1 项目概述
1.1项目需求和目标
课设内容是找一个数据集,上传至HDFS,用Spark读取HDFS上的数据并做分析,最后再可视化。
1.2开发环境和开发工具
(1)硬件(物理机、虚拟机和云平台等)
设备名称 宋芝桦
处理器 AMD Ryzen 7 5800H with Radeon Graphics 3.20 GHz
机带 RAM 16.0 GB (15.9 GB 可用)
设备 ID 63809797-43ED-4F1E-A3E1-54F4F028FBED
产品 ID 00342-36237-70737-AAOEM
系统类型 64 位操作系统, 基于 x64 的处理器
虚拟机内存 4G
处理器 4
硬盘 50GB
(2)软件(包括操作系统、各框架版本、主要类库等)
物理机:Windows11,VMware,X-shell 7,Xftp 7
虚拟机:anaconda3,Hadoop-3.1.3,spark3.0.0,jypyter,jdk1.8
2 大数据集群开发环境搭建
2.1安装准备
图1 虚拟机/云平台
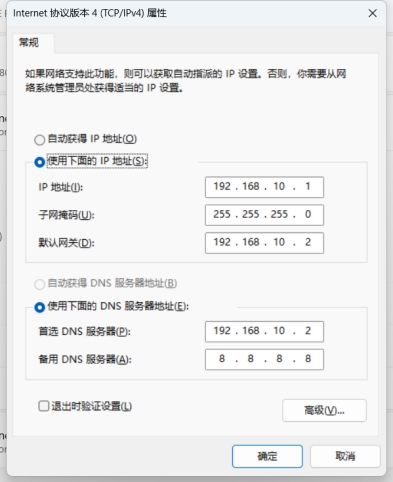
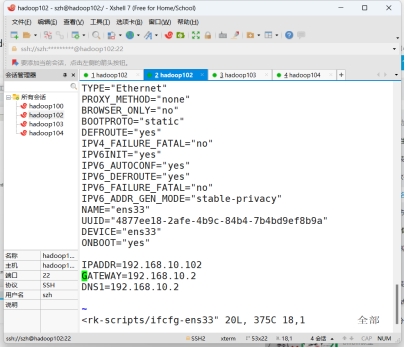
图2 网络配置

图3 配置用户root权限
2.2安装JDK

图4 配置JDK
2.3 Hadoop集群部署
1. 下载并解压Hadoop:
2. 配置环境变量:
3. 对Hadoop的配置文件进行编辑,这些文件包括core-site.xml, hdfs-site.xml, mapred-site.xml和yarn-site.xml,他们位于/opt/modele/Hadoop-3.1.3/etc/hadoop/目录下。
4. 格式化Hadoop文件系统:第一次启动Hadoop之前,需要先格式化Hadoop文件系统:hdfs namenode -format
5. 启动Hadoop集群:通过用start-all.sh脚本来启动Hadoop集群:Myhadoop.sh start

图5 启动集群
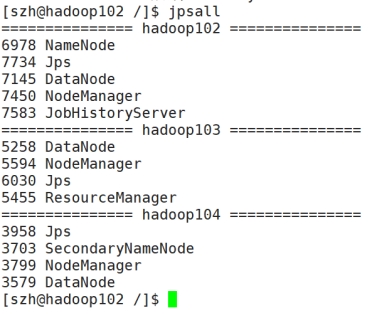
图6 启动集群成功
2.4 Spark集群部署
1. 准备集群环境:确保集群中的所有节点都满足Spark的部署要求,包括操作系统版本、Java版本、内存和CPU等。
2. 下载Spark安装包:从官方网站下载最新版本的Spark安装包,解压到所有集群节点的相同目录中。
3. 配置环境变量:在所有节点的~/.bashrc或~/.bash_profile文件中添加SPARK_HOME和PATH环境变量,指向Spark安装目录和可执行文件目录。
4. 配置主从关系:在Spark的conf目录中复制spark-env.sh.template文件为spark-env.sh,并根据需求配置其中的参数,比如设置SPARK_MASTER_IP为主节点的IP地址。
5. 启动集群:在主节点上运行sbin/start-all.sh脚本启动一个Spark集群。可以使用sbin/stop-all.sh脚本停止集群。
6. 验证集群:使用Spark自带的web界面或命令行工具查看集群状态,确保所有节点都成功连接。
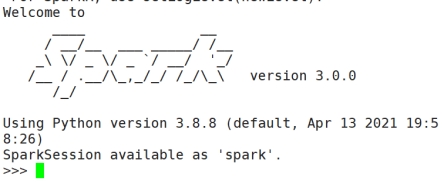
图7 启动spark
2.5 代码开发环境
Anaconda是一个数据科学和机器学习的开源发行版,包含了Python解释器、各种科学计算库和工具。而Jupyter是一个基于Web的交互式计算环境,支持多种编程语言,包括Python、R和Julia等。
Anaconda和Jupyter之间的关系是,Anaconda可以作为Jupyter的一个环境,通过Anaconda安装Jupyter后,可以在Jupyter中使用Anaconda提供的各种库和工具进行数据分析和机器学习任务。用户可以在Jupyter中编写和运行Python代码、创建交互式的数据可视化,以及撰写数据分析报告。
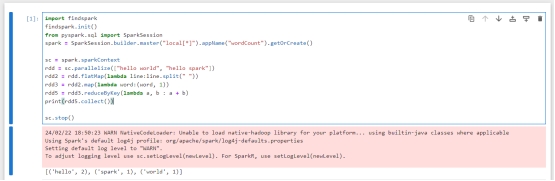
图8 jupyter成功
3 数据集
3.1 数据集获取和简介
(1) 数据集的获取:Individual Carbon Footprint Calculation (kaggle.com)
(2) 数据集字段介绍:
・ “体型”:体型。
・ “”:性别。
・ “饮食”:饮食。
・ “多久淋浴一次”:淋浴的频率
・ “供暖能源”:住宅供暖能源
・ “运输”:运输偏好。
・ “车辆类型”:车辆燃料类型。
・ “社交活动”:参与社交活动的频率。
・ “每月杂货账单”:每月在杂货上花费的金额,以美元为单位。
・ “乘飞机旅行的频率”:上个月使用飞机的频率。
・ “车辆每月行驶里程公里数”:上个月车辆行驶的公里数。
・ “垃圾袋尺寸”:垃圾袋的尺寸
・ “垃圾袋每周计数”:上周扔掉的垃圾量。
・ “TV PC Daily Hour”:每天在电视或 PC 前花费的时间。
・ “每月多少件新衣服”:每月购买的衣服数量。
・ “每天上网时间有多长”:每天在互联网上花费的时间。
・ “能源效率”:您是否关心购买节能设备。
・ “回收”:它回收的废物。
・ “Cooking_With”:用于烹饪的设备
・ “碳排放”:因变量,总碳排放量。
3.2 数据预处理
格式转换:

图9 格式转换代码
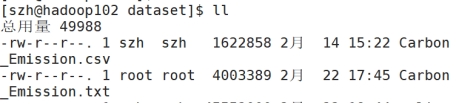
图10 格式转换结果
4 数据分析
4.1 数据存储
数据上传至HDFS:
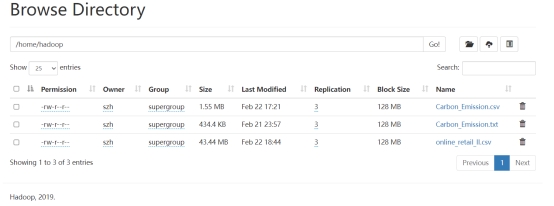
图11 数据上传至HDFS
4.2 数据读取
spark = SparkSession.builder.appName("example").getOrCreate()
# 读取CSV文件并创建DataFrame
df = spark.read.csv("hdfs://hadoop102:8020/home/hadoop/Carbon_Emission.csv", header=True, inferSchema=True)
4.3 数据分析
设计若干个分析指标(至少三个),用Spark编码实现。
(1) 体重中正常,肥胖,超重,体重不足之间所占比重
代码:df.groupBy("Body Type").count().show()
(2) 供暖能暖中煤,天然气,电力,木材之间所占比重关系
代码:df.groupBy("Heating Energy Source").count().show()
(3) 展示不同CarbonEmission的数量分布
(4) 展示两个变量Vehicle Monthly Distance Km与CarbonEmission之间的关系
(5) Relationship between Sex and CarbonEmission之间的联系
4.4 数据持久化
# 将可视化结果保存到本地文件
plt.savefig("sex_carbon_emission.png") # 指定保存文件名,可以是png、jpg等格式
5 数据可视化
(1) 体重中正常,肥胖,超重,体重不足之间所占比重
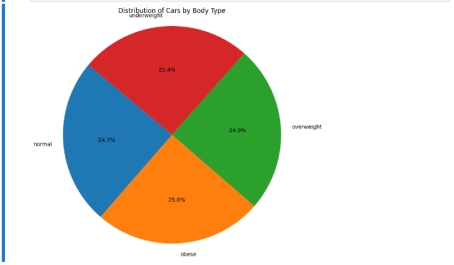
图12 体重特性
(2)供暖能暖中煤,天然气,电力,木材之间所占比重关系
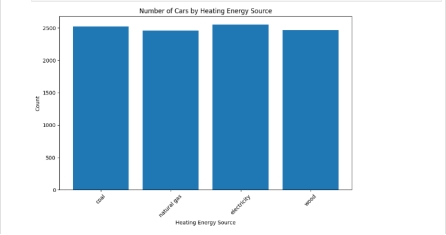
图13 供暖方式比重
(3)展示不同CarbonEmission的数量分布
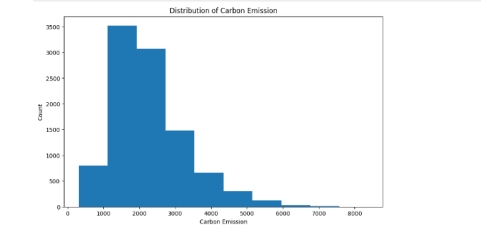
图14 不同CarbonEmission的数量分布
(4)展示两个变量Vehicle Monthly Distance Km与CarbonEmission之间的关系
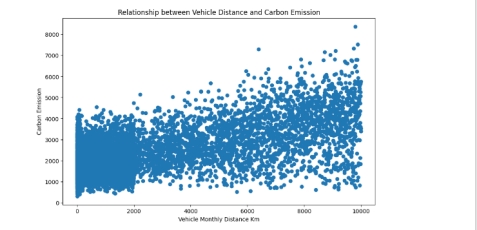
图15 Vehicle Monthly Distance Km与CarbonEmission之间的关系
(5)Relationship between Sex and CarbonEmission之间的联系
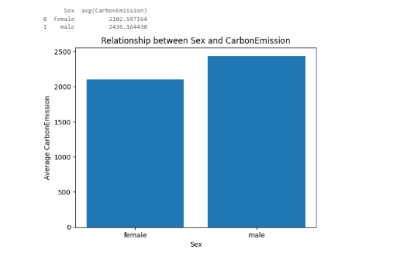
图16 Relationship between Sex and CarbonEmission之间的联系
6 总结
(1)数据上传至HDFS:已成功将数据集上传至Hadoop分布式文件系统(HDFS)。
(2)数据处理与分析:借助Spark工具成功从HDFS中读取了数据,并进行了预处理和转换等必要操作。
(3)数据可视化:使用Spark DataFrame等工具有效地将分析结果进行可视化展示。
(4)挑战及不足:在Hadoop配置过程中遇到问题,直接粘贴配置内容而未将其修改为插入模式,导致初始启动集群失败。此经验表明了配置时需要更加细心和谨慎,以避免类似问题的发生。
参考文献
[1]. Zaharia, M., Chowdhury, M., Franklin, M. J., Shenker, S., & Stoica, I. (2010). Spark: Cluster Computing with Working Sets. HotCloud, 10(10-10), 95-43.
[2]. Das, A., & Narayanankutty, K. (2016). Apache Spark for Big Data Analysis. Big Data Analytics, 23-40.
[3]. Laengle, S., Mulder, J., Smit, G. J. M., & Van den Heuvel, W. J. (2016). Large-scale graph analytics using Spark: A comparison of current paradigms. Journal of Parallel and Distributed Computing, 97, 112-127.
