ժ Ҫ
�������-��ĻΪý�鴫���IJƾ���վ����¶�����ţ��漰�������й�˾�Ķ����������ҵ���顢��Ӫˮƽ�Ͳ���ս�Ծ��ߵ�һϵ����Ҫ��Ϣ���ǹ������Ͷ�ʵ���Ҫ��Ϣ��Դ����˴��Ͳƾ�������վ�ı���������һ���̶���Ӱ�������ж�����ߡ����ǣ��ƾ����ŵļ�ֵ�����ж�������������˼ά�ĽǶ�����ʶ�ƾ����ţ��Ǹ���ѧ�߽��вƾ��о���������ȵ㡣
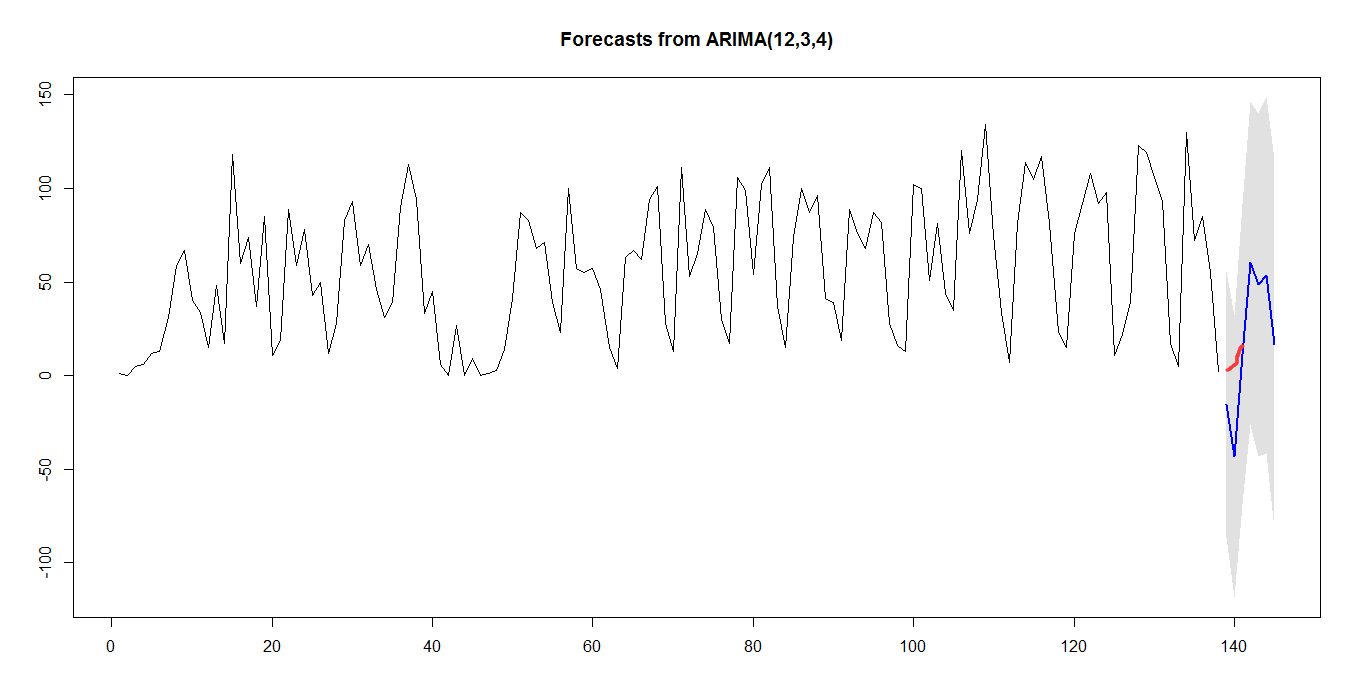
�ı��ھ��������ھ�����һ����Ҫ��ɲ��֣���ͨ��������Զ��شӲ�ͬ���ı�Դ�г�ȡ�����õ���Ϣ����������Ϣ��������ͼ�����ϵ��������̽������ͳ�о��ֶ����о�������ä�㣬���ı��ھ��Ҫ�����ѵ����ڡ���ˣ�����ƾ����ţ������ı��ھ�ϵͳ��ָ���������Ͷ�ʾ��ߣ��������ۼ�ֵҲӦ�ü�ֵ������ͨ��ϵͳ�����������֣����ű����л����ʻ��������������ʻ㣬�������ű������������е��ǵ�û������ع�ϵ�����⣬����ʹ����ARIMAģ�ͣ����ڰ�����ݶ�δ��7�����ذ�����ƽ���Ԥ�⣬����һ�����ָ�����塣
�ؼ��ʣ��ı��ھƾ����ţ�Ͷ�ʾ��ߣ�ARIMAģ��
Abstract
The news, which propagated by the media of browser �C screen, involves the directors of listed companies of opinion, industry, market, management level and the financial strategy and so on, is important information source of investors to invest. Thus, the reported by the large financial news website will to a certain extent affect people��s judgment and decision-making. How much the value of the financial news, and how to identify the perspective of critical thinking in the financial news, is a hotspot of financial research among international scholars.
Text mining is an important part of data mining technology, which can automatically extract from different text source of the information available through the computer. It is the point of text mining and the difficulty, to relate this information with the new phenomenon and assumptions, and to explore the blind spot of traditional research methods research is less than. Therefore, it has the theory value and application value, to construct a system of text mining, guide people to investment decision-making, facing the financial news. In this paper, through the system design and analysis, found that after active vocabulary is often more than the negative words in the news report, and news reports of emotion and downs of the stock market is not positive correlation. In addition, this paper use the ARIMA model, based on the plate data to forecast the future trend of the seven days of related sectors, has certain guiding significance for reference.
Keywords��Text Mining��Financial News��Investment Decision��ARIMA model
Ŀ¼
ժ Ҫ
Abstract
1.����
1.1 �о�Ŀ�ĺ�����
1.2 �ƾ���������
1.3 ����Python����
1.4 �ı��ھ����
1.5��ϵͳ�ܹ�
2. ����եȡ�����
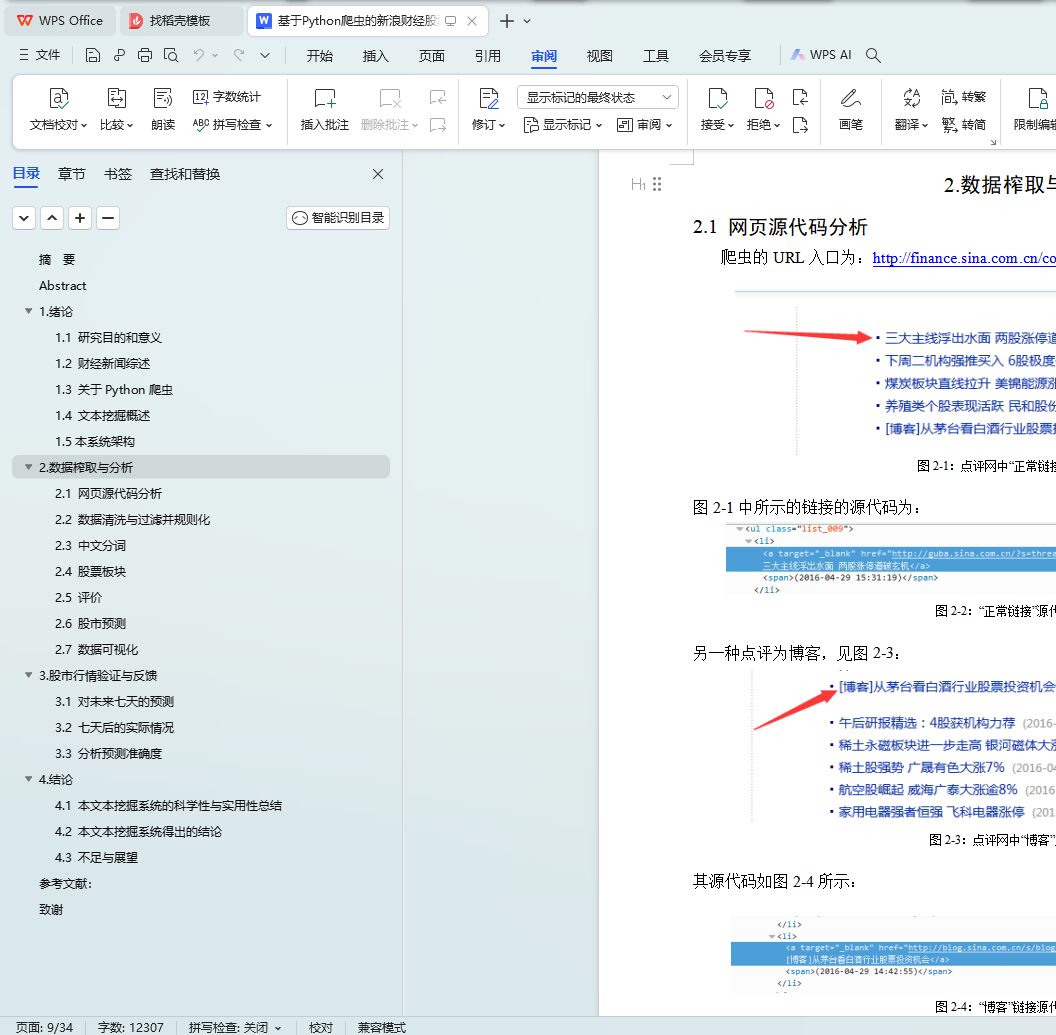
2.1 ��ҳԴ�������
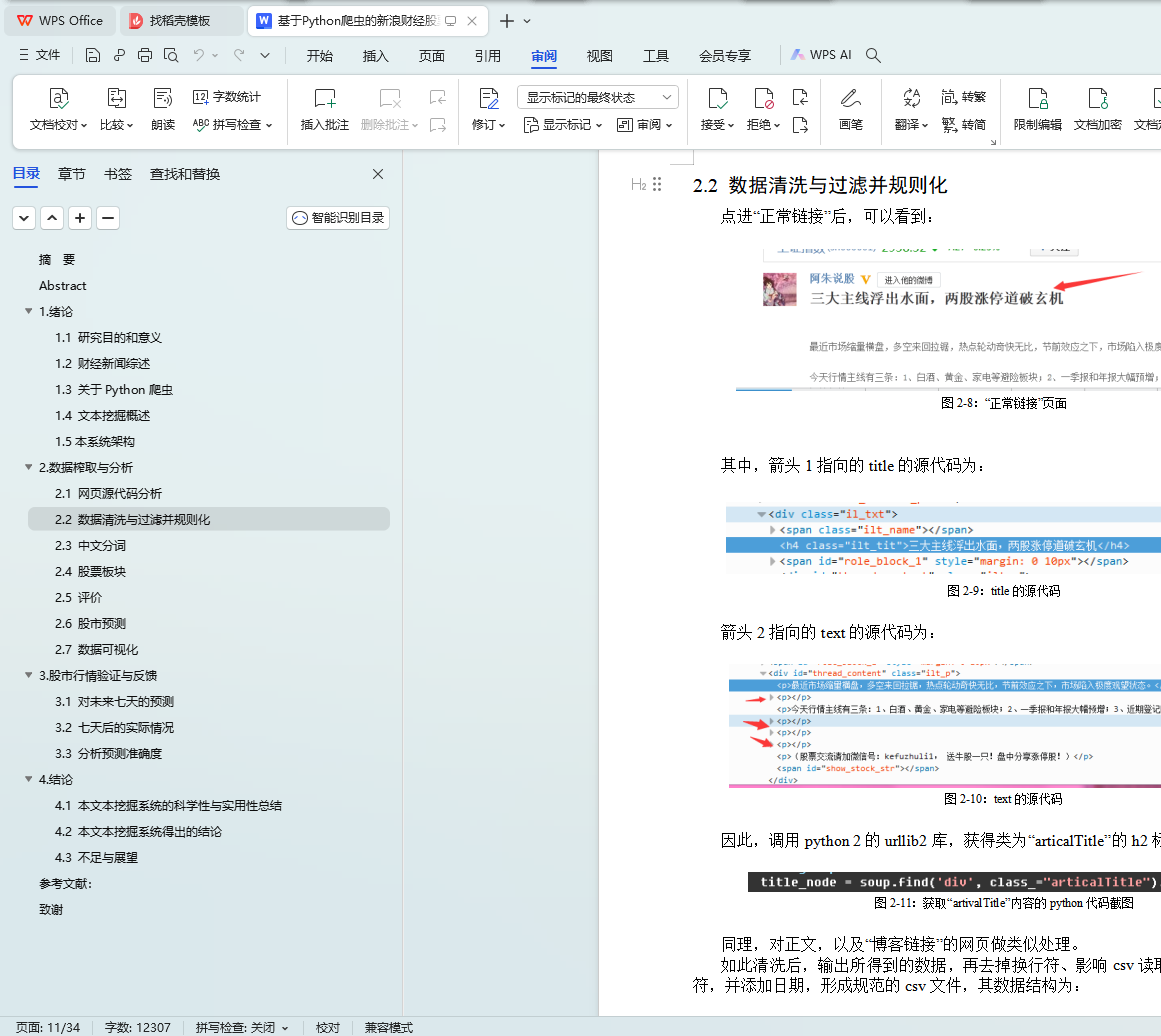
2.2 ������ϴ����˲�����
2.3 ���ķִ�
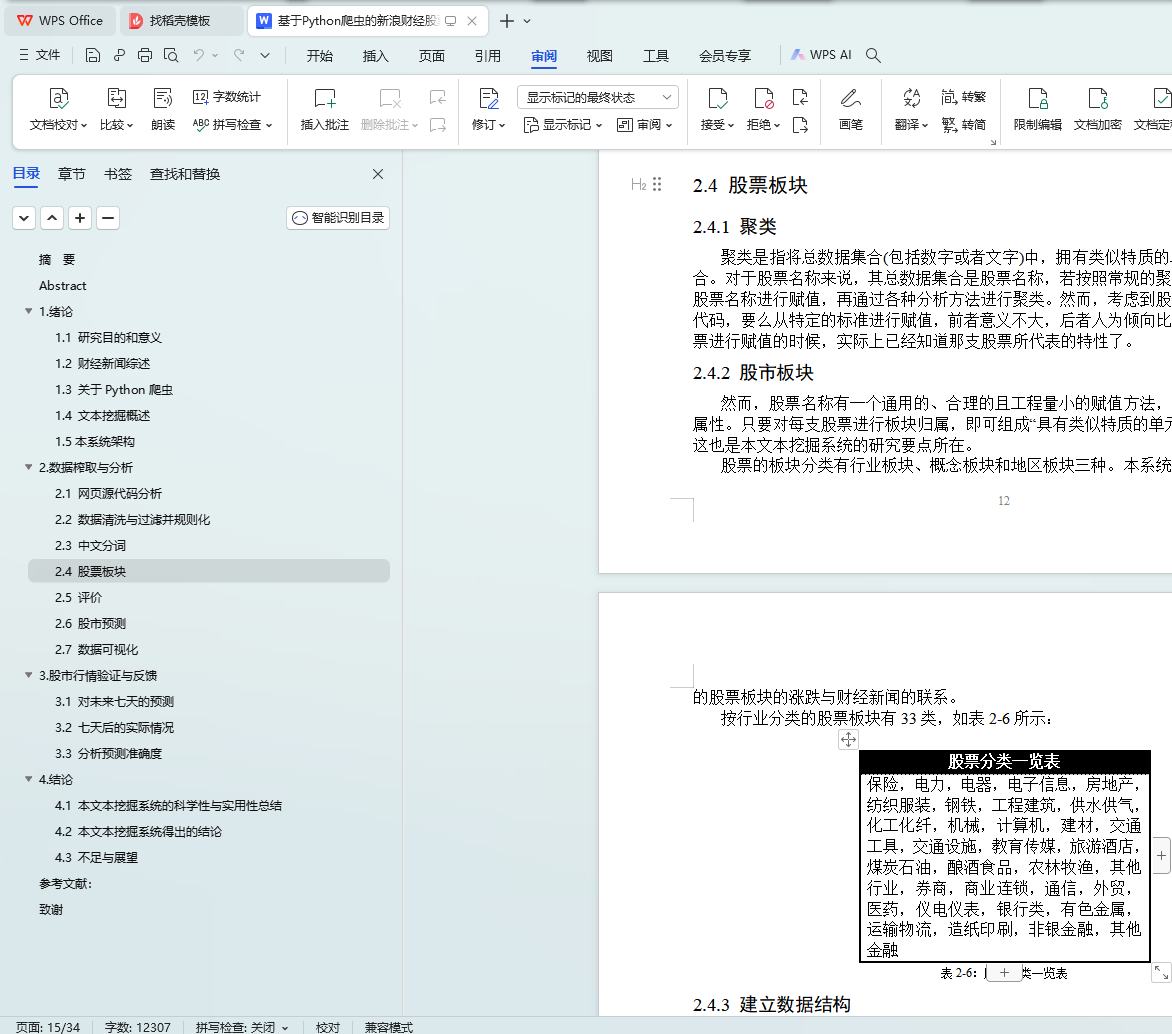
2.4 ��Ʊ���
2.5 ����
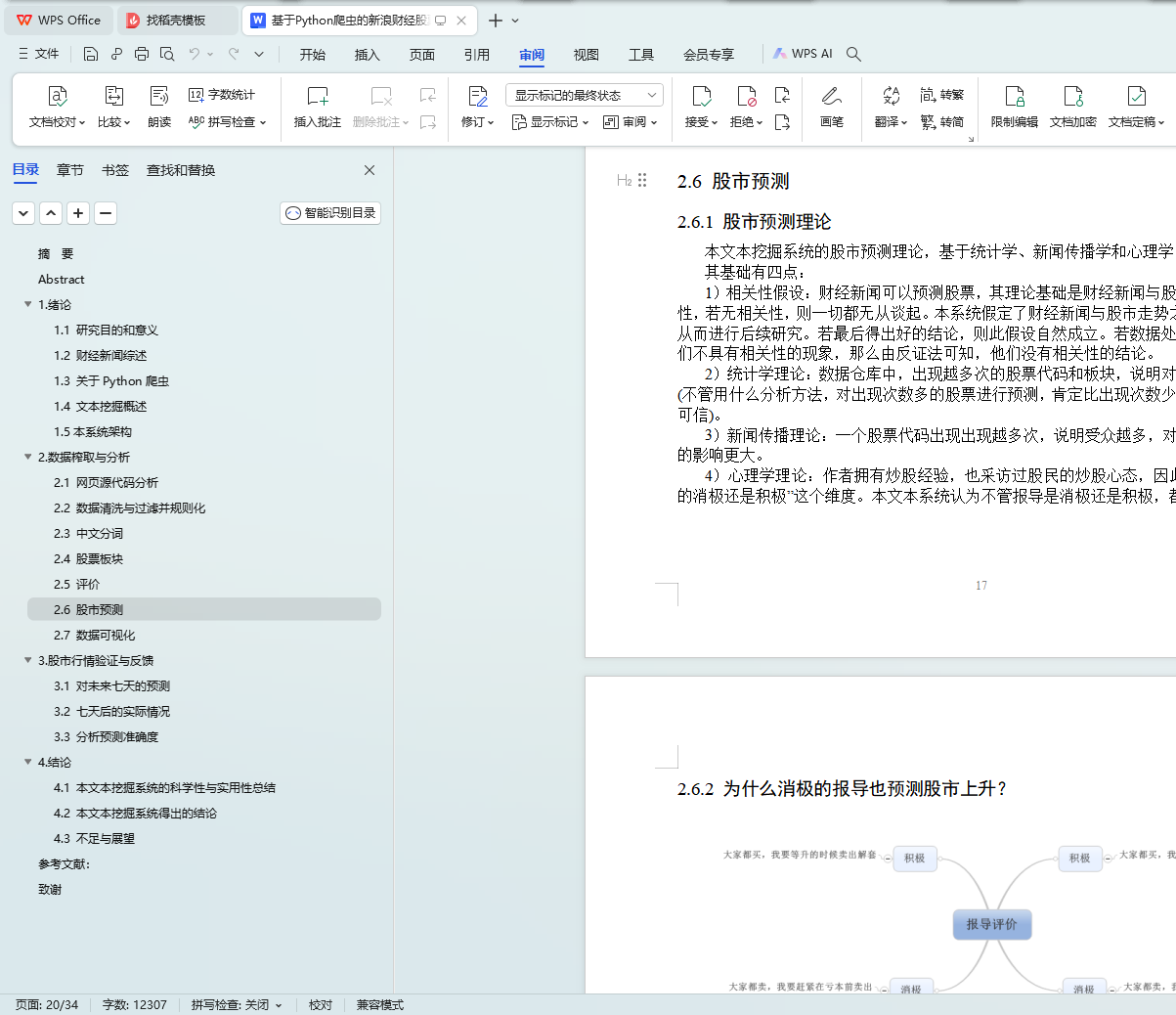
2.6 ����Ԥ��
2.7 ���ݿ��ӻ�
3. ����������֤�뷴��
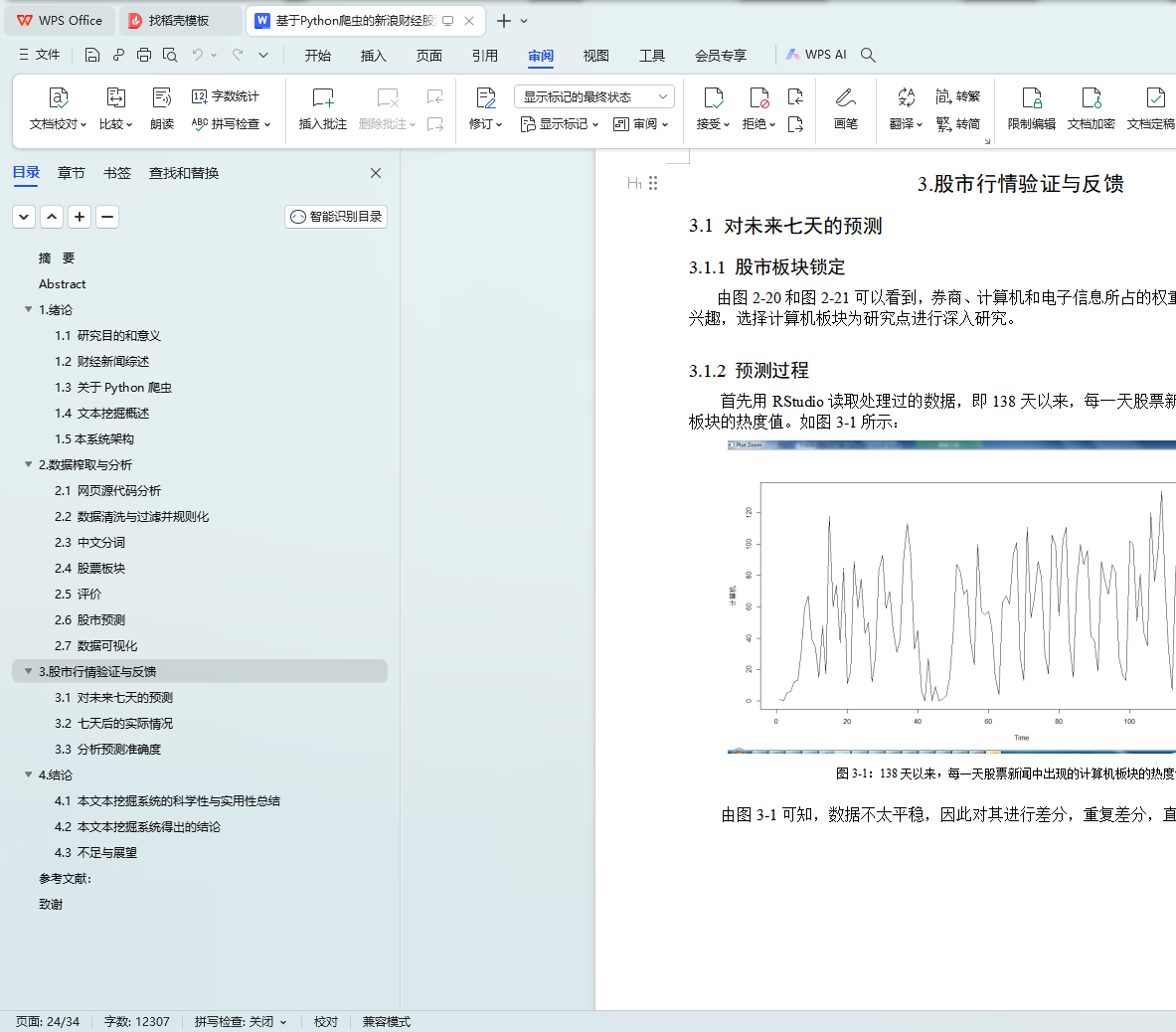
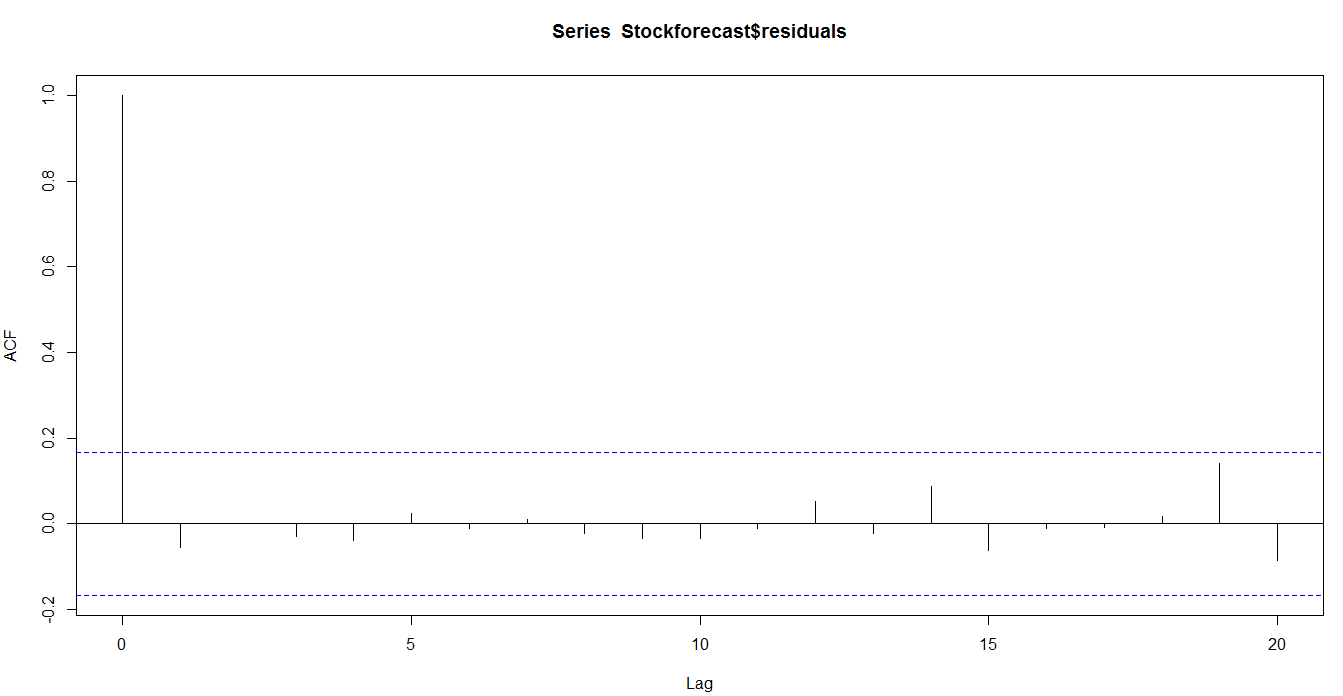
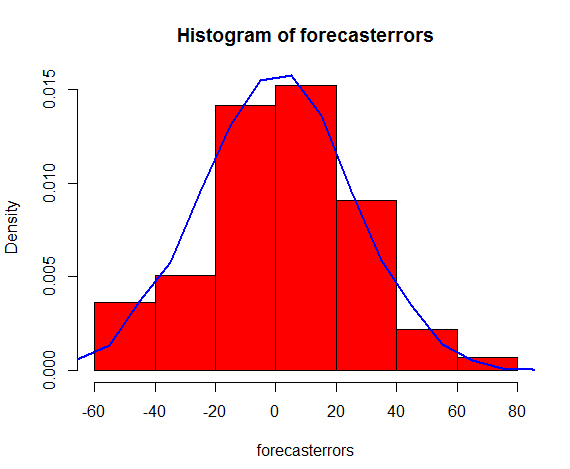
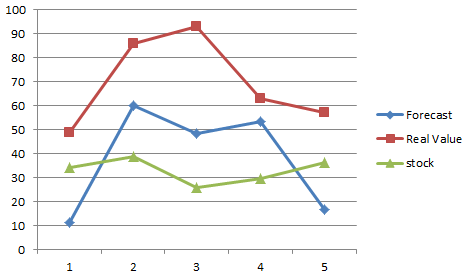
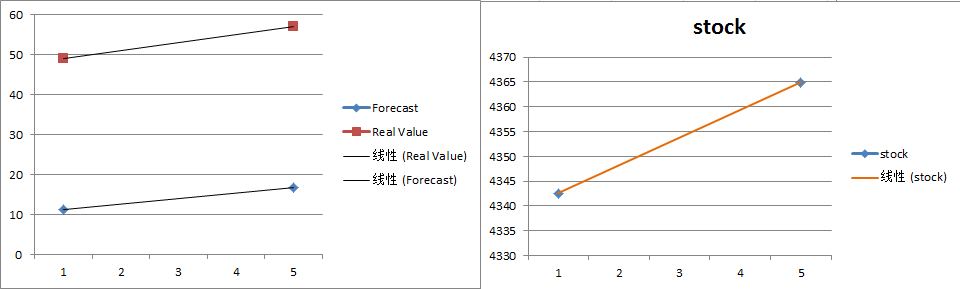
3.1 ��δ�������Ԥ��
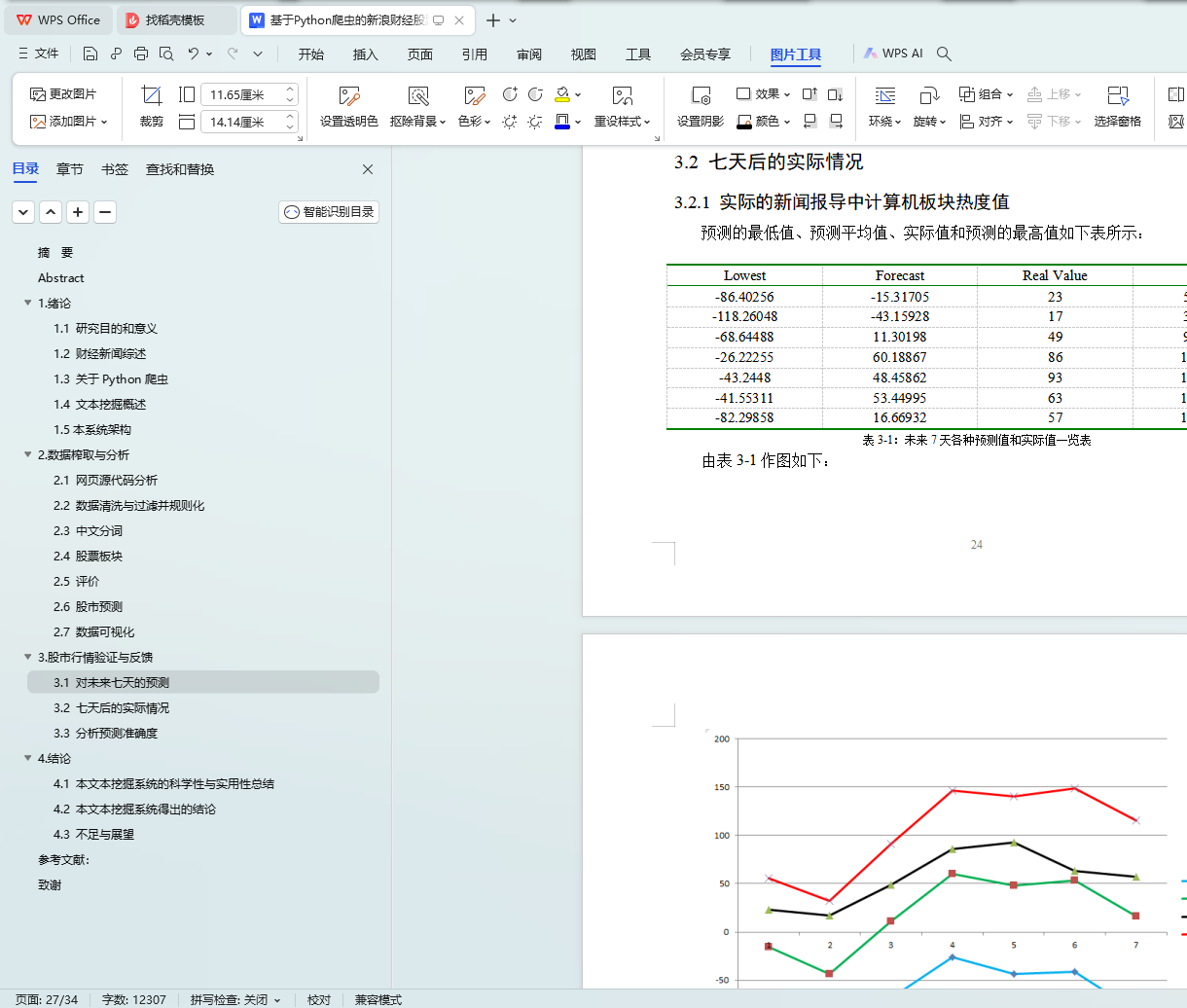
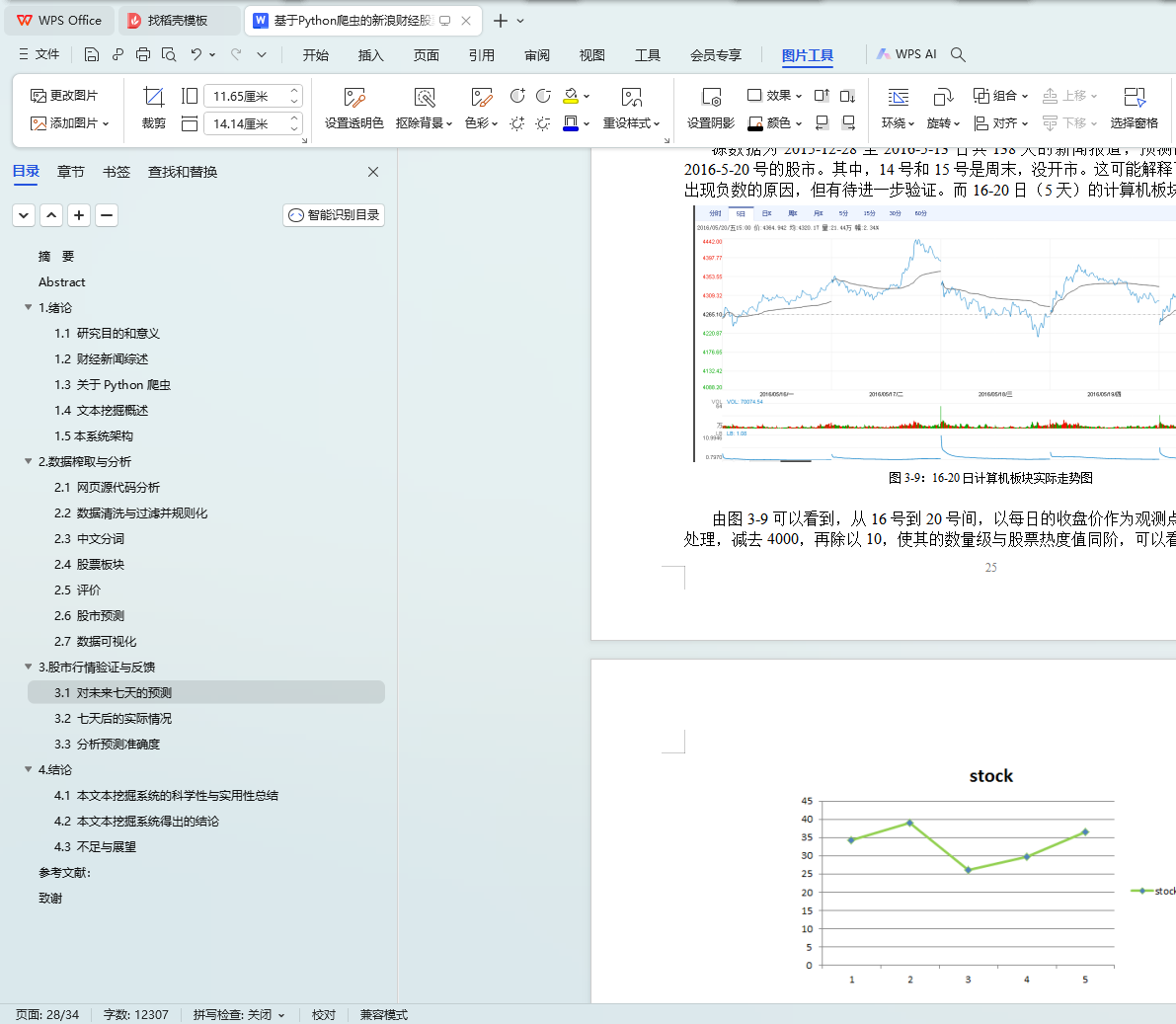
3.2 ������ʵ�����
3.3 ����Ԥ��ȷ��
4. ����
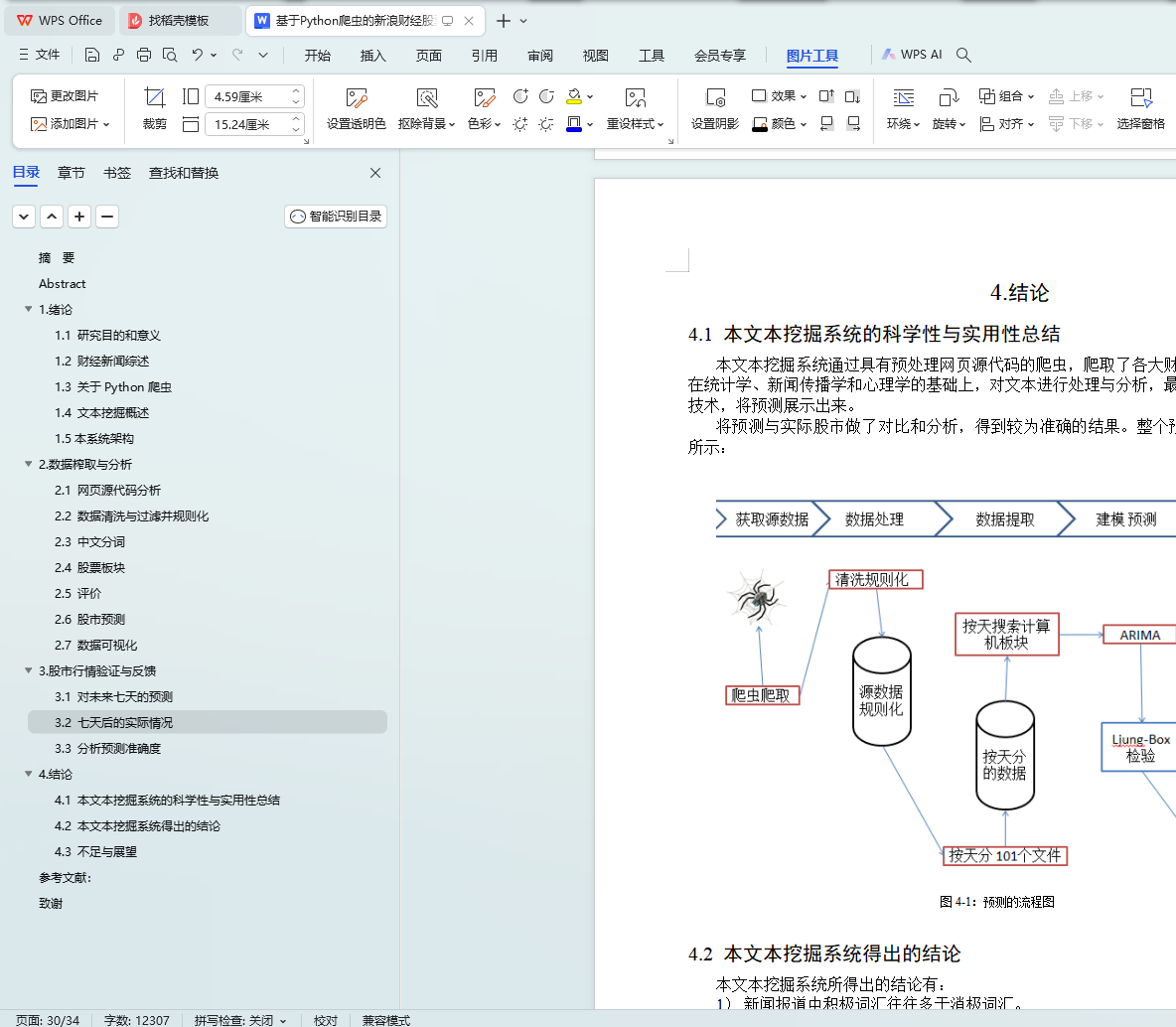
4.1 ���ı��ھ�ϵͳ�Ŀ�ѧ����ʵ�����ܽ�
4.2 ���ı��ھ�ϵͳ�ó��Ľ���
4.3 ������չ��
�ο����ף�
��л