毕业设计(论文)
译文及原稿
|
译文题目:
|
基于支持向量机的语音情感识别
|
|
原稿题目:
|
Speech Emotion Recognition Using Support Vector Machines
|
|
原稿出处:
|
International Journal of Computer Applications (0975-8887) Volume 1 - No. 20
|
基于支持向量机的语音情感识别
摘要
在人机交互(HCI)这一广泛的应用领域,自动语音情感识别(SER)是目前较流行的研究课题。比如Mel频率倒谱系数(MFCC)和Mel能谱动力系数(MEDC)这些都是提取与语音表达的语音特征。在Berlin的数据库中,支持向量机(SVM)作为分类器识别不同的情绪状态:愤怒、快乐、悲伤、中性、恐惧。LIBSVM在被用于识别情感中,性别独立的94.73%女性和100%的男性演说试验中,它给出了93.75%的识别率。
范畴与学科描述符
I.5.0【模式识别】:一般
一般术语
性能;实验;认为因素
关键字
语音情感 情感识别 SVM MFCC MEDC
1.概述
在人机交互领域(HCI)中,自动语音情感识别是最近开始研究的课题。随着计算机日渐成为我们日常生活中的重要组成部分,语音情感识别的需要已经上升为一种更为自然的人机之间的通信接口。为了达到这样的目标,计算机必须要能够感知到当前的情绪并且为此情绪作出不同的反应。这个过程包括要清楚用户的情感状态。为了使人机交互更加自然,计算机就应该像人类一样有识别情感的能力。
自动情感识别(AER)有两种方式:通过语音或者面部表情。在HCI领域中,比如面部表情和手势,语音是情感识别系统中最基本的方式。在沟通中想要得知对方的动机和情绪,语音是最有力的一种方式。
近年来,大量的研究过工作已经通过语音信息识别到了人的情感[1][2]。很多研究者已经找到了很多识别方法:神经网络(NN)、高斯混合模型(GMM)、隐马尔科夫模型(HMM)、最大似然的贝里斯分类器(MLC)、最邻近算法(KNN)和支持向量机(SVM)[3],[4]。
支持向量机是因为有达到识别和认知的目的而被用于识别语音情感,。它通过制造一个N维空间的超平面来达到识别的功能。这个分类器的主要思想是通过一个线性和非线性的间隔区的训练样本点集合,利用核函数将原输入设置成一个高维空间的分类函数。
被记录在柏林科技大学里的情感数据库[5]适用于特征提取和训练支持向量机,包括了德语的情感行为,它包括五位男性五位女性的十位专业演员说的在7个不同的情感中的10个句子493个词语。这些情绪包括生气、郁闷、厌恶、恐惧、幸福、悲伤和中性。
语音情感识别可以应用于精神病学的诊断、智能玩具、谎言检测、学习环境、教育软件和在电话呼叫中心的对话中检测情绪状态并及时反馈给操作员和主管监控。
2.系统的实现
人与人的互动中的情感分析在工程和计算机科学中用电脑自动的方式来识别情绪中有着重要的作用。
如图1所示的输入是来自柏林的包含不同情绪情感的.wav语音,之后通过特征提取,在特征提取中有两个特征MFCC[5][6]和MEDC[7]。这些特征及其相应等级标注分别输入到LIBSVM分类型中,分类器输出的每一个标注都代表相应的情感类;有生气、悲伤、高兴、中性和恐惧五种。
2.1特征提取
在以前的研究中提取的都是语音的能量、音调、共振峰频率等韵律特征,这种一般的韵律特征主要的表明了说话者的情感状态。在特征提取中有两种特征:MEL频率倒谱系数(MFCC)和MEL能谱动力系数(MEDC)。
图2是MFCC特征提取的过程,有以下的步骤;
预处理:连续时间信号通过相应的采样频率采样。在MFCC特征提取的第一阶段是在高频中增加一定的能量,即通过一个过滤器对其进行预加重。
分帧:将语音信号通过采样转换为数字信号{ADC},到帧长为20-40ms的时间范围内分帧能使非平稳语音信号分割为似稳定帧,并能得到通过傅里叶变换的语音信号。这是因为大家都知道,语音信号中的似稳定的周期为很短的20-40ms。
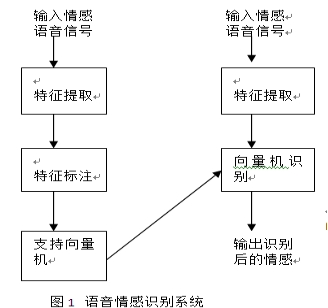
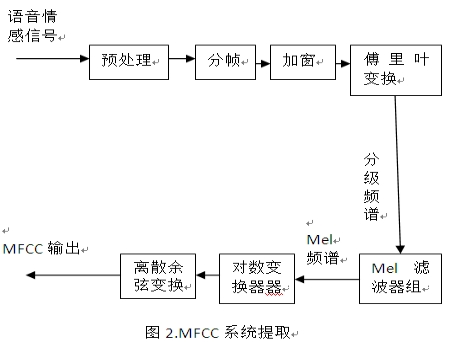
图2.MFCC系统提取
加窗:给信号开始和结束的每一帧加窗是为了减少信号的间断。
快速傅里叶变换:快速傅里叶变换(FFT)算法是用于衡量语音信号的频谱。FFT将长度为N的每一帧从时域变换为频域。
