1. ������Ϣ����Ŀ���������ڿ�/�������ơ���������ݣ�
Automated facial video-based recognition of depression and anxiety symptom severity: cross-corpus validation--Machine Vision and Applications --2019
2. ժҪ������ʲô����Ҫ�����˼����дժҪ�ģ�
There is a growing interest in computational approaches permitting accurate detection of nonverbal signs of depression and related symptoms (i.e., anxiety and distress) that may serve as minimally intrusive means of monitoring illness progression. The aim of the present work was to develop a methodology for detecting such signs and to evaluate its generalizability and clinical specificity for detecting signs of depression and anxiety. Our approach focused on dynamic descriptors of facial expressions, employing motion history image, combined with appearance-based feature extraction algorithms (local binary patterns,histogram of oriented gradients), and visual geometry group features derived using deep learning networks through transfer learning. The relative performance of various alternative feature description and extraction techniques was first evaluated on a novel dataset comprising patients with a clinical diagnosis of depression (n = 20) and healthy volunteers (n = 45). Among various schemes involving depression measures as outcomes, best performance was obtained for continuous assessment of depression severity (as opposed to binary classification of patients and healthy volunteers). Comparable performance was achieved on a benchmark dataset, the audio/visual emotion challenge (AVEC��14). Regarding clinical specificity, results indicated that the proposed methodology was more accurate in detecting visual signs associated with self-reported anxiety symptoms. Findings are discussed in relation to clinical and technical limitations and future improvements.
3. ���������⣨Motivation��
Limited continuous monitoring of persons at risk (e.g., individuals with a history of mental illness or suffering from chronic, debilitating physical diseases) is one of the factors contributing to the high rate of underdiagnosed depressive episodes [5].
�Ը�Σ��Ⱥ(���磬�о���ʷ������������˥���Լ�������)�������ij�������ǵ�����ϲ���ĸ߱�����������[5]������֮һ��
4. ���������Method��
Our approach focused on dynamic descriptors of facial expressions,
employing motion history image, combined with appearance-based feature extraction algorithms (local binary patterns, histogram of oriented gradients), and visual geometry group features derived using deep learning networks through transfer learning. The relative performance of various alternative feature description and extraction techniques was first evaluated on a novel dataset comprising patients with a clinical diagnosis of depression (n = 20) and healthy volunteers (n = 45). Among various schemes involving depression measures as outcomes, best performance was obtained for continuous assessment of depression severity (as opposed to binary classification of patients and healthy volunteers). Comparable performance was
achieved on a benchmark dataset, the audio/visual emotion challenge (AVEC��14).
���ǵķ����������沿����Ķ�̬�������������˶���ʷͼ��ϻ�����۵�������ȡ�㷨(�ֲ���ֵģʽ�������ݶ�ֱ��ͼ)���Լ�ͨ��Ǩ��ѧϰ�����ѧϰ�����õ��Ӿ��������������������������������ȡ�������������������һ���µ����ݼ��Ͻ��������������ݼ������ٴ����Ϊ����֢�Ļ���(n = 20)�ͽ���־Ը��(n = 45)���ڸ����漰������ʩ��Ϊ����ķ����У����������������س̶Ȼ������ѱ���(����ڻ��ߺͽ���־Ը�ߵĶ�Ԫ����)����һ�������ݼ�����Ƶ/�Ӿ������ս(AVEC��14)��ȡ���˿ɱ��Եı��֡�
5. ʵ���������� ��Results��
ʲô���ݼ���ʵ�����������õģ�ʵ������������ͼ�������ɡ�
ʵ�������
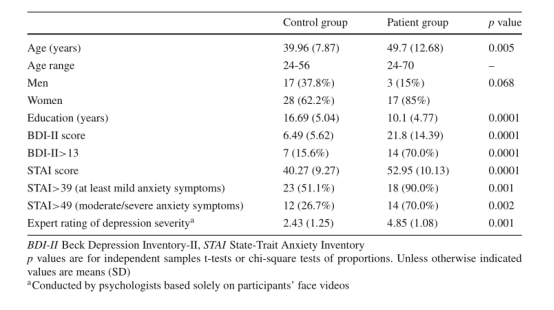
The study included two groups of participants: healthy volunteers (n = 45) aged 20�C65 years without history of mental or neurological disorder, and patients suffering from MDD as diagnosed by their treating psychiatrists at the Psychiatry Outpatient Clinic, University Hospital of Heraklion (n = 20).
�����о�������������ߣ�������20-65��֮�䡢û�о����������ʷ�Ľ���־Ը��(n=45)���Լ���������������ѧҽԺ���������������Ƶľ���ѧ�����ΪMDD�Ļ���(n=20)��
This took place prior to the description of positive experience/joy clip and, again, prior to the description of negative experience/sadness clip. Specifically, in the beginning of the protocol (c.f. Table 2 task #4) the participants were instructed by the research assistant on how to breathe in order to relax, while their heart rate and peripheral Blood V olume Pulse (BVP) were monitored through photoplethysmography using a NeXus-10 device (Mind Media, Netherlands). Participants were offered a second guided relaxation session immediately following the ��Joy�� video clip (Task #8 in Table2) to help them resume baseline levels of emotional and psychophysiological states (i.e., as recorded at the beginning of the experimental session). This was ensured by monitoring BVP on the Nexus-10 device during the breathing exercise. Facial video data used in the present study originated from steps 7�C8 and 11�C13 of the study protocol, shown in bold. The total duration of the experiment ranged from 60�C90 min. A Point Grey Grasshopper®3 camera was employed to record high-resolution video at a high frame-rate. Camera settings were set to permit future assessment of the impact of recording quality on the algorithm efficiency. Benchmark tests showed that 80 frames per second (fps) and a resolution of 1920 �� 1920 pixels was the maximum configuration that the available PC could support. Indirect lighting was applied totheparticipant��s facetoensureuniformfacialillumination and minimize shadows.
�����˵����Э��Ŀ�ͷ(c.f.����2����#4)�о�����ָ����������κ����Է��ɣ�ͬʱʹ��Nexus-10�豸(Mind Media������)ͨ�����������Ǽ�����ǵ����ʺ�����ѪҺ�ݻ�����(BVP)���������ڡ����֡���Ƶ����(��2�е�����#8)֮���������ܵڶ�����ָ���ķ��ɿγ̣��������ǻָ���������������״̬�Ļ���ˮƽ(������ʵ��γ̿�ʼʱ��¼��)������ͨ���ں�����ϰ�ڼ���Nexus-10�豸�ϵ�BVP��ȷ���ġ����о���ʹ�õ��沿��Ƶ���������о������IJ���7-8��11-13���Դ�����ʾ��ʵ����ʱ��Ϊ60~90min��ʹ��Point Grey Grasshop®3������Ը�֡��¼�Ƹ߷ֱ�����Ƶ����������ñ�����Ϊ��������������¼�������㷨Ч�ʵ�Ӱ�졣��������ʾ��80֡/��(Fps)��1920��1920���صķֱ����ǿ��õ�PC����֧�ֵ�������á��������Ӧ���ڲ����ߵ��沿����ȷ���沿�������ȣ�������ȵؼ�����Ӱ��
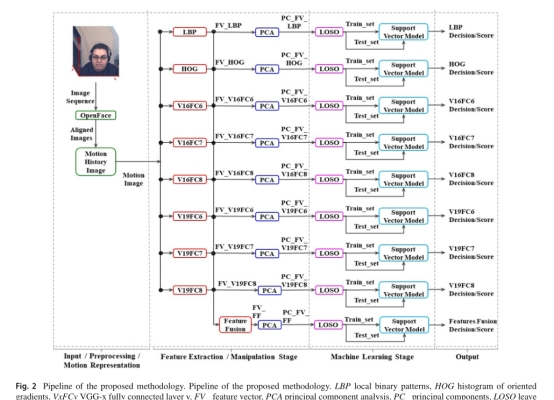
6. �ܽ�/���ۣ�Conclusions��
��ͼ�������ɡ�
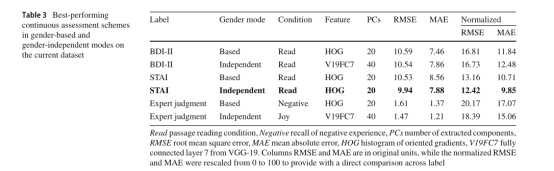
7. ������ʲô���⣨Inspirations��
һ�����½�β����conclusions and future work��discussion�������������
��������������ݹ��������ܽ�ͼ��
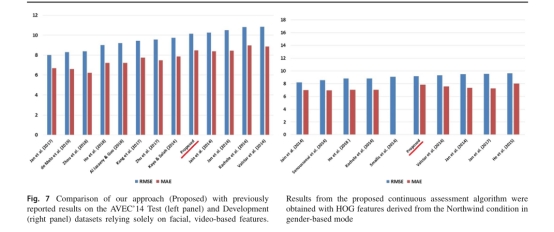
For instance, a recent report of depression severity prediction using the Pittsburgh dataset relied on serial video recordings [56] whereas a single measurement was available in the current study. In other reports deep learning was employed for both algorithm training and tuning comparing [13,16] whereas in the current work this technique was used solely for feature extraction.
���磬���һ��ʹ��ƥ�ȱ����ݼ�Ԥ������֢���س̶ȵı�����������������Ƶ��¼[56]�����ڵ�ǰ���о���ֻ��һ�ֲ��������������������У����ѧϰ�������㷨ѵ���͵��űȽ�[13��16]�����ڵ�ǰ�Ĺ����У����ּ���������������ȡ��
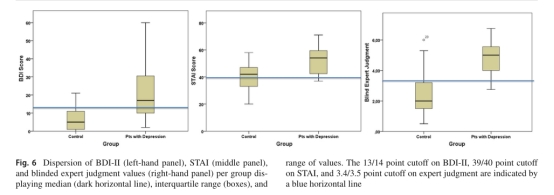
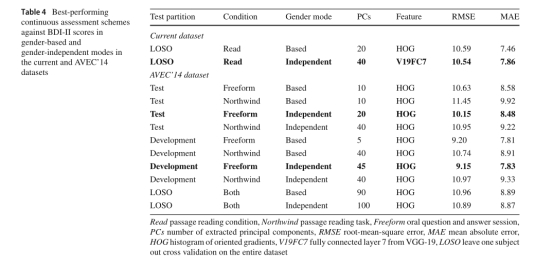
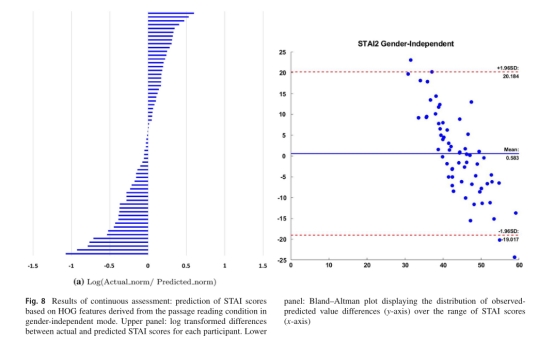
It should be noted, however, that best results (prediction of STAI or BDI-II scores) were obtained with video recordings fromtheneutral,passage-readingtaskingender-independent mode. As shown in the Bland-Altman plot of Fig. 8, t h e m o s t notable failure involved underestimation of STAI scores, given the higher associated clinical risk. Among the four patients in this category, two suffered from severe depression and were treated with high doses of anti-depressants, which may have affected the dynamics of facial expressions. Another patient spoke Greek as a second language and experienced some difficulty in reading the text, while the fourth patient also experienced some difficulty in reading due to reduced visual acuity. Clinicaldiagnosisofdepressiondidnotemergeasarobust out come variable in binary classification schemes .In part this findingmaybeattributedtotheconsiderableoverlapbetween the two study groups on self-reported depression symptomatology (BDI-II scores) and expert-rated facial signs of depression as shown in Fig. 6. The fact that the patients were
����ģʽ��ʵ�������´��ڣ���˿��ܷ�ӳ����������Եġ���̬���沿���ƣ���������к���֪��û����ս�Ե�������(���Ķ����Զ���)��õ���Ƶ��¼������á�Ȼ����Ӧ��ע����ǣ���õĽ��(STAI��BDI-II������Ԥ��)��ͨ�����Եġ��Ķ������ṩ���ص�ģʽ�µ���Ƶ��¼��õġ���ͼ8��Bland-Altmanͼ��ʾ�����ǵ���صĽϸ��ٴ����գ�������ʧ���漰��STAI���ֵĵ������������������У�������������������֢���������˴�����Ŀ�����ҩ�����ƣ������Ӱ�����沿����Ķ�̬����һ�����߽�ϣ������Ϊ�ڶ����ԣ����Ķ�����ʱ������һЩ���ѣ�������������Ҳ��Ϊ�����½������Ķ�����������һЩ���ѡ�
8. д����ʲô�ص㣺
8.1���µ������ṹ�����Ǽ������֣�
ժҪ�����ԣ������ռ������������������
8.2���ԣ�Introduction��д�����֯�ģ����ҳ������ԡ���ÿһ�λ������ľ䣬���Լ��ܽ�����ľ䣩
��1�Σ������ľ�Ļ�����ͼ�������ɡ�
��Щ���ȷ����־��ã�����һ����ȱ�㣬��Ϊ����û�п��ǵ��������������������ҽѧ����(�罹��֢��֢״)�Լ��������ҪӦ��Դ�����������ܵ����������ı���ƫ��[4]��Ӱ��
��2�Σ������ľ�Ļ�����ͼ�������ɡ�
Ȼ�������ǵ�Ŀǰ���Ƚ��ļ���ˮƽ��������Ƶ������֢����ϵͳ����������Ϊ�����Ĺ��ߣ�����Ҫ����Ϊ����֧��ϵͳ��һ���֣�������������רҵ��Ա�Ը�Σ��Ⱥ����Զ�̼�ء����ǵ�����������Եġ��沿�������ź��Ƕ�̬��[4��7��8]���������е�ǰ�ķ�����ʹ�û�����Ƶ�������������ǻ���֡(��̬)��������
��3�Σ������ľ�Ļ�����ͼ�������ɡ�
����û�п��ŵ����ݼ�������֧���¼�����������Ŀ���������A VEC��13-��141��DAIC-WOZ2���ݼ�����������Ϊ����������ս(A VEC)������ʶ������ս(DSC)��һ�����Ƴ��ġ�
8.3��ʲô���Ա��������ĺþ��ӿ���ժ¼���������Ժ�д����������磬��ο���ͼ��˵������������˵�������������ͬ���������ܸߵͺͱȽϣ���α��������ϵ���������ȵȡ���ժ¼2-4���þ��ӣ�
�þ��Ӹ��ƹ������ɣ����ܽ�ͼ����
The A VEC dataset is suitable for assessing the generalizability of novel algorithms and analysis pipelines across cultures as it includes a range of video recording contexts and settings.
A VEC���ݼ��ʺ����������㷨�Ϳ��Ļ������ܵ���ͨ���ԣ���Ϊ������һϵ����Ƶ¼�������ĺ����á�
The present study is addressing four specificaims.Firstly, to describe the development of a novel dataset comprising multimodal recordings from patients diagnosed with Major Depressive Disorder (MDD) and healthy volunteers. Data were obtained on a variety of experimental settings (including emotionally and cognitively neutral conditions and emotionally stimulating social and non-social contexts).
���о��������ĸ�������о�����һ������һ���µ����ݼ��Ŀ����������ݼ��������Ա����Ϊ���������ϰ�(MDD)�Ļ��ߺͽ���־Ը�ߵĶ�ģʽ��¼���������ڸ���ʵ�黷���л�õ�(������к���֪�����������Լ���д̼������ͷ���ỷ��)��
The generalizability of the developed method was tested on the A VEC��14 dataset, comprising 300 video recordings from 83 participants obtained in the context of two conditions which are very similar to tasks used in the present study, namely reading a neutral text passage and completing a question-and-answer session with the experimenter.
��A VEC��14���ݼ��ϲ����˸÷����ĸ����ԣ������ݼ�����83�������ߵ�300����Ƶ��¼����Щ��Ƶ��¼���������뱾�о���ʹ�õ�����dz����Ƶ������»�õģ����Ķ������ı�����������ʵ���ߵ��ʴڡ�
