文献精读报告样例
1. 文献信息:题目――发表期刊/会议名称――发表年份;
DEPRESSION DETECTION BASED ON DEEP DISTRIBUTION LEARNING--IEEE--2019
2. 摘要内容是什么?(要理解人家如何写摘要的)
复制文献中的摘要内容过来 (为以后写文献综述做准备,不能截图)
Major depressive disorder is among the most common and harmful mental health problems. Several deep learning architectures have been proposed for video-based detection of depression based on the facial expressions of subjects. To predict the depression level, these architectures are often modeled for regression with Euclidean loss. Consequently, they do not leverage the data distribution, nor explore the ordinal relationship between facial images and depression levels, and have limited robustness to noisy and uncertain labeling. This paper introduces a deep learning architecture for accurately predicting depression levels through distribution learning. It relies on a new expectation loss function that allows to estimate the underlying data distribution over depression levels, where expected values of the distribution are optimized to approach the ground-truth levels. The proposed approach can produce accurate predictions of depression levels even under label uncertainty. Extensive experiments on the AVEC2013 and AVEC2014 datasets indicate that the proposed architecture represents an effective approach that can outperform state-of-the-art techniques.
3. 拟解决的问题(Motivation)
在摘要或引言(一般快结尾处)中找
复制文献中的相关内容过来(不能截图)
However, such loss functions are based on labeled facial images, and do not explicitly explore the ordinal relationship between the facial images and depression levels.In addition, in order to improve performance, the architectures tend to employ more than one channel to explore multi-regions of facial frames, which further increases the model complexity.
4. 解决方法(Method)
方法有原理图的,给出原理图(截图过来),并且要给出原理图步骤的概括性语言描述(复制文献中的相关内容过来,不能截图);没有原理图的,要给出方法Method的基本思想的语言描述(复制下,不能截图)。
In this paper, a deep learning architecture is introduced to accurately predict depression levels, where distribution learning is proposed to model the ordinal relationship between the facial images and depression levels.
Figure 1 illustrates the deep learning architecture proposed to predict depression levels. Although applicable in a wide range of CNNs, expectation loss is embedded into ResNet-50 [13] for distribution learning. ResNet architectures have shown the efficiency of deeper networks by using identity shortcut connections. In the ResNet-50 model, the basic blocks are comprised of a stack of convolutional layers with 1 × 1, 3 × 3 and 1 × 1 kernels.
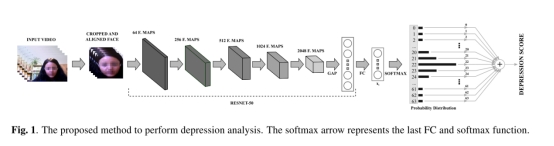
5. 实验结果及分析 (Results)
什么数据集,实验参数如何设置的,实验结果怎样?截图过来即可。
数据集:The proposed architecture is employed for automatically predicting the level of depression in subjects. For performance evaluation, experiments are conducted on AVEC2013 and AVEC2014 depression sub-challenge datasets. The objective of the sub-challenge is to estimate depression level of subjects on the Beck Depression Inventory (BDI). The BDI scores range from 0 to 63 with the following definitions: 0-13 (none depression), 14-19 (mild depression), 20-28 (moderate depression), and 29-63 (sever depression).
实验参数:The AVEC2013 depression dataset is a subset of the
audio-visual depressive language corpus (AViD-Corpus), which is composed of 150 videos from 82 subjects. The dataset is divided into three partitions: training, development and test set of 50 videos each. The AVEC2014 depression dataset is also a subset of AViD-Corpus. The subjects are recorded using a webcam and a microphone while performing two tasks: Freeform task, participants respond to questions such as discuss a sad childhood memory, and Northwind task, participants read audibly an excerpt from a fable.
实验结果:
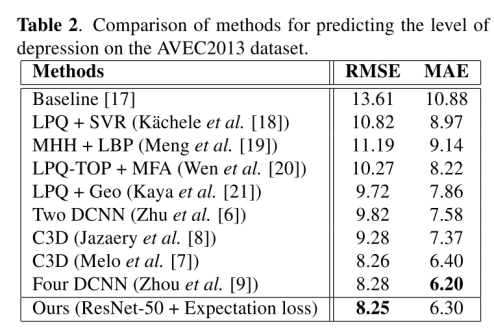
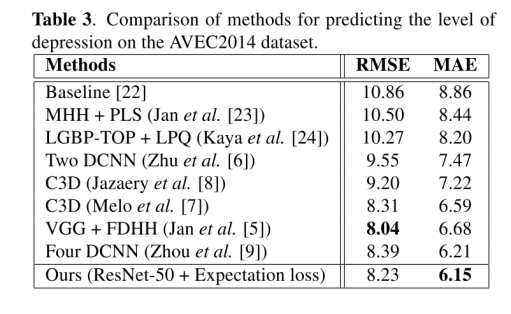
6. 总结/结论(Conclusions)
截图过来即可。

7. 还存在什么问题(Inspirations)
一般文章结尾处(conclusions and future work或discussion)可以找这个。
复制相关文字内容过来(不能截图)
Moreover, some movements, such as when the subjects put their hands on their face, may impair the performance of the model since they make it difficult to analyze facial expressions.
8. 写作有什么特点:
8.1文章的整个结构包含那几个部分?
自己写一下
1. 题目
2. 作者介绍和机构介绍
3. 摘要(ABSTRACT)
4. 引言(INTRODUCTION):介绍背景以及本论文的方法和理念
5. 提出的方法架构(PROPOSED ARCHITECTURE)
6. 实验分析(EXPERIMENTAL ANALYSIS)
7. 结论(CONCLUSION)
8. 感谢(ACKNOWLEDGEMENT)
9. 参考文献(REFERENCES)
8.2引言(Introduction)撰写如何组织的?(找出“引言”中每一段话的中心句,或自己总结出中心句)
第1段:有中心句的话,截图过来即可。
第2段:有中心句的话,截图过来即可。

第3段:有中心句的话,截图过来即可。

第4段:有中心句的话,截图过来即可。

第5段:有中心句的话,截图过来即可。

8.3有什么语言表达优美的好句子可以摘录下来,供以后写作借鉴?例如,如何看“图”说话、看“表”说话、如何描述不同方法的性能高低和比较,如何表述因果关系。。。。等等。(摘录2-4个好句子)
好句子复制过来即可(不能截图)。
Consequently, they do not leverage the data distribution, nor explore the ordinal relationship between facial images and depression levels, and have limited robustness to noisy and uncertain labeling.
Consequently, the proposed approach can address problems with noisy and ambiguous labels since the model explores the relationship between the facial images and depression levels.
In this paper, expectation loss is proposed to estimate the data distribution over depression levels, allowing robust predictions given the ambiguous depression levels.
