基于WxJava框架的集客微信公众号的设计与实现
0 TODO List
1. 微信公众号的配置
2. 服务器框架的选择与搭建
3. 后台获取用户授权,储存用户信息
4. 新闻的抓取与存储
1 微信公众号的配置
1.1 配置基本接口信息
在成功申请公众号后,为了快速进入微信公众号的后台开发,我们可以申请微信公众号的开发者测试账号。在测试账号管理中,我们会得到微信颁发的appID和appsecret,将两者写入后端代码,然后使用appID和appsecret发送请求,我们就可以获取access_token用于验证公众号信息。
在测试号配置当中,我们还需要配置基本接口信息,填写正确的URL响应微信发送的Token验证。用于Token验证的URL必须是二级域名并且支持HTTPS协议,但是在开发过程中,服务器只能使用自己的主机,因此需要使用内网穿透让微信服务器可以访问到自己的服务器。这里我们使用了NATAPP,NATAPP是基于ngrok的高速内网穿透服务,我们在购买隧道和域名后,将域名解析到127.0.0.1便可以使微信服务器访问到本机。
在后端,我们需要编写验证Token验证的代码,通过检验signature对请求进行校验。若确认此次GET请求来自微信服务器,请原样返回echostr参数内容,接入生效,成为开发者成功,否则接入失败。加密/校验流程如下:
1)将token、timestamp、nonce三个参数进行字典序排序
2)将三个参数字符串拼接成一个字符串进行sha1加密
3)开发者获得加密后的字符串可与signature对比,标识该请求来源于微信。
以上是微信公众号的基本接口配置,在配置完这些基础接口后,我们需要对公众号的自定义菜单以及菜单入口进行配置。使用access_token发送修改菜单栏请求到微信服务器,在请求中设置菜单栏的按钮类型与外部URL,即可完成对菜单栏的配置。
1.2 配置中出现的问题
在配置基本接口信息中,只能填写二级域名,但是申请的阿里云二级域名不能实现NAT穿透,并且无法申请SSL证书,因此需要使用NAT穿透服务,将域名解析到本机地址。这里我们使用了NATAPP服务,申请了二级域名并且将域名解析到本机,解决了接口的URL配置问题。
2 服务器框架的选择与搭建
2.1 服务器框架的选择
在服务器框架的选择方面,我们需要使用一个轻便、可扩展、高性能的服务器框架。针对以上特点,我们选择了Spirng Boot + Mybatis + Redis + Lombok的服务器框架,使用Maven进行项目依赖管理,Git进行版本控制。使用Spring Boot,我们可以减少大量的开发配置时间,将精力集中在核心代码开发中,并且Spring Boot集成了Tomcat,非常方便我们进行运行调试。使用Redis的原因在于Redis作为NoSQL数据库,其数据都存储在内存中,性能极高,读速度是110000次/s,写速度是81000次/s,并且Redis还提供了丰富的数据类型与集群化模式。Lombok可以简化我们编写POJO的代码量,并且非常轻便,适合快速开发。
2.2 服务器框架的搭建
通过IDEA自带的Maven项目创建,在pom.xml文件中引入我们框架所需的依赖信息及版本,Maven会自动帮我们下载并引入依赖包。
Spring Boot采用约定式配置方式,因此只需要将基本信息进行配置即可。工程的基本配置在application.yml中进行配置,创建完application.yml后,在application.yml中对数据库的地址、用户名密码等基本信息进行配置,然后设置服务器的端口号,即可运行程序。
3 获取用户授权,储存用户信息
3.1 解决方案
用户点击菜单栏入口,进入客集平台首页之前,我们需要先取得用户的授权以获取用户的个人信息。微信用户的授权方式为OAuth 2.0协议,授权的过程中涉及到了多次请求的转发。当用户点击菜单栏入口后,后端主动向微信服务器发送一条获取权限的请求,并在请求中设置重定向URL。请求的格式为:
https://yok.mynatapp.cc/wechat/authorize?returnUrl=https://yok.mynatapp.cc
请求进入/ wechat/authorize路径后,后端需要向微信服务器发送一条获取授权的请求,以取得用户的授权,请求域为snsapi_userinfo(获取用户信息),请求的格式为:
https://open.weixin.qq.com/connect/oauth2/authorize?appid=%s&redirect_uri=%s&response_type=code&scope=%s&state=%s#wechat_redirect
当用户允许授权后,微信服务器会发送授权code到后端,此时还需要使用code再去请求一次微信服务器以获取access_token,请求格式为:
https://api.weixin.qq.com/sns/oauth2/access_token?appid=%s&secret=%s&code=%s&grant_type=authorization_code
在获取access_token后,我们将access_token储存在redis中,接下来就可以使用access_token去请求用户的个人信息。
4 新闻的抓取与存储
4.1 解决方案
在集客平台中,我们需要在页面向用户显示近期发生的新闻,而目前又没有一个可以使用获取我们想要的新闻的接口可以调用,因此需要我们实现一个可抓取新闻的脚本,并且能够将新闻储存在数据库当中。
这里我们选择了BeautifulSoup4去提取新闻关键词与内容,bs4的作用是能够快速方便简单的提取网页中指定的内容,给我一个网页字符串,然后使用它的接口将网页字符串生成一个对象,然后通过这个对象的方法来提取数据。以抓取人民日报为例:
图1:人民日报首页
人民日报目录中标签id为pageLink的<a>标签中包含了新闻的链接,我们 通过bs4解析到所有标签id为pageLink的<a>标签中的链接内容,然后遍历请求其中的文章链接。因为每篇新闻的css模板都相同,所以我们只需要使用相同的解析模板即可,以其中一篇新闻为例:
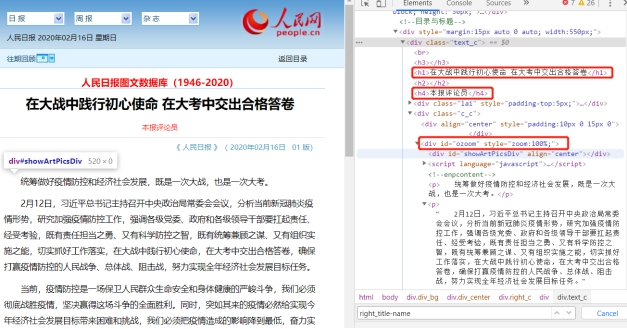
图2:新闻页面及布局
文章的标题保存在<h1>标签中,作者保存在<h4>标签中,文字内容保存在id为ozoom的<div>标签中,我们只需要依次从这些标签中解析出文字就可以获得文章的所有信息。
4.2 遇到的问题
解析过程中,如果出现图片,无法保存图片,只能保存链接,如果出现图文的形式,可能无法正确的保存图片在整篇文章中的位置。
Vue异步请求导致的问题