���ڻ���ѧϰ�㷨�����ӷ����IJ������ﻯѧ�ɷ��о�
ժҪ
���Ļ�����Ŀ���������ݣ������ݽ�����Ԥ�����������Է����������˾������㷨�Բ����IJ������͡����Ρ���ɫ�ͷ绯�̶Ƚ��н�ģ���������ɭ�ֻع�ķ����Է绯ǰ�IJ�����ѧ�ɷֽ���Ԥ�⣬�����ලѧϰ�ķ�ʽ�Բ�����������Ƿ��࣬��ͨ������ѧϰ���㷨����ģ�ͣ��Բ�����Ʒ���������Ԥ�⣬���ͨ�����ӷ������в������ﻯѧ�ɷֵĹ������о���
�������һ������һ�ĵ�һ��ͨ������������ģ�ͣ����������ͣ������Լ���ɫ��Ϊ�Ա���������������ķ绯�̶���Ϊ���������������ģ�ͣ�����ͨ�����ƾ������ķ�ʽֱ�۵�չʾ���������ͣ������Լ���ɫ���ڲ����ķ绯�̶ȵ�Ӱ�졣����һ�ĵڶ�С����������ͨ�������������������������м��飬�ó��ز�����Ǧ�������ڻ�ѧ�ɷ��ϵIJ�ͬ���Ըز�����Ǧ�������ֱ���м��飬�ó��ز�����Ǧ�������绯ǰ��ѧ�ɷֵIJ�ͬ��ͨ�� F ��������ֲ������м��飬ɸѡ���벣���ķ绯�̶������������Թ�ϵ�Ļ�ѧ�ɷ֣���ΪԤ��绯ǰ�Ļ�ѧ�ɷ֡�����ҪԤ��������������ɭ�ֻع�ķ�ʽ���ν�����䣬��ɶԷ绯ǰ������ѧ�ɷֵ�Ԥ�⡣
����������������������绯����Ի�ѧ�ɷֺ�����Ӱ�죬��ͨ��������ͳ�������жԱ��о����õ���ͬ���������ֱ�۲��졣���Ž�һ��ѡ�������磬�������������͵ķ������⡣��ԭ���ݰ��� 5��1 �ı�������Ϊѵ��������Լ���ѡ�����֪����MLP��ģ�ͽ���ѵ������ͨ���������ķ�������ģ�ͷ����������õ�������ɡ�������ڶ�����Ҫ���ÿ�����ѡ��ѧ�ɷֽ�������֣��������ַ�������������Խ�����з����������Ƿ��࣬���Dz��õ����ලѧϰ����:Kmeans ��DBSCAN������ѡ���� Kmeans ���ֱ�ӻ�ѧ��ģ�ͽǶȷ����˺����Ժ������ԡ�
��������������δ֪���Ͳ����������⣬���������ȶԲ��������ݽ���������ǿ
Smote �㷨������������ݲ��������⡣���ų���ʹ�ö��ֻ���ѧϰģ�ͣ��������ɭ�֡�xgboost �ȣ���ͨ����Ҷ˹�Ż��ķ�ʽ���л���ѧϰģ�Ͳ������Ż������Ƚ���ȷ�ʣ������ŵó����ۡ�
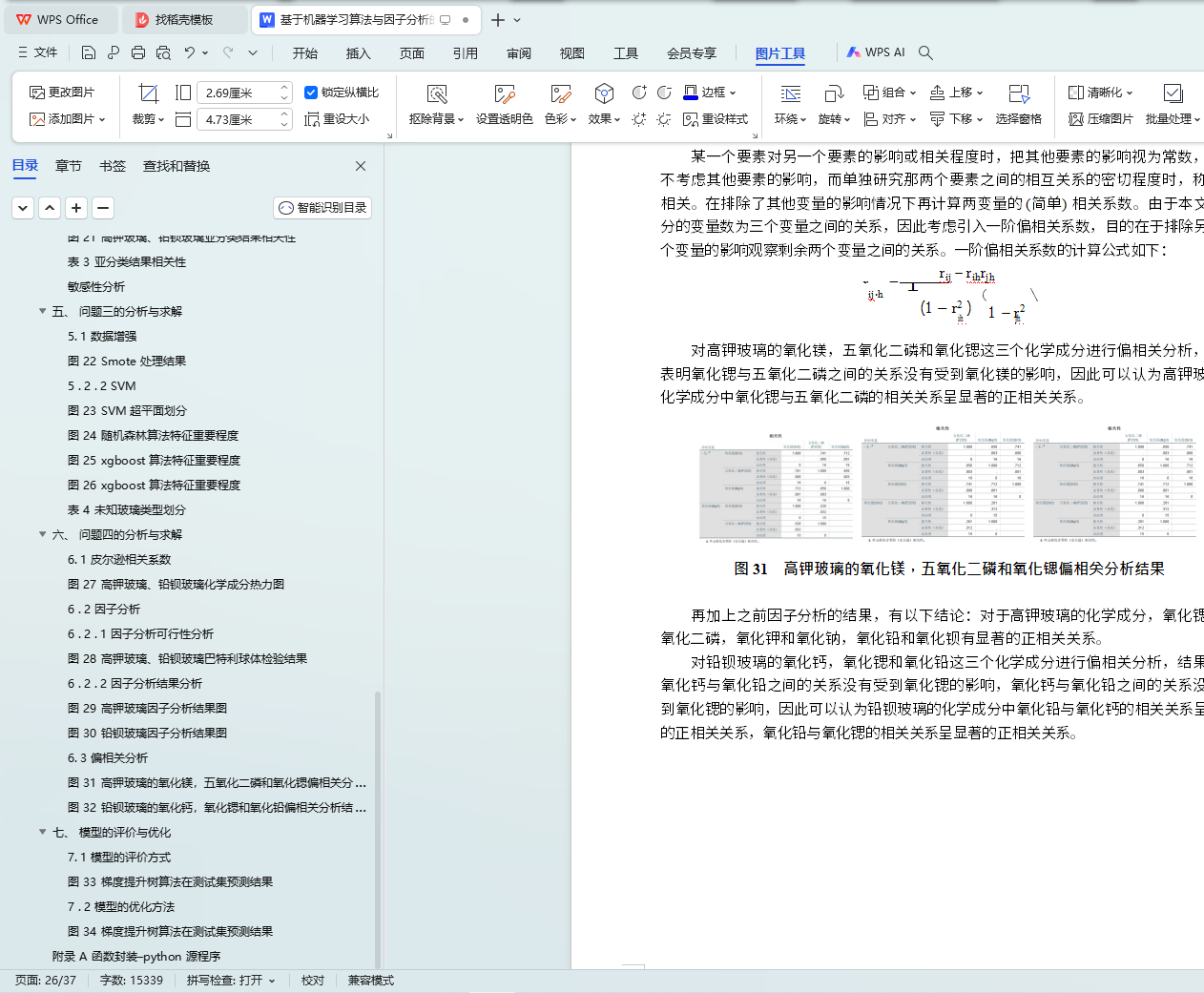
��������ģ������ȿ��ǶԲ�ͬ���IJ����Ļ�ѧ�ɷֽ��� Pearson ����Է����� ͨ����������Ծ���ķ�ʽ�۲����֮���Ƿ���������븺��صĹ�ϵ��֮���ȡ���ӷ����ķ�������ȡ��Ҫ���ӣ�������ת��ijɷ־����ԭ���Ļ�ѧ�������з��飬����һ���еĻ�ѧ�ɷ��нϸߵ�����ԡ����ǵ������ѧ�ɷ�֮����ܻ��л���Ӱ���������������ٲ�ȡƫ����Է�������һ�����������ص�Ӱ����Ϊ���������ݲ���������Ҫ�ص�Ӱ�죬�������о�������Ҫ��֮������ϵ�����г̶ȡ����ó����ۡ�
�ؼ��֣� �������� ����ѧϰ�㷨 ���ӷ��� ��Ҷ˹�Ż�
Ŀ¼
һ�� ��������
1 . 1 �����
1 . 2 �������
���� ����˼·��ģ����
2 . 1 ���������ģ����
2 . 1 . 2 ������ķ���
2 . 1 . 3 �������ķ���
2 . 1 . 4 �����ĵķ���
2 . 2 ����˼·
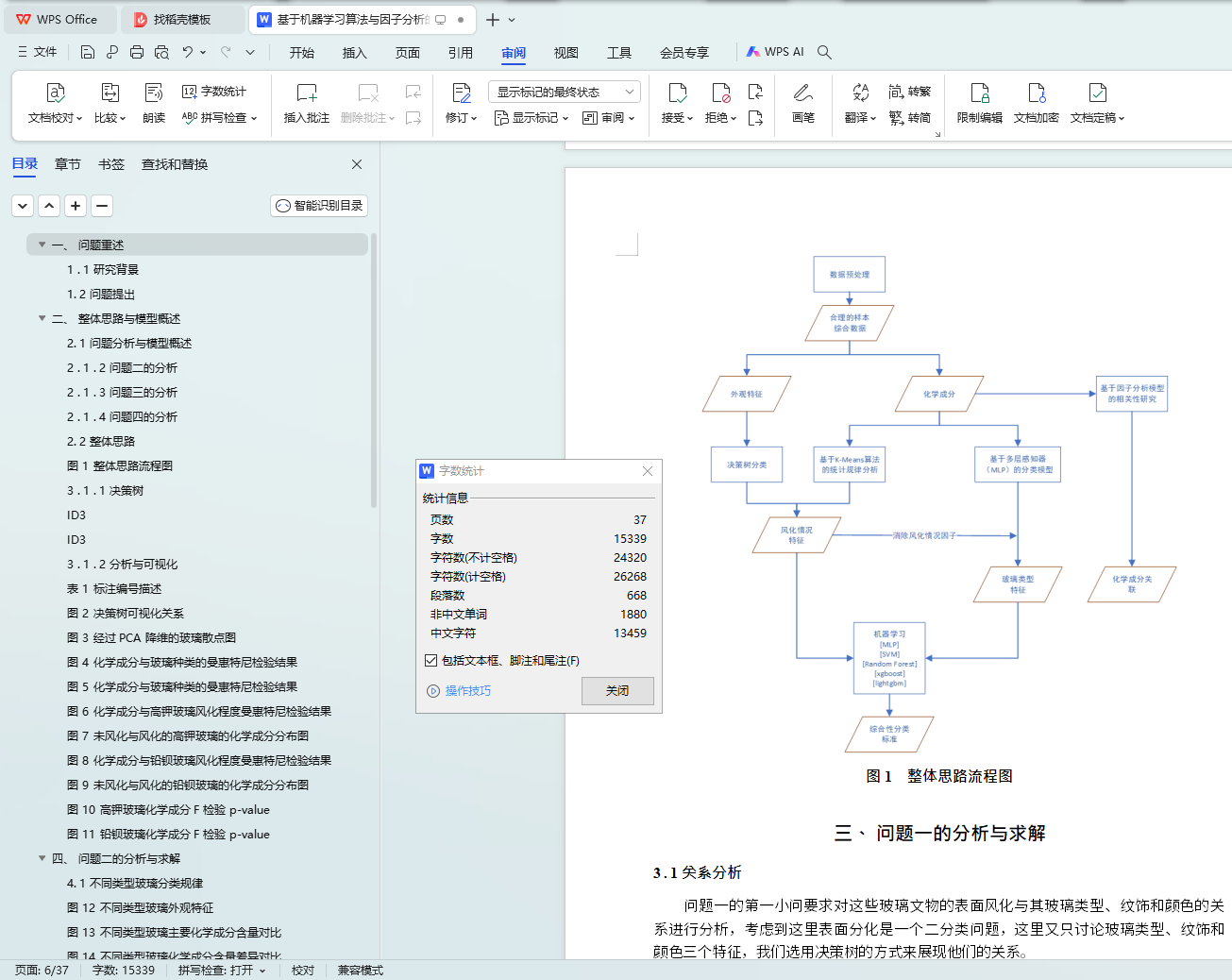
ͼ 1 ����˼·����ͼ
3 . 1 . 1 ������
ID3
ID3
3 . 1 . 2 ��������ӻ�
�� 1 ��ע�������
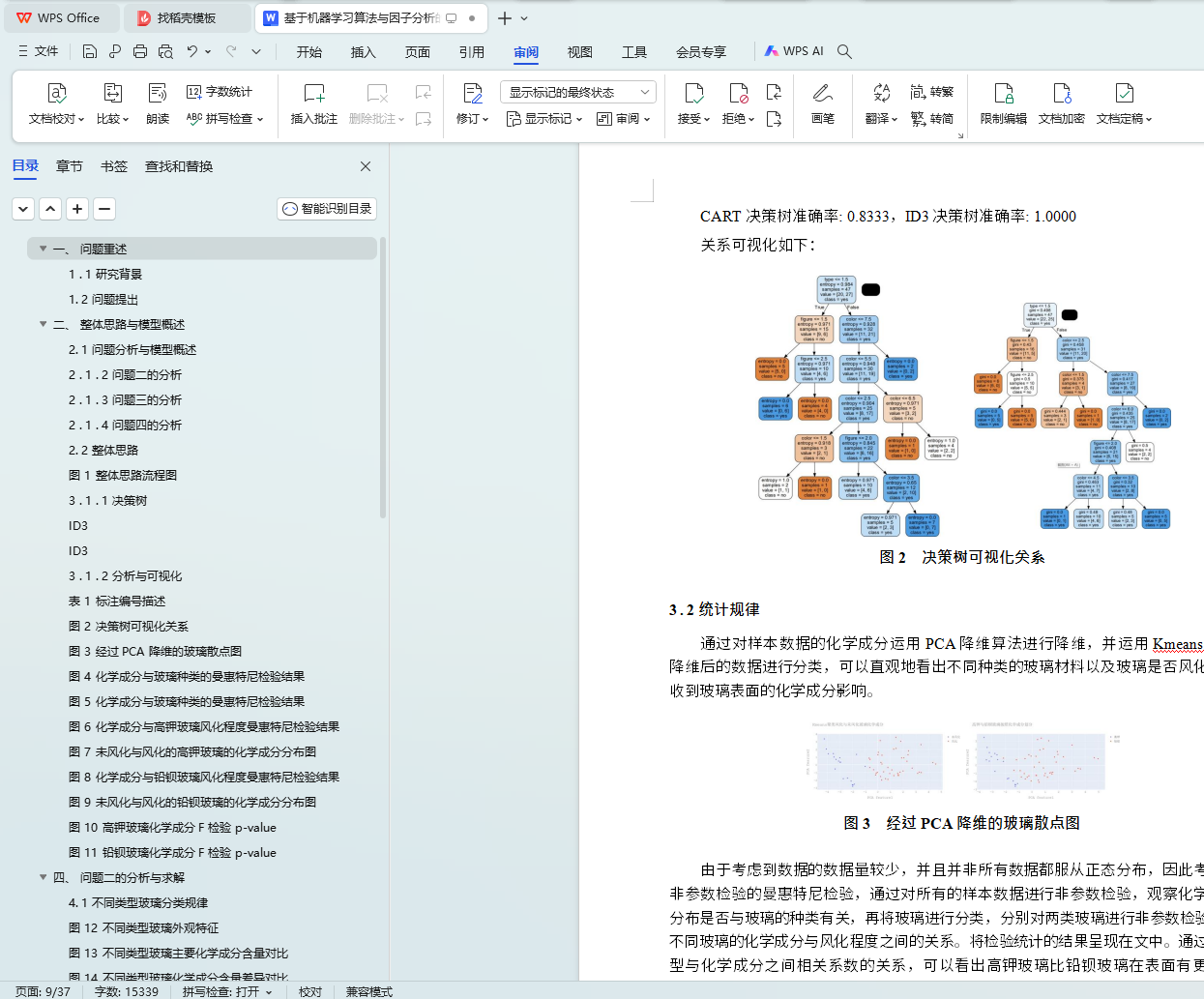
ͼ 2 ���������ӻ���ϵ
ͼ 3 ���� PCA ��ά�IJ���ɢ��ͼ
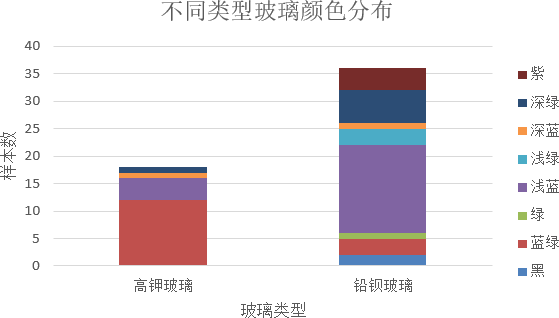
ͼ 4 ��ѧ�ɷ��벣��������������������
ͼ 5 ��ѧ�ɷ��벣��������������������
ͼ 6 ��ѧ�ɷ���ز����绯�̶��������������
ͼ 7 δ�绯��绯�ĸز����Ļ�ѧ�ɷֲַ�ͼ
ͼ 8 ��ѧ�ɷ���Ǧ�������绯�̶��������������
ͼ 9 δ�绯��绯��Ǧ�������Ļ�ѧ�ɷֲַ�ͼ
ͼ 10 �ز�����ѧ�ɷ� F ���� p-value
ͼ 11 Ǧ��������ѧ�ɷ� F ���� p-value
�ġ� ������ķ��������
4 . 1 ��ͬ���Ͳ����������
ͼ 12 ��ͬ���Ͳ����������
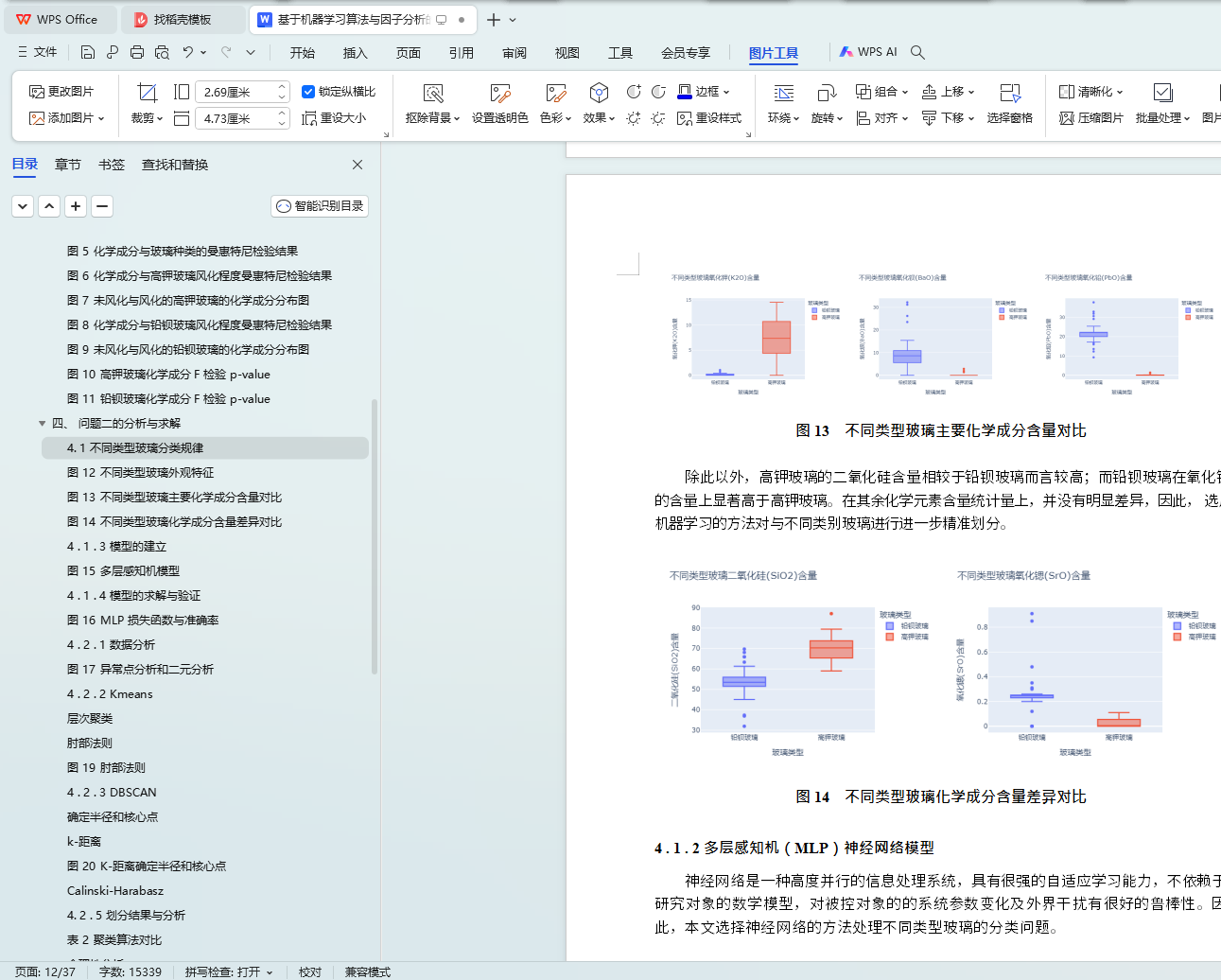
ͼ 13 ��ͬ���Ͳ�����Ҫ��ѧ�ɷֺ����Ա�
ͼ 14 ��ͬ���Ͳ�����ѧ�ɷֺ�������Ա�
4 . 1 . 3 ģ�͵Ľ���
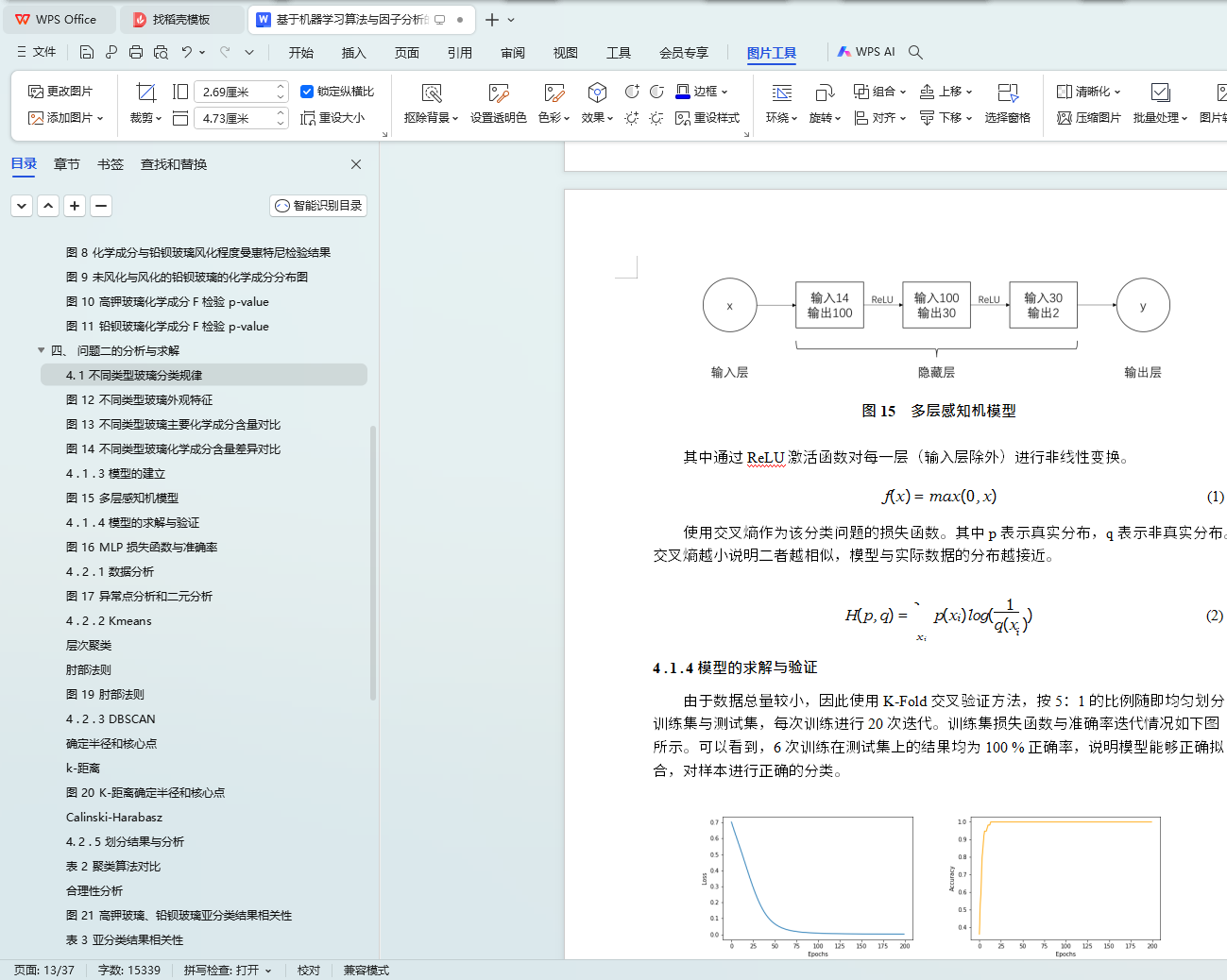
ͼ 15 ����֪��ģ��
4 . 1 . 4 ģ�͵��������֤
ͼ 16 MLP ��ʧ������ȷ��
4 . 2 . 1 ���ݷ���
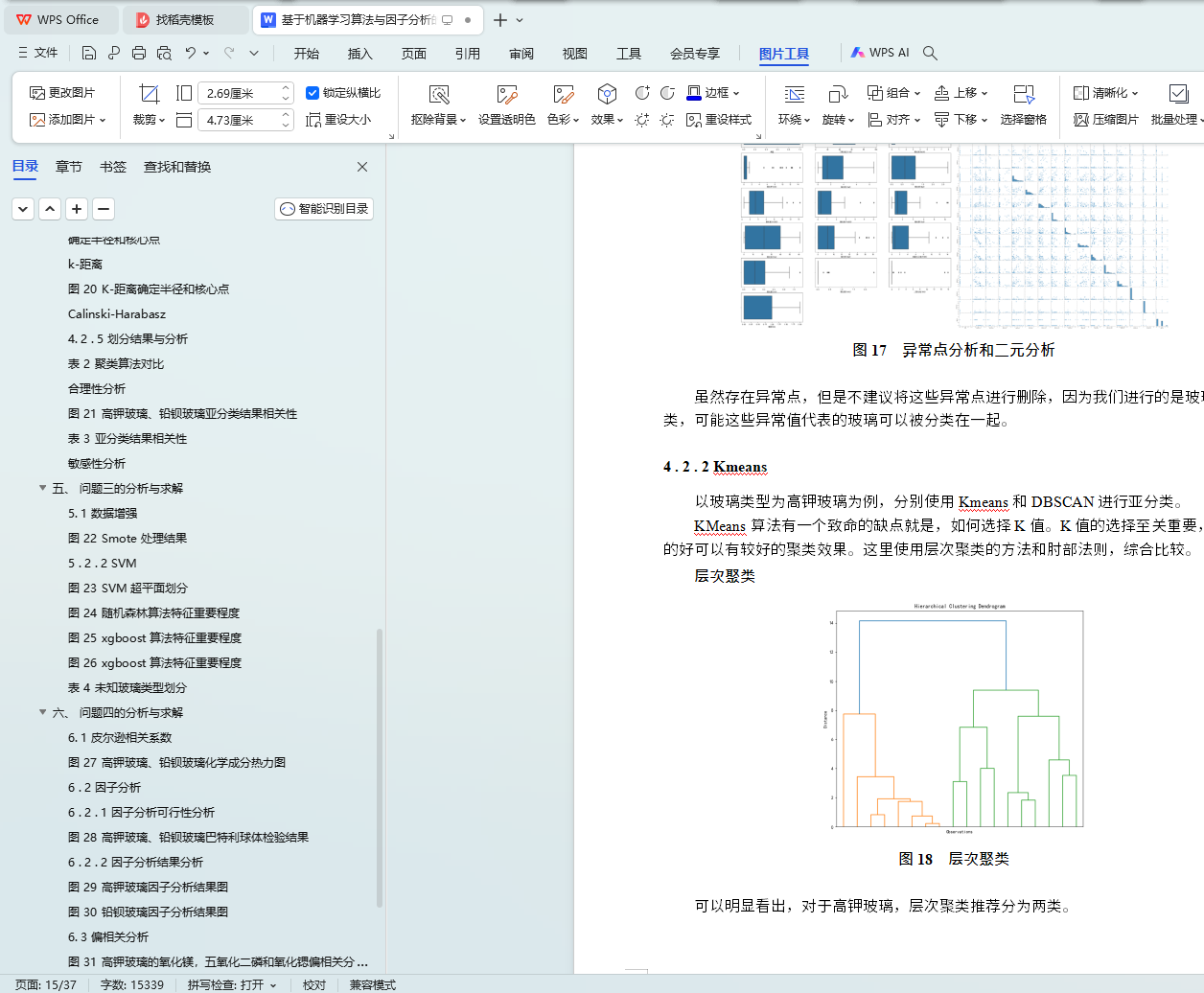
ͼ 17 �쳣������Ͷ�Ԫ����
4 . 2 . 2 Kmeans
����
�ⲿ����
ͼ 19 �ⲿ����
4 . 2 . 3 DBSCAN
ȷ���뾶�ͺ��ĵ�
k-����
ͼ 20 K-����ȷ���뾶�ͺ��ĵ�
Calinski-Harabasz
4 . 2 . 5 ���ֽ�������
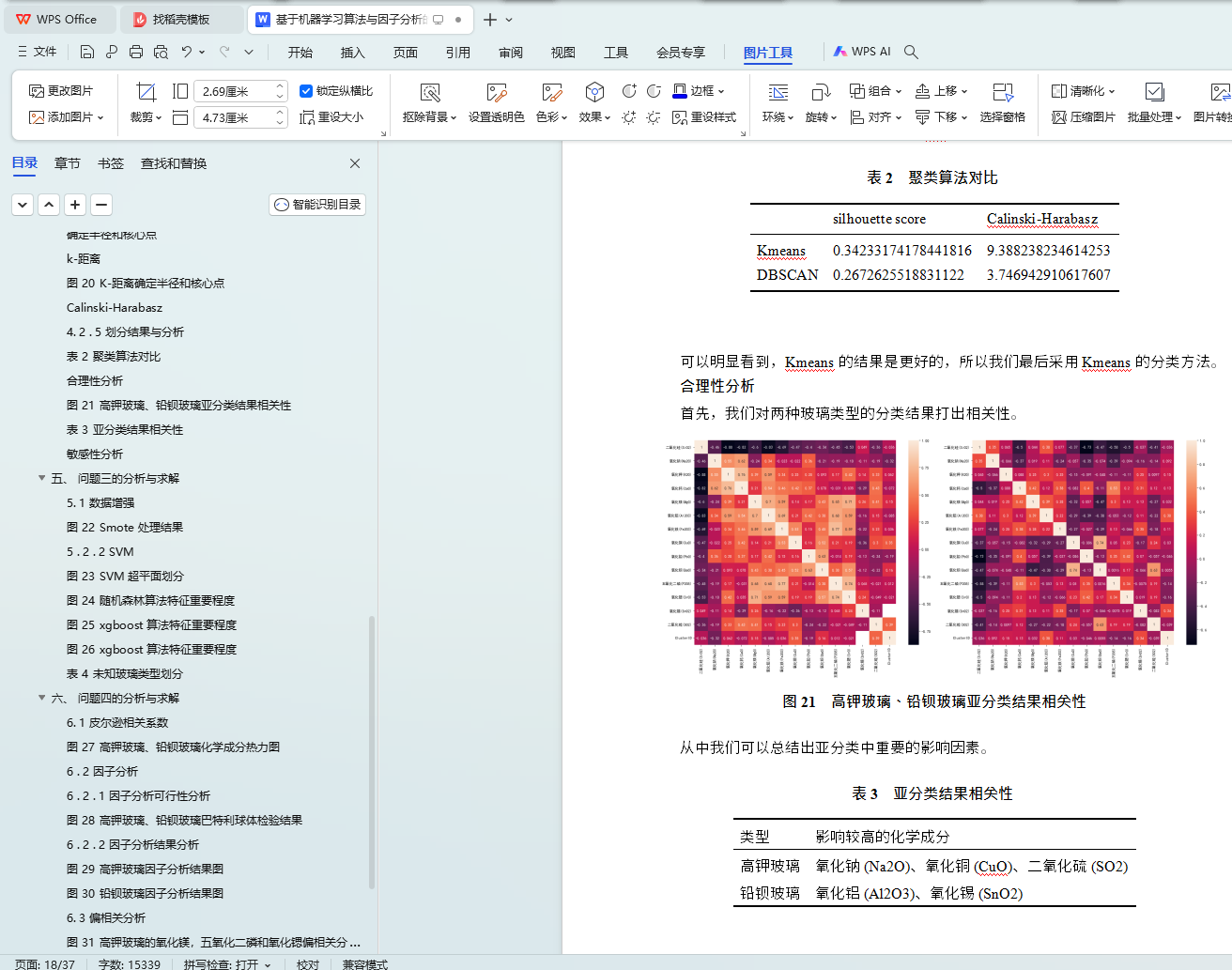
�� 2 �����㷨�Ա�
�����Է���
ͼ 21 �ز�����Ǧ�������Ƿ����������
�� 3 �Ƿ����������
�����Է���
�塢 �������ķ��������
5 . 1 ������ǿ
ͼ 22 Smote �������
5 . 2 . 2 SVM
ͼ 23 SVM ��ƽ�滮��
ͼ 24 ���ɭ���㷨������Ҫ�̶�
ͼ 25 xgboost �㷨������Ҫ�̶�
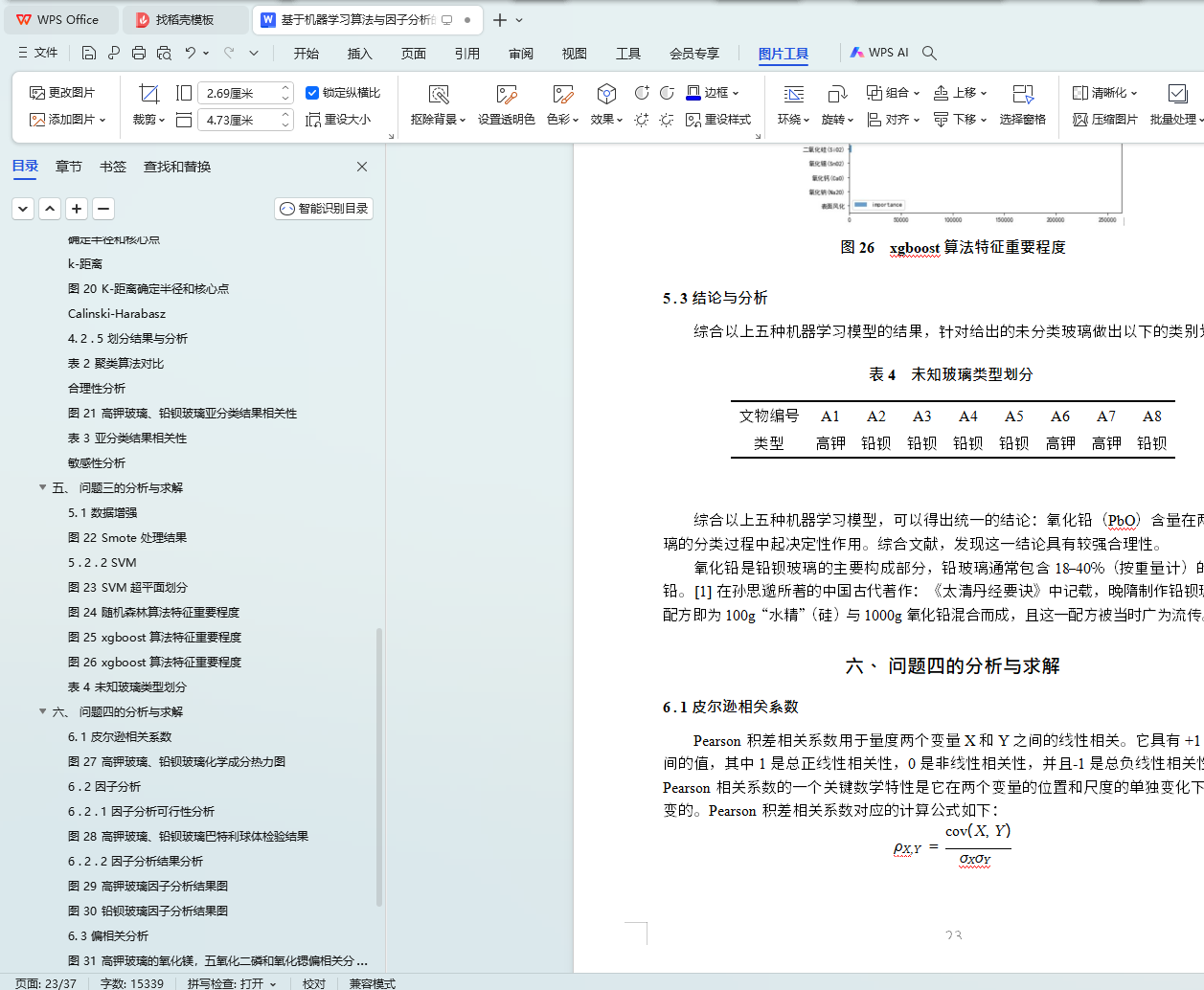
ͼ 26 xgboost �㷨������Ҫ�̶�
�� 4 δ֪�������ͻ���
���� �����ĵķ��������
6 . 1 Ƥ��ѷ���ϵ��
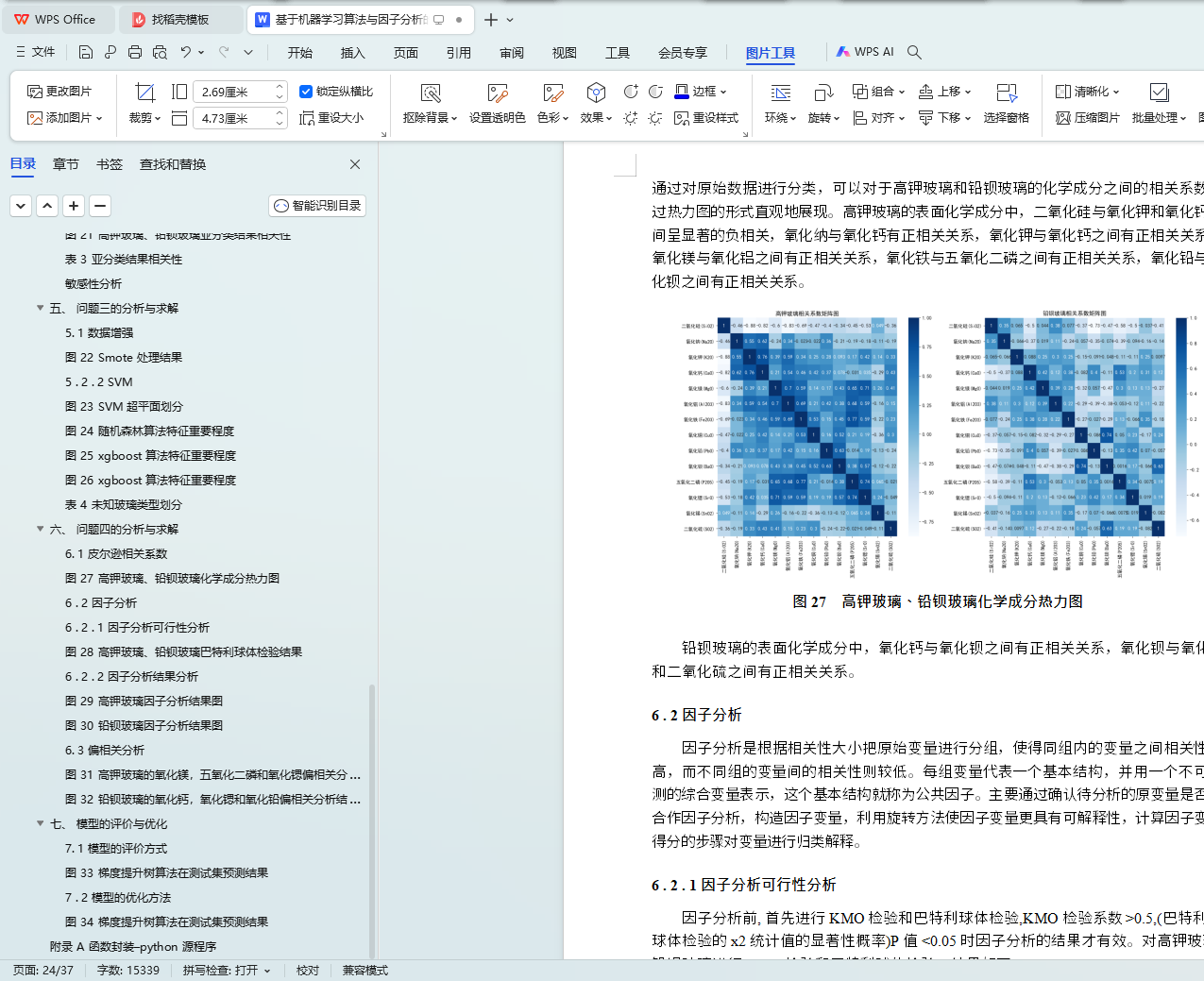
ͼ 27 �ز�����Ǧ��������ѧ�ɷ�����ͼ
6 . 2 ���ӷ���
6 . 2 . 1 ���ӷ��������Է���
ͼ 28 �ز�����Ǧ���������������������
6 . 2 . 2 ���ӷ����������
ͼ 29 �ز������ӷ������ͼ
ͼ 30 Ǧ���������ӷ������ͼ
6 . 3 ƫ��ط���
ͼ 31 �ز���������þ������������������ƫ��ط������
ͼ 32 Ǧ�������������ƣ������Ⱥ�����Ǧƫ��ط������
�ߡ� ģ�͵��������Ż�
7 . 1 ģ�͵����۷�ʽ
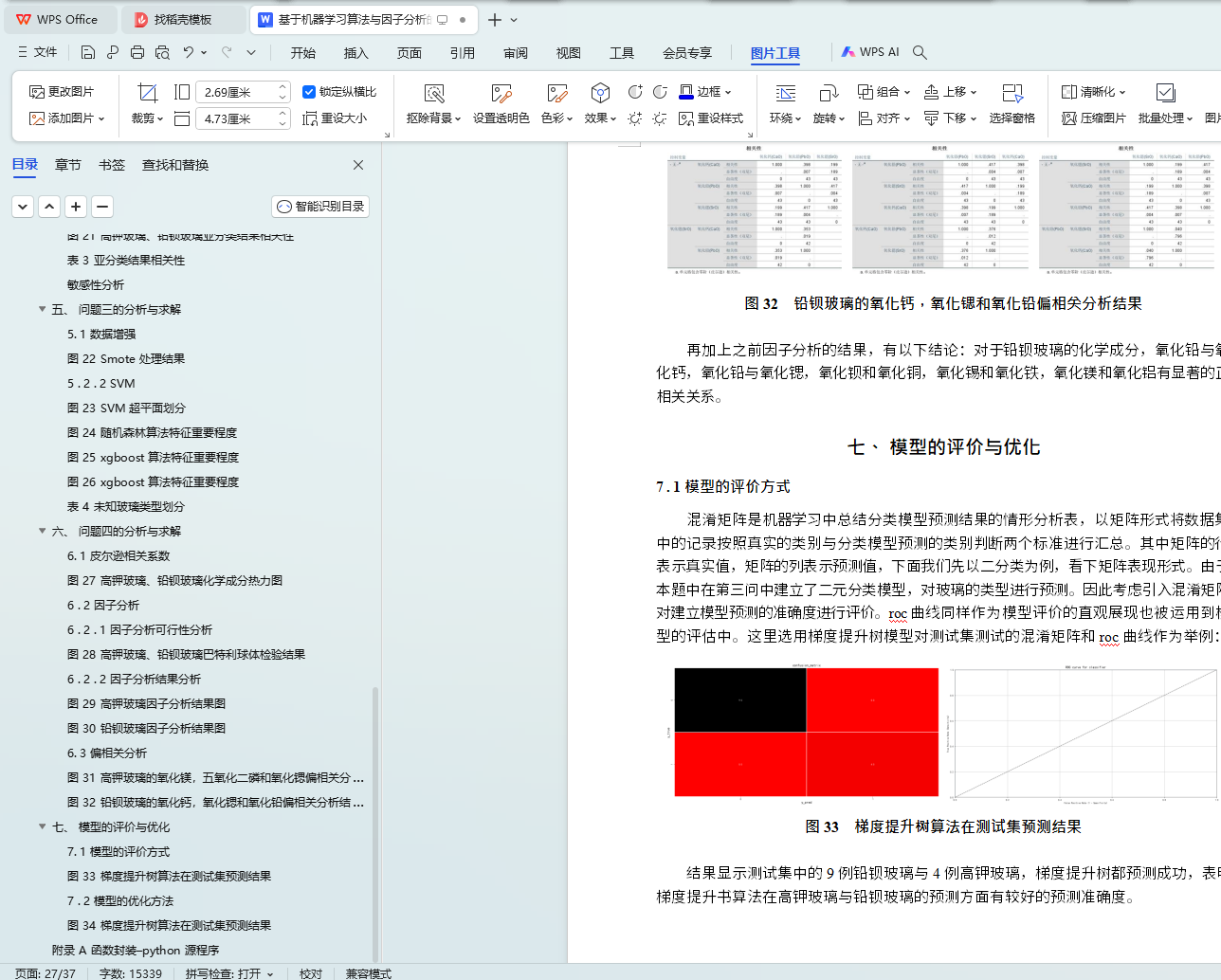
ͼ 33 �ݶ��������㷨�ڲ��Լ�Ԥ����
7 . 2 ģ�͵��Ż�����
ͼ 34 �ݶ��������㷨�ڲ��Լ�Ԥ����
��¼ A ������װ�Cpython Դ����