基于改进TF-IDF的朴素Bayes文本分类器
的实现和应用
【摘要】 随着人工智能的快速发展以及5G时代的到来,每个人都可以轻松的接入互联网。互联网中充斥着大量各种各样的文本信息,用户可以使用智能设备轻松、便捷的进行检索。信息的获取变得空前简单和快速,但是这些信息往往夹杂这一些垃圾信息、广告等,用户想要从海量的信息中快速的找到对自己有用的信息变得十分困难。自然语言处理技术应运而生,在进行分类任务时,给每个特征词分配相同的权重,然而在文本中不同的特征词往往重要程度不同,分配合适的权重将有助提高分类效果。为此本文提出一种改进的朴素Bayes文本分类算法,该算法以TF-IDF为基础,使用特征词位置因子以加强特征权重的准确性,对不同词分配不同的特征权重,对TF-IDF中的IDF值计算方法进行改进,从而提高算法的准确性。在实验部分,本文使用真实的从网上采集得新闻数据集进行文本分类实验从而验证算法改进的效果,实验结果符合预期,改进后的朴素Bayes文本分类算法在三个分类指标上都有较大提高,且改进后的TF-IDF使用更少的特征词就可以做到与原始TF-IDF相同的分类精度,改进后算法能有效地提高分类性能和效率。
【关键词】 文本分类,朴素Bayes,TF-IDF,特征权重
Implementation and Application of Naive Bayes Text Classifier Based on Improved TF-IDF
【Abstract】 With the rapid development of artificial intelligence and the advent of the 5G era, anyone can easily access the Internet. The network is full of various text messages, and users can use smart devices to obtain information easily and conveniently. Although the access to information is simpler and faster than before, this information is often mixed with some junk and advertisements. It is very difficult for users to find useful information from a large amount of information. Natural language processing technology is available. When performing the classification task, each feature word is assigned the same weight. However, different feature words in the text often have different importance. Allocating proper weight can improve the classification effect. To this end, this paper proposes an improved simple Bays text classification algorithm based on TF-IDF, which uses the position coefficients of feature words to improve the accuracy of feature weights and assigns different feature weights to different words. The calculation method of TI- IDF has been improved, and the accuracy of the algorithm has been improved. In the experimental part, this article uses actual news data sets collected from the Internet to conduct text classification experiments to verify the effect of algorithm improvements. The experimental results are as expected. The improved simple Bayesian text classification algorithm has been greatly improved in three classification indicators. In addition, the improved TF-IDF can use fewer feature words to achieve the same classification accuracy as the original TF-IDF, and the improved algorithm can effectively improve the classification performance and efficiency.
【Key Words】 Text classification, naive Bayes, TF-IDF,, feature weight
表目录
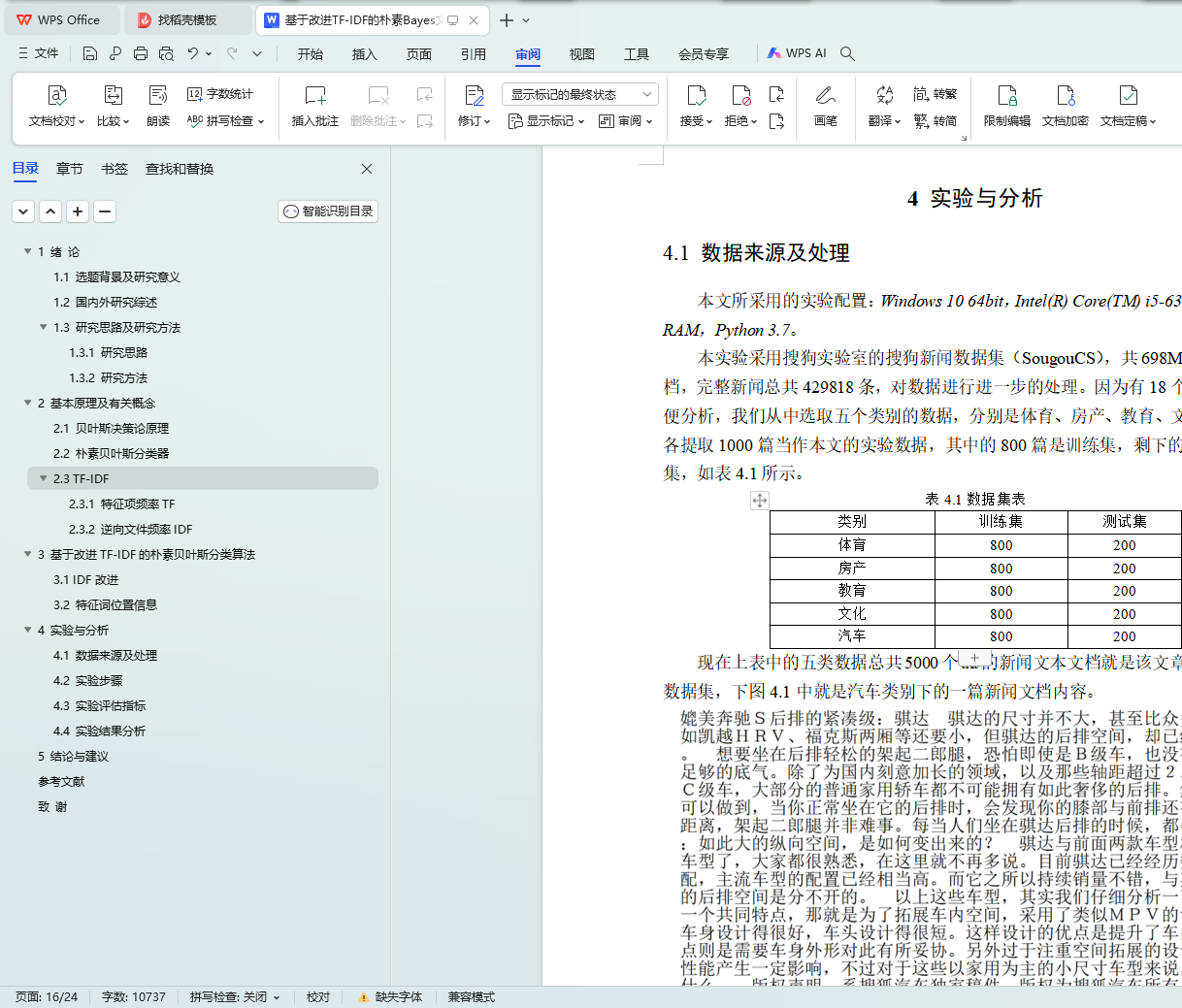
表4.1数据集表
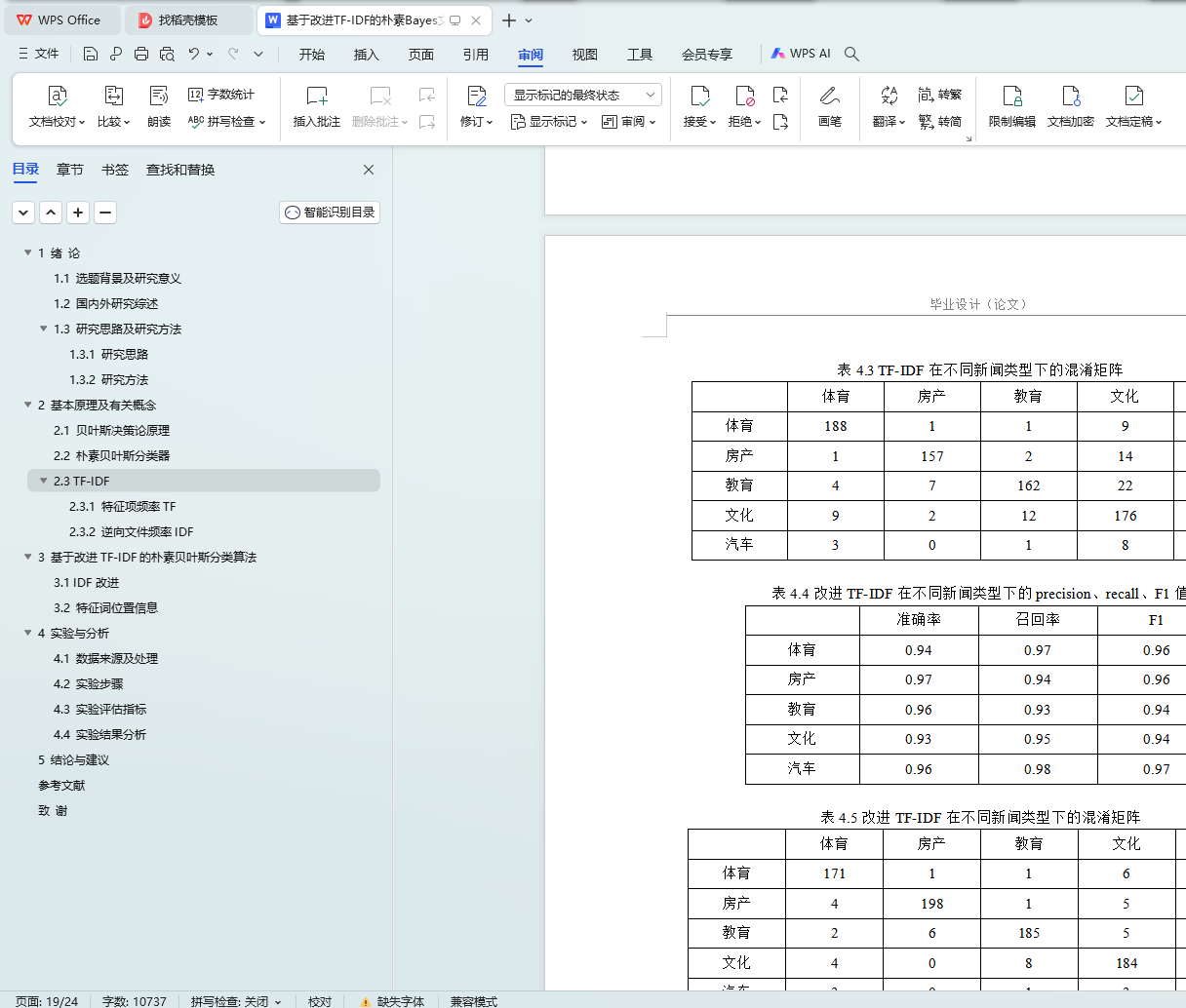
表4.2 TF-IDF在不同新闻类型下的precision、recall、F1值
表4.3 TF-IDF在不同新闻类型下的混淆矩阵
表4.4改进TF-IDF在不同新闻类型下的precision、recall、F1值
表4.5改进TF-IDF在不同新闻类型下的混淆矩阵
表4.6基于属性加权在不同新闻类型下的precision、recall、F1值
表4.7基于属性加权在不同新闻类型下的混淆矩阵