一、实验目的
豆瓣用户每天都在对“看过”的电影进行“很差”到“力荐”的评价,豆瓣根据每部影片看过的人数以及该影片所得的评价等综合数据,通过算法分析产生豆瓣电影 Top 250。
本报告旨在对这250部电影(下称“好评电影”)的上映年代、电影导演、制作国家、电影类型进行分析,以期为电影制作方以及渴望寻找优秀电影观看的观影者 对电影的选择提供若干参考建议。

二、实验环境
操作系统:Windows 10 家庭中文版 版本号21H2
Python版本:python 3.7.3
虚拟机VMware安装Linux
Xshell5、navicat、FineBI





三、实验内容与过程
3.1 相关技术介绍
1、爬虫技术
网络爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,其实通俗的讲就是通过程序去获取web页面上自己想要的数据,也就是自动抓取数据。爬虫的目地在于将目标网页数据下载至本地,以便进行后续的数据分析.爬虫技术的兴起源于海量网络数据的可用性,通过爬虫技术,能够较为容易的获取网络数据,并通过对数据的分析,得出有具有价值的结论。Python语言简单易用,现成的爬虫框架和工具包降低了使用门槛,具体使用时配合正则表达式的运用,使得数据抓取工作变得生动有趣。
2、所用到的python库
(1)Requests
Requests 是用Python语言编写,基于 urllib,采用Apache2 Licensed 开源协议的HTTP库。Requests 继承了urllib的所有特性。Requests支持HTTP连接保持和连接池,支持使用cookie保持会话,支持文件上传,支持自动确定响应内容的编码,支持国际化的URL和POST 数据自动编码。主要用于请求URL,获取返回信息,打印输出响应头,和重定向等。在爬取数据过程中,使用了request库的get方法来发送请求。
主要就是获取整个页面的一个模块
步骤:
1、获取url地址
2、发送get/post请求
3、进行UA伪装、头部信息,也是身份的载体标识
4、返回响应页面的数据
(2)XPath
XPath 是一门在 XML文档中查找信息的语言。用于在 XML文档中通过元素和属性进行导航,选取XML文档中的节点或者节点集。这些路径表达式和在常规的电脑文件系统中看到的表达式非常相似。在爬取bilibili热门视频top500的过程中,使用xpath查找排名、标题、播放量、弹幕量、up主等信息。
对局部的页面进行数据解析
1、通过lxml库进行实例化对象etree
2、将获取到的页面加载到我们的etree对象中,
3、再通过etree实例化对象里的Xpath方法进行数据解析
4、进行持久化存储
<head>、<body>、<div>、<p>、<a>....类型的都称之为标签,也可以称之为节点
<p>是<div>的子节点,<div>的父节点,<span>是<div>的孙子节点,<p>和<a>称之为胞节点
/text():获取该标签底下的所有的文本内容
//text():获取该标签下的所有非直系标签的文本内容
/:放在最前面表示根节点,其他位置表示依次查找
//:表示两次以上的在任意位置可查找
(3)lxml
lxml 是一个HTML/XML的解析器,主要的功能是如何解析和提取 HTML /XML数据。lxml和正则一样,也是用C实现的,是一款高性能的Python HTML /XML 解析器,可以利用之前学习的XPath语法,来快速的定位特定元素以及节点信息。使用lxml.etree处理XML文档。lxml提供了两种解析网页的方式,一种是你解析自己写的离线网页时,另一种则是解析线上网页。
(4)Pandas
pandas 是基于NumPy的一种工具,该工具是为解决数据分析任务而创建。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。它是使Python成为强大而高效的数据分析环境的重要因素之一。Pandas可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据。
(5)Pymysql
PyMySQL是在 Python3.x版本中用于连接 MySQL服务器的一个库,PyMySQL遵循 Python数据库API v2.0规范,并包含了pure-Python MySQL客户端库。可以通过pip install PyMySQL命令安装最新版的 PyMySQL。
3、Zookper
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。ZooKeeper包含一个简单的原语集,提供Java和C的接口。
4、Hbase
Base是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
5、Sqoop
Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递,可以将一个关系型数据库(例:MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
6、Hive
Hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。Hive的优点是学习成本低,可以通过类似SQL语句实现快速MapReduce统计,使MapReduce变得更加简单,而不必开发专门的MapReduce应用程序。hive十分适合对数据仓库进行统计分析。
7、FineBI可视化
帆软FineBi是帆软软件有限公司推出的一款可视化bi(商业智能产品),本质是通过分析企业已有的信息化数据,发现并解决问题,辅助决策。帆软FineBI的定位是业务人员/数据分析师自主制作仪表板,进行探索分析,以最直观快速的方式,了解自己的数据,发现数据的问题。用户只需要进行简单的拖曳操作,选择自己需要分析的字段,几秒内就可以看到数据分析结果,通过层级的收起和展开,下钻 上卷,可以迅速地了解数据的汇总情况。
3.2 系统设计
 3.2.1整体架构图
3.2.1整体架构图




3.2.2 功能需求分析
(1)配置Hadoop环境变量
配置core-site.xml
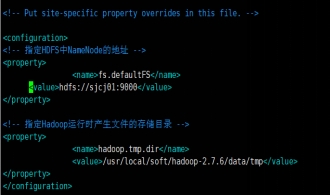
配置hadoop-env.sh
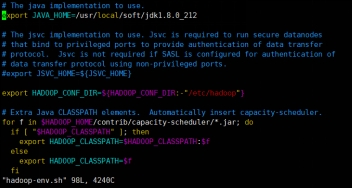
配置hdfs-site.xml
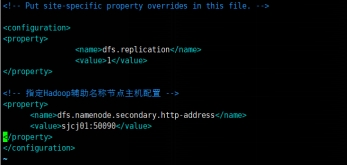
配置yarn-env.sh

配置yarn-site.xml

配置mapred-env.sh
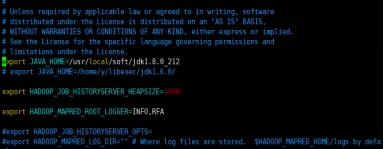
配置mapred-site.xml
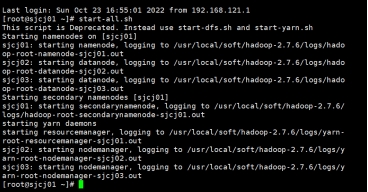
启动集群
(2)sqoop的安装过程
解压sqoop安装包

配置环境变量


重命名配置文件

修改配置文件

测试sqoop

(3)获取URL,进入页面打开浏览器控制台,选择Network查看调用的数据接口,我们可以看到URL地址、请求方式、请求头信息、响应头信息,以及请求头里的cookie、User-Agent(浏览器属性)。


(4)响应数据处理,获取到相应内容之后,进行解析内容,有两种解析方式,运用bs4库中的BeautifulSoup进行解析或者lxml库中的etree解析成树状html。

(5)登录虚拟机,Xshell 5 同时连接连接hadoop01,hadoop02,hadoop03
(6)查看ip地址

3.2.3 系统流程分析
一个网络爬虫程序的基本执行流程可以总结三个过程:请求数据, 解析数据, 保存数据。
(1)请求数据
请求的数据除了普通的HTML之外,还有 json 数据、字符串数据、图片、视频、音频等。
(2)解析数据
当一个数据下载完成后,对数据中的内容进行分析,并提取出需要的数据,提取到的数据可以以多种形式保存起来,数据的格式有非常多种,常见的有csv、json、pickle等。
(3)保存数据
最后将数据以某种格式(CSV、JSON)写入文件中,或存储到数据库(MySQL、MongoDB)中。同时保存为一种或者多种。
通常,我们想要获取的数据并不只在一个页面中,而是分布在多个页面中,这些页面彼此联系,一个页面中可能包含一个或多个到其他页面的链接,提取完当前页面中的数据后,还要把页面中的某些链接也提取出来,然后对链接页面进行爬取。
3.3 功能实现
1、根据request模块取整个网页

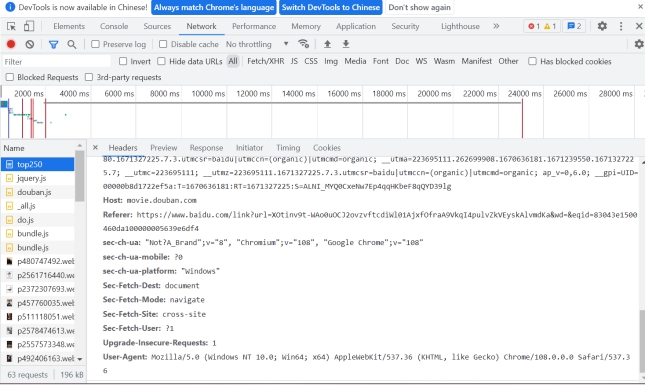

2、Xpath解析数据
注:在Element界面进行数据路径的读取可以直接copy xpath,更加方便。


3、进行持久化存储(本地,csv、json的文件进行存储)
(1)采用csv形式将数据存储,将数据取名为data,存储在当前路径下top100.cav,index默认为False,mode的形式为w,对应的编码格式ancoding为utf-8;
采用json形式将数据存储,将数据取名为data,存储在当前路径下movie_top250.cav,orient为records,froce_acsii对应的ASCII值为False;
采用数据库形式将数据存储,将movie_ranking,movie_name,movie_director,movie_type,movie_releaseData,movie_score,movie_numder,movie_starring,movie_country加入里列表中,将pandas取名为pd(import pandas as pd),将创建好的字段与对应的数据一一匹配.

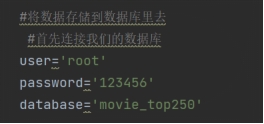
(2)将获取到的数据保存到数据库里面去,连接数据库要有对应的用户名,密码,数据库,从而切换到数据库中。
连接数据库(导入pymysql),对应的master的地址host,可在虚拟机里输入:ifconfig查看ip地址的。


(3)db连接事务,从而进行遍历和循环,将movie_ranking,movie_name,movie_director,movie_type,movie_releaseData,movie_score,movie_numder,movie_starring,movie_country通过insert into添加到t_movie中,进行数据类型说明,一一对应,追加进来(下标从0开始),最后将数据全部导入进来,通过try,执行sql语句,将其提交到数据库中执行,执行成功则db.commit(),若执行不成功,则报错(取名为e),打印一个错误相关信息并且发送回滚(指的是程序或数据处理错误,将程序或数据恢复到上一次正确状态的行为),最后关闭数据库close()。

(4)创建一张表Tabledata(对应的用户名,密码,数据库),连接数据库,连接成功后进行事务操作,连接mysql数据库,进行判断是否存在该表,若存在则删除,若不存在则创建(说明其字符类型并设计编码格式为utf-8),执行sql语句,将其提交到数据库中执行,执行成功则db.commit(),若执行不成功,则报错(取名为e),打印一个错误相关信息并且发送回滚(指的是程序或数据处理错误,将程序或数据恢复到上一次正确状态的行为),最后关闭数据库close()

(5)用main函数判断,爬取50条数据(开始打印相关的数据及信息),对应的url地址http://www.bilibili.com/v/popular/rank/all,将列表的格式转换为pandas里的dataframe,取个别名data,将获取到的数据追加到本地,.csv 或者是.json格式。

(6)连接mysql数据库,将数据放入到数据库中,创建mysql用户名user为root,mysql密码,password为123456,mysql数据库databases为'movie_top250'
(7)创建表createTabledata,将数据导入到数据库里去,再打印一个结束相关的数据及信息,以及爬取电影总共的时间和爬取电影总共的条数。

4、存储到数据库(mysql--数据库的可视化(navicat))
(1)登录

(2)展示数据库
(3)进入movie_top250数据库

(4)展示movie_top250中的表,将原先的数据以表的字段的格式导入进来
(5)查询表

(6)用Navicat更直观的查询表的信息

5、编写脚本,执行脚本
安装Zookeeper、Sqoop、Hbase、Hive并配置环境变量
(1)添加MySQL连接驱动
# 从HIVE中复制MySQL连接驱动到$SQOOP_HOME/lib
cp/usr/local/soft/hive-1.2.1/lib/mysql-connector-java-5.1.49.jar/usr/local/soft/sqoop-1.4.6/lib/
# 打印sqoop版本
sqoop version
# 测试MySQL连通性
sqoop list-databases -connect jdbc:mysql://master:3306/ -username root -password 123456

准备MySQL数据 ,登录MySQL数据库 ,创建bili_db数据库 切换数据库并导入数据 另外一种导入数据的方式 使用Navicat运行SQL文件 (上述已提及)

(2)编写脚本,保存为MySQLToHDFS.conf (方式是将命令封装成一 个脚本文件,然后使用另一个命令执行)

执行脚本 sqoop --options-file MySQLToHDFS.conf



(3)编写脚本,并保存为MySQLToHBase.conf(sqoop1.4.6 只支持 HBase1.0.1 之前的版本的自动创建 HBase 表的功能)
执行脚本 sqoop --options-file MySQLToHBase.conf

6、通过FineBI商业智能进行数据分析与可视化
1、上映年代分析

好评电影多集中在1990年之后。在1990年之前以及1990年之后两部分中,好评电影数量波动不大。电影艺术会随着时代的变化而变化,如今的观影者会更加接受现代的电影艺术。

进入21世纪之后,好评电影数量较多。好评电影出现最多的年代处于2000~2009年之间。
2、导演情况分析

在好评电影中,有多位导演的不止一部影片上榜,其中上榜电影数最多的两位导演是:克里斯托弗・诺兰 和 宫崎骏。在其后也有多位中国籍导演。导演对于一部影片的影响巨大,可以说好的导演能决定一部电影的成功与否。
3、制作国家分析

好评电影的制作国家由美国领衔,占比近50%。在其后日本、香港、中国大陆、英国也占了较大份额。美国的电影产业较为成熟,引领着这个时代的电影艺术潮流。
4、电影类型分析
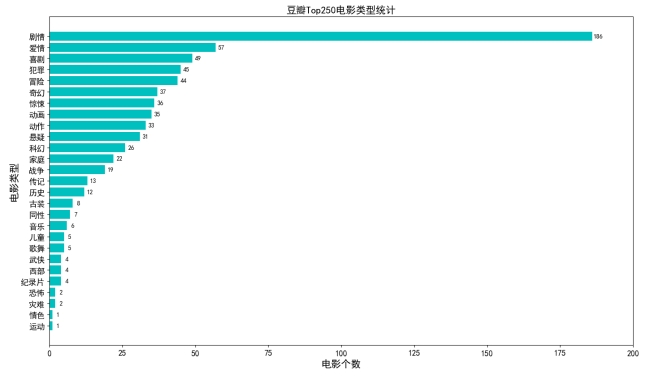
在好评电影中,剧情类型电影一骑绝尘,有高达186部电影带有“剧情”标签。其后,爱情、喜剧、冒险等类型也有多部电影。电影类型决定了电影的基调和主旨,是决定电影内容的重要因素之一。
四、实验总结
本学期数据采集让我学到了很多。比如爬虫的作用:用来获取数据量大,获取方式相同的网页数据,代替手工获取。大部分爬虫都是按“发送请求――获得页面――解析页面――抽取并储存内容”这样的流程来进行,这其实也是模拟了我们使用浏览器获取网页信息的过程。Python中爬虫相关的包很多:urllib、requests、bs4、scrapy、pyspider 等,我们是从requests+Xpath 开始,requests 负责连接网站,返回网页,Xpath 用于解析网页,便于抽取数据。在敲代码的过程中也意识到了自身很多的不足,因为知识点掌握的不牢固,在写代码的时候也遇到了大大小小的问题,对知识点认识不够细致,编写代码出错的时候,代码纠错就很艰难,但也及时求助了老师和同学从而解决了问题。
通过课程设计加强了动手能力,从理论到实践,学到很多很多的东西,同时巩固了以前所学过的知识,也意识到理论与实际相结合是很重要的,只有理论知识是远远不够的,只有把所学的理论知识与实践相结合起来,从理论中得出结论,才能真正为社会服务,从而提高自己的实际动手能力和独立思考的能力。最后也很感谢课设范老师这几周对我们的细心教导,在我遇到困难时,您帮助我解决了很多问题,从而让我知识以及一些代码命令掌握的更牢固,谢谢您!
