目录
一、基本信息
(一)立题依据
1. 选题意义
2. 国内外研究述评
3. 参考文献
(二)研究方案
1. 研究目标、研究内容及拟解决的关键问题
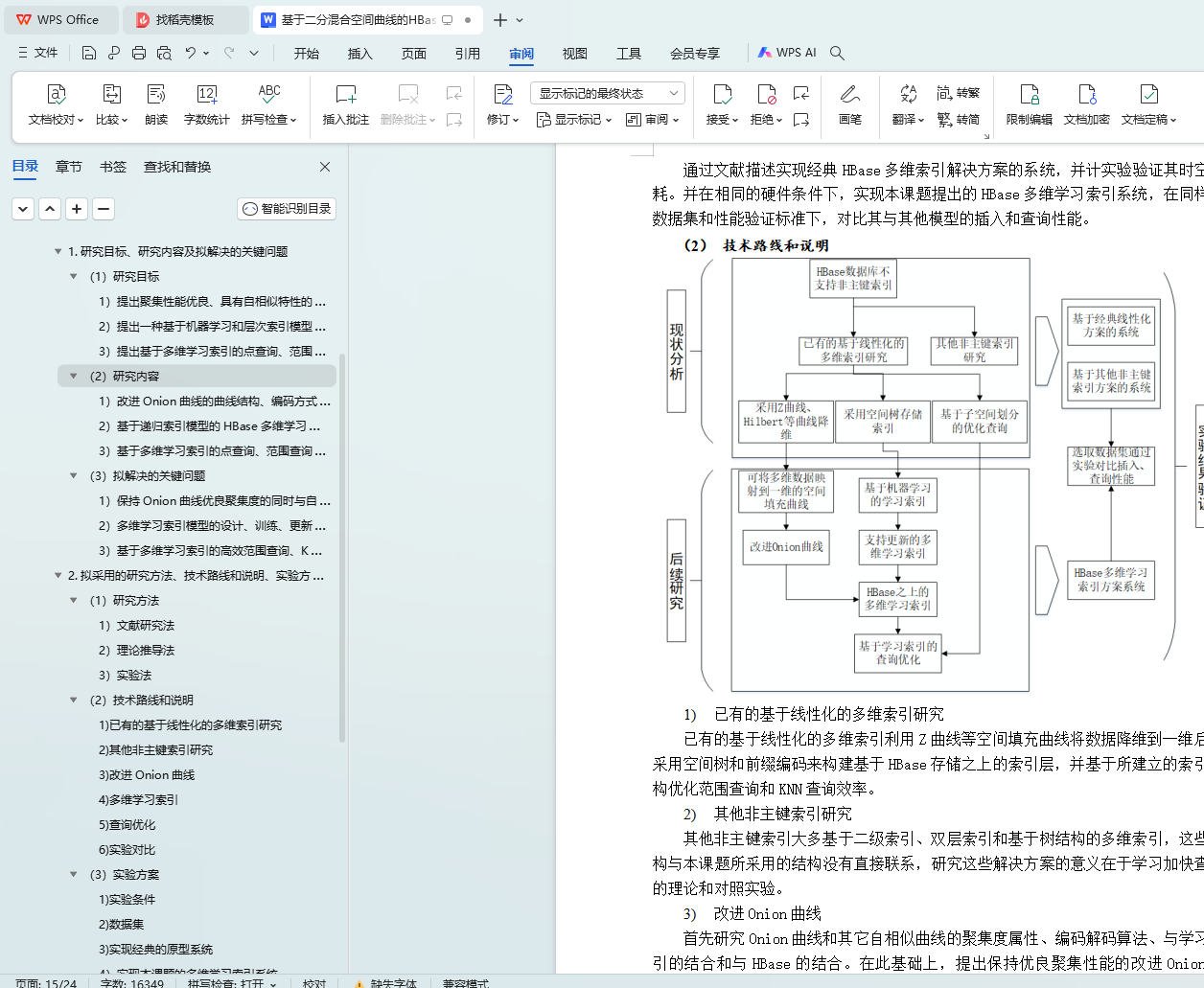
2. 拟采用的研究方法、技术路线和说明、实验方案及可行性分析
3. 本研究的特色与创新之处
4. 研究计划及预期研究结果
(三)研究基础
1. 已参加过的相关研究工作和已取得的研究工作进展
2. 已具备的条件,尚缺少的条件和拟解决的途径
3. 研究经费预算和经费落实情况
一、基本信息
|
开
题
者
基
本
信
息
|
学号
|
|
姓名
|
|
性别
|
男
|
出生年月
|
|
|
入学时最后学历
|
本科
|
入学时最后学位
|
学士
|
入学时最后毕业年月
|
|
|
入学时最后毕业院校
|
华北科技学院
|
入学时最后毕业专业
|
网络工程
|
|
入学时最后毕业论文题目
|
基于SpringBoot的家政系统的设计与实现
|
|
入学时
最后
毕业
论文
主要
研究
内容
|
(限400字):首先,研究家政系统结构规划、模块的功能及其联系,包括用户注册、权限的授予与获取、发布与搜索家政信息、热度排行等功能。其次,在技术上研究如何使用SpringBoot、Vue、Spring JPA等技术来实现系统代码。最后,采用Mysql数据库作为数据库的实现,在对表进行抽象设计之后建表。最终的系统采用Vue框架编写前端,SpringBoot框架来编写后端,Spring JPA框架和Mysql数据库来操纵底层数据,来实现之前设计的家政系统的相关功能。
|
|
选
题
基
本
信
息
|
论文名称
|
基于改进Onion曲线的HBase多维学习索引研究
|
|
主题词
|
改进Onion曲线 多维学习索引 HBase
|
|
研究题目
|
A
|
属于:A.导师课题一部分 B.委培单位的课题 C.其他
|
|
研究类型
|
B
|
A.基础研究 B.应用研究 C.综合研究 D.其他研究
|
|
选题来源
|
E
|
A.973、863项目 B. 国家社科规划、基金项目 C.教育部人文、社会科学研究项目 D.国家自然科学基金项目 E.中央、国家各部门项目 F.省(自治区、直辖市)项目 G. 国际合作研究项目 H.与港、澳、台合作研究项目 I.企、事业单位委托项目 J.外资项目 K. 国防项目 L.学校自选项目 M.非立项 N.其他
|
|
经费
|
万元
|
|
|
选题
中文
摘要
|
(限300字)
HBase 是基于Hadoop分布式文件系统的数据库,能够对海量数据进行随机、实时的读/写访问,然而HBase不支持基于非主键属性建立索引。学习索引是近年来人工智能和数据库领域的结合催生的新技术,能够降低传统索引的时空代价。
本课题首先采用自相似化的方法改进Onion空间填充曲线,将多维索引数据降维映射为一维序列。其次,基于存储的一维数据集,对层次索引模型(RMI)进行训练,模型学习数据的分布并预测输入的查询范围与存储位置的映射,从而构成位于HBase存储层之上的多维学习索引层。接着,通过子分区划分、预测误差等方法设计有效的点查询、范围查询和KNN查询算法。最后,基于上述理论,在实验环境集群上搭建一个原型系统,通过实验验证所构建系统基于多维学习索引的点查询、范围查询和KNN查询的性能,并与其他经典HBase非主键索引解决方案对比,来验证本课题提出的多维学习索引模型时空效率。
|
二、报告正文
(一)立题依据
1. 选题意义
互联网用户规模的日益增长,随之产生的是网络庞大的数据量。而在这庞大的数据量背后,蕴藏着巨大的价值。现在的企业应用系统的数据规模量己经达到了TB规模甚至PB规模。数据量正在急剧增加,如何有效地使用和存储这些巨大的信息是一场斗争。传统的关系型数据库管理系统(RDBMS)由于关系定义严格、水平扩展能力较差等局限性无法满足需求[1],为了有效应对海量数据的存储与查询管理人们越来越多地用 NoSQL分布式数据存储系统替代传统关系数据库。在众多优秀的分布式数据存储和管理系统中,HBase 以其基于开源分布式文件系统Hadoop的存储模式、海量数据条件下的高可靠性、高稳定性等特点脱颖而出,占有了很大的一块市场。
HBase底层所采用的存储结构为LSM树,是一种类似于B+树的存储结构,可以高效的支持基于主键的快速查询。然而,对于非主键的条件查询,HBase采用的是全表扫描并过滤的方式,从而导致查询速度慢、资源消耗大的问题。尽管HBase没有为辅助索引提供原生支持,但有些应用场景仍需要使用辅助索引[2],例如物联网、IoV、交通、地球科学等领域,基于非主键的多维查询是必要的。面对这样的问题,在RDBMS上通常会通过创建索引来解决。但是在分布式数据库上,创建索引要考虑到跨节点的问题。针对HBase的特性,本课题采用改进的Onion空间填充曲线来创建非主键多维学习索引,从而使HBase能够基于非主键索引来进行相应的查询。