近期阅读论文报告
主要阅读:Retentive Network: A Successor to Transformer for Large Language Models
这篇工作由微软亚研院和清华推出,提出了Transformer的替代者-RetNet。作者认为RetNet弥补了包括Transformer在内的之前所有结构的不足,并且同时具有训练并发性、推断的低消耗性和良好的模型性能这三个特征。

作者推导了循环结构(recurrent)和注意力机制的关系。然后提出留存机制(retention mechanism),并且这种结构支持三种计算范式:1并行性2循环性3依赖块的循环性。
在语言模型上面的实验结果表明RetNet在并行训练、低成本部署和高效推理方面表现优秀。这使得RetNet可以成为Transformer的继任者。
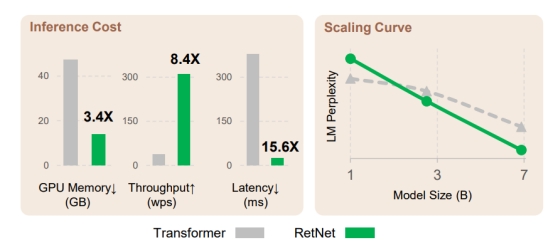
图 1 RetNet和Transformer的对比

首先,目前所有的模型都被上图的“不可能三角”限制,即低成本推理、好的性能和训练并行性不能同时满足,Transformer满足了训练并行性和良好的性能,但是训练成本很高。循环神经网络由于自身结构限制,不能并行训练。同时期的几乎所有其他工作,都不能同时满足上述三个条件。
