本文使用Python编程语言进行项目开发,版本是Python3.7.9,检测模型的搭建、训练和测试都是基于Facebook深度学习框架Pytorch[13]进行的。训练的软硬件环境是CPU型号I5-8400,运行内存16G,显卡是NVIDIA GTX1060,操作系统是Ubuntu18.0.1,配置Python3.7+Pytorch1.7.0的虚拟环境。
3.1.1手势交互功能的设计与实现
在2.3.2中提到手势识别需要利用目标检测算法来实现对手势类别的分类。提到目标检测算法就需要介绍卷积神经网络(Convolutional Netronal Network,简称CNN)的相关理论。早在1998年,LeCun构建了LeNet-5[Lecun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to documentrecognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324.]卷积神经网络用于分类手写字符,取得了良好的检测效果。卷积神经网络有4个部分,分别是卷积层、池化层、全连接层和分类层,卷积神经的网络结构如图xx所示。下面是对CNN网络结构的具体介绍。
(1)卷积层。卷积层的作用是特征提取,卷积层中的卷积核执行卷积运算提取图像特征。[插入卷积过程的图片]
(2)池化层。池化层的作用是对图像特征进项降维,减小特征大小和网络权重大小,降低网络计算量。常见的池化方法有最大池化、平均池化和随机池化,各自的运算方式各不相同,但都起到降维的作用。
(3)全连接层。每个卷积神经网络经过卷积和池化后,都会连接到全连接层,全连接层的每个神经云都是与前一层的所有神经云一一对应,将前面传入的特征展开成一维特征向量,计算公式如下,
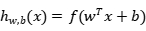
其中,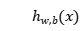 表示输出;
表示输出;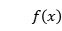 代表激活函数;w代表权重;x代表输入;b代表偏置量。
代表激活函数;w代表权重;x代表输入;b代表偏置量。
(4)分类层。分类层即输出层,其中的神经元数量依照不同的任务而定。在分类任务中,神经元的个数就是类别数。
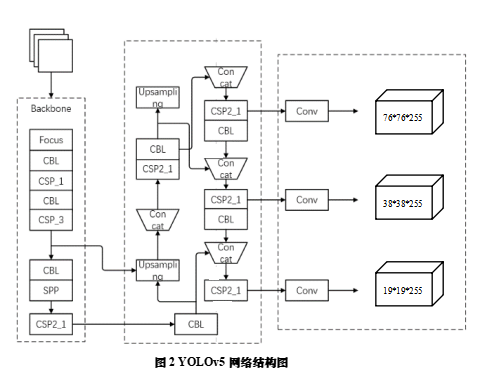
目前基于卷积神经网络的目标检测算法可以分为两类,一类是以faster-RCNN为代表的两阶段(two-stage)算法;另一类是以YOLO为代表的一阶段(one-stage)算法。两阶段算法顾名思义,需要比一阶段算法多执行一步,这样带来的好处是检测精度高,但缺点是速度较慢。所以现在较广泛应用的是Redmon[3]等提出的one-stage检测算法YOLO(You Only Look Once)。YOLO系列目标检测模型可以直接在网络中提取特征来预测物体的位置和分类,实时性较好,能够较好满足实时检测场景的需求。YOLO模型的兴起和卷积神经网络的优异性能有很大关联,经过不断的改进,YOLO已经迭代了5代,从开始的YOLOv1,到现在的YOLOv5,在实时性和准确性上都有很好的表现。本文使用的是最新的YOLOv5,它的性能相对上一代的YOLOv4有了明显的提升,精度更好,训练出的权重体积也更小,网络结构如图XX所示。
(1)手势的定义
根据实车调研和文献研究,确定了手势交互的8种手势,分别是:
1)静态手势:大拇指向上(Thumb_up)、大拇指向下(Thumb_down)、OK手势(Hand_ok)和五指张开(Hand_five);
2)动态手势:手掌向左滑动(Left)、手掌向右滑动(Right)、手掌顺时针旋转(Clockwise)以及手掌逆时针旋转(Counter_clockwise)。
这几种手势在系统中有不同的功能,具体的功能在系统的不同任务内也大有不同。在车载音乐系统中,大拇指向上和向下代表切换歌曲,OK手势表示确认播放,五指张开表示暂停播放,还有手掌顺时针和逆时针旋转表示调整音量大小;而在氛围灯控制任务中,大拇指向上和向下可以控制灯光律动的速度,手掌左右滑动代表切换灯光颜色。手势的功能需要设计者在系统内自行定义,只需要不相互冲突即可。
(2)手势数据的采集和处理[在上面补充YOLO图像识别的整个流程]
本文征集了12名实验人员,男女各半,年龄包含22-37岁,身体状况良好。在光线良好的环境下,通过摄像头采集了被试者的手势图像视频集,通过分割视频帧的方式,得到约10000张图片,去除其中的模糊图像和质量较差的图像,还剩约6500张手势图像,其中包括4类不同的静态手势,每种约有1600张,80%作为训练数据,20%作为验证数据。手势图片背景、光照强度和拍摄角度不固定,都是采用普通RGB摄像头采集的三原色图片,手部的位置距离摄像头约在30-50厘米。数据集格式是PASCAL VOC格式,数据集标注使用了常见的labelimg工具,里面有标记后的图像数据,标注后生成xml格式文件包含手势的类型和手势的位置信息。数据集需要处理成YOLOv5需要的txt标记文件。txt中存放的是归一化处理后的类别、中心点、宽高数据。转换方式如下:
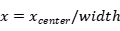
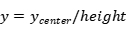
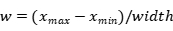
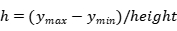
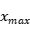 、
、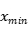 、
、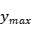 、
、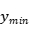 分别值xml格式文件中标注区域所在位置的左上角坐标和右下角坐标的数值。
分别值xml格式文件中标注区域所在位置的左上角坐标和右下角坐标的数值。
(3)模型训练和验证[补充shufflenet的优点]
在YOLOv5模型训练过程中,需要调整模型参数,其中包括分类的类别数、训练的迭代次数、学习率的大小以及权重的衰减系数等等参数。根据本文研究内容,需要识别的类别有5类,分别是大拇指向上(thumb_up)、大拇指向下(thumb_down)、ok手势(hand_ok)、手掌张开(hand_five)和无手势(no_hand)。整个训练迭代次数为200次,初始学习率设为0.001,学习率动量设为0.937,权重的衰减系数为0.0005。一次完整的训练耗时15个小时。
本文利用界面响应效率来验证手势控制的有效性。界面架构参考了上市车型吉利星越的系统界面,分成了5个模块,分别是主界面模块、音乐模块、导航模块、天气模块、氛围灯模块。人员能够通过手势的变化控制界面,界面通过PyQt5编写,通过信号和槽的连接将手势作为命令传给界面。例如在图3中,系统识别到手势动作向右时,控制界面向右滑动,从图a滑动到图b,反之,控制界面向左滑动,从图b滑动到图a。对于手部连续运动导致的ID Switch[16]问题,使用Kalman跟踪算法[17]来解决。为了验证手势控制界面的响应准确率,本文设计了验证试验,选取10名被试人员,在实验室环境下,固定光源和相机,安排人员用手势控制界面,统计界面响应的准确率数据。经过试验验证,动态手势的操作准确率约为86.25%,静态手势的操作平均准确率约为95.13%,具体情况如表4所示。
|
手势
|
正确次数
|
错误次数
|
未识别次数
|
测试次数
|
准确率
|
|
Thumb_up
|
128
|
0
|
2
|
130
|
98.5%
|
|
Thumb_down
|
122
|
5
|
4
|
131
|
93.1%
|
|
Hand_ok
|
113
|
7
|
3
|
123
|
91.9%
|
|
Hand_five
|
128
|
2
|
2
|
132
|
97.0%
|
|
Left
|
91
|
8
|
1
|
100
|
91%
|
|
Right
|
87
|
11
|
2
|
100
|
87%
|
|
Clockwise
|
85
|
15
|
0
|
100
|
85%
|
|
Counter_clockwise
|
82
|
18
|
0
|
100
|
82%
|
实验结果显示,使用YOLOv5目标检测模型来用于手势识别准确率较高,识别速度达到了20FPS左右,可以满足本课题实时手势识别的要求。
3.1.2语音交互功能的设计与实现
百度AI开放平台是百度利用自身的技术优势完成了一个AI基础架构平台,并开放出来供开发者使用,它具备语音识别、语音合成和语音解析等功能,为移动端和PC端都提供了相应的接口。
本系统调用了百度的语音接口实现对音频信号的转换,将人通过话筒输入的声音转换成文本数据并保存到文本文件中。百度语音识别控件支持实时语音转写、语音合成、语音唤醒等功能。
(1)语音识别
实时语音识别需要通过网络连接服务器来上传语音和下传文本信息,优点是识别精度好,不需要占用本地的储存空间安装语音库,但识别速度取决于上传和下传的网络速度。
(2)语音唤醒
语音唤醒可以减少非指令语音的误操作,输入正确的唤醒词才能调用语音识别功能,提高了识别效率。唤醒词可以按照自身需要确定内容,通常是四字格式,譬如“你好,XX”。在正确输入唤醒词后,语音识别系统需要作出反馈,提示用户可以执行语音识别功能,语音系统的反馈通常是由语音合成来完成。
(3)语音合成
语音合成是将用户设定好的文本内容用特定的声音输出成语音信息,即将文字信息转换成声音信息,这种声音相较于一般的机器声更加流程和自然。目前百度智能语音提供了包含老幼中青的6种声音,开发者可以按照自己的喜好选择。
[缺少一幅语音识别流程图]本文调用百度语音识别功能的流程如图xx所示,具体步骤如下:
(1)启动程序,播放启动程序提示音。用户使用麦克风输入语音,需要通过唤醒词唤醒语音识别功能。
(2)系统检测到语音,将语音上传服务器,调用语音识别引擎,将语音转换成文本信息,传回本地端。唤醒后检测的窗口时间为5s,时间间隔可以自行设定。
(3)系统检测到文本指令,若指令正确,启动语音合成给用户反馈信息,识别结束;如果指令错误,需要重新执行以上流程。
在多通道交互系统设计之前,需要检验百度语音识别API的效果[基于智能手机的多通道交互系统研究-王蒙]。在语音识别过程中一般会出现三种错误:
(1)丢失错误:未能识别命令;
(2)误识别错误:正确的命令被误识别为其他命令;
(3)插入错误:在正确命令中间插入不存在的词语。
定义准确率公式为:
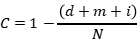
C表示识别的准确率;N为测试的总次数;d表示丢失错误次数;m表示误识别的次数;i表示插入错误的次数。
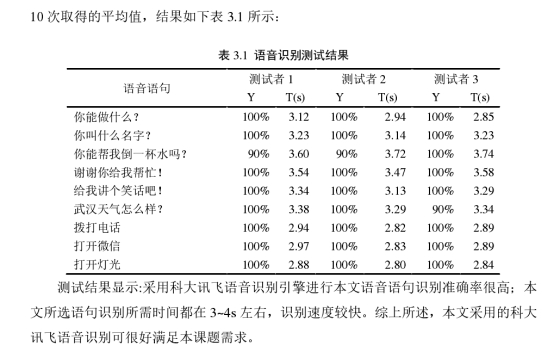
为了验证百度语音识别的准确率和速度,本文选取3名实验人员在实验室环境下测试语音识别效果,实验人员需要对着麦克风说出以下命令词,为了便于统计,每个命令次重复说10次,统计系统识别的平均时间和平均准确率数据,具体的数据如表XX所示:
|
命令词
|
测试人A
反馈时间 准确率
|
测试人B
反馈时间 准确率
|
测试人C
反馈时间 准确率
|
|
上一首歌
|
|
|
|
|
|
|
|
下一首歌
|
|
|
|
|
|
|
|
关闭音乐
|
|
|
|
|
|
|
|
打开氛围灯
|
|
|
|
|
|
|
|
今天天气如何?
|
|
|
|
|
|
|
测试结果。。。根据xx文献资料显示,语音识别的反馈时间应该在xx-xx范围内,百度语音识别可以满足需求。
3.1.3眼动交互功能的设计与实现
眼动交互也是利用摄像头捕捉眼球视线的方式来实现。
(1)实验标准定义
在进行驾驶分心测试时,会通过检测视线是否集中在目标区域来检验驾驶员是否分心。但存在一些主观和客观的原因让驾驶员的视线暂时离开了目标区域,如强烈的光线刺激或者观察后视镜情况,这会让实验检测到的数据不准确。因此需要指定分心标准,在标准内的数据代表驾驶员保持专注的状态,标准外的数据代表驾驶员已经分心。通过标准的指定可提高数据的有效性。
[此处需要查询<基于驾驶分心行为的车载信息装置测评研究>P44]Land的研究表明,专注时间和任务类型相关,最短平均专注时间为150ms。因此,本文将驾驶员视线停留在目标区域大于150ms的片段定义为专注,驾驶员视线离开目标区域大于150ms的片段定义为分心。
(2)眼动检测与氛围灯交互
在XX章中提到,氛围灯可以通过灯光颜色和灯效的变化提醒驾驶员改变当前状态,将注意力几种到驾驶任务上。在整个系统中,氛围灯警示功能的实现需要依赖眼动检测先给出检测结果,之后才能调动氛围灯模块的功能。当驾驶员的视线停留在目标区域时,氛围灯保持低亮度状态,在这个状态不会影响驾驶任务;当驾驶员的视线离开目标区域超过150ms,氛围灯的亮度逐渐提高,颜色也变化成警示的黄色或者红色,并且灯效也变成律动的模式,提醒驾驶员将注意力放在驾驶任务上;当驾驶员的视线离开目标区域远大于150ms时,氛围灯的亮度会提升到最亮,并且颜色会变成深红色的禁止色,律动的频率也更快,警示驾驶员应该立即将视线回到目标区域,运行过程如图XX所示。[此处补上一幅眼动识别和氛围灯的流程图]
(3)任务测试
让5名实验人员故意将视线从目标区域移开来模拟分心状态,检验眼动识别系统的准确率。实验人员需要先让视线停留在目标区150ms以上,然后将视线转向其他方向,再视线移回目标区150ms,轮流执行,每人执行20次以上,计算眼动识别系统的平均准确率,详细结果如图XX所示。

3.3本章小结
本章详细阐述了如何实现多通道交互系统的手势识别、语音识别、眼动识别等功能。手势识别采用YOLOv5目标检测模型,通过采集手势数据和模型训练,实现了4种静态手势的分类;再通过计算手部中心点坐标向量的变化,利用kalman滤波算法实现对移动手势的稳定跟踪,实现了对4种动态手势的识别。对于手势交互的效率采用了实验验证的方式来检测。让实验人员使用手势动作控制界面的切换,界面是用PyQt5编写,测试得到手势识别的准确率,可以满足课题需要。语音识别则是采用了百度语音识别和语音合成引擎,完成语音信息转文本和文本信息转语音的过程。同样是让实验人员来检测语音识别系统的性能,让实验人员发出10道语音指令,验证了语音系统的识别准确率和反应时间。阐述了眼动识别的运行机制,首先利用摄像头检测人眼位置,在通过算法确定视线中心点,当视线从目标区转移时,判断视线转移的方向和分心时间,最后通过实验人员的实验检测出眼动识别的运行效果。
在检验完多通道交互系统中各项分系统的性能之后,各项系统的性能符合课题性能的要求,下面将叙述交互系统的设计过程。