相控阵雷达波束调度策略,为通过强化学习结合神经网络方法训练相控阵雷达智能体提供控制基础。
3.2、ROS以及模型构建工具Gazebo仿真建模
ROS中内置的Gazebo具有强大的3D仿真能力,可以很好的模拟相控阵雷达的工作环境,并且可以通过编程雷达节点,让雷达与环境数据产生交互,从而实现通过强化学习算法用环境数据训练雷达智能体的效果。
3.3、环境数据的产生及处理
在构建雷达探测的仿真环境时,可通过精心设定多种具有不同尺寸规模、运动速率以及行进方向的可探测物体,并且借助编程语言或数学软件所提供的随机数生成功能,构建符合高斯分布的噪声样本。在成功生成噪声样本后,将其逐一对应地叠加至原始环境数据之上,从而全面检验雷达系统在复杂目标场景下的探测性能与精准度,为其在实际应用中的可靠性与有效性提供坚实的数据支撑与性能评估依据。同时,由于原始环境数据是人为构造且可知的,可以对智能体决策的正确率作出准确的评估。
3.4、卡尔曼滤波算法雷达信息处理
在相控阵雷达系统中,我们需要从带有噪声的测量数据中尽可能准确地估计系统的状态。例如,在雷达跟踪目标时,由于环境干扰、测量设备本身的精度限制等因素,接收到的目标位置、速度等信息都包含噪声。在系统满足线性和噪声为高斯分布的假设下,卡尔曼滤波提供了一种最优的状态估计方法。它能够根据系统的动态特性和测量数据,以最小均方误差(MMSE)为准则,动态地融合预测信息和测量信息,得到系统状态的最优估计。它能够根据系统的动态模型和一系列带有噪声的测量值,有效地估计系统的真实状态。通过这种方法,我们可以为智能体训练提供更符合实际测量的雷达数据。
3.5、函数逼近器Q-function的构建及更新机制
对于雷达智能体,状态空间应该包含与雷达探测任务相关的各种信息。例如,雷达接收到的目标回波信号强度、目标的方位角、俯仰角、目标与雷达的距离、目标的速度估计(通过多普勒频移等方式获得)以及雷达自身的工作状态(如波束指向、发射功率等)。这些状态变量构成了一个多维的状态空间,用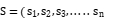 )表示,
)表示,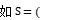 距离,方向,速度)。
距离,方向,速度)。
动作空间是雷达智能体能够采取的动作集合。对于雷达来说,动作可能包括调整波束的指向(在方位角和俯仰角方向上)、改变发射功率、切换工作频率、改变信号处理模式等。动作空间用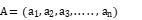 ,每个
,每个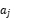 表示第j个动作,如
表示第j个动作,如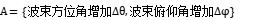 。
。
基于上述定义的状态空间和动作空间,Q - 函数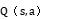 可以用函数逼近器构建,在相控阵雷达波束调度复杂场景中,常采用神经网络逼近 Q - 函数。神经网络输入层接收状态向量s,输出层输出对应各动作的
可以用函数逼近器构建,在相控阵雷达波束调度复杂场景中,常采用神经网络逼近 Q - 函数。神经网络输入层接收状态向量s,输出层输出对应各动作的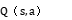 值。其输入神经元数量等于状态空间的维度,输出神经元数量等于动作空间的维度。中间层可以根据具体的复杂度需求设置一定数量的隐藏层和神经元。
值。其输入神经元数量等于状态空间的维度,输出神经元数量等于动作空间的维度。中间层可以根据具体的复杂度需求设置一定数量的隐藏层和神经元。
神经网络输出层的每个神经元对应一个动作的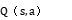 值。在决策时,智能体选择具有最高值的动作。例如,如果输出层有 5 个神经元,分别对应 5 个不同的雷达动作,智能体比较这 5 个输出值,选择最大
值。在决策时,智能体选择具有最高值的动作。例如,如果输出层有 5 个神经元,分别对应 5 个不同的雷达动作,智能体比较这 5 个输出值,选择最大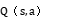 值对应的动作来执行。
值对应的动作来执行。
在雷达智能体与环境进行交互的过程中,根据智能体采取的动作、当前状态、获得的奖励以及下一个状态来更新 Q - 函数。通常采用的更新公式(以DQN为例)是:

其中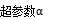 是学习率,用于控制更新的步长,
是学习率,用于控制更新的步长,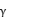 是折扣因子,用于权衡即时奖励和未来奖励的重要性,
是折扣因子,用于权衡即时奖励和未来奖励的重要性,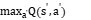 表示在下一个状态
表示在下一个状态 下采取最优动作的Q值。
下采取最优动作的Q值。
在雷达探测场景中,奖励可以根据雷达是否成功探测到目标、目标跟踪的准确性等因素来设定。例如,如果雷达成功探测并跟踪到目标,给予一个正奖励;如果丢失目标或者出现误判,给予一个负奖励。
3.6、通过环境数据训练DQN构建智能体
借助设定的大量环境数据训练由深度 Q 网络(DQN)构建的具备自我迭代优化能力的雷达智能体,使其具备完成自主决断波束控制策略及目标探测跟踪等任务,进而有效提升雷达系统的智能化程度与任务执行效率。
 4、进度安排
4、进度安排
1周-2周:与导师沟通,充分理解毕设任务。调研相关论文,加深对任务的理解。学习目标跟踪的常用算法。
3周-4周:重点关注本领域的主流方法和模型,理解方法的思路和细节。
5周-6周:使用Python代码复现主流方法或模型,理解仿真结果。
7周-8周:提出基于强化学习的面向目标探测与跟踪的相控阵雷达波束调度策略,
9周-10周:使用Python代码仿真所提出的方法。
11周-12周:撰写毕业设计论文。
13周-14周:完善代码、完善论文,准备毕业设计答辩。
 5、最终成果
5、最终成果
本课题涉及雷达波束调度策略。完成本课题后,工作内容及具体要求如下:
1. 提出一个相控阵雷达波束调度策略算法,可以在精确跟踪目标的同时,及时发现新目标。
2. 完成相控阵雷达波束调度策略的仿真代码,实现算法的基本功能。
3. 完成多种不同的典型仿真场景,体现出算法在多种不同的情况下都能完成精确的目标跟踪和可靠的目标探测。
4. 完成本科毕业设计论文,论文规范符合哈尔滨工程大学相关要求。
5. 完成本科毕业设计答辩,答辩结果须达到良好或优秀。
6. 完成一篇论文。
