基于大数据的地域职位需求和薪资分析
摘 要
互联网市场很的繁荣,带动了很多招聘网站的产生。互联网市场技术的市场情况会很好的反映在招聘网站上。如果能够通过研究招聘网站对互联网技术进行研究,分析出它所在地区技能要求和薪资情况,那将会是一件特别有意义的事。
本系统主要完成的是基于大数据的地域职位需求和薪资分析的设计和实现,主要实现了以下几个功能,分别是数据爬取、数据清洗、数据存储、预测薪资、分词统计和数据呈现等功能。数据爬取采用 Python 语言,主要使用的模块有 requests、bs4 和 re 数据清洗系统使用 Hive 框架,代码放在.hql 的脚本中。数据存储系统使用 Hbase 框架,使用
Java 语言先从 Hive 读取数据,然后把读取到的数据存储到 Hbase 上。预测薪资算法采用 Java 语言实现,分词统计采用 Spark 框架,然后使用 Java 语言实现。数据呈现是使用 Java Web 搭建网站,后台使用 SSM 框架调用预测算法和分词算法,前端使用 EChars 呈现出使用预测算法和分词算法得到的结果。
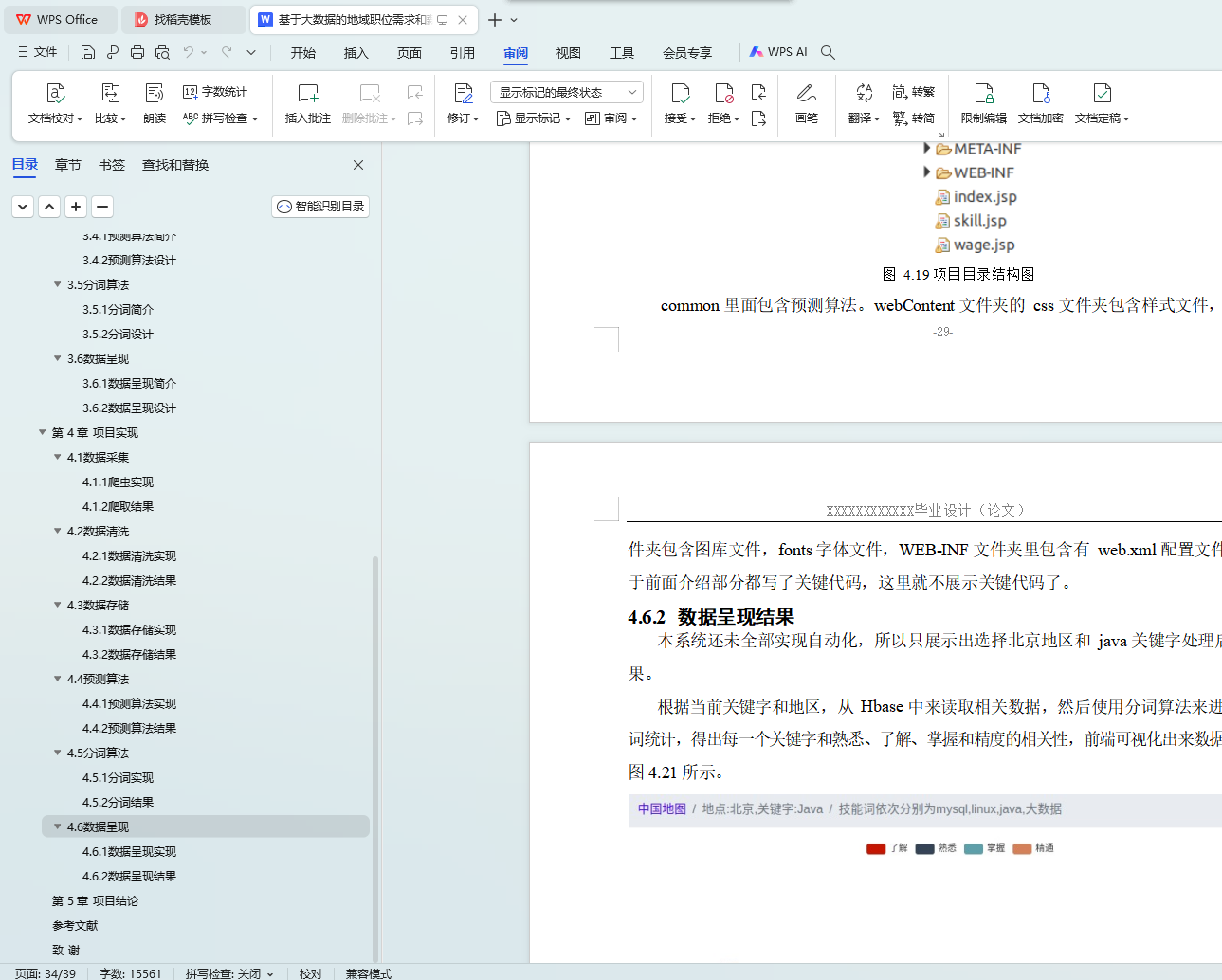
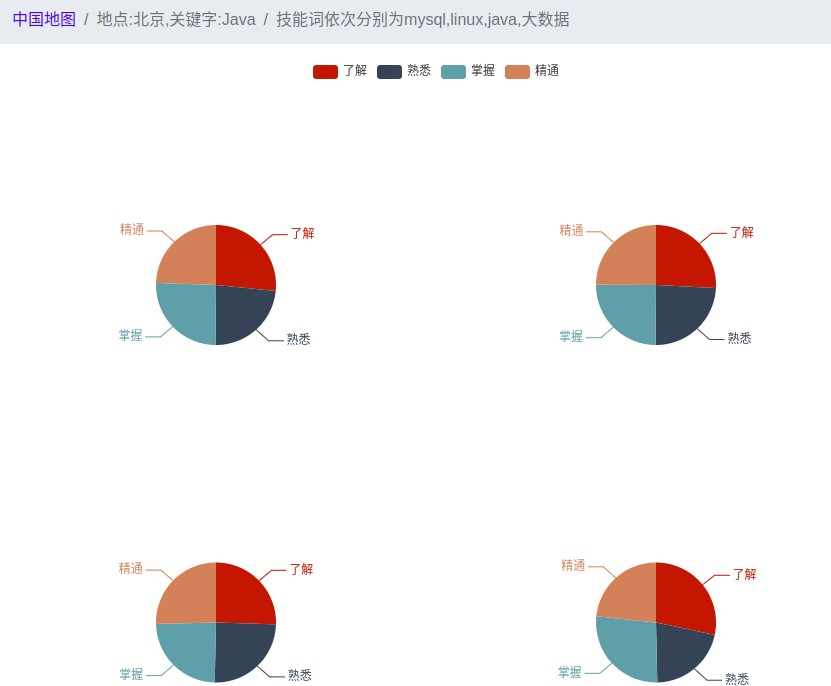
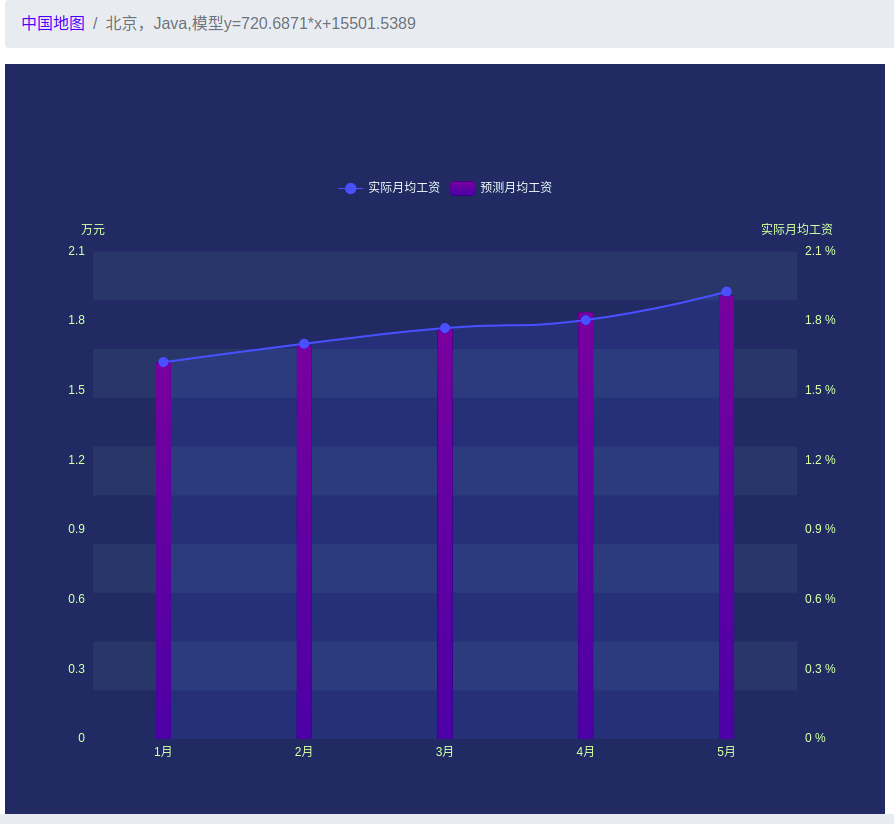
本系统最终呈现的效果是一个网站,因为网站呈现出来的结果具备直观性和可观赏性,很方便用户查看。用户点击地图上的地区,就会出现相应地区的薪资预测图和该地区相应关键字对应的技能词的统计结果。
关键词:大数据,Hive,Hbase,线性规划,分词统计
Analysis of Regional Job Requirements and Salary Based on Big Data Technology
Abstract
The Internet market is booming, which has led to the creation of many recruitment websites. The market situation of Internet market technology will be well reflected in the recruitment website. It would be especially interesting to be able to research Internet technology through research recruitment websites and analyze the skill requirements and salary levels in its region.
This system mainly completes the design and implementation of regional job demand and salary analysis based on big data. It mainly realizes the following functions: data crawling, data cleaning, data storage, salary prediction, word segmentation statistics and data presentation. Data crawling is implemented in python language. The main modules used are requests, bs4 and re. The data cleaning system uses the hive framework, and the code is placed in the script of.Hql. Data storage system uses hbase framework, uses java language to read data from hive, and then stores the read data on hbase. The predictive salary algorithm is implemented in Java language, the word segmentation statistics is implemented in spark framework, and then implemented in Java language. Data presentation is to use java web to build websites, ssm framework is used in the background to call prediction algorithm and word segmentation algorithm, and echars is used in the front end to present the results obtained by using prediction algorithm and word segmentation algorithm.
The final effect of the system is a website, because the results presented by the website are intuitive and enjoyable, which is convenient for users to view. When the user clicks on the area on the map, the salary forecast map of the corresponding area and the statistical result of the skill word corresponding to the corresponding keyword in the area appear.
Key words: BigData, Hive, Hbase, Linear Programming, Word Segmentation Statistics
目 录
摘 要 I
ABSTRACT II
第 1 章 项目引言 1
1.1 项目背景 1
1.2 国内研究现状 1
1.3 研究内容 2
1.4 论文结构 2
第 2 章 项目框架 3
2.1 HADOOP 框架 3
2.2 HBASE 框架 4
2.3 HIVE 框架 5
2.4 SPARK 框架 6
第 3 章 项目设计 7
3.1 数据采集 7
3.1.1 爬虫简介 7
3.1.2 爬虫设计 7
3.2 数据清洗 10
3.1.1 数据清洗简介 10
3.2.2 数据清洗设计 11
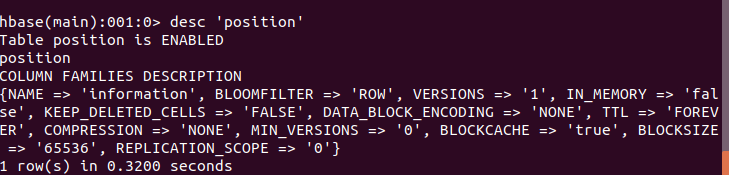
3.3 数据存储 11
3.3.1 数据存储简介 11
3.3.2 数据存储设计 12
3.4 预测算法 12
3.1.1 预测算法简介 12
3.4.2 预测算法设计 13
3.5 分词算法 13
3.5.1 分词简介 13
3.5.2 分词设计 14
3.6 数据呈现 15
3.6.1 数据呈现简介 15
3.6.2 数据呈现设计 15
第 4 章 项目实现 16
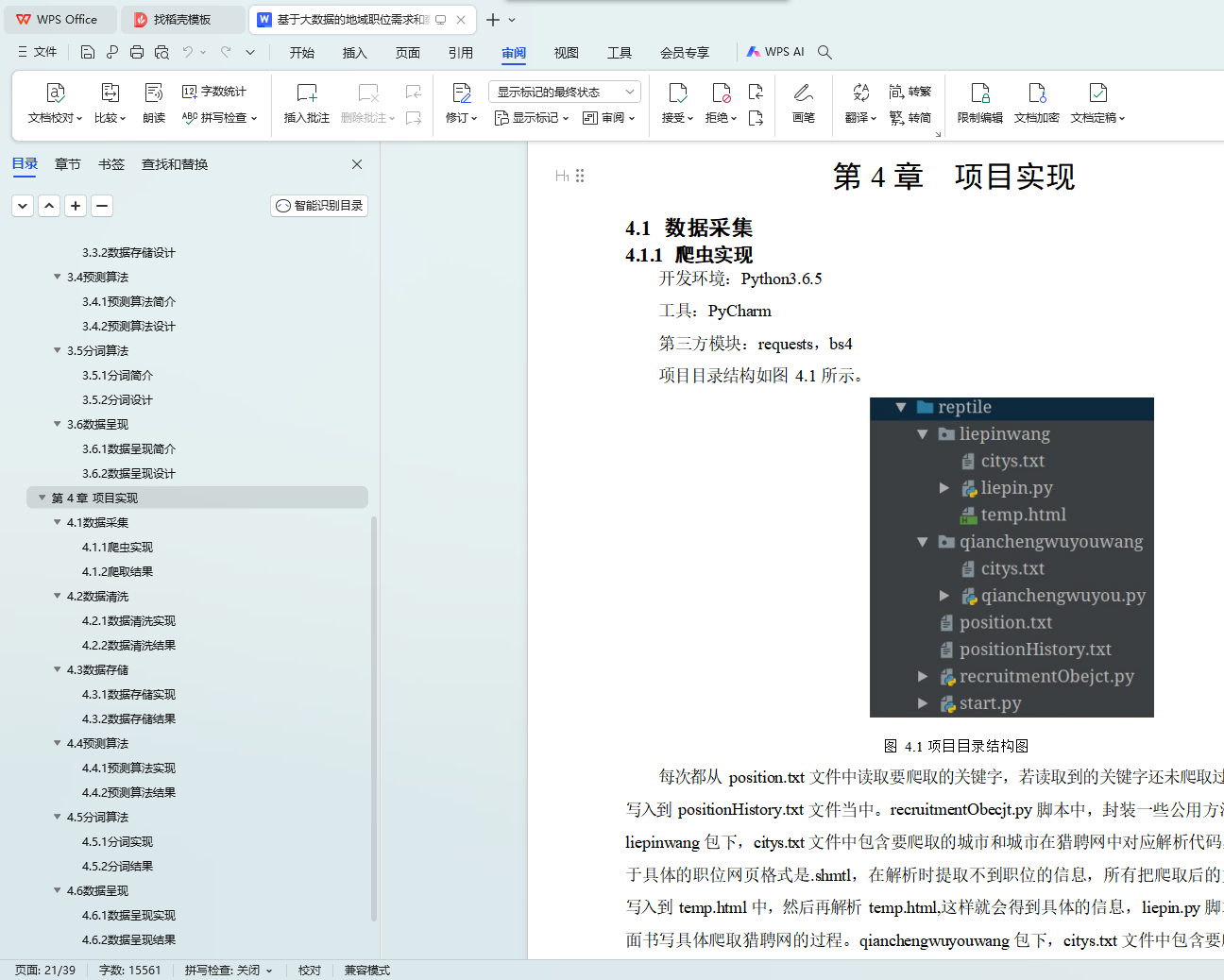
4.1 数据采集 16
4.1.1 爬虫实现 16
4.1.2 爬取结果 18
4.2 数据清洗 19
4.2.1 数据清洗实现 19
4.2.2 数据清洗结果 20
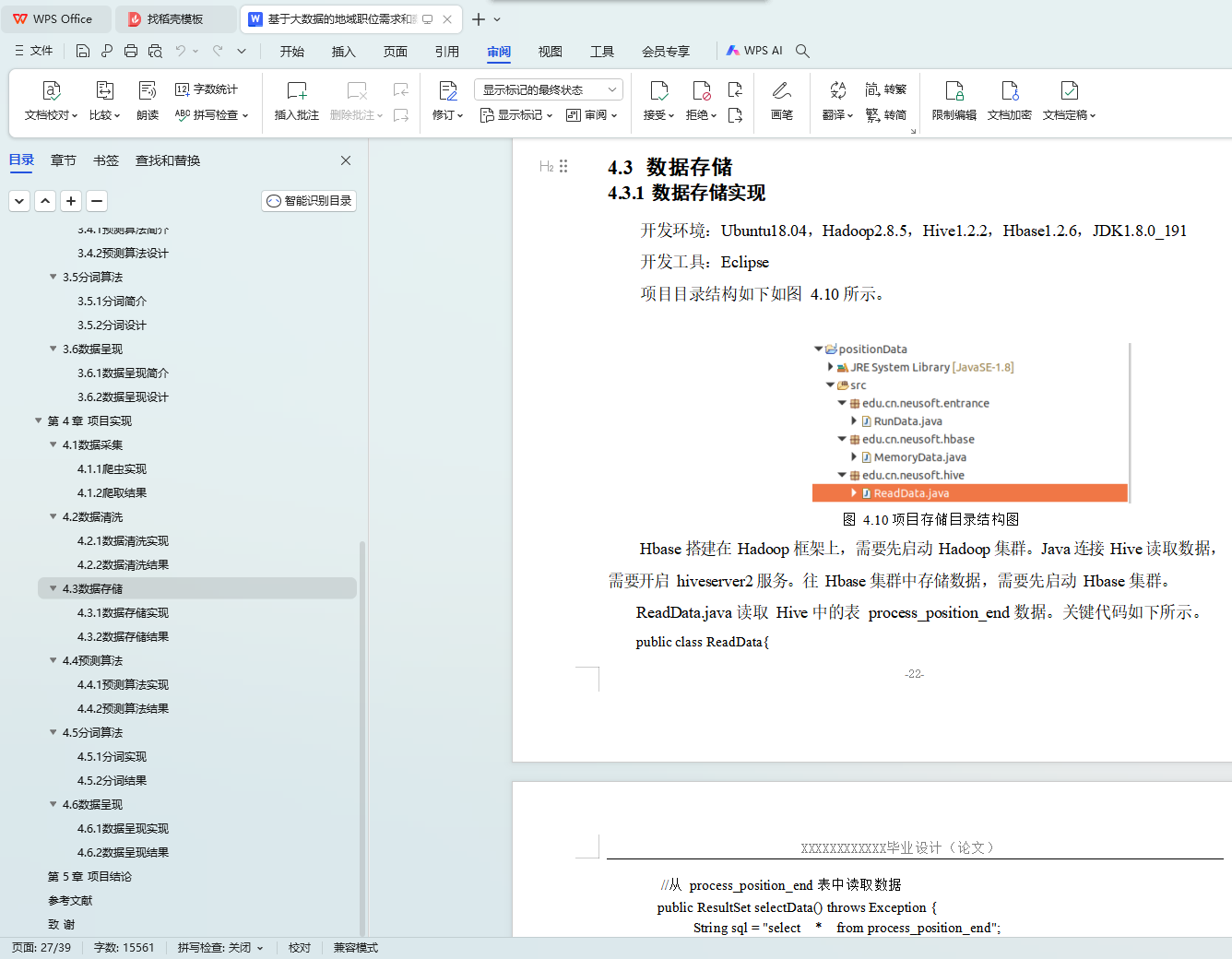
4.3 数据存储 22
4.3.1 数据存储实现 22
4.3.2 数据存储结果 24
4.4 预测算法 24
4.4.1 预测算法实现 24
4.4.2 预测算法结果 26
4.5 分词算法 26
4.5.1 分词实现 26
4.5.2 分词结果 27
4.6 数据呈现 28
4.6.1 数据呈现实现 28
4.6.2 数据呈现结果 29
第 5 章 项目结论 31
参考文献 31
致 谢 33