1. 整个系统最终展现的功能是当用户将浏览器扩展安装成功后,打开豆瓣某评论页面即可将页面中的系统判断为虚假的评论标亮显示,实时性很重要。
2. 前台设计
实现一个谷歌浏览器扩展,(1)实现对浏览器用户动作的监听,当用户点开豆瓣某电影短评页面时使爬虫开始爬取且仅爬取该评论页面的评论及评论用户的id。(2)实现从数据库中读取已经做好标签的评论,将标签为1的评论在网页上实时标亮显示出来。
3. 后端设计
基于django框架,主要包括以下功能:
(1)实现API接口。实时接收前端插件指令。
(2)爬虫功能:接收到前台指令后,爬取用户在前端所点开的页面的评论及评论的id,将评论传输给大模型,并将评论及id存储到数据表中
(3)数据库设计:设计一个MySQL数据库,采用数据表存储评论、评论id以及评论虚假性标签。
(4)虚假评论识别:调用大模型,对传输进来的评论逐个进行判断,若判断为虚假评论则标为1,非虚假评论标为0,将判断结果同时存放于数据库对应评论的标签中。
根据以上设计,系统需要具备以下功能:
- 前端插件能够监听用户动作,并向后端发送指令。
- 前端插件还能实时读取数据库中标签为1的评论,将网页上的对应评论标亮显示
- 后端能够接收前端指令,启动爬虫工作,并将评论传输给NLP模型进行识别,将评论和评论id存到数据库中
- NLP模型能够准确识别虚假评论,并将结果存储于数据库中。
- 数据库能够存储评论、评论id以及评论虚假性标签,并支持实时更新。
- API接口能够实时接收前端命令,并实时判断和存储评论。
研究内容
虚假评论检测系统应该为用户浏览网页时提供一个更为简洁方便的工具。首先确定系统的两个主要模块。第一是面向系统设计者所设计的模型构建模块,包括数据处理模块、模型的构建、训练与测试模块,评论识别模块。第二是面向系统用户所设计的虚假评论检测与展示模块包括评论获取模块、实时通信模块和结果展示模块。
模型构建模块位于基于Django搭建的整体后台框架,分为三个子模块。首先,数据处理模块从数据库中读出评论数据,对其进行数据清洗等工作,便于后续模型的识别与判断;其次,模型的构建、训练与测试模块,最重要的部分在于深度学习模型的构建。第三,评论识别模块,接收到识别评论虚假性请求后对深度学习模型进行调用,获取评论判别结果,将结果存入数据库中。
虚假评论检测与展示模块:前台基于JavaScript编写浏览器扩展,后台基于Django框架。共分为三个子模块。首先,评论获取模块负责评论数据的获取,实现实时爬取豆瓣某电影评论页面的评论数据,并将评论数据其存入数据库中;其次,实时通信模块最重要的在于实时性,帮助用户实现对浏览器动作的监听,当用户点开某作品评论页面即向后台发送请求,调用评论获取模块、评论识别模块和结果展示模块,开始虚假评论识别与展示任务;第三,结果展示模块实现的是在用户浏览评论页面的同时读取数据库中评论与其标签,将对应标签为1的虚假评论在页面中标亮显示,为用户提供实时参考。
基于所构建的基于深度学习的虚假评论识别系统,对系统主要功能进行测试,验证系统有效性。
需求分析
虚假评论检测系统整体共包含两大模块:(1)模型构建模块,包括数据处理功能,模型构建、训练与测试功能和模型调用、评论判别和结果存储功能;(2)虚假评论检测与展示模块,包括评论数据爬取、数据存储功能,用户监听、前后台通信功能,以及模结果获取与展示功能。
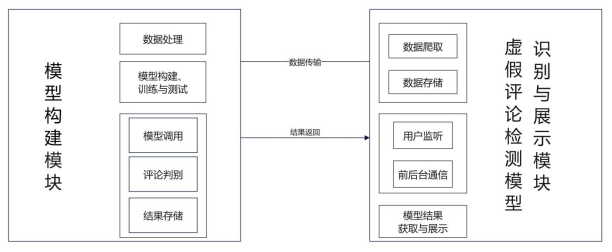
功能需求。
对于系统设计者,主要包括以下需求:
(1)数据处理需求:需要对于爬取的数据进行处理,对于爬取的数据,需要对于缺失的数据进行填补,不正确的数据进行修正。评论本身需要进行数据清洗,数据归一化处理等。同时我们需要分别对于评论内容数据进行词向量的特征替换。
(2)模型构建需求:根据评论内容,我们需要根据具体的数据性质来进行建模。对于内容,考虑使用语言模型进行建模,融合几种深度学习模型,目的是为了获得更好的判别结果。
(3)模型训练与测试需求:选取适当的数据集进行模型的训练,并进行模型微调,通过测试集测试训练结果。
(4)评论判别需求:当后端接收命令时,调用深度学习模型,读取数据库中所存爬取到的评论到模型中进行评论虚假性判别,将判别标签存入数据库中。
对于系统用户,主要包括以下需求:
(1)数据爬取需求:当前台监听到用户动作时发出爬取命令,爬取当前用户浏览网页的评论数据。
(2)前后台通信与实时数据传输需求:前台需要实时监听浏览器动作,向后台发送请求,后台需要向前台发送处理结果。评论数据,评论判别结果等需要在前后台之间进行实时数据传输。
(3)数据存储需求:爬取到的评论数据和评论判别标签存于数据库中
(4)模型结果获取与展示需求:系统会自动的返回对于输入的评论的判别结果。并在所浏览的页面将虚假评论标亮显示。
